サブツリーのコストは、大雑把に考える必要があります (カーディナリティ エラーが大きい場合は特にそうです)。 SET STATISTICS IO ON; SET STATISTICS TIME ON; 出力は、実際のパフォーマンスのより良い指標です。
ゼロ行の並べ替えは、リソースの 87% を使用しません。あなたの計画におけるこの問題は、統計の見積もりの 1 つです。実際の計画に示されているコストは、依然として推定コストです。実際に起こったことを考慮してそれらを調整することはありません。
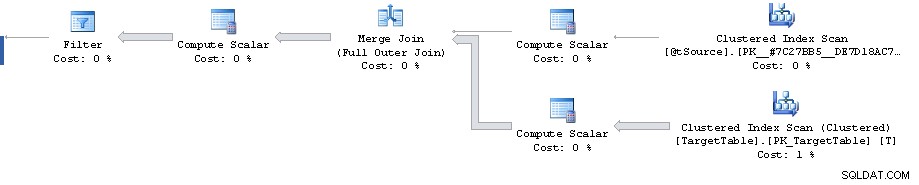
計画には、フィルタによって 1,911,721 行が 0 に削減されるポイントがありますが、今後の推定行数は 1,860,310 です。その後、すべてのコストは偽物であり、87% のコストと推定される 3,348,560 行のソートで最高潮に達します。
カーディナリティ推定エラーは Merge 外で再現できます Full Outer Join の推定計画を調べることによるステートメント 同等の述語を使用 (同じ 1,860,310 行の見積もりが得られます)。
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
とはいえ、フィルター自体までの計画は非常に最適ではないように見えます. 2 つのクラスター化インデックス レンジ シークを含むプランが必要な場合に、完全なクラスター化インデックス スキャンを実行しています。 1 つはソースの結合から主キーに一致する単一の行を取得し、もう 1 つは T.Key1 = @id を取得します。 範囲 (これは、後でクラスター化されたキーの順序でソートする必要がないようにするためでしょうか?)
おそらく、この書き直しを試して、うまくいくか、うまくいかないかを確認してください
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;