前回の記事では、EXPLAINコマンドの基本について説明し、クエリを実行したときにPostgreSQLで何が起こるかを分析しました。
PostgreSQLでのEXPLAINの基本について書き続けます。この情報は、GuillaumeLelargeによるUnderstandingEXPLAINの簡単なレビューです。一部の情報が欠落しているため、オリジナルを読むことを強くお勧めします。
キャッシュ
クエリを実行すると、物理レベルで何が起こりますか?それを理解しましょう。サーバーをUbuntu13.10にデプロイし、OSレベルのディスクキャッシュを使用しました。
PostgreSQLを停止し、ファイルシステムに変更をコミットし、キャッシュをクリアして、PostgreSQLを実行します:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
キャッシュがクリアされたら、BUFFERSオプションを使用してクエリを実行します
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

表をブロックごとに読み取ります。キャッシュは空です。ディスクからテーブル全体を読み取るには、8334ブロックにアクセスする必要がありました。
バッファ:共有読み取りは、PostgreSQLがディスクから読み取るブロックの数です。
前のクエリを実行します
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

バッファ:共有ヒットは、PostgreSQLキャッシュから取得されたブロックの数です。
クエリごとに、PostgreSQLはキャッシュからますます多くのデータを取得するため、独自のキャッシュがいっぱいになります。
キャッシュ読み取り操作は、ディスク読み取り操作よりも高速です。合計ランタイム値を追跡することで、この傾向を確認できます。
キャッシュストレージサイズは、postgresql.confファイルのshared_buffers定数によって定義されます。
どこ
クエリに条件を追加します
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
テーブルにインデックスはありません。クエリを実行すると、テーブルの各レコードが順番にスキャンされ(Seq Scan)、c1>500の状態と比較されます。条件が満たされると、レコードが結果に追加されます。それ以外の場合は破棄されます。フィルタは、この動作とコスト値の増加を示します。
推定行数が減少します。
元の記事では、コストがこの値をとる理由と、推定行数の計算方法について説明しています。
インデックスを作成する時が来ました。
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

推定行数が変更されました。インデックスはどうですか?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

100万を超える510行のみがフィルタリングされます。 PostgreSQLはテーブルの99.9%以上を読み取る必要がありました。
Seq Scanを無効にすることで、インデックスの使用を強制します:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

IndexScanおよびIndexCondでは、Filterの代わりにfoo_c1_idxインデックスが使用されます。
テーブル全体を選択する場合、インデックスを使用すると、クエリの実行にかかるコストと時間が増加します。
Seqスキャンを有効にする:
SET enable_seqscan TO on;
クエリを変更します:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
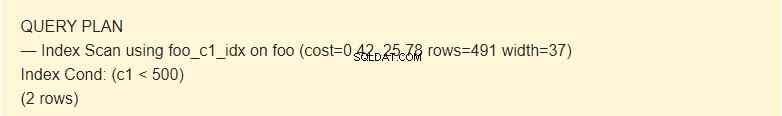
ここで、プランナーはインデックスを使用します。
それでは、テキストフィールドを追加して値を複雑にしましょう。
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

ご覧のとおり、foo_c1_idxインデックスはc1<500に使用されます。c2~~‘abcd%’ ::textを実行するには、フィルターを使用します。
結果の出力には、LIKE演算子のPOSIX形式が使用されていることに注意してください。条件にテキストフィールドしかない場合:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seqスキャンが適用されます。
c2でインデックスを作成します:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

テストフィールドのデータベースでUTF-8エンコーディングを使用しているため、インデックスは適用されません。
インデックスを作成するときは、text_pattern_ops演算子のクラスを指定する必要があります。
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

素晴らしい!うまくいきました!
ビットマップインデックススキャンは、foo_c2_idx1インデックスを使用して、必要なレコードを決定します。次に、PostgreSQLはテーブル(ビットマップヒープスキャン)に移動して、これらのレコードが実際に存在することを確認します。この動作はPostgreSQLのバージョン管理を指します。
行全体ではなく、インデックスが作成されるフィールドのみを選択した場合:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

テーブルの行を読み取る必要がないため、インデックスのみのスキャンはインデックススキャンよりも高速に実行されます:width=4。
結論
- SeqScanはテーブル全体を読み取ります
- インデックススキャンはWHEREステートメントのインデックスを使用し、行を選択するときにテーブルを読み取ります
- ビットマップインデックススキャンは、インデックススキャンとテーブル全体の選択制御を使用します。多数の行に効果的です。
- Index Only Scanは、インデックスのみを読み取る最速のブロックです。
さらに読む:
PostgreSQLでのクエリ最適化。 EXPLAINの基本–パート3