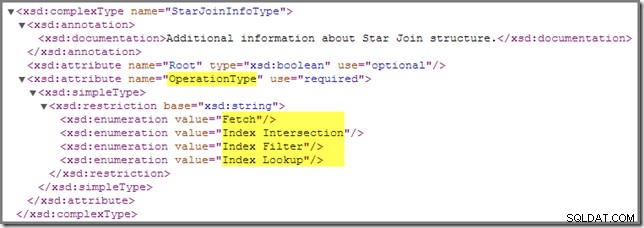
実行プランの1つ以上の結合にStarJoinInfoの注釈が付けられていることに気付く場合があります。 構造。公式のショープランスキーマには、このプラン要素について次のように書かれています(クリックして拡大):
そこに示されているインラインドキュメント(「スター結合構造に関する追加情報」 ")はそれほど啓発的ではありませんが、他の詳細は非常に興味深いものです。これらについて詳しく見ていきます。
「SQLServerスター結合の最適化」などの用語を使用して詳細についてお気に入りの検索エンジンを調べると、最適化されたビットマップフィルターを説明する結果が表示される可能性があります。これは、SQL Server 2008で導入された個別のエンタープライズ専用機能であり、StarJoinInfoとは関係ありません。 構造全体。
選択的スタークエリの最適化
StarJoinInfoの存在 SQLServerが選択的なスタースキーマクエリを対象とした一連の最適化の1つを適用したことを示します。これらの最適化は、(エンタープライズだけでなく)すべてのエディションのSQLServer2005から利用できます。 選択的に注意してください ここでは、ファクトテーブルからフェッチされた行数を示します。クエリ内の次元述語の組み合わせは、その個々の述語が多数の行を修飾する場合でも、依然として選択的である可能性があります。
通常のインデックスの共通部分
次のAdventureWorksクエリが示すように、クエリオプティマイザは、適切な単一のインデックスが存在しない複数の非クラスタ化インデックスの組み合わせを検討する場合があります。
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
オプティマイザーは、2つの非クラスター化インデックス(1つはSalesPersonIDにある)を組み合わせると判断します。 もう1つはCustomerID )は、このクエリを満たすための最も安価な方法です(両方の列にインデックスはありません):
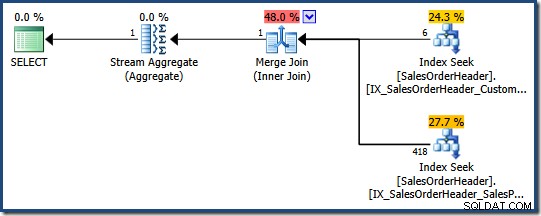
各インデックスシークは、述部を渡す行のクラスター化インデックスキーを返します。結合は返されたキーと一致し、両方に一致する行のみを確保します。 述語が渡されます。
テーブルがヒープの場合、各シークはクラスター化インデックスキーではなくヒープ行識別子(RID)を返しますが、全体的な戦略は同じです。各述語の行識別子を見つけて、それらを一致させます。
手動スター結合インデックス交差
同じ考え方を、ディメンションテーブルに適用された述語を使用してファクトテーブルから行を選択するクエリに拡張できます。これがどのように機能するかを確認するには、次のクエリ(Contoso BIサンプルデータベースを使用)を検討して、正確に50人の従業員がいるContosoストアで販売されたMP3プレーヤーの合計販売額を見つけます。
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; 後の取り組みと比較するために、この(非常に選択的な)クエリは次のようなクエリプランを生成します(クリックして展開):
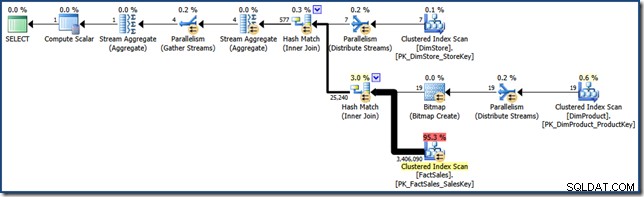
その実行計画の推定コストは、15.6ユニットをわずかに超えています。 。ファクトテーブルのフルスキャンによる並列実行が特徴です(ビットマップフィルターが適用されていますが)。
このサンプルデータベースのファクトテーブルには、デフォルトでファクトテーブルの外部キーに非クラスター化インデックスが含まれていないため、いくつか追加する必要があります。
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
これらのインデックスを配置すると、インデックスの交差を使用して効率を向上させる方法を確認できます。最初のステップは、個別の述部ごとにファクトテーブルの行識別子を見つけることです。次のクエリは、単一のディメンション述語を適用してから、ファクトテーブルに結合して、行識別子(ファクトテーブルのクラスター化インデックスキー)を検索します。
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; クエリプランは、小さなディメンションテーブルのスキャンを示し、続いてファクトテーブルの非クラスター化インデックスを使用して行識別子を検索します(非クラスター化インデックスには常にベーステーブルのクラスター化キーまたはヒープRIDが含まれることに注意してください):
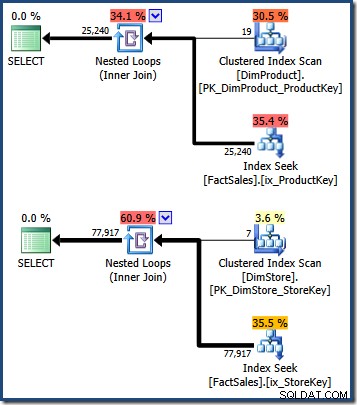
これらの2セットのファクトテーブルクラスター化インデックスキーの共通部分は、元のクエリによって返される必要がある行を識別します。これらの行識別子を取得したら、各ファクトテーブル行で売上高を検索し、合計を計算する必要があります。
手動インデックス交差クエリ
これらすべてをクエリにまとめると、次のようになります。
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
FORCESEEK ファクトテーブルへのポイントルックアップを確実に取得するためのヒントがあります。これがないと、オプティマイザーはファクトテーブルをスキャンすることを選択します。これは、まさに回避しようとしていることです。 MAXDOP 1 ヒントは、最終的な計画を表示目的でかなり妥当なサイズに保つのに役立ちます(クリックしてフルサイズで表示):
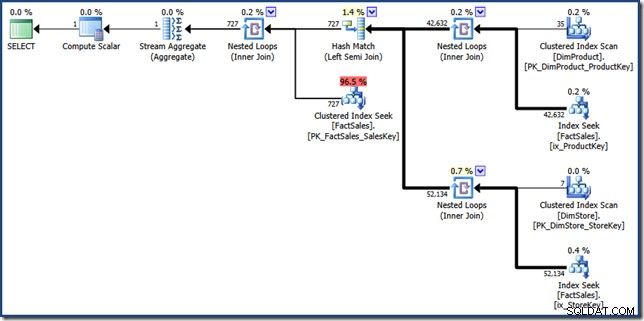
手動インデックス交差計画の構成要素は、非常に簡単に識別できます。右側の2つのファクトテーブル非クラスター化インデックスルックアップは、2セットのファクトテーブル行識別子を生成します。ハッシュ結合は、これら2つのセットの共通部分を見つけます。ファクトテーブルへのクラスター化されたインデックスシークは、これらの行識別子の売上高を見つけます。最後に、StreamAggregateが合計金額を計算します。
このクエリプランは、ファクトテーブルの非クラスター化インデックスとクラスター化インデックスに対して比較的少数のルックアップを実行します。クエリが十分に選択的である場合、これはファクトテーブルを完全にスキャンするよりも安価な実行戦略である可能性があります。 Contoso BIサンプルデータベースは比較的小さく、販売ファクトテーブルには340万行しかありません。より大きなファクトテーブルの場合、フルスキャンと数百のルックアップの違いは非常に重要になる可能性があります。残念ながら、手動で書き直すと、重大なカーディナリティエラーが発生し、推定コストが46.5ユニットになる計画になります。 。
ルックアップを使用した自動スター結合インデックス交差
幸いなことに、私たちが書いているクエリがこの手動の書き直しを正当化するのに十分選択的であるかどうかを決定する必要はありません。選択クエリのスター結合最適化は、クエリオプティマイザが、よりユーザーフレンドリーな元のクエリ構文を使用して、このオプションを探索できることを意味します。
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
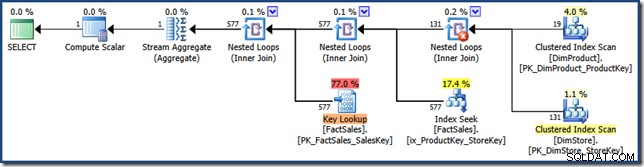
AND DP.ProductName LIKE N'%MP3%'; オプティマイザーは、 1.64の推定コストで次の実行プランを作成します 単位(クリックして拡大):
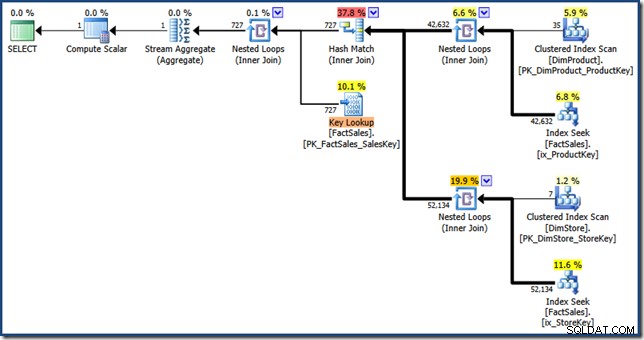
このプランと手動バージョンの違いは次のとおりです。インデックス交差は、セミ結合ではなく内部結合です。クラスター化インデックスルックアップは、クラスター化インデックスシークではなくキールックアップとして表示されます。ポイントを無駄にするリスクがありますが、ファクトテーブルがヒープである場合、キールックアップはRIDルックアップになります。
StarJoinInfoプロパティ
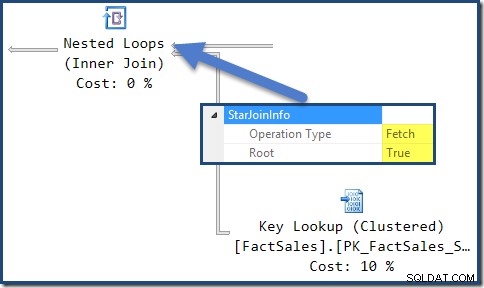
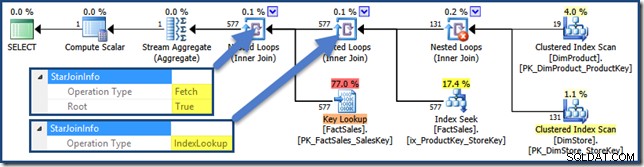
このプランの結合にはすべてStarJoinInfoがあります 構造。表示するには、結合イテレータをクリックして、[SSMSのプロパティ]ウィンドウを確認します。 StarJoinInfoの左側にある矢印をクリックします ノードを展開する要素。
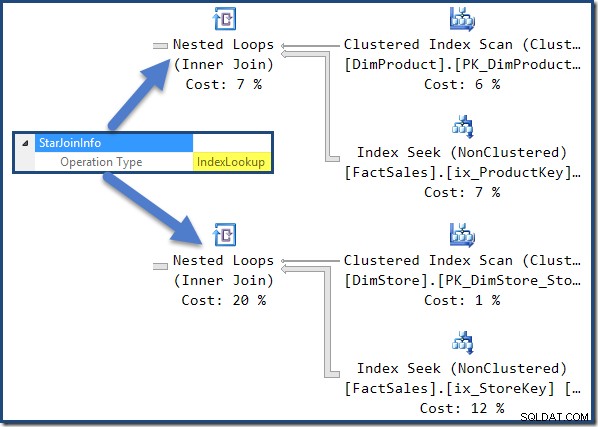
プランの右側にある非クラスター化ファクトテーブルの結合は、オプティマイザーによって作成されたインデックスルックアップです:
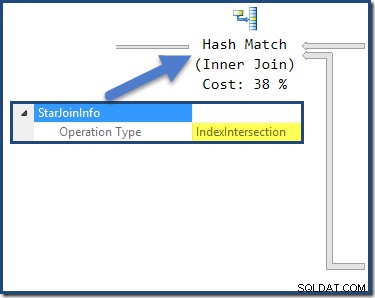
ハッシュ結合にはStarJoinInfoがあります インデックス交差を実行していることを示す構造(これもオプティマイザーによって製造されます):
StarJoinInfo 左端のネストされたループの結合は、行識別子によってファクトテーブルの行をフェッチするために生成されたことを示しています。これは、オプティマイザによって生成されたスター結合サブツリーのルートにあります:
デカルト積と複数列のインデックスルックアップ
スター結合の最適化の一部と見なされるインデックス交差プランは、単一列の非クラスター化インデックスがファクトテーブルの外部キーに存在する選択的なファクトテーブルクエリに役立ちます(一般的な設計手法)。
頻繁にクエリされる組み合わせに対して、ファクトテーブルの外部キーに複数列のインデックスを作成することも意味がある場合があります。組み込みの選択的スタークエリ最適化には、このシナリオの書き直しも含まれています。これがどのように機能するかを確認するには、次の複数列のインデックスをファクトテーブルに追加します。
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
テストクエリを再度コンパイルします:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; クエリプランには、インデックスの共通部分が含まれなくなりました(クリックして拡大):
ここで選択した戦略は、各述語をディメンションテーブルに適用し、結果のデカルト積を取得し、それを使用して複数列インデックスの両方のキーを検索することです。次に、クエリプランは、前に示したとおりに行識別子を使用して、ファクトテーブルへのキールックアップを実行します。
クエリプランは、パフォーマンスの最適化において、悪いことと見なされることが多い3つの機能(フルスキャン、デカルト積、およびキールックアップ)を組み合わせているため、特に興味深いものです。 。これは、2次元の積が非常に小さいと予想される場合に有効な戦略です。
StarJoinInfoはありません デカルト積の場合ですが、他の結合には情報があります(クリックして拡大):
インデックスフィルター
showplanスキーマに戻ると、もう1つStarJoinInfoがあります。 カバーする必要のある操作:
Index Filter 値は、ファクトテーブルをフェッチする前に実行する価値があるほど選択的であると見なされる結合で見られます。十分に選択的でない結合は、フェッチ後に実行され、StarJoinInfoはありません。 構造。
テストクエリを使用してインデックスフィルターを表示するには、3番目の結合テーブルをミックスに追加し、これまでに作成された非クラスター化ファクトテーブルインデックスを削除して、新しいインデックスを追加する必要があります。
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; クエリプランは次のようになります(クリックして拡大):
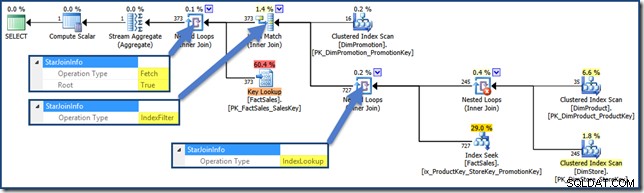
ヒープインデックス交差クエリプラン
完全を期すために、インデックス交差オプティマイザーの書き換えを有効にするために必要な2つの非クラスター化インデックスを使用してファクトテーブルのヒープコピーを作成するスクリプトを次に示します。
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; このクエリの実行プランには以前と同じ機能がありますが、インデックスの共通部分はファクトテーブルのクラスター化されたインデックスキーの代わりにRIDを使用して実行され、最後のフェッチはRIDルックアップです(クリックして展開):
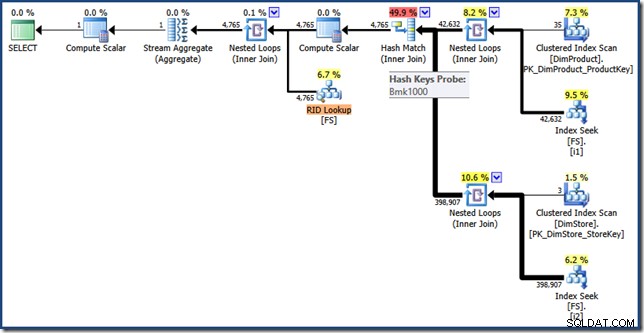
最終的な考え
ここに示されているオプティマイザーの書き換えは、比較的少数の行を返すクエリを対象としています。 大から ファクトテーブル。これらの書き換えは、2005年以降SQLServerのすべてのエディションで利用可能です。
データウェアハウジングでの選択的なスター(およびスノーフレーク)スキーマクエリを高速化することを目的としていますが、オプティマイザは、適切なテーブルと結合のセットを検出する場合は常に、これらの手法を適用できます。スタークエリの検出に使用されるヒューリスティックは非常に幅広いため、StarJoinInfoでプランの形状に遭遇する可能性があります ほぼすべてのタイプのデータベースの構造。より小さな(次元のような)テーブルへの参照を含む妥当なサイズ(たとえば100ページ以上)のテーブルは、これらの最適化の潜在的な候補です(明示的な外部キーはではないことに注意してください 必須)。
このようなことを楽しんでいる人のために、論理的なnテーブル結合から選択的なスター結合パターンを生成するオプティマイザールールは、 StarJoinToIdxStrategyと呼ばれます。 (スターはインデックス戦略に参加します。)