クエリの実行に時間がかかるのはなぜですか?なぜインデックスがないのですか? PostgreSQLのEXPLAINについて聞いたことがあるかもしれません。しかし、使い方がわからない人はまだまだたくさんいます。この記事が、ユーザーがこの優れたツールに取り組むのに役立つことを願っています。
この記事は、GuillaumeLelargeによるUnderstandingEXPLAINの著者改訂版です。いくつかの情報を見逃してしまったので、オリジナルに精通することを強くお勧めします。
悪魔は描かれているほど黒くはありません
クエリを最適化するには、PostgreSQLカーネルのロジックを理解することが重要です。説明しようと思います。それほど複雑ではありません。
EXPLAINは、特定のクエリごとにカーネルが行うことを説明する必要な情報を表示します。
EXPLAINコマンドが何を表示するかを見て、PostgreSQL内で正確に何が起こるかを理解しましょう。この情報はPostgreSQL9.2以降のバージョンに適用できます。
私たちのタスク:
- EXPLAINコマンドの出力を読んで理解する方法を学ぶ
- クエリが実行されたときにPostgreSQLで何が起こるかを理解する
最初のステップ
数百万行のテストテーブルで練習します。
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
データを読んでみてください
EXPLAIN SELECT * FROM foo;
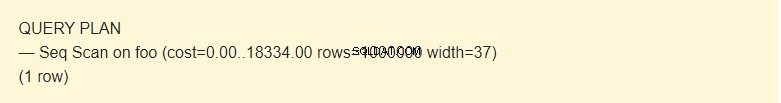
テーブルからデータを読み取る方法はいくつかあります。この場合、EXPLAINは、Seqスキャンが使用されたことを通知します—順次、ブロックごとに、Fooテーブルデータを読み取ります。
費用とは ?
さて、それは時間ではなく、操作のコストを見積もるために設計された概念です。最初の値0.00は、最初の行を取得するためのコストです。 2番目の値18334.00は、すべての行を取得するためのコストです。
行 SeqScan操作が実行されたときに返されるおおよその行数です。スケジューラーはこの値を返します。私の場合、テーブルの実際の行数と一致します。
幅 1行の平均サイズ(バイト単位)です。
10行追加してみましょう。
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

行の値は変更されていません。テーブルの統計は古いです。統計を更新するには、ANALYZEコマンドを呼び出します。
さて、行 正しい行数を表示します。
ANALYZEを実行するとどうなりますか?
- ランダムに、いくつかの行が選択され、テーブルから読み取られます。
- 各列の値の統計が収集されます。
ANALYZEが読み取る行数は、default_statistics_targetパラメータによって異なります。
実際のデータ
EXPLAINコマンドの出力で上で見たものはすべて、プランナーが期待するものです。それらを実際のデータの結果と比較してみましょう。これを行うには、EXPLAIN(ANALYZE)を使用します。
EXPLAIN (ANALYZE) SELECT * FROM foo;

このようなクエリは実際に実行されます。したがって、INSERT、DELETE、またはUPDATEステートメントに対してEXPLAIN(ANALYZE)を実行すると、データが変更されます。気をつけて!このような場合は、ROLLBACKコマンドを使用してください。
このコマンドは、次の追加パラメーターを表示します。
- 実際の時間は、それぞれ最初の行とすべての行を取得するために費やされたミリ秒単位の実際の時間です。
- rowsは、SeqScanで受信した実際の行数です。
- loopsは、SeqScan操作を実行する必要があった回数です。
- 合計実行時間は、クエリ実行の合計時間です。
さらに読む:
PostgreSQLでのクエリ最適化。 EXPLAINの基本–パート2
PostgreSQLでのクエリ最適化。 EXPLAINの基本–パート3