グラフィカルな実行プランに関する限り、SQLServerの物理的な並べ替えのアイコンは1つだけです。

これと同じアイコンが、3つの論理ソート演算子(ソート、トップNソート、および個別ソート)に使用されます:
レベルをさらに深くすると、実行エンジンには4つの異なるSortの実装があります(最適化されたループ結合のバッチ並べ替えはカウントされません。これは完全な並べ替えではなく、プランには表示されません)。 SQL Server 2014を使用している場合、実行エンジンの並べ替えの実装の数は7つに増えます。
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew(SQL Server 2014のみ)
- CQScanInMemSortNew
- インメモリOLTP(Hekaton)ネイティブにコンパイルされたプロシージャTop N Sort(SQL Server 2014のみ)
- インメモリOLTP(Hekaton)ネイティブにコンパイルされたプロシージャGeneral Sort(SQL Server 2014のみ)
この記事では、これらの並べ替えの実装と、それぞれがSQLServerで使用される場合について説明します。パート1では、リストの最初の4つの項目について説明します。
1。 CQScanSortNew
これは最も一般的なソートクラスであり、他の使用可能なオプションが適用できない場合に使用されます。一般的な並べ替えでは、クエリの実行が開始される直前に予約されているワークスペースメモリの付与が使用されます。この助成金は、カーディナリティの見積もりと平均行サイズの予想に比例し、増やすことはできません クエリの実行が開始された後。
現在の実装では、さまざまな内部マージソート(おそらくバイナリマージソート)を使用しているように見えます。予約されたメモリが不十分であることが判明した場合は、外部マージソート(必要に応じて複数のパスを使用)に移行します。外部マージソートは物理的なtempdbを使用します メモリに収まらないソート実行用のスペース(一般にソートスピルとして知られています)。一般的な並べ替えは、並べ替え操作中に区別を適用するように構成することもできます。
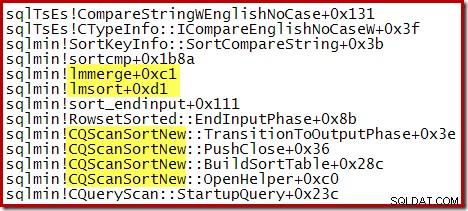
次の部分的なスタックトレースは、 CQScanSortNewの例を示しています。 内部マージソートを使用した文字列のクラスソート:
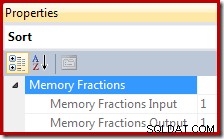
実行プランでは、Sortは、レコードの読み取り時にSortで使用できるクエリワークスペースメモリ付与全体の割合(入力フェーズ)、および並べ替えられた出力が親プランオペレーターによって消費されているときに利用可能な割合(出力フェーズ)に関する情報を提供します。 。
メモリ許可の割合は0から1までの数値(1 =許可されたメモリの100%)であり、[並べ替え]を強調表示して[プロパティ]ウィンドウを見ると、SSMSに表示されます。以下の例は、単一の並べ替え演算子のみを使用したクエリから取得したものであるため、入力フェーズと出力フェーズの両方で使用可能な完全なクエリワークスペースメモリ付与があります。
メモリの割合は、入力フェーズ中に、実行プランでその下にあるメモリを消費する演算子を同時に実行するクエリメモリ許可全体をSortが共有する必要があるという事実を反映しています。同様に、出力フェーズでは、Sortは、実行プランで同時に実行されているメモリを消費する演算子と、付与されたメモリを共有する必要があります。
クエリプロセッサは、一部のオペレータがブロック(ストップアンドゴー)していることを認識できるほど賢く、メモリ付与をリサイクルおよび再利用できる境界を効果的にマークします。並列プランでは、一般的なソートで使用できるメモリ付与の割合はスレッド間で均等に分割され、スキュー(並列ソートプランでのスピルの一般的な原因)の場合に実行時にリバランスできません。
SQL Server 2012以降には、メモリを消費するプランオペレーターを初期化するために必要な最小ワークスペースメモリ許可、および望ましいに関する追加情報が含まれています。 メモリ付与(メモリ内の操作全体を完了するために必要と推定される「理想的な」メモリ量)。実行後(「実際の」)実行プランには、メモリ許可の取得の遅延、実際に使用されたメモリの最大量、およびメモリ予約がNUMAノード間でどのように分散されたかに関する新しい情報もあります。
次のAdventureWorksの例はすべて、 CQScanSortNewを使用しています。 一般的な並べ替え:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; 最初のクエリ(個別ではない並べ替え)は、次の実行プランを生成します。
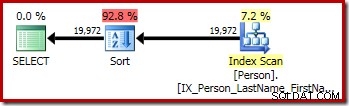
2番目と3番目の(同等の)クエリはこの計画を作成します:
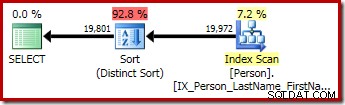
CQScanSortNew 論理的な一般的な並べ替えと論理的な個別の並べ替えの両方に使用できます。
2。 CQScanTopSortNew
CQScanTopSortNew CQScanSortNewのサブクラスです トップNソートを実装するために使用されます(名前が示すように)。 CQScanTopSortNew コア作業の多くをCQScanSortNewに委任します 、ただし、Nの値に応じて、さまざまな方法で詳細な動作を変更します。
N> 100の場合、 CQScanTopSortNew 基本的には通常のCQScanSortNew N行の後にソートされた行の生成を自動的に停止するソート。 N <=100の場合、 CQScanTopSortNew 並べ替え操作中に現在の上位N件の結果のみを保持し、現在適格である最低のキー値を追跡します。
たとえば、最適化されたトップNソート(N <=100)中に、コールスタックは RowsetTopNを機能します。 一方、セクション1の一般的な並べ替えでは、 RowsetSortedが表示されました。 :
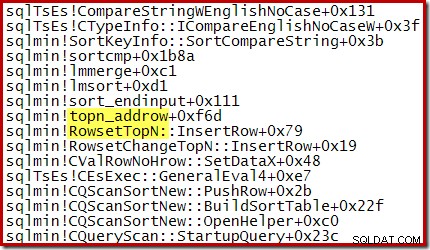
N> 100の上位Nソートの場合、実行の同じ段階での呼び出しスタックは、前に見た一般的なソートと同じです。
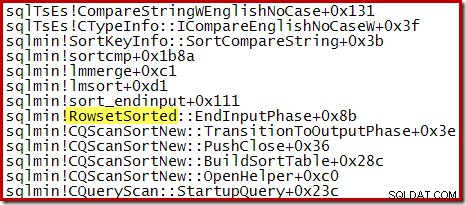
CQScanTopSortNew クラス名は、これらのスタックトレースのいずれにも表示されません。これは単にサブクラス化が機能する方法によるものです。これらのクエリの実行中の他の時点で、 CQScanTopSortNew メソッド(Open、GetRow、CreateTopNTableなど)は、呼び出しスタックに明示的に表示されます。例として、クエリ実行の後の時点で次のようになり、 CQScanTopSortNewが表示されます。 クラス名:
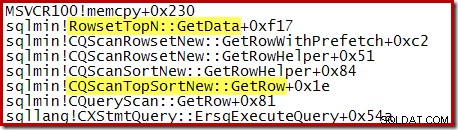
トップNソートとクエリオプティマイザ
クエリオプティマイザは、実行エンジンオペレータのみであるTopNSortについては何も知りません。オプティマイザが(個別ではない)物理ソートのすぐ上にある物理トップ演算子を使用して出力ツリーを生成する場合、最適化後の書き換えにより、2つの物理操作を単一のトップNソート演算子にまとめることができます。 N> 100の場合でも、これは、Sort出力とTop入力の間で行を繰り返し渡すことによる節約を表します。
次のクエリは、文書化されていない2つのトレースフラグを使用して、オプティマイザの出力と最適化後の書き換えの動作を示しています。
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352);> オプティマイザーの出力ツリーには、物理的なTop演算子とSort演算子が別々に表示されます。
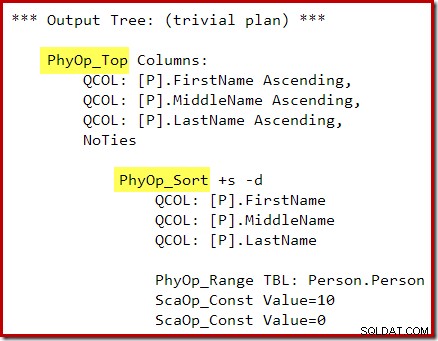
最適化後の書き換え後、トップとソートは単一のトップNソートに折りたたまれています:
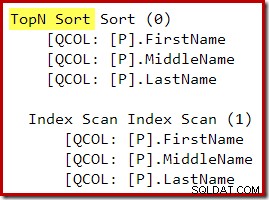
上記のT-SQLクエリのグラフィカルな実行プランは、単一のTopNSort演算子を示しています。
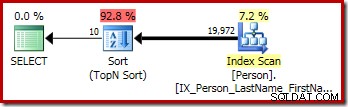
トップNソートの書き換えを破る
トップNソートの最適化後の書き換えでは、隣接するトップおよび明確でないソートのみをトップNソートに折りたたむことができます。上記のクエリにDISTINCT(または同等のGROUP BY句)を追加すると、上位Nソートの書き換えが防止されます:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; このクエリの最終的な実行プランには、個別の上位演算子と並べ替え(個別の並べ替え)演算子が含まれています。
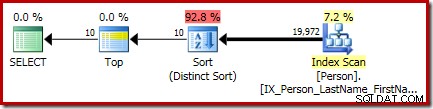
並べ替えには、一般的な CQScanSortNewがあります。 前のセクション1で見たように、クラスは個別モードで実行されます。
トップNソートへの書き換えを防ぐ2番目の方法は、トップとソートの間に1つ以上の追加の演算子を導入することです。例:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; クエリオプティマイザの出力には、TopとSortの間の操作が含まれるようになったため、最適化後の書き換えフェーズではTopNSortは生成されません。
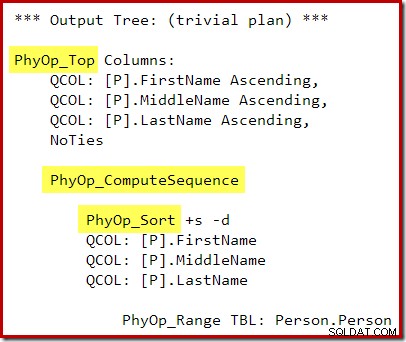
実行計画は次のとおりです。

トップとソートの間の計算シーケンス(2つのセグメントとシーケンスプロジェクトとして実装)は、トップとソートが単一のトップNソート演算子に折りたたまれるのを防ぎます。もちろん、この計画からも正しい結果が得られますが、実行は、組み合わせたトップNソート演算子を使用した場合よりも少し効率が低下する可能性があります。
3。 CQScanIndexSortNew
CQScanIndexSortNew DDLインデックス作成プランでのソートにのみ使用されます。これは、すでに見た一般的な並べ替え機能の一部を再利用しますが、インデックス挿入のための特定の最適化を追加します。また、より多くのメモリを動的に要求できる唯一のソートクラスです。 実行開始後。
テーブルの行の総数は通常既知の量であるため、カーディナリティの推定は、インデックス作成計画では正確であることがよくあります。これは、インデックス作成計画の並べ替えに対するメモリの付与が常に正確であるということではありません。デモが少し簡単になります。したがって、次の例では、文書化されていないが、かなりよく知られているUPDATE STATISTICSコマンドの拡張機能を使用して、オプティマイザーをだまして、インデックスを作成しているテーブルに1行しかないことを考えさせます。
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; インデックスビルドの実行後(「実際の」)実行プランでは、1行の見積もりと19,972行が実際に並べ替えられているにもかかわらず、こぼれた並べ替え(SQL Server 2012以降で実行した場合)の警告は表示されません。
>
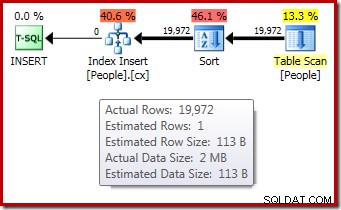
最初のメモリ許可が動的に拡張されたことの確認は、ルートイテレータのプロパティを確認することで得られます。クエリには最初に1024KBのメモリが付与されましたが、最終的には1576KBを消費しました:
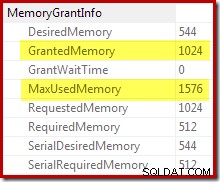
付与されたメモリの動的な増加は、デバッグチャネルの拡張イベントsort_memory_grant_adjustment。を使用して追跡することもできます。 このイベントは、メモリ割り当てが動的に増加するたびに生成されます。このイベントが監視されている場合、以下のように、拡張イベント(いくつかの厄介な構成とトレースフラグを使用)または接続されたデバッガーのいずれかを介して、公開時にスタックトレースをキャプチャできます。
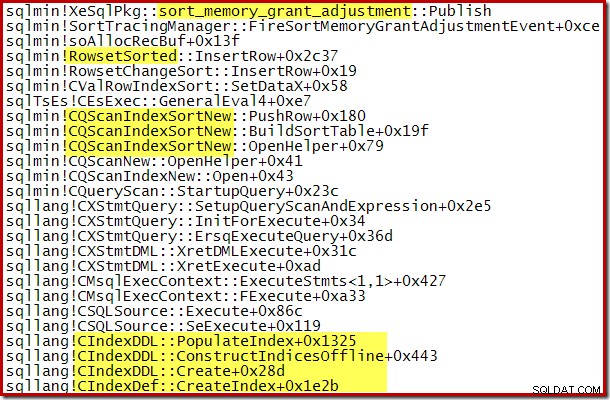
動的メモリ許可拡張は、スレッド間での行の分散が不均一である並列インデックス構築計画にも役立ちます。ただし、この方法で消費できるメモリの量は無制限ではありません。 SQL Serverは、拡張が必要になるたびに、その時点で利用可能なリソースを考慮して、要求が妥当であるかどうかを確認します。
このプロセスに関する洞察は、文書化されていないトレースフラグ1504を、3604(コンソールへのメッセージ出力用)または3605(SQL Serverエラーログへの出力用)とともに有効にすることで取得できます。インデックス作成計画が並列の場合、並列ワーカーはトレースメッセージをクロススレッドでコンソールに送信できないため、3605のみが有効です。
トレース出力の次のセクションは、メモリが制限されているSQLServer2014インスタンスで適度に大きなインデックスを構築しているときにキャプチャされました。
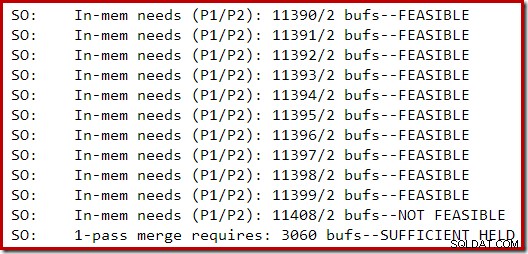
ソートのメモリ拡張は、要求が実行不可能であると見なされるまで続行され、その時点で、シングルパスのソートスピルが完了するのに十分なメモリがすでに保持されていると判断されました。
4。 CQScanPartitionSortNew
このクラス名は、このタイプのソートがパーティション表データに使用されるか、パーティション表に索引を作成するときに使用されることを示唆している可能性がありますが、実際にはどちらも当てはまりません。パーティション化されたデータの並べ替えには、 CQScanSortNewを使用します またはCQScanTopSortNew 普段通り;パーティションインデックスに挿入するために行を並べ替えるには、通常、 CQScanIndexSortNewを使用します。 セクション3に見られるように。
CQScanPartitionSortNew 並べ替えクラスはSQLServer2014にのみ存在します。これは、パーティション化されたクラスター化列ストアインデックスに挿入する前に、パーティションIDで行を並べ替える場合にのみ使用されます。 。 パーティション化にのみ使用されることに注意してください クラスタ化された列ストア。通常の(パーティション化されていない)クラスター化された列ストア挿入プランは、ソートの恩恵を受けません。
パーティション化されたクラスター化列ストアインデックスへの挿入は、常にソートを備えているとは限りません。これは、挿入される行の推定数に依存するコストベースの決定です。オプティマイザーが、I / Oを最適化するためにパーティションごとに挿入を並べ替える価値があると推定した場合、列ストア挿入演算子には DMLRequestSortがあります。 プロパティをtrueに設定し、 CQScanPartitionSortNew 実行計画に並べ替えが表示される場合があります。
このセクションのデモでは、連番の永続的なテーブルを使用します。これらのいずれかがない場合は、次のスクリプトを使用して作成できます。
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); デモ自体には、パーティション化されたクラスター化列ストアのインデックス付きテーブルを作成し、オプティマイザーに事前挿入パーティションソートを使用するように説得するのに十分な行を(上記のNumbersテーブルから)挿入することが含まれます。
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; 挿入の実行プランは、行がクラスター化された列ストアの挿入イテレーターにパーティションIDの順序で確実に到着するようにするために使用される並べ替えを示しています。

CQScanPartitionSortNew中にキャプチャされたコールスタック ソートが進行中であったことを以下に示します:
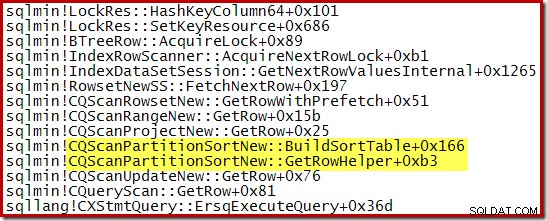
このソートクラスには、他にも興味深いことがあります。ソートは通常、Openメソッド呼び出しで入力全体を消費します。ソート後、親オペレーターに制御を戻します。その後、ソートは、GetRow呼び出しを介して通常の方法で、一度に1つずつソートされた出力行の生成を開始します。 CQScanPartitionSortNew 上記の呼び出しスタックでわかるように、は異なります。Openメソッド中に入力を消費せず、GetRowが親から初めて呼び出されるまで待機します。
パーティション化されたクラスター化列ストアインデックスに行を挿入する実行プランに表示されるパーティションIDのすべての並べ替えが、 CQScanPartitionSortNewになるわけではありません。 選別。ソートが列ストアインデックス挿入演算子のすぐ右側に表示される場合、それが CQScanPartitionSortNewである可能性が非常に高くなります。 並べ替えます。
最後に、 CQScanPartitionSortNew は、ドキュメント化されていないトレースフラグ8666を有効にしてSortオペレーター実行プランプロパティが生成されたときに公開されるSoftSortプロパティを設定する2つのソートクラスのうちの1つです。
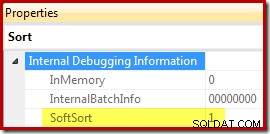
この文脈での「ソフトソート」の意味は不明です。これはクエリオプティマイザのフレームワークのプロパティとして追跡され、最適化されたパーティションデータ挿入に関連している可能性がありますが、それが何を意味するのかを正確に判断するには、さらに調査が必要です。それまでの間、このプロパティを使用して、並べ替えが CQScanPartitionSortNewで実装されていることを推測できます。 デバッガーを接続せずに。上記のInMemoryプロパティフラグの意味については、パート2で説明します。ではありません。 通常の並べ替えがメモリ内で実行されたかどうかを示します。
パート1の概要
- CQScanSortNew 他のオプションが適用できない場合に使用される一般的なソートクラスです。 tempdb を使用して外部マージソートに移行し、メモリ内のさまざまな内部マージソートを使用しているようです。 付与されたメモリワークスペースが不十分であることが判明した場合。このクラスは、一般的な並べ替えと個別の並べ替えに使用できます。
- CQScanTopSortNew トップNソートを実装します。 N <=100の場合、メモリ内の内部マージソートが実行され、 tempdbにスピルすることはありません。 。ソート中は、現在の上位n個のアイテムのみがメモリに保持されます。 N>100の場合CQScanTopSortNew CQScanSortNewと同等です N行が出力された後に自動的に停止するソート。 N> 100の並べ替えは、 tempdbに流出する可能性があります 必要に応じて。
- 実行プランに見られる上位Nソートは、クエリ最適化後の書き換えです。クエリオプティマイザが隣接するトップで個別でないソートを含む出力ツリーを生成する場合、この書き換えにより、2つの物理演算子が単一のトップNソート演算子に折りたたまれる可能性があります。
- CQScanIndexSortNew インデックス構築DDLプランでのみ使用されます。これは、実行中により多くのメモリを動的に取得できる唯一の標準ソートクラスです。インデックス作成の並べ替えは、SQL Serverが要求されたメモリの増加が現在のワークロードと互換性がないと判断した場合など、状況によってはディスクに流出する可能性があります。
- CQScanPartitionSortNew SQL Server 2014にのみ存在し、パーティション化されたクラスター化列ストアインデックスへの挿入を最適化するためにのみ使用されます。 「ソフトソート」を提供します。
この記事の第2部では、 CQScanInMemSortNewについて説明します。 、および2つのインメモリOLTPネイティブコンパイルされたストアドプロシージャの並べ替え。