このブログの最初の部分では、優れたPostgreSQLレプリケーション環境に関連するいくつかの重要な概念について説明しました。それでは、ClusterControlを使用してこれらすべてを簡単な方法で組み合わせる方法を見てみましょう。このため、ClusterControlがインストールされていることを前提としていますが、インストールされていない場合は、公式サイトにアクセスするか、公式ドキュメントを参照してインストールしてください。
PostgreSQLストリーミングレプリケーションの導入
ClusterControlからPostgreSQLクラスターのデプロイを実行するには、[デプロイ]オプションを選択し、表示される指示に従います。
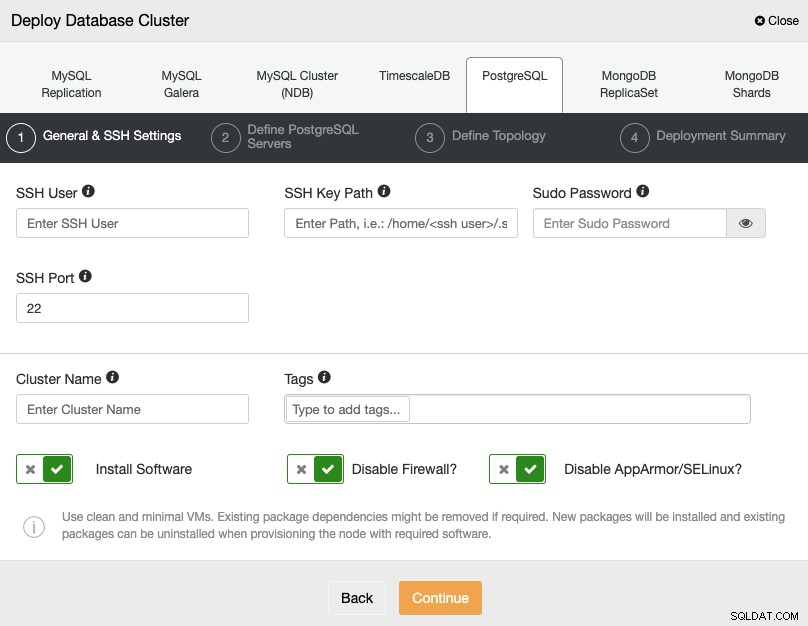
PostgreSQLを選択するときは、ユーザー、キー、またはパスワードを指定する必要があります。 SSHでサーバーに接続するためのポート。新しいクラスターの名前を追加し、ClusterControlに対応するソフトウェアと構成をインストールするかどうかを指定することもできます。
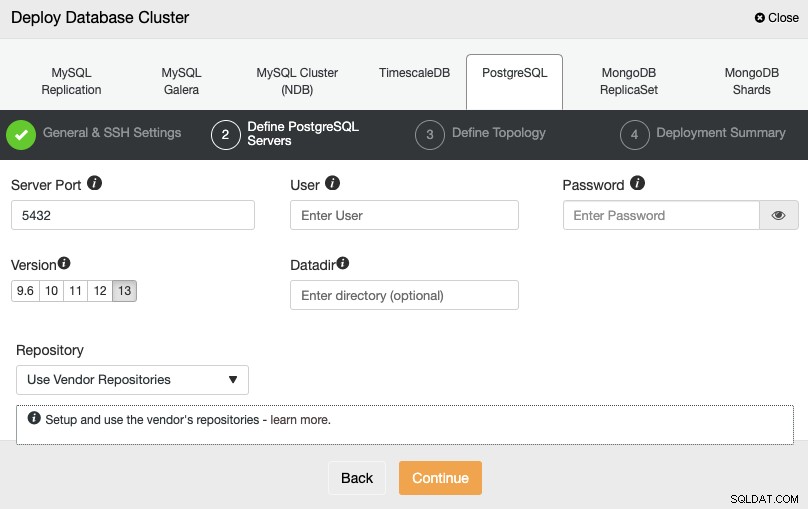
SSHアクセス情報を設定した後、データベースの資格情報を定義する必要があります、version、およびdatadir(オプション)。使用するリポジトリを指定することもできます。
次のステップでは、IPアドレスまたはホスト名を使用して作成するクラスターにサーバーを追加する必要があります。
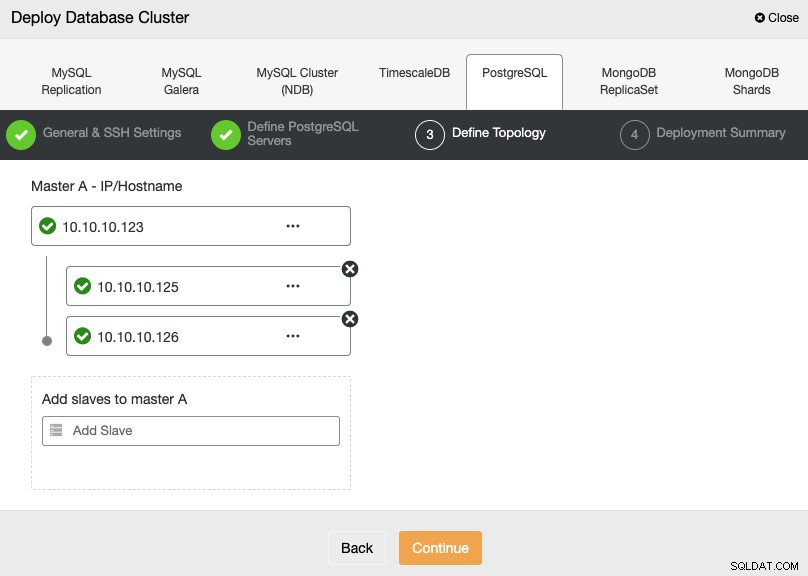
最後のステップで、レプリケーションを同期にするか、同期するかを選択できます。非同期で、[デプロイ]を押すだけです。
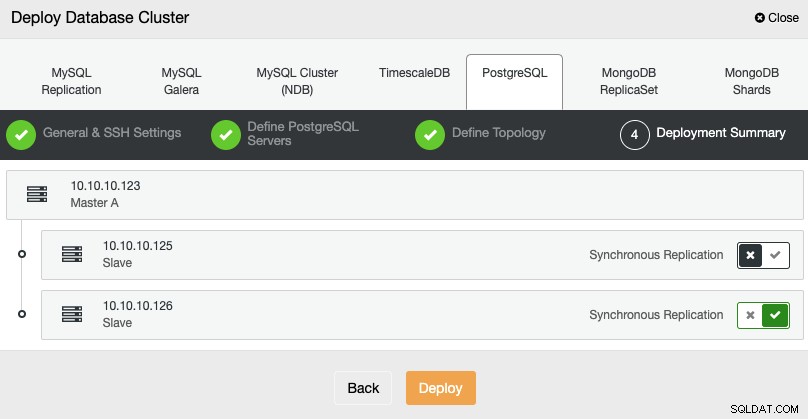
タスクが完了すると、新しいPostgreSQLクラスターがClusterControlのメイン画面。

これでクラスターが作成されたので、クラスターに対していくつかのタスクを実行できます。ロードバランサー(HAProxy)、接続プール(PgBouncer)、または新しい同期または非同期レプリケーションスレーブを追加するようなものです。
ClusterControl->クラスターアクション->レプリケーションスレーブの追加に移動します。
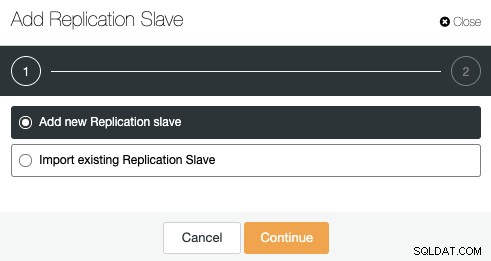
新しいレプリケーションスレーブを追加したり、既存のレプリケーションスレーブをインポートしたりすることもできます。最初のオプションを選択して続行しましょう。
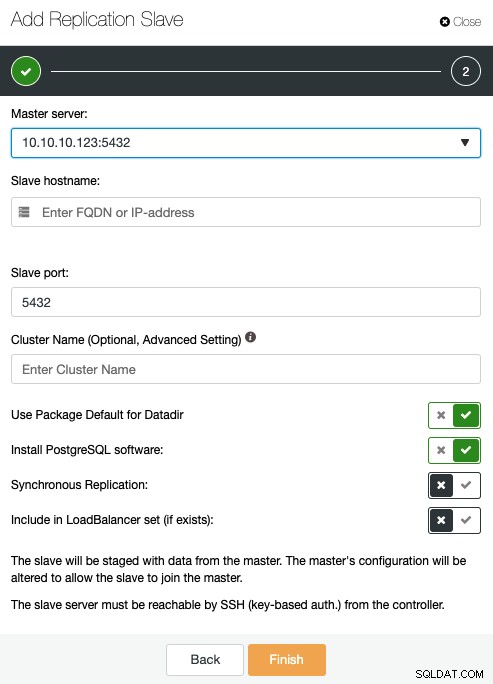
ここでは、マスターサーバー、IPアドレス、またはホスト名を指定する必要があります。新しいレプリケーションスレーブ、ポート、およびClusterControlでソフトウェアをインストールするか、このノードを既存のロードバランサーに含める場合。レプリケーションを同期または非同期に構成することもできます。
これで、対応するレプリカを備えたPostgreSQLクラスターが配置されました。接続プールを追加して、パフォーマンスを向上させる方法を見てみましょう。
PgBouncerの展開
ClusterControlに移動->PostgreSQLCluster-> Cluster Actions-> Add LoadBalancer->PgBouncerを選択します。ここでは、選択したデータベースノードにデプロイされる新しいPgBouncerノードをデプロイしたり、既存のPgBouncerをインポートしたりすることもできます。
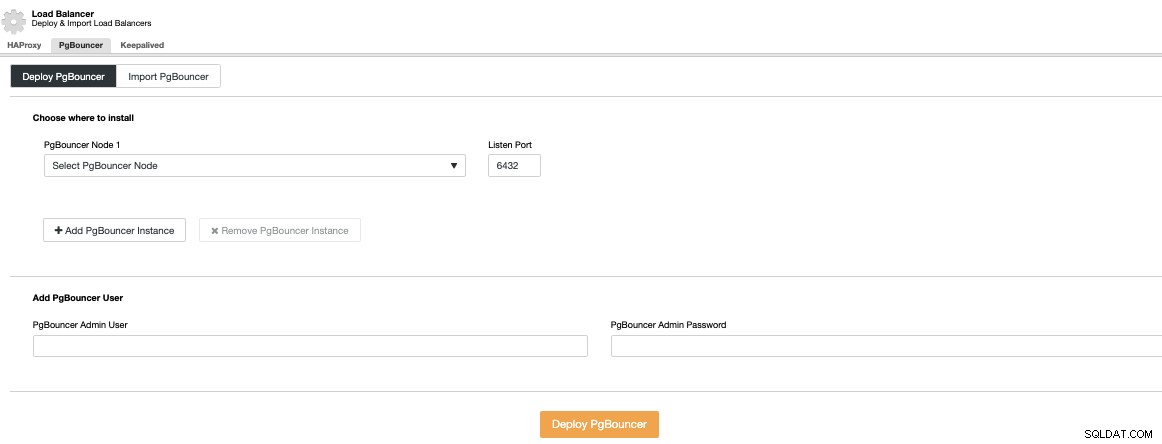
IPアドレスまたはホスト名、リッスンポート、およびPgBouncerの資格情報。 Deploy PgBouncerを押すと、ClusterControlはノードにアクセスし、手動で介入することなくすべてをインストールして構成します。
ClusterControlアクティビティセクションで進行状況を監視できます。終了したら、新しいプールを作成する必要があります。これを行うには、ClusterControl->PostgreSQLクラスターの選択->ノード->PgBouncerノードに移動します。
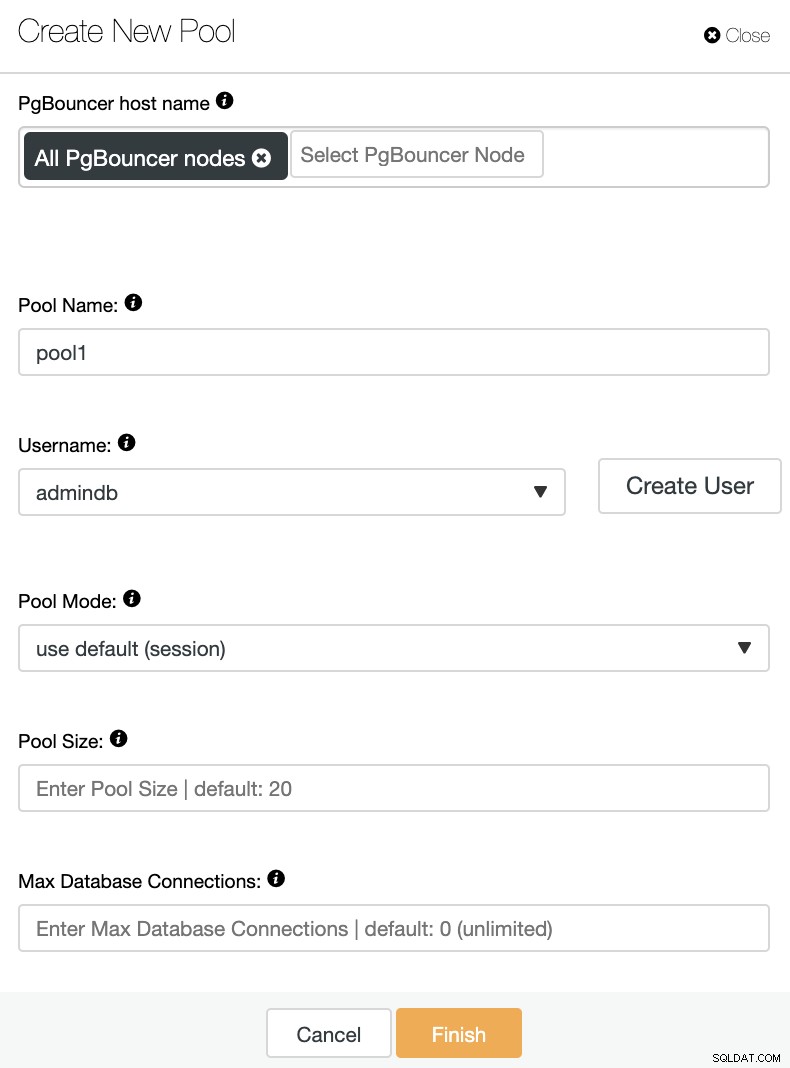
次の情報を追加する必要があります:
-
PgBouncerホスト名:接続プールを作成するノードホストを選択します。
-
プール名:プール名とデータベース名は同じである必要があります。
-
ユーザー名:PostgreSQLプライマリノードからユーザーを選択するか、新しいユーザーを作成します。
-
プールモード:セッション(デフォルト)、トランザクション、またはステートメントプーリングのいずれかになります。
-
プールサイズ:このデータベースのプールの最大サイズ。デフォルト値は20です。
-
データベース接続の最大数:データベース全体の最大数を構成します。デフォルト値は0で、無制限を意味します。
これで、ノードセクションにプールが表示されるはずです。
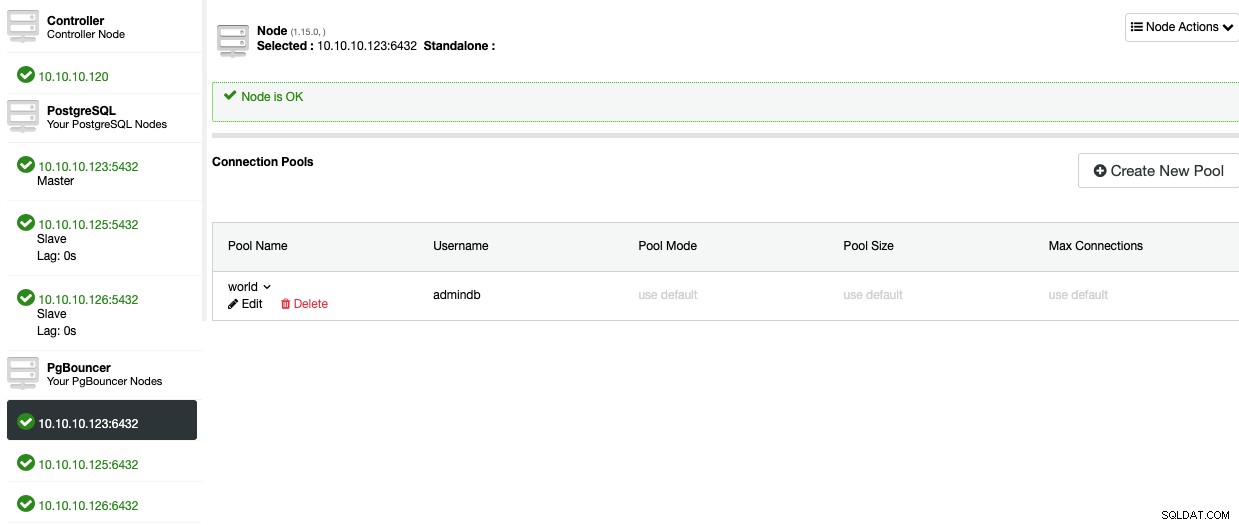
PostgreSQLデータベースに高可用性を追加するには、ロードバランサー。
ロードバランサーの展開を実行するには、[クラスターアクション]メニューで[ロードバランサーの追加]オプションを選択し、要求された情報を入力します。
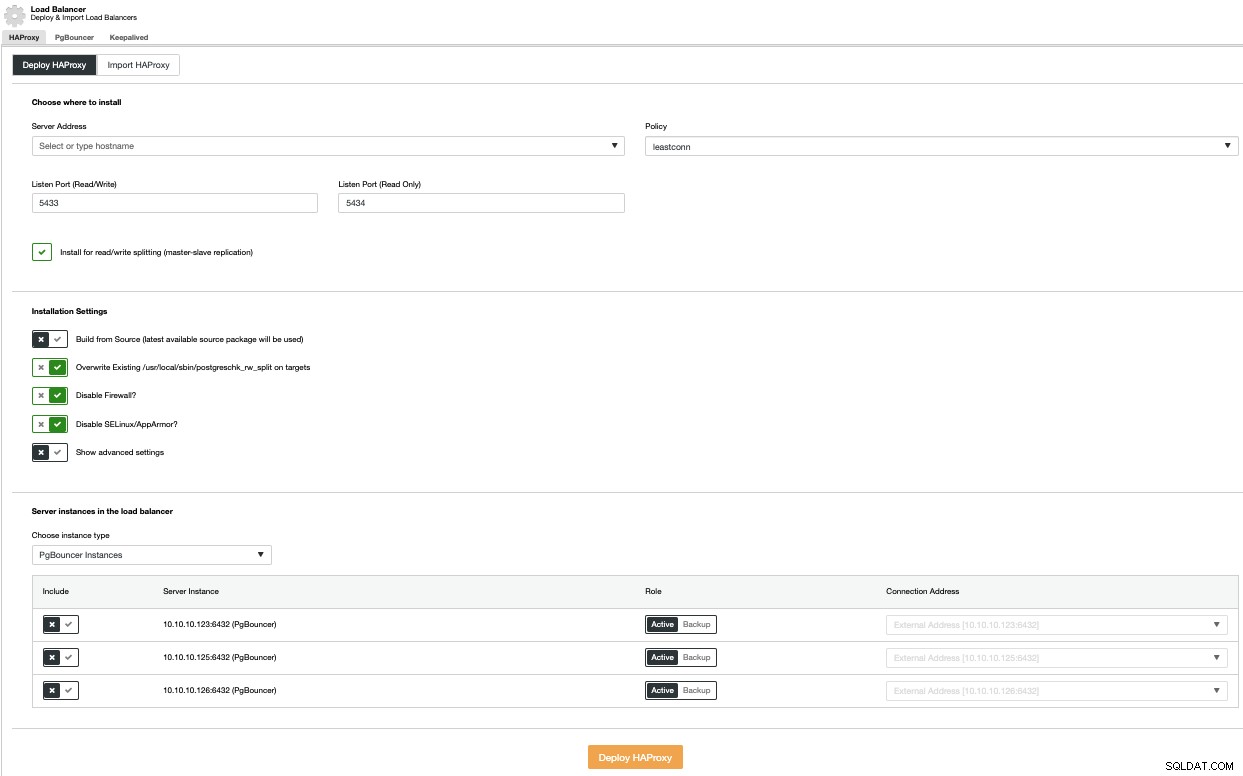
IPまたはホスト名、ポート、ポリシー、およびノードを追加する必要があります使用します。 PgBouncerを使用している場合は、インスタンスタイプのコンボボックスで選択できます。
単一障害点を回避するには、少なくとも2つのHAProxyノードをデプロイし、Keepalivedを使用して、アクティブなHAProxyノードに割り当てられているアプリケーションで仮想IPアドレスを使用できるようにする必要があります。このノードに障害が発生した場合、仮想IPアドレスはセカンダリロードバランサーに移行されるため、アプリケーションは引き続き通常どおりに機能します。
キープアライブ展開を実行するには、[クラスターアクション]メニューで[ロードバランサーの追加]オプションを選択してから、[キープアライブ]タブに移動します。
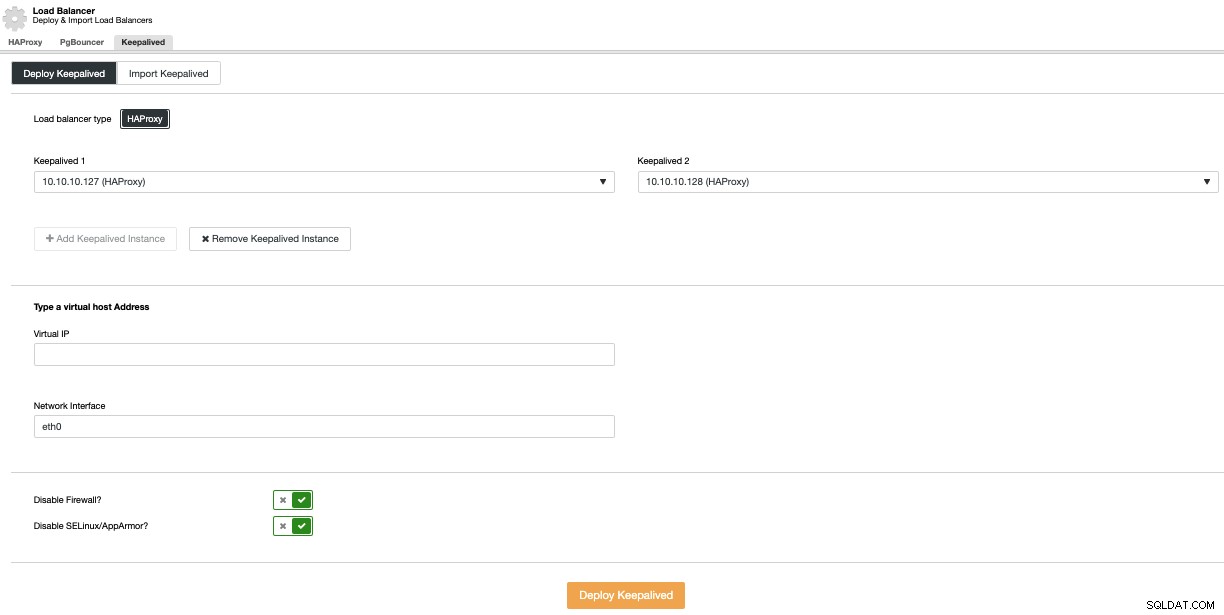
ここで、HAProxyノードを選択し、仮想IPアドレスを指定します。データベース(または接続プール)にアクセスするために使用されます。
現時点では、次のトポロジが必要です。
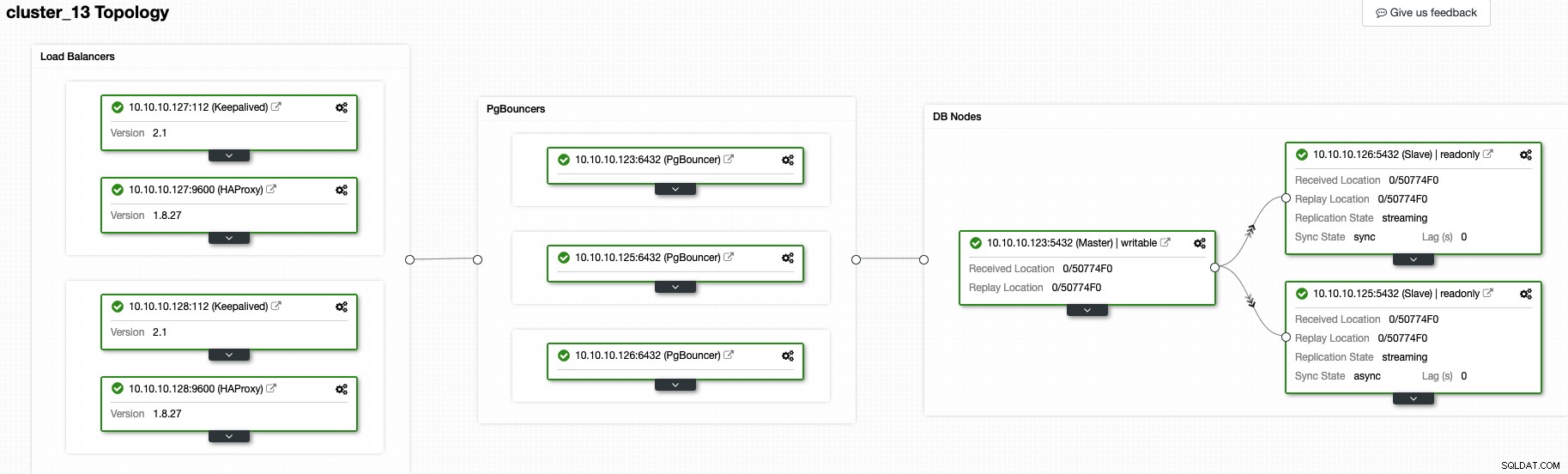
つまり、HAProxy + Keepalived->PgBouncer->PostgreSQLデータベースノード、これはPostgreSQLクラスターに適したトポロジです。
ClusterControl自動回復機能
障害が発生した場合、ClusterControlは最も高度なスタンバイノードをプライマリに昇格させ、問題を通知します。また、スタンバイノードの残りの部分をフェイルオーバーして、新しいプライマリサーバーから複製します。
デフォルトでは、HAProxyは読み取り/書き込みと読み取り専用の2つの異なるポートで構成されています。読み取り/書き込みポートでは、プライマリデータベース(またはPgBouncer)ノードがオンラインで、残りのノードはオフラインであり、読み取り専用ポートでは、プライマリノードとスタンバイノードの両方がオンラインです。
>HAProxyは、ノードの1つにアクセスできないことを検出すると、自動的にそのノードをオフラインとしてマークし、トラフィックの送信を考慮しません。検出は、デプロイメント時にClusterControlによって構成されたヘルスチェックスクリプトによって実行されます。これらは、インスタンスが稼働しているかどうか、回復中かどうか、または読み取り専用かどうかを確認します。
ClusterControlがスタンバイノードをプロモートすると、HAProxyは両方のポートで古いプライマリをオフラインとしてマークし、プロモートされたノードを読み取り/書き込みポートでオンラインにします。
システムが接続する仮想IPアドレスが割り当てられているアクティブなHAProxyに障害が発生した場合、KeepalivedはこのIPアドレスをパッシブなHAProxyに自動的に移行します。これは、システムが正常に機能し続けることができることを意味します。
ご覧のとおり、ClusterControlを使用し、PostgreSQLレプリケーションの基本的なベストプラクティスの概念に従っている場合は、優れたPostgreSQLトポロジを簡単に作成できます。もちろん、最適な環境はワークロード、ハードウェア、アプリケーションなどによって異なりますが、例として使用して、必要に応じてピースを移動することができます。