集約はソースシステムに任せるのが最善であるという@PaulStockに完全に同意します。 SSISのアグリゲートは、ソートによく似た完全なブロックコンポーネントであり、その点についてはすでに私の議論をしました 。
ただし、ソースシステムでこれらの操作を実行しても機能しない場合があります。私が思いついた最善の方法は、基本的にデータを二重処理することです。はい、病気ですが、影響を受けずに列を通過させる方法を見つけることができませんでした。最小/最大シナリオの場合、オプションとしてそれが必要ですが、明らかにSumのようなものでは、コンポーネントがどの「ソース」行に関連付けられるかを知るのが難しくなります。
2005
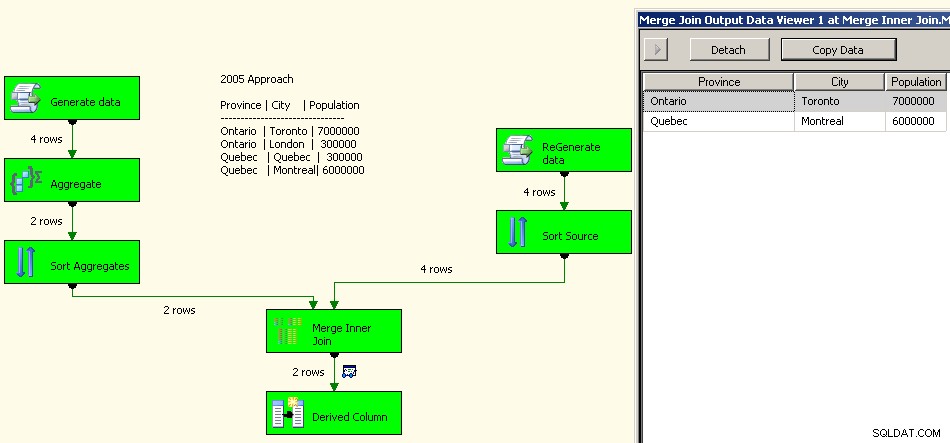
2005年の実装は次のようになります。ソースデータを再処理する必要があることに加えて、これらすべてのブロッキング変換が含まれているため、パフォーマンスは良くありません。実際、良いものから数桁です。
マージ参加 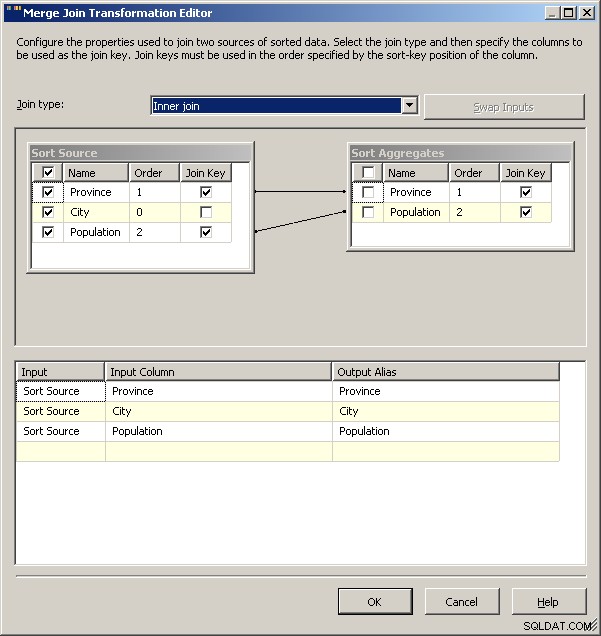
2008
2008年には、キャッシュ接続マネージャー を使用するオプションがあります。 これは、少なくとも重要な場合には、ブロッキング変換を排除するのに役立ちますが、それでもソースデータを二重処理するコストを支払う必要があります。
2つのデータフローをキャンバスにドラッグします。 1つ目は、キャッシュ接続マネージャーにデータを入力し、集約が行われる場所である必要があります。
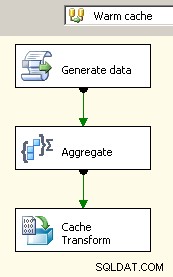
キャッシュに集約データが含まれるようになったので、メインデータフローにルックアップタスクをドロップし、キャッシュに対してルックアップを実行します。
一般的なルックアップタブ
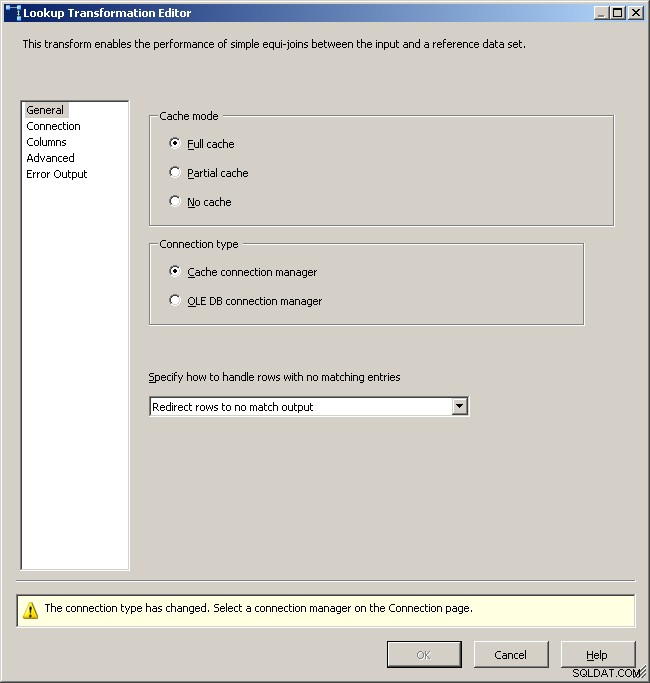
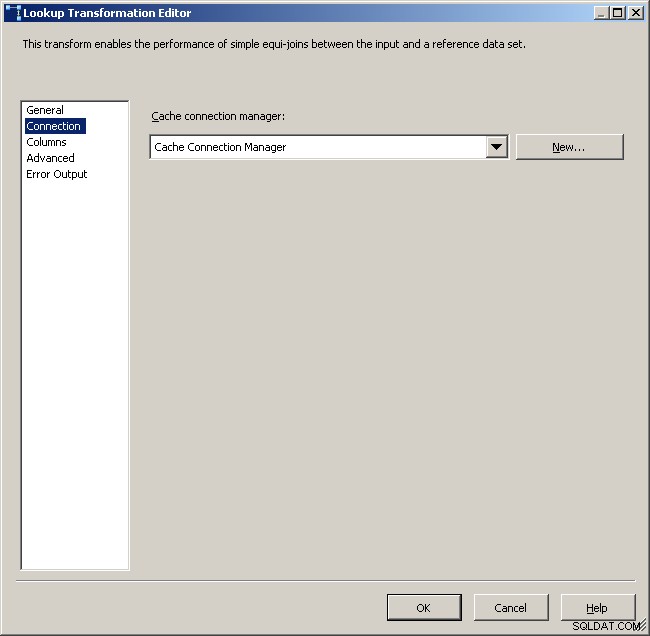
キャッシュ接続マネージャーを選択します
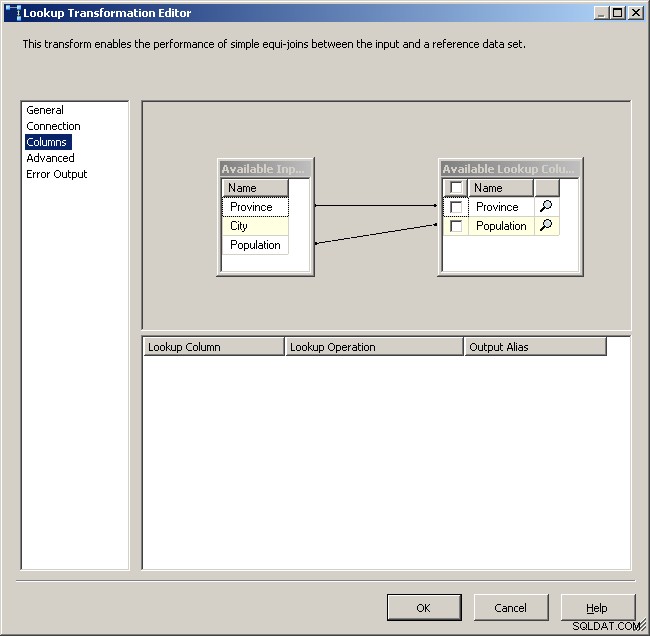
適切な列をマッピングする
大成功 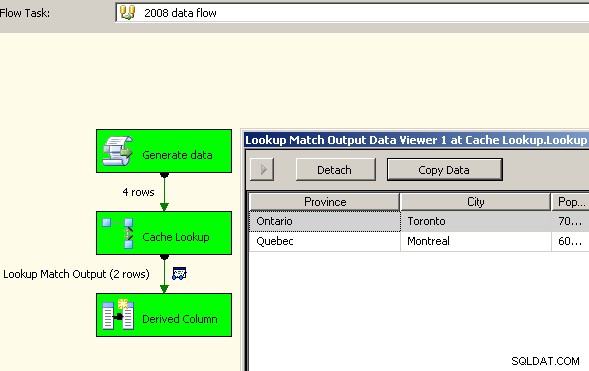
スクリプトタスク
私が考えることができる3番目のアプローチ、2005年または2008年は、それを自分で書くことです。原則として、私はスクリプトタスクを避けようとしますが、これはおそらく理にかなっているケースです。 非同期スクリプト変換 ただし、そこで集計を処理するだけです。維持するコードが増えますが、ソースデータを再処理する手間を省くことができます。
最後に、一般的な警告として、ネクタイの影響がソリューションにどのように影響するかを調査します。このデータセットの場合、グエルフのようなものが突然膨らんでトロントを結ぶと予想しますが、もしそうなら、パッケージは何をすべきでしょうか?現時点では、両方ともオンタリオの2行になりますが、それは意図された動作ですか?もちろん、スクリプトを使用すると、同点の場合に何が起こるかを定義できます。 「通常の」データをキャッシュし、それをルックアップ条件として使用し、集計を使用してタイの1つだけを引き戻すことで、2008年のソリューションを真っ向から立てることができます。 2005は、マージ結合の左側のソースとしてアグリゲートを配置するだけで、おそらく同じことを実行できます
編集
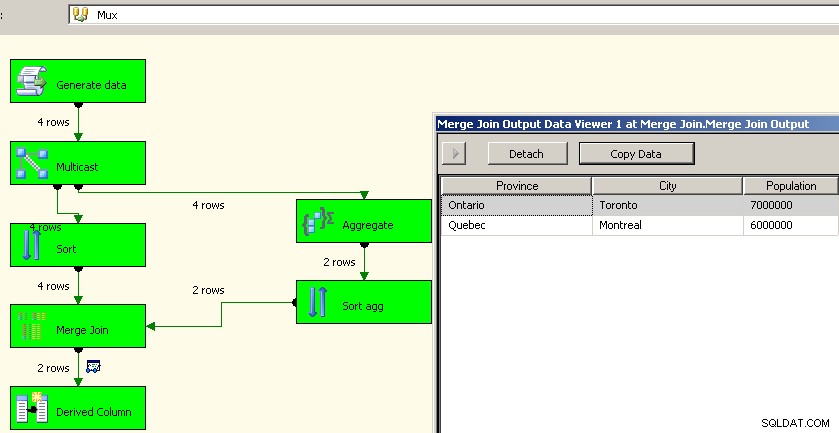
ジェイソン・ホーナーは彼のコメントで良い考えを持っていました。別のアプローチは、マルチキャストトランスフォーメーションを使用し、1つのストリームで集約を実行して、それを元に戻すことです。ユニオンで機能させる方法はわかりませんでしたが、上記のように並べ替えとマージ結合を使用することはできました。これは、ソースデータを再処理する手間を省くため、おそらくより良いアプローチです。