データベースの主要な要件の1つは、スケーラビリティを実現することです。これは、競合(ロック)を可能な限り最小限に抑えた場合にのみ達成できます。読み取り/書き込み/更新/削除はデータベースで頻繁に発生する主要な操作の一部であるため、これらの操作をブロックせずに同時に実行することが非常に重要です。これを実現するために、主要なデータベースのほとんどは、マルチバージョン同時実行制御と呼ばれる同時実行モデルを採用しています。 これにより、競合が最小限のレベルにまで減少します。
MVCCとは
マルチバージョン同時実行制御(以降、MVCC)は、READ操作とWRITE操作が競合しないように、同じオブジェクトの複数のバージョンを維持することにより、細かい同時実行制御を提供するアルゴリズムです。ここで、WRITEはUPDATEとDELETEを意味します。これは、新しく挿入されたレコードが分離レベルに従って保護されるためです。各WRITE操作はオブジェクトの新しいバージョンを生成し、各同時読み取り操作は分離レベルに応じて異なるバージョンのオブジェクトを読み取ります。読み取りと書き込みの両方が同じオブジェクトの異なるバージョンで動作するため、これらの操作はいずれも完全にロックする必要がなく、したがって両方を同時に動作させることができます。競合がまだ存在する可能性がある唯一のケースは、2つの同時トランザクションが同じレコードを書き込もうとした場合です。
現在の主要なデータベースのほとんどはMVCCをサポートしています。このアルゴリズムの目的は、同じオブジェクトの複数のバージョンを維持することであるため、MVCCの実装は、複数のバージョンが作成および維持される方法に関してのみデータベースごとに異なります。したがって、対応するデータベース操作とデータの保存が変更されます。
MVCCを実装するための最もよく知られているアプローチは、PostgreSQLとFirebird / Interbaseで使用されているアプローチであり、もう1つはInnoDBとOracleで使用されています。以降のセクションでは、PostgreSQLとInnoDBでどのように実装されているかについて詳しく説明します。
PostgreSQLのMVCC
複数のバージョンをサポートするために、PostgreSQLは、以下に説明するように、各オブジェクト(PostgreSQL用語ではタプル)の追加フィールドを維持します。
- xmin –タプルを挿入または更新したトランザクションのトランザクションID。 UPDATEの場合、タプルの新しいバージョンにこのトランザクションIDが割り当てられます。
- xmax –タプルを削除または更新したトランザクションのトランザクションID。 UPDATEの場合、現在存在するバージョンのタプルにこのトランザクションIDが割り当てられます。新しく作成されたタプルでは、このフィールドのデフォルト値はnullです。
PostgreSQLは、すべてのデータをHEAP(デフォルトのサイズは8KBのページ)と呼ばれるプライマリストレージに保存します。すべての新しいタプルは、それを作成したトランザクションとしてxminを取得し、古いバージョンのタプル(更新または削除された)にはxmaxが割り当てられます。古いバージョンのタプルから新しいバージョンへのリンクは常にあります。古いバージョンのタプルを使用して、ロールバックの場合にタプルを再作成したり、分離レベルに応じてREADステートメントで古いバージョンのタプルを読み取ったりすることができます。
テーブルにT1(値1)とT2(値2)の2つのタプルがあるとします。新しい行の作成は、以下の3つのステップで示すことができます。
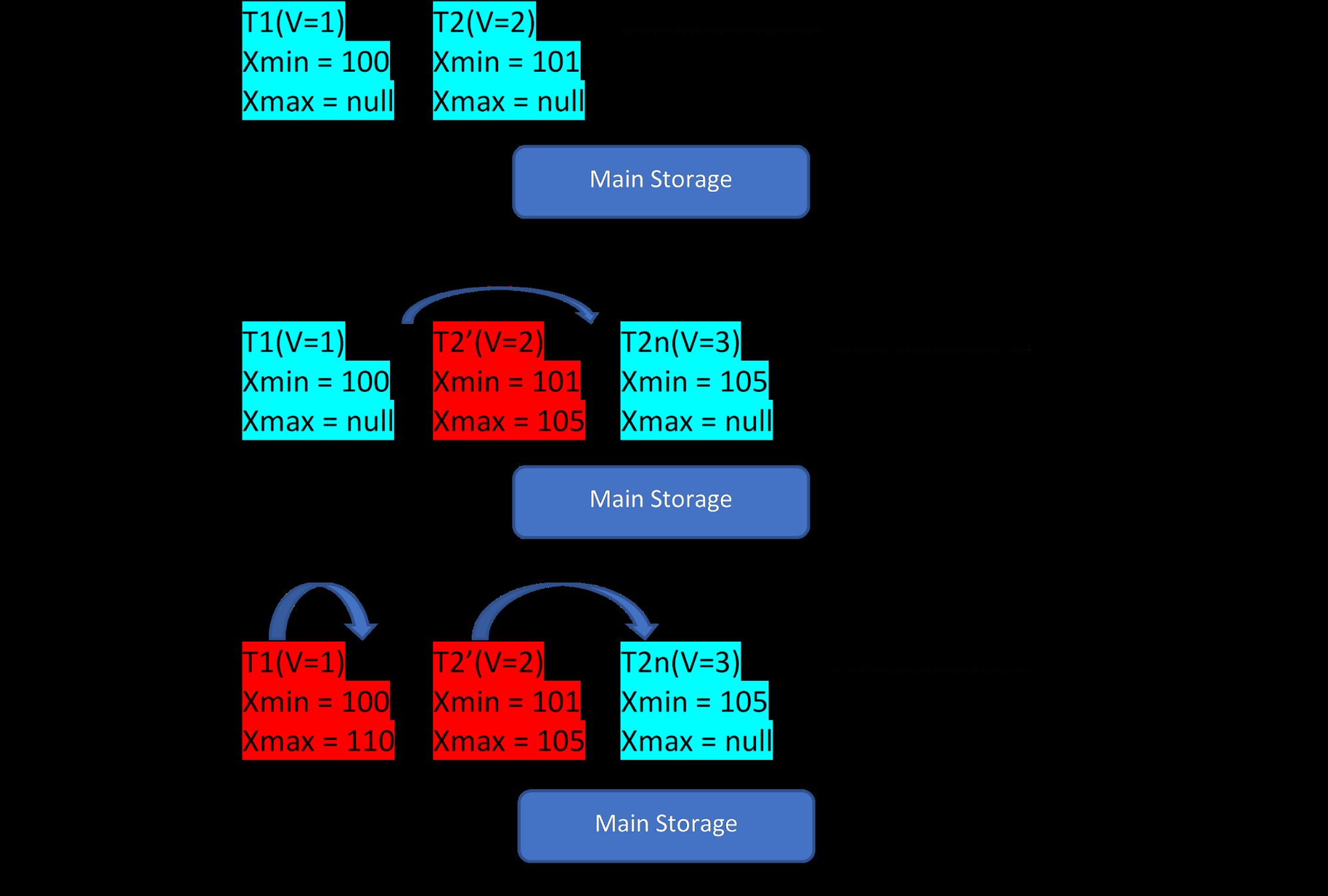 MVCC:PostgreSQLでの複数のバージョンの保存
MVCC:PostgreSQLでの複数のバージョンの保存 写真からわかるように、最初はデータベースに値1と2の2つのタプルがあります。
次に、2番目のステップに従って、値2の行T2が値3で更新されます。この時点で、新しいバージョンが新しい値で作成され、同じストレージ領域の既存のタプルの隣に格納されます。 。その前に、古いバージョンにはxmaxが割り当てられ、最新バージョンのタプルを指します。
同様に、3番目のステップでは、値1の行T1が削除されると、既存の行が同じ場所で仮想的に削除されます(つまり、現在のトランザクションにxmaxが割り当てられただけです)。このための新しいバージョンは作成されません。
次に、各操作で複数のバージョンが作成される方法と、実際の例を使用してロックせずにトランザクション分離レベルが維持される方法を見てみましょう。以下のすべての例では、デフォルトで「READCOMMITTED」分離が使用されています。
挿入
レコードが挿入されるたびに、新しいタプルが作成され、対応するテーブルに属するページの1つに追加されます。
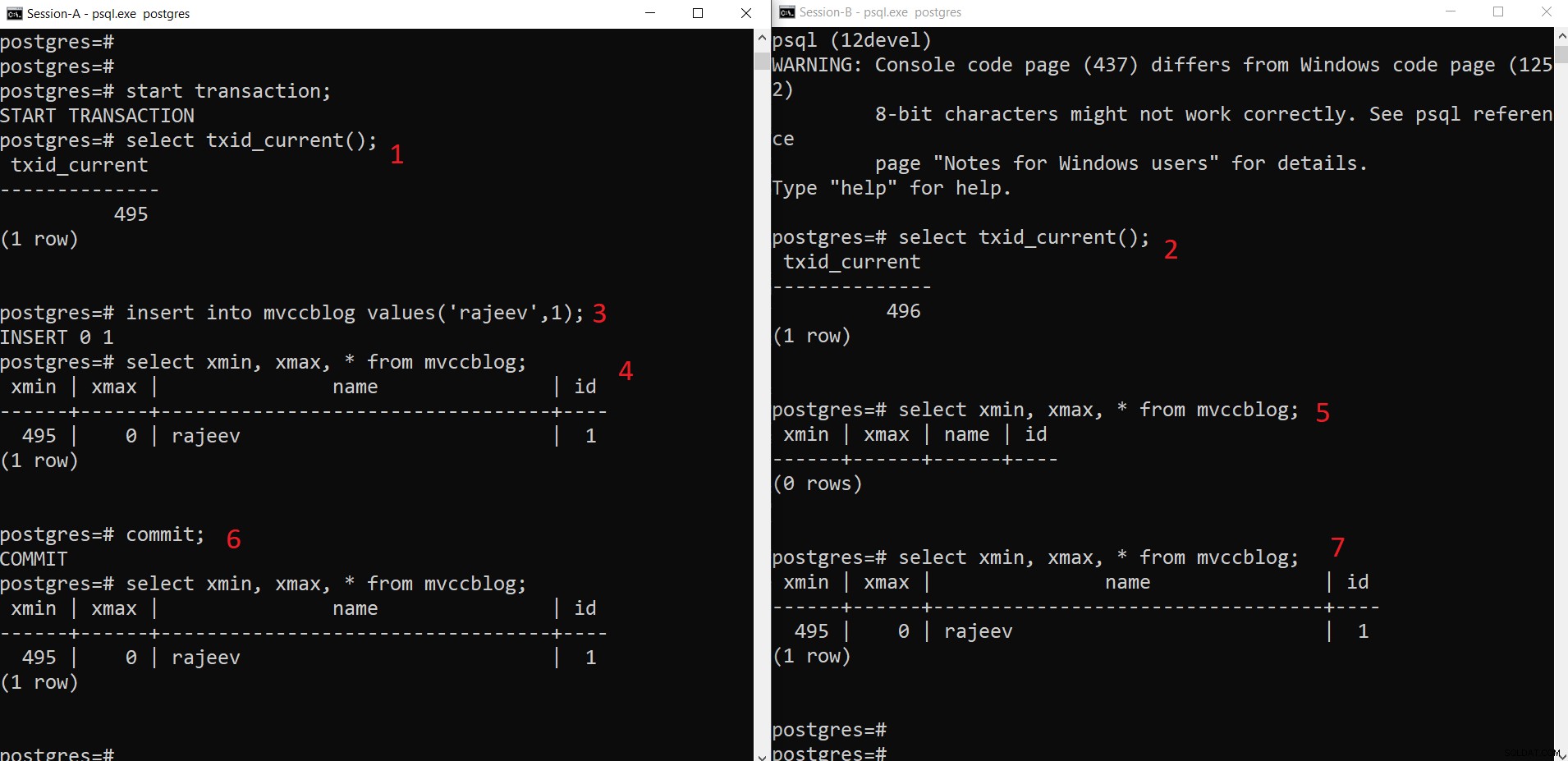 PostgreSQL同時INSERT操作
PostgreSQL同時INSERT操作 ここで段階的に見ることができるように:
- セッション-Aはトランザクションを開始し、トランザクションID495を取得します。
- セッションBはトランザクションを開始し、トランザクションID496を取得します。
- セッション-新しいタプルを挿入します(HEAPに格納されます)
- これで、xminが現在のトランザクションID495に設定された新しいタプルが追加されます。
- ただし、xmin(つまり、495)がまだコミットされていないため、Session-Bからは同じことが表示されません。
- コミットしたら。
- データは両方のセッションに表示されます。
更新
PostgreSQL UPDATEは「インプレース」更新ではありません。つまり、既存のオブジェクトを必要な新しい値で変更しません。代わりに、オブジェクトの新しいバージョンを作成します。したがって、UPDATEには以下の手順が広く含まれます。
- 現在のオブジェクトを削除済みとしてマークします。
- 次に、オブジェクトの新しいバージョンを追加します。
- オブジェクトの古いバージョンを新しいバージョンにリダイレクトします。
したがって、レコードの数は同じままですが、HEAPは、もう1つのレコードが挿入されたかのようにスペースを取ります。
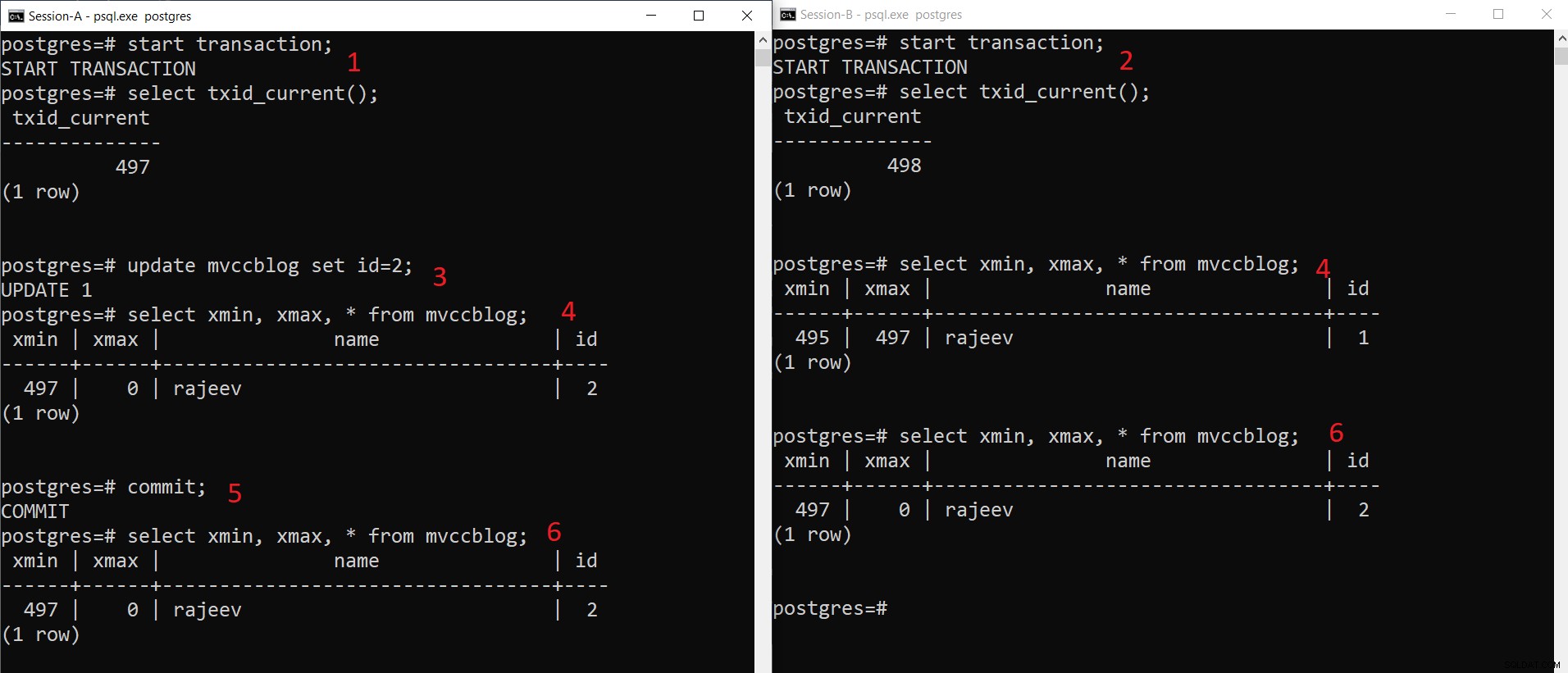 PostgreSQL同時INSERT操作
PostgreSQL同時INSERT操作 ここで段階的に見ることができるように:
- セッション-Aはトランザクションを開始し、トランザクションID497を取得します。
- セッションBはトランザクションを開始し、トランザクションID498を取得します。
- Session-Aは既存のレコードを更新します。
- ここで、Session-Aはタプルの1つのバージョン(更新されたタプル)を表示しますが、Session-Bは別のバージョン(古いタプルですがxmaxは497に設定されています)を表示します。両方のタプルバージョンがHEAPストレージに保存されます(空き容量によっては同じページでも)
- Session-Aがトランザクションをコミットすると、古いタプルのxmaxがコミットされると、古いタプルは期限切れになります。
- これで、両方のセッションに同じバージョンのレコードが表示されます。
削除
削除は、新しいバージョンを追加する必要がないことを除けば、UPDATE操作とほとんど同じです。 UPDATEの場合に説明するように、現在のオブジェクトをDELETEDとしてマークするだけです。
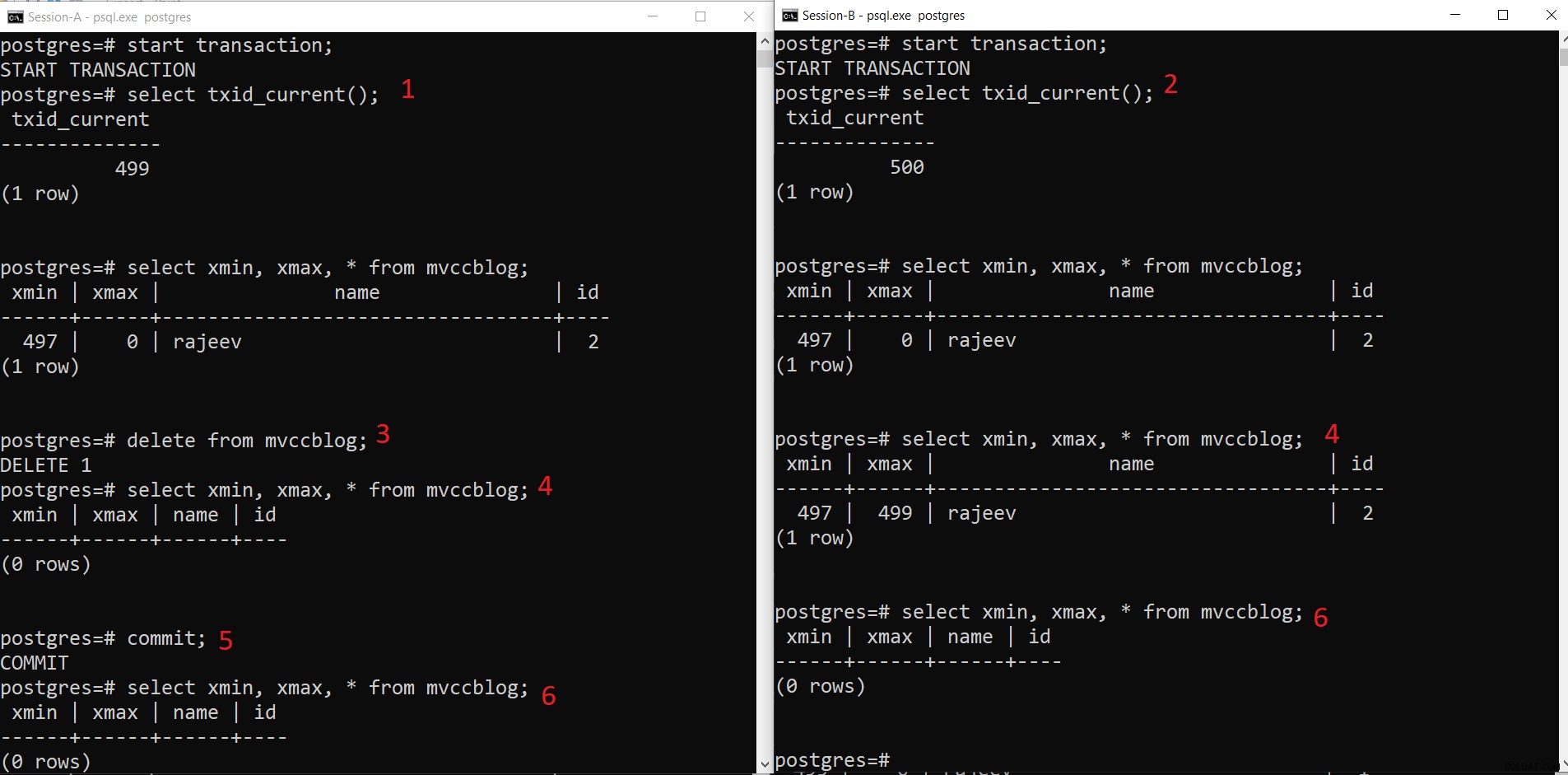 PostgreSQL同時DELETE操作
PostgreSQL同時DELETE操作 - セッション-Aはトランザクションを開始し、トランザクションID499を取得します。
- セッションBはトランザクションを開始し、トランザクションID500を取得します。
- Session-Aは既存のレコードを削除します。
- ここでSession-Aは、現在のトランザクションから削除されたタプルを認識しません。一方、Session-Bは古いバージョンのタプルを認識します(xmaxは499、このレコードを削除したトランザクション)。
- Session-Aがトランザクションをコミットすると、古いタプルのxmaxがコミットされると、古いタプルは期限切れになります。
- これで、両方のセッションで削除されたタプルが表示されなくなります。
ご覧のとおり、既存のバージョンのオブジェクトを直接削除する操作はなく、必要に応じてオブジェクトの追加バージョンを追加します。
次に、複数のバージョンを持つタプルでSELECTクエリがどのように実行されるかを見てみましょう。SELECTは、分離レベルに従って適切なタプルが見つかるまで、すべてのバージョンのタプルを読み取る必要があります。タプルT1があり、更新されて新しいバージョンT1’が作成され、更新時にT1’’が作成されたとします。
- SELECT操作は、このテーブルのヒープストレージを通過し、最初にT1をチェックします。 T1 xmaxトランザクションがコミットされると、このタプルの次のバージョンに移動します。
- T1のタプルxmaxもコミットされたとすると、再びこのタプルの次のバージョンに移動します。
- 最後に、T1’’を検出し、xmaxがコミットされていない(またはnull)こと、およびT1’’xminが分離レベルに従って現在のトランザクションに表示されていることを確認します。最後に、T1のタプルを読み取ります。
ご覧のとおり、有効期限が切れたタプルがガベージコレクター(VACUUM)によって削除されるまで、適切な表示タプルを見つけるために、タプルの3つのバージョンすべてをトラバースする必要があります。
InnoDBのMVCC
複数のバージョンをサポートするために、InnoDBは、以下に説明するように、各行に追加のフィールドを維持します。
- DB_TRX_ID:行を挿入または更新したトランザクションのトランザクションID。
- DB_ROLL_PTR:ロールポインタとも呼ばれ、ロールバックセグメントに書き込まれたログレコードを元に戻すことを指します(これについては次で詳しく説明します)。
PostgreSQLと同様に、InnoDBもすべての操作の一部として行の複数のバージョンを作成しますが、古いバージョンのストレージは異なります。
InnoDBの場合、変更された行の古いバージョンは、別のテーブルスペース/ストレージ(元に戻すセグメントと呼ばれます)に保持されます。 PostgreSQLとは異なり、InnoDBは最新バージョンの行のみをメインストレージ領域に保持し、古いバージョンは元に戻るセグメントに保持されます。 元に戻すセグメントの行バージョンは、ロールバックの場合に操作を元に戻すため、および分離レベルに応じてREADステートメントによって古いバージョンの行を読み取るために使用されます。
テーブルにT1(値1)とT2(値2)の2つの行があるとすると、新しい行の作成は次の3つの手順で示すことができます。
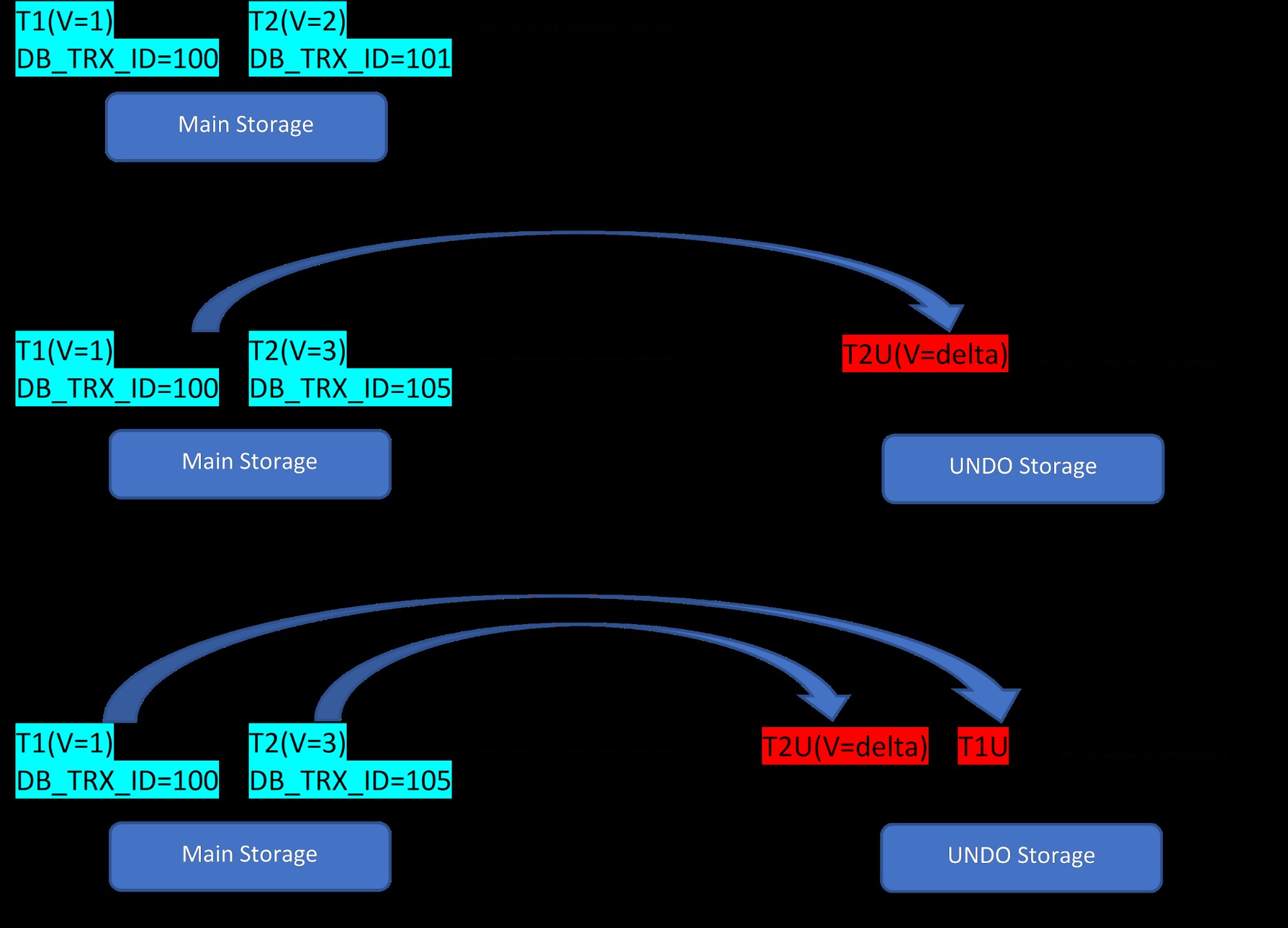 MVCC:InnoDBでの複数のバージョンのストレージ
MVCC:InnoDBでの複数のバージョンのストレージ 図からわかるように、最初はデータベースに値1と2の2つの行があります。
次に、第2段階に従って、値2の行T2が値3で更新されます。この時点で、新しいバージョンが新しい値で作成され、古いバージョンが置き換えられます。その前に、古いバージョンはUNDOセグメントに保存されます(UNDOセグメントバージョンにはデルタ値しかないことに注意してください)。また、ロールバックセグメントには、新しいバージョンから古いバージョンへのポインタが1つあることに注意してください。 PostgreSQLとは異なり、InnoDBの更新は「インプレース」です。
同様に、3番目のステップでは、値1の行T1が削除されると、既存の行がメインストレージ領域で仮想的に削除され(つまり、行の特別なビットをマークするだけです)、これに対応する新しいバージョンが追加されます。元に戻すセグメント。ここでも、メインストレージからUNDOセグメントへのロールポインタが1つあります。
外部から見ると、すべての操作はPostgreSQLの場合と同じように動作します。複数のバージョンの内部ストレージだけが異なります。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするMVCC:PostgreSQLとInnoDB
それでは、MVCCの実装に関してPostgreSQLとInnoDBの主な違いを分析してみましょう。
-
古いバージョンのサイズ
PostgreSQLは古いバージョンのタプルでxmaxを更新するだけなので、古いバージョンのサイズは対応する挿入されたレコードと同じままです。つまり、古いタプルのバージョンが3つある場合、それらはすべて同じサイズになります(更新ごとの実際のデータサイズの違いを除く)。
InnoDBの場合、Undoセグメントに格納されているオブジェクトのバージョンは、通常、対応する挿入されたレコードよりも小さくなります。これは、変更された値(つまり、差分)のみがUNDOログに書き込まれるためです。
-
INSERT操作
InnoDBはINSERTの場合でもUNDOセグメントに1つの追加レコードを書き込む必要がありますが、PostgreSQLはUPDATEの場合にのみ新しいバージョンを作成します。
-
ロールバックの場合に古いバージョンを復元する
ロールバックの場合に古いバージョンを復元するために、PostgreSQLは特別なことをする必要はありません。古いバージョンのxmaxは、このタプルを更新したトランザクションと同じであることを忘れないでください。したがって、このトランザクションIDがコミットされるまで、同時スナップショットのタプルは有効であると見なされます。トランザクションがロールバックされると、対応するトランザクションは中止されたトランザクションであるため、すべてのトランザクションで自動的に有効であると見なされます。
一方、InnoDBの場合、ロールバックが発生したら、オブジェクトの古いバージョンを再構築する必要があります。
-
古いバージョンが占有していたスペースの再利用
PostgreSQLの場合、古いバージョンが占めていたスペースは、このバージョンを読み取るための並列スナップショットがない場合にのみデッドと見なすことができます。古いバージョンが無効になると、VACUUM操作でそれらが占有していたスペースを再利用できます。 VACUUMは、構成に応じて手動またはバックグラウンドタスクとしてトリガーできます。
InnoDB UNDOログは、主にINSERTUNDOとUPDATEUNDOに分けられます。最初のトランザクションは、対応するトランザクションがコミットされるとすぐに破棄されます。 2つ目は、他のスナップショットと並列になるまで保持する必要があります。 InnoDBには明示的なVACUUM操作はありませんが、同様の行に、バックグラウンドタスクとして実行されるUNDOログを破棄する非同期PURGEがあります。
-
遅延真空の影響
前のポイントで説明したように、PostgreSQLの場合はバキュームの遅延による大きな影響があります。これにより、レコードが絶えず削除されていても、テーブルが肥大化し、ストレージスペースが増加します。また、VACUUM FULLを実行する必要があり、非常にコストのかかる操作になる可能性があります。
-
テーブルが肥大化した場合のシーケンシャルスキャン
PostgreSQLシーケンシャルスキャンは、オブジェクトのすべてが死んでいる場合でも(バキュームを使用して削除されるまで)、古いバージョンのオブジェクトをすべてトラバースする必要があります。これは、PostgreSQLの典型的で最も話題になっている問題です。 PostgreSQLはタプルのすべてのバージョンを同じストレージに保存することを忘れないでください。
一方、InnoDBの場合は、必要な場合を除いて、元に戻すレコードを読み取る必要はありません。すべての取り消しレコードが無効になっている場合は、最新バージョンのオブジェクトをすべて読み取るだけで十分です。
-
インデックス
PostgreSQLは、HEAPの実際のデータへの1つのリンクを保持する別のストレージにインデックスを格納します。そのため、INDEXに変更がなかったとしても、PostgreSQLはINDEX部分も更新する必要があります。後でこの問題はHOT(Heap Only Tuple)更新を実装することで修正されましたが、新しいヒープタプルを同じページに収容できない場合は、通常のUPDATEにフォールバックするという制限があります。
InnoDBはクラスター化されたインデックスを使用するため、この問題は発生しません。
結論
PostgreSQL MVCCには、ワークロードに頻繁なUPDATE / DELETEがある場合、特に肥大化したストレージに関していくつかの欠点があります。したがって、PostgreSQLを使用する場合は、VACUUMを適切に構成するように十分に注意する必要があります。
PostgreSQLコミュニティもこれを主要な問題として認識しており、UNDOベースのMVCCアプローチ(仮称はZHEAP)の作業をすでに開始しており、将来のリリースでも同じようになる可能性があります。