2つ以上のデータセットの連結は、最も一般的にはUNION ALLを使用してT-SQLで表現されます。 句。 SQL Serverオプティマイザーは、パフォーマンスを向上させるために結合や集計などを並べ替えることができることが多いため、SQL Serverが連結入力の並べ替えも検討することは非常に合理的であり、これにより利点が得られます。たとえば、オプティマイザはA UNION ALL Bを書き換えることの利点を検討できます。 B UNION ALL Aとして 。
実際、SQLServerオプティマイザはしません これを行う。より正確には、2008R2までのSQLServerリリースでは、連結入力の並べ替えのサポートが制限されていましたが、これは削除されました SQL Server 2012で使用されており、それ以降は再表示されていません。
SQL Server 2008 R2
直感的には、連結入力の順序は、行の目標がある場合にのみ重要です。 。既定では、SQL Serverは、対象となるすべての行がクライアントに返されることに基づいて実行プランを最適化します。行の目標が有効な場合、オプティマイザーは最初の数行をすばやく生成する実行プランを見つけようとします。
行の目標は、たとえばTOPを使用するなど、さまざまな方法で設定できます。 、FAST n ヒントを照会するか、EXISTSを使用します (その性質上、最大で1つの行を見つける必要があります)。行の目標がない場合(つまり、クライアントがすべての行を必要とする場合)、通常、連結入力が読み取られる順序は重要ではありません。各入力は、いずれの場合も最終的に完全に処理されます。
SQL Server 2008 R2までのバージョンでの制限付きサポートは、正確に1行という目標がある場合に適用されます。 。この特定の状況では、SQLServerは予想されるコストに基づいて連結入力を並べ替えます。
これは、コストベースの最適化中には行われず(予想されるように)、通常のオプティマイザー出力の最適化後の土壇場での書き換えとして行われます。この配置には、最初の行をすばやく返すように最適化されたプランを作成しながら、コストベースのプラン検索スペースを増やさないという利点があります(可能な並べ替えごとに1つの選択肢になる可能性があります)。
例
次の例では、内容が同じ2つのテーブルを使用しています。1から100万までの100万行の整数。 1つのテーブルは、非クラスター化インデックスのないヒープです。もう1つは、一意のクラスター化されたインデックスを持っています:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); 行の目標なし
次のクエリは、各テーブルで同じ行を検索し、2つのセットの連結を返します。
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; クエリオプティマイザによって作成される実行プランは次のとおりです。
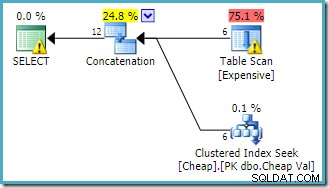
ルートの警告SELECT オペレーターは、ヒープテーブルに明らかに欠落しているインデックスについて警告しています。テーブルスキャンオペレータの警告は、Sentry OnePlanExplorerによって追加されます。スキャン内に隠された残りの述語のI/Oコストに注意を向けています。
行の目標を設定していないため、連結への入力の順序はここでは重要ではありません。両方の入力が完全に読み取られ、すべての結果行が返されます。興味深いことに(これは保証されていませんが)、入力の順序は元のクエリのテキストの順序に従っていることに注意してください。トップレベルのORDER BYを使用しなかったため、最終結果行の順序も指定されていないことにも注意してください。 句。これは意図的なものであり、最終的な順序付けは当面のタスクにとって重要ではないと想定します。
次のように、クエリでテーブルの記述順序を逆にすると、次のようになります。
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; 実行プランは変更に従い、最初にクラスター化されたテーブルにアクセスします(これも保証されません):
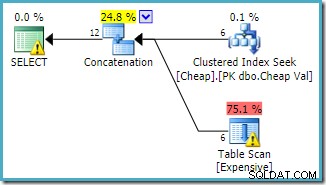
両方のクエリは、同じ操作を異なる順序で実行するため、同じパフォーマンス特性を持つことが期待される場合があります。
行目標あり
明らかに、ヒープテーブルにインデックスがないため、クラスター化されたテーブルでの同じ操作と比較して、通常、特定の行の検索にコストがかかります。オプティマイザーに最初の行をすばやく返すプランを要求すると、SQL Serverが連結入力を並べ替えて、安価なクラスター化されたテーブルが最初に参照されることが期待されます。
最初にヒープテーブルに言及するクエリを使用し、FAST1クエリヒントを使用して行の目標を指定します。
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); SQL Server 2008 R2のインスタンスで作成された推定実行プラン は:
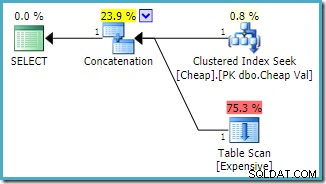
最初の行を返すための推定コストを削減するために、連結入力が並べ替えられていることに注意してください。欠落しているインデックスと残りのI/O警告が消えたことにも注意してください。目標ができるだけ早く単一の行を返すことである場合、どちらの問題もこの計画の形では重要ではありません。
SQL Server 2016で実行された同じクエリ (いずれかのカーディナリティ推定モデルを使用)は次のとおりです:
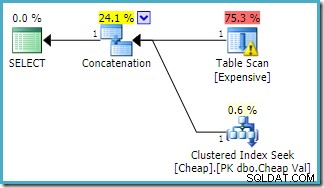
SQL Server 2016は、連結入力を並べ替えていません。プランエクスプローラーのI/O警告が返されましたが、残念ながら、オプティマイザーは今回、欠落しているインデックスの警告を生成していません(関連性はありますが)。
一般的な並べ替え
前述のように、連結入力を並べ替える最適化後の書き換えは、次の場合にのみ有効です。
- SQL Server2008R2以前
- ちょうど1つの行の目標
最初の行をすばやく返すように最適化されたプランではなく、本当に1つの行だけを返したい場合(ただし、最終的にはすべての行を返す)、TOPを使用できます。 派生テーブルまたは共通テーブル式(CTE)を含む句:
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA; SQL Server 2008 R2以前では、これにより最適な並べ替え入力プランが生成されます。
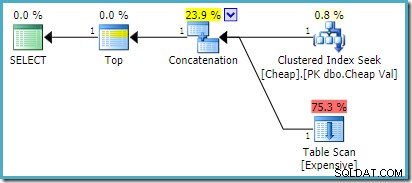
SQL Server 2012、2014、および2016では、最適化後の並べ替えは発生しません。
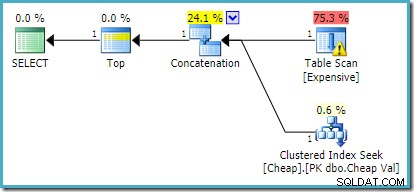
TOP (2)を使用するなど、複数の行を返す場合 、必要な書き換えは適用されません FAST 1であっても、SQL Server2008R2では ヒントも使用されます。そのような状況では、TOPを使用するなどのトリックに頼る必要があります 変数とOPTIMIZE FOR ヒント:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint クエリヒントは、行の目標を1に設定するのに十分ですが、変数の実行時の値により、目的の行数(2)が返されます。
SQL Server2008R2での実際の実行プランは次のとおりです。
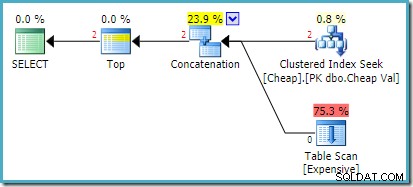
返される両方の行は、並べ替えられたシーク入力からのものであり、テーブルスキャンはまったく実行されません。プランエクスプローラーは、見積もりが1行(ヒントによる)であったのに対し、実行時に2行が検出されたため、行数を赤で表示します。
UNIONALLなし
この問題は、UNION ALLで明示的に記述されたクエリに限定されません。 。 EXISTSなどの他の構造 およびOR また、オプティマイザが連結演算子を導入する可能性があり、入力の並べ替えが不足する可能性があります。まさにこの問題について、データベース管理者のStackExchangeに関する最近の質問がありました。その質問からのクエリを変換して、サンプルテーブルを使用します:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; SQL Server 2016の実行プランには、最初の入力にヒープテーブルがあります:
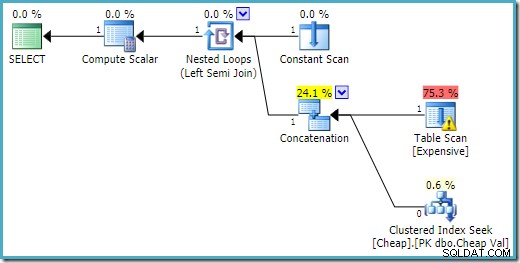
SQL Server 2008 R2では、入力の順序は、半結合の単一行の目標を反映するように最適化されています。
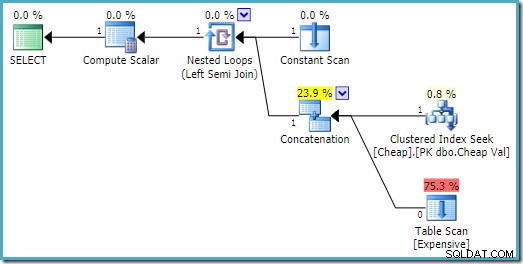
より最適な計画では、ヒープスキャンは実行されません。
回避策
場合によっては、連結入力の1つが他の入力よりも常に安価に実行されることがクエリ作成者に明らかになります。それが真実である場合、より安価な連結入力が最初に書かれた順序で表示されるようにクエリを書き直すことは非常に有効です。もちろん、これは、クエリ作成者がこのオプティマイザの制限を認識し、文書化されていない動作に依存する準備をする必要があることを意味します。
連結入力のコストが状況によって、おそらくパラメーター値によって異なる場合、より難しい問題が発生します。 OPTION (RECOMPILE)を使用する SQLServer2012以降では役に立ちません。このオプションは、SQL Server 2008 R2以前で役立つ場合がありますが、単一行の目標要件も満たされている場合に限ります。
観察された動作(クエリテキストの順序に一致するクエリプランの連結入力)に依存することに懸念がある場合は、プランガイドを使用してプランの形状を強制できます。さまざまな入力順序がさまざまな状況に最適である場合、条件を事前に正確にコーディングできる複数のプランガイドを使用できます。ただし、これは理想的とは言えません。
最終的な考え
SQL Serverクエリオプティマイザには、実際にはコストベースが含まれています 探索ルール、UNIAReorderInputs 、これは、連結入力順序のバリエーションを生成し、コストベースの最適化中に代替案を探索することができます(最適化後の単発の書き換えとしてではありません)。
このルールは現在、一般的な使用には有効になっていません。私の知る限り、プランガイドまたはUSE PLANの場合にのみアクティブになります ヒントがあります。これにより、現在のクエリが適格でない場合でも、エンジンは入力の並べ替えの書き換えに適格なクエリに対して生成されたプランを正常に強制できます。
私の感覚では、コストベースの最適化の一部として連結入力の並べ替えの恩恵を受けるクエリは十分に一般的ではないと見なされるため、またはおそらく余分な労力が支払われないという懸念があるため、この探索ルールは意図的にこの使用に限定されていますオフ。私自身の見解では、行の目標が有効な場合は、連結演算子の入力の並べ替えを常に検討する必要があります。
また、(より限定された)最適化後の書き換えがSQLServer2012以降で効果的でないことも残念です。これは微妙なバグが原因である可能性がありますが、ドキュメント、ナレッジベース、またはConnectでこれについて何も見つかりませんでした。ここに新しいConnectアイテムを追加しました。
2017年8月9日更新 :これは修正済み SQL Server 2014および2016のトレースフラグ4199で、KB4023419を参照してください。
修正:UNION ALLを使用したクエリと行の目標は、SQL Server 2008 R2と比較した場合、SQLServer2014以降のバージョンで実行速度が低下する可能性があります