TeamCityは、Javaで構築された継続的インテグレーションおよび継続的デリバリーサーバーです。クラウドサービスおよびオンプレミスとして利用できます。ご想像のとおり、継続的インテグレーションおよびデリバリーツールはソフトウェア開発に不可欠であり、それらの可用性は影響を受けない必要があります。幸い、TeamCityは高可用性モードでデプロイできます。
このブログ投稿では、TeamCityの高可用性環境の準備と展開について説明します。
TeamCityはいくつかの要素で構成されています。 Javaアプリケーションとそれをバックアップするデータベースがあります。また、プライマリTeamCityインスタンスと通信しているエージェントも使用します。高可用性デプロイメントは、いくつかのTeamCityインスタンスで構成され、1つはプライマリとして機能し、他はセカンダリとして機能します。これらのインスタンスは、同じデータベースとデータディレクトリへのアクセスを共有します。以下に示すように、役立つスキーマはTeamCityのドキュメントページで入手できます。

ご覧のとおり、データディレクトリとデータディレクトリの2つの共有要素があります。データベース。それらも高可用性であることを確認する必要があります。共有マウントを構築するために使用できるさまざまなオプションがあります。ただし、GlusterFSを使用します。データベースについては、サポートされているリレーショナルデータベース管理システムの1つであるPostgreSQLを使用し、ClusterControlを使用してそれに基づいた高可用性スタックを構築します。
GlusterFSを構成する方法
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt update次に、すべてのTeamCityノードにGlusterFSをインストールできます。
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFSは、ノード間の接続にポート24007を使用します。すべてのノードが開いていてアクセスできることを確認する必要があります。
接続が確立されたら、1つのノードから実行してGlusterFSクラスターを作成できます。
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.これで、ステータスがどのようになるかをテストできます:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)すべてが良好で、接続が確立されているようです。
次に、GlusterFSで使用するブロックデバイスを準備する必要があります。これは、すべてのノードで実行する必要があります。まず、パーティションを作成します:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.次に、そのパーティションをフォーマットします:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0最後に、すべてのノードで、パーティションのマウントに使用するディレクトリを作成し、起動時にマウントされるようにfstabを編集する必要があります。
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabexample@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)これで、ノードの1つを使用してGlusterFSボリュームを作成および開始できます。
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successボリュームが開始されると、ステータスを確認できます:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksご覧のとおり、すべて問題ないようです。重要なのは、GlusterFSがそのボリュームにアクセスするためにポート49152を選択したことです。また、マウントするすべてのノードでポート49152に到達できることを確認する必要があります。
次のステップは、GlusterFSクライアントパッケージをインストールすることです。この例では、GlusterFSサーバーと同じノードにインストールする必要があります。
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.次に、TeamCityの共有データディレクトリとして使用するディレクトリをすべてのノードに作成する必要があります。これはすべてのノードで発生する必要があります:
example@sqldat.com:~# sudo mkdir /teamcity-storage最後に、すべてのノードにGlusterFSボリュームをマウントします。
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageTeamCityの共有ストレージのセットアップが完了すると、高可用性データベースインフラストラクチャを構築できるようになります。 TeamCityはさまざまなデータベースを使用できます。ただし、このブログではPostgreSQLを使用します。 ClusterControlを活用して、データベース環境を展開して管理します。
マルチノード展開を構築するためのTeamCityのガイドは役立ちますが、TeamCity以外のすべての高可用性を除外しているようです。 TeamCityのガイドでは、データストレージ用のNFSまたはSMBサーバーが提案されています。これらのサーバー自体には冗長性がなく、単一障害点になります。 GlusterFSを使用してこれに対処しました。単一のデータベースノードは明らかに高可用性を提供しないため、共有データベースについて言及しています。適切なスタックを構築する必要があります:

この場合。これは、3つのPostgreSQLノード、1つのプライマリ、および2つのレプリカで構成されます。 HAProxyをロードバランサーとして使用し、Keepalivedを使用して仮想IPを管理し、アプリケーションが接続する単一のエンドポイントを提供します。 ClusterControlは、レプリケーショントポロジを監視し、障害が発生したプロセスを再起動したり、プライマリノードがダウンした場合にレプリカの1つにフェイルオーバーしたりするなど、必要に応じて必要なリカバリを実行することで障害を処理します。
まず、データベースノードをデプロイします。 ClusterControlには、ClusterControlノードからそれが管理するすべてのノードへのSSH接続が必要であることに注意してください。

次に、接続に使用するユーザーを選択します。データベース、そのパスワード、およびデプロイするPostgreSQLのバージョン:

次に、PostgreSQLのデプロイに使用するノードを定義します:
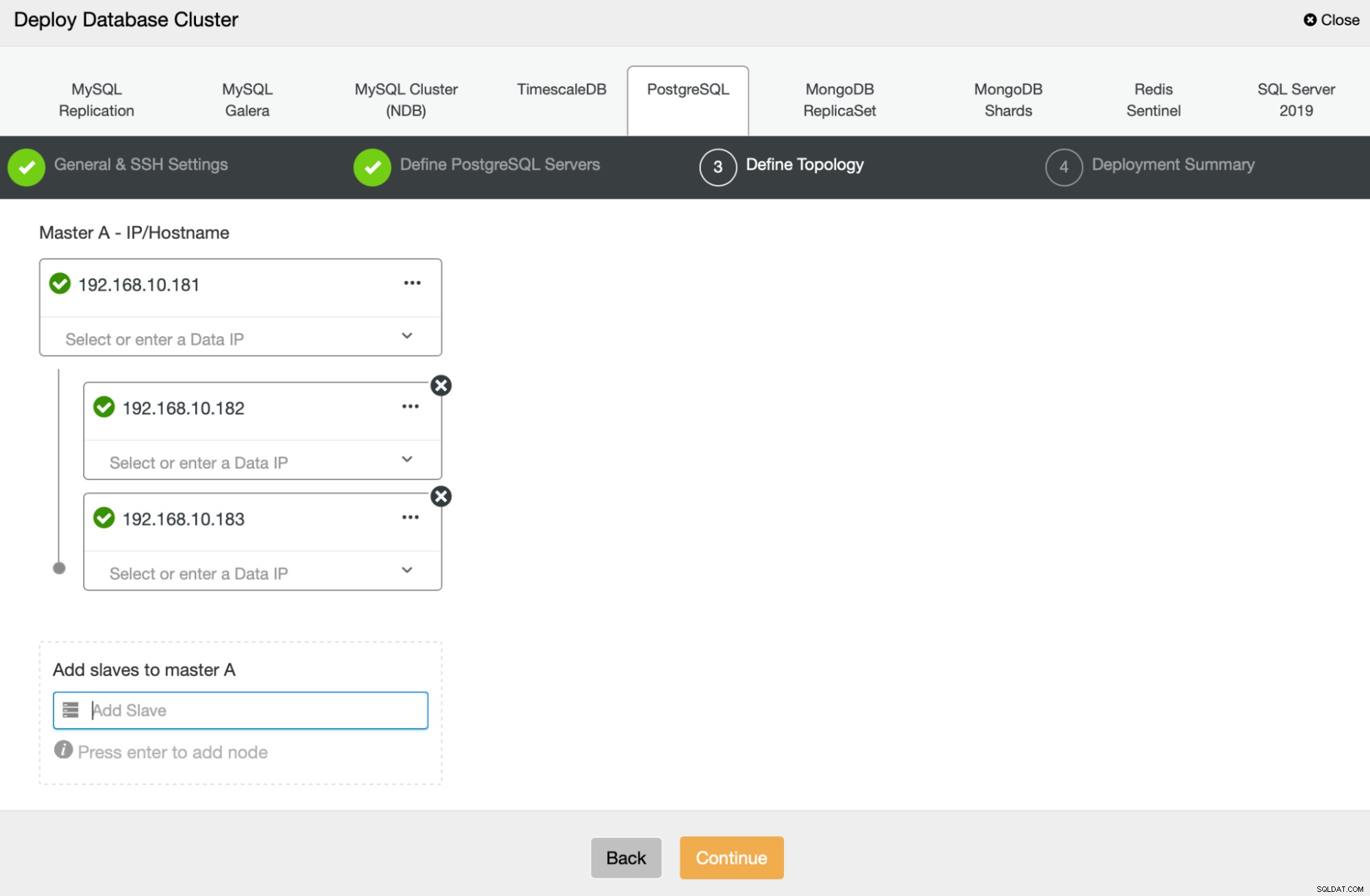
最後に、ノードで非同期レプリケーションと同期レプリケーションのどちらを使用するかを定義できます。これら2つの主な違いは、同期レプリケーションにより、プライマリノードで実行されるすべてのトランザクションが常にレプリカにレプリケートされるようになることです。ただし、同期レプリケーションはコミットの速度も低下させます。最高の耐久性を得るために同期レプリケーションを有効にすることをお勧めしますが、パフォーマンスが許容できるかどうかは後で確認する必要があります。

[デプロイ]をクリックすると、デプロイジョブが開始されます。 ClusterControlUIの[アクティビティ]タブで進行状況を監視できます。最終的に、ジョブが完了し、クラスターが正常にデプロイされたことがわかります。

[管理]->[ロードバランサー]に移動してHAProxyインスタンスをデプロイします。ロードバランサーとしてHAProxyを選択し、フォームに入力します。最も重要な選択は、HAProxyをデプロイする場所です。この場合はデータベースノードを使用しましたが、実稼働環境では、ロードバランサーをデータベースインスタンスから分離することをお勧めします。次に、HAProxyに含めるPostgreSQLノードを選択します。それらすべてが必要です。

これで、HAProxyの展開が開始されます。これを少なくとももう一度繰り返して、冗長性のために2つのHAProxyインスタンスを作成します。この展開では、3つのHAProxyロードバランサーを使用することにしました。以下は、2番目のHAProxyのデプロイメントを構成する際の設定画面のスクリーンショットです。
すべてのHAProxyインスタンスが稼働している場合、Keepalivedをデプロイできます。ここでの考え方は、KeepalivedをHAProxyと併置し、HAProxyのプロセスを監視することです。 HAProxyが機能しているインスタンスの1つに、仮想IPが割り当てられます。このVIPは、アプリケーションがデータベースに接続するために使用する必要があります。 Keepalivedは、そのHAProxyが使用できなくなったかどうかを検出し、使用可能な別のHAProxyインスタンスに移動します。
デプロイメントウィザードでは、Keepalivedで監視するHAProxyインスタンスを渡す必要があります。また、VIPのIPアドレスとネットワークインターフェースを渡す必要があります。

最後の最後のステップは、TeamCityのデータベースを作成することです。

これで、高可用性PostgreSQLクラスターの展開が完了しました。
次のステップは、TeamCityをマルチノード環境にデプロイすることです。 3つのTeamCityノードを使用します。まず、TeamCityの要件に一致するJavaJREとJDKをインストールする必要があります。
apt install default-jre default-jdkこれで、すべてのノードでTeamCityをダウンロードする必要があります。共有ディレクトリではなく、ローカルにインストールします。
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gz次に、ノードの1つでTeamCityを起動できます:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logTeamCityが開始されると、UIにアクセスして展開を開始できます。最初に、データディレクトリの場所を渡す必要があります。これは、GlusterFSで作成した共有ボリュームです。

次に、データベースを選択します。すでに作成したPostgreSQLクラスターを使用します。

JDBCドライバーをダウンロードしてインストールします:

次に、アクセスの詳細を入力します。 Keepalivedが提供する仮想IPを使用します。ポート5433を使用していることに注意してください。これは、HAProxyの読み取り/書き込みバックエンドに使用されるポートです。常にアクティブなプライマリノードを指します。次に、TeamCityで使用するユーザーとデータベースを選択します。

これが完了すると、TeamCityはデータベース構造の初期化を開始します。

ライセンス契約に同意します:

最後に、TeamCityのユーザーを作成します。

以上です!これで、TeamCityGUIが表示されるはずです。

次に、TeamCityをマルチノードモードで設定する必要があります。まず、すべてのノードで起動スクリプトを編集する必要があります。
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shexport TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"これが完了すると、残りのノードを開始できます:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
TeamCityでのフェイルオーバーは自動化されていないことに注意してください。メインノードが機能しなくなった場合は、セカンダリノードの1つに接続する必要があります。これを行うには、[ノードの構成]に移動して、[メイン]ノードにプロモートします。ログイン画面から、これがセカンダリノードであることが明確に示されます。

[ノードの構成]で、1つのノードにクラスタから削除されました:

このノードに書き込めないことを示すメッセージが表示されます。心配しないで;このノードを「メイン」ステータスにプロモートするために必要な書き込みは正常に機能します:

[有効にする]をクリックすると、セカンダリTimeCityノードが正常にプロモートされました。

node1が使用可能になり、そのノードでTeamCityが再開されると、クラスターに再参加することを確認してください:

パフォーマンスをさらに向上させたい場合は、TeamCityUIの前にHAProxy+ Keepalivedをデプロイして、GUIへの単一のエントリポイントを提供できます。 TeamCity用のHAProxyの構成の詳細については、ドキュメントを参照してください。
ご覧のとおり、高可用性のためにTeamCityをデプロイすることはそれほど難しくありません。そのほとんどは、ドキュメントで完全に説明されています。この一部を自動化し、高可用性データベースバックエンドを追加する方法を探している場合は、ClusterControlを30日間無料で評価することを検討してください。 ClusterControlは、バックエンドを迅速に展開および監視し、自動フェイルオーバー、リカバリ、監視、バックアップ管理などを提供します。
ソフトウェア開発ツールとベストプラクティスに関するその他のヒントについては、データベースのニーズでDevOpsチームをサポートする方法を確認してください。
オープンソースベースのデータベースインフラストラクチャを管理するための最新ニュースとベストプラクティスを入手するには、TwitterまたはLinkedInでフォローし、ニュースレターを購読することを忘れないでください。またね!