AWS PostgreSQLサービスは、すべての既知のデータベースエンジン向けのAmazonのDaaSオファリングであるRDSの傘下にあります。
マネージドデータベースサービスは、インフラストラクチャのメンテナンスからの独立性と高可用性構成を求める顧客にアピールする特定の利点を提供します。いつものように、1つのサイズですべてのソリューションに対応できるわけではありません。現在利用可能なオプションを以下に示します。
Aurora PostgreSQL
Amazon Aurora FAQページには、製品に飛び込む前に考慮する必要のある重要な詳細が記載されています。たとえば、ストレージレイヤーが仮想化されており、SSDによってバックアップされた独自の仮想化ストレージシステム上にあることがわかりました。
価格
価格については、AuroraPostgreSQLはAWS無料利用枠では利用できないことに注意する必要があります。
互換性
同じFAQページは、Amazonが100%PostgreSQLの互換性を主張していないことを明らかにしています。 ほとんど (私の強調)アプリケーションの(例えば、 AWSPostgreSQLフレーバーはワイヤー互換です PostgreSQL9.6で。その結果、WiresharkPostgreSQLDissectorは正常に機能します。
パフォーマンス
パフォーマンスはインスタンスタイプにも関連しています。たとえば、接続の最大数はデフォルトでインスタンスサイズに基づいて構成されます。
互換性に関しても重要なのは、PostgreSQLのデフォルトのページサイズである8KiBに保たれているページサイズです。ページについて言えば、FAQを引用する価値があります。「従来のデータベースエンジンとは異なり、Amazon Auroraは変更されたデータベースページをストレージレイヤーにプッシュしないため、IO消費をさらに節約できます。 これが可能になったのは、Amazonがページキャッシュの管理方法を変更し、データベースに障害が発生した場合にページキャッシュをメモリに残せるようにしたためです。この機能は、クラッシュ後のデータベースの再起動にも役立ち、ログを再生する従来の方法よりもはるかに高速にリカバリを実行できます。
上記のFAQによると、AuroraPostgreSQLはPostgreSQLの3倍のパフォーマンスを提供します SELECTおよびUPDATE操作。 AmazonのPostgreSQLベンチマークホワイトペーパーによると、パフォーマンスの測定に使用されたツールはpgbenchとsysbenchでした。注目すべきは、インスタンスタイプ、リージョンの選択、およびネットワークパフォーマンスに対するパフォーマンスの依存関係です。なぜINSERTが言及されていないのか疑問に思いますか?これは、PostgreSQL ACID準拠(「C」)では、削除とそれに続く挿入を使用して更新されたレコードを作成する必要があるためです。
パフォーマンスの向上を最大限に活用するために、Amazonは、アプリケーションが多数の同時クエリとトランザクションを使用してデータベースと対話するように設計されることをお勧めします。 。この重要な要素は見過ごされがちであり、実装のせいでパフォーマンスが低下します。
制限
移行を計画する際に考慮すべきいくつかの制限があります:
-
巨大なページは変更できませんが、デフォルトでオンになっています:
template1=> select aurora_version(); aurora_version ---------------- 1.0.11 (1 row) template1=> show huge_pages ; huge_pages ------------ on (1 row) - pg_hbaはサーバーの再起動が必要なため、使用できません。ちなみに、PostgreSQLはリロードするだけでよいので、これはAmazonのドキュメントのタイプミスである必要があります。管理者は、pg_hbaに依存する代わりに、AWSセキュリティグループとPostgreSQLGRANTを使用する必要があります。
- PITRの粒度は5分です。
- クロスリージョンレプリケーションは現在PostgreSQLでは利用できません。
- テーブルの最大サイズは64TiBです
- 最大15個のリードレプリカ
スケーラビリティ
データベースインスタンスのスケールアップとスケールダウンは現在手動プロセスであり、AWSコンソールまたはCLIを介して実行できますが、自動スケーリングは機能していますが、Amazon Aurora FAQによると、MySQLでのみ使用できます。
 イベントログスケーリングコンピューティングリソース
イベントログスケーリングコンピューティングリソース 水平方向にスケーリングするには、アプリケーションはAWS SDK APIを利用する必要があります。たとえば、高速フェイルオーバーを実現するためです。
高可用性
高可用性に移行すると、プライマリノードに障害が発生した場合、AuroraPostgreSQLはクラスターエンドポイントをDNSAレコードとして提供します。このレコードは、マスターになるように選択されたレプリカを指すように内部で自動的に更新されます。
バックアップ
データベースが削除された場合、手動バックアップスナップショットは保持され、自動スナップショットは削除されます。
複製
レプリカはプライマリインスタンスと同じ基盤ストレージを共有するため、理論的にはレプリケーションラグはミリ秒の範囲です。
フェイルオーバー期間を短縮するために、レプリカの読み取りをお勧めします。スタンバイにリードレプリカがある場合、フェイルオーバープロセスには約30秒かかりますが、レプリカがない場合は最大15分かかります。
その他の朗報は、22ページに示すように、論理レプリケーションもサポートされていることです。
Amazon Aurora FAQには、MySQLの場合のようにレプリケーションの詳細は記載されていませんが、Aurora PostgreSQLのベストプラクティスには、レプリケーションのステータスを確認するための便利なクエリが用意されています。
select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp from
aurora_replica_status();上記のクエリは次のようになります:
-[ RECORD 1 ]--------------+-------------------------------------
server_id | testdb
session_id | 9e268c62-9392-11e8-87fc-a926fa8340fe
highest_lsn_rcvd | 46640889
cur_replay_latency_in_usec | 8830
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:54-07
-[ RECORD 2 ]--------------+-------------------------------------
server_id | testdb-us-east-1b
session_id | MASTER_SESSION_ID
highest_lsn_rcvd |
cur_replay_latency_in_usec |
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:55-07レプリケーションは非常に重要なトピックであるため、上記のベンチマークホワイトペーパーで概説されているように、pgbenchテストを設定する価値がありました。
[example@sqldat.com ~]$ whoami
ec2-user
[example@sqldat.com ~]$ tail -n 2 .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
export PATH=$PATH:/usr/local/pgsql/bin/
[example@sqldat.com ~]$ which pgbench
/usr/local/pgsql/bin/pgbench
[example@sqldat.com ~]$ pgbench --version
pgbench (PostgreSQL) 9.6.8ヒント: pgpassファイルを作成し、ホスト、データベース、およびユーザー環境変数をエクスポートして、不要な入力を回避します。例:
[example@sqldat.com ~]# tail -n 3 ~/.bashrc export
PGUSER=dbadmin
export PGHOST=c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGDATABASE=template1
[example@sqldat.com ~]# cat ~/.pgpass
*:*:*:dbadmin:passwordデータ初期化コマンドを実行します:
[example@sqldat.com ~]$ pgbench -i --fillfactor=90 --scale=10000 postgresデータの初期化の実行中に、次のスクリプト内から呼び出された上記のSQLを使用してレプリケーションラグをキャプチャします。
while : ; do
psql -t -q \
-c 'select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp
from aurora_replica_status();' postgres
sleep 1
done次のコマンドを使用して、画面ログ出力をフィルタリングします。
[example@sqldat.com ~]# awk -F '|' '{print $4,$5,$6}' screenlog.2 | sort -k1,1 -n | tail
513116 2018-07-30 04:30:44.394729+00 2018-07-30 04:30:43+00
529294 2018-07-30 04:20:54.261741+00 2018-07-30 04:20:53+00
544139 2018-07-30 04:41:57.538566+00 2018-07-30 04:41:57+00
1001902 2018-07-30 04:42:54.80136+00 2018-07-30 04:42:53+00
2376951 2018-07-30 04:38:06.621681+00 2018-07-30 04:38:06+00
2376951 2018-07-30 04:38:07.672919+00 2018-07-30 04:38:07+00
5365719 2018-07-30 04:36:51.608983+00 2018-07-30 04:36:50+00
5365719 2018-07-30 04:36:52.912731+00 2018-07-30 04:36:51+00
6308586 2018-07-30 04:45:22.951966+00 2018-07-30 04:45:21+00
8210986 2018-07-30 04:46:14.575385+00 2018-07-30 04:46:13+00レプリケーションが8秒も遅れていることがわかりました!
関連するメモとして、AWSCloudWatchメトリクスAuroraReplicaLagMaximumは上記のSQLコマンドの結果と一致しません。理由を知りたいので、フィードバックをいただければ幸いです。
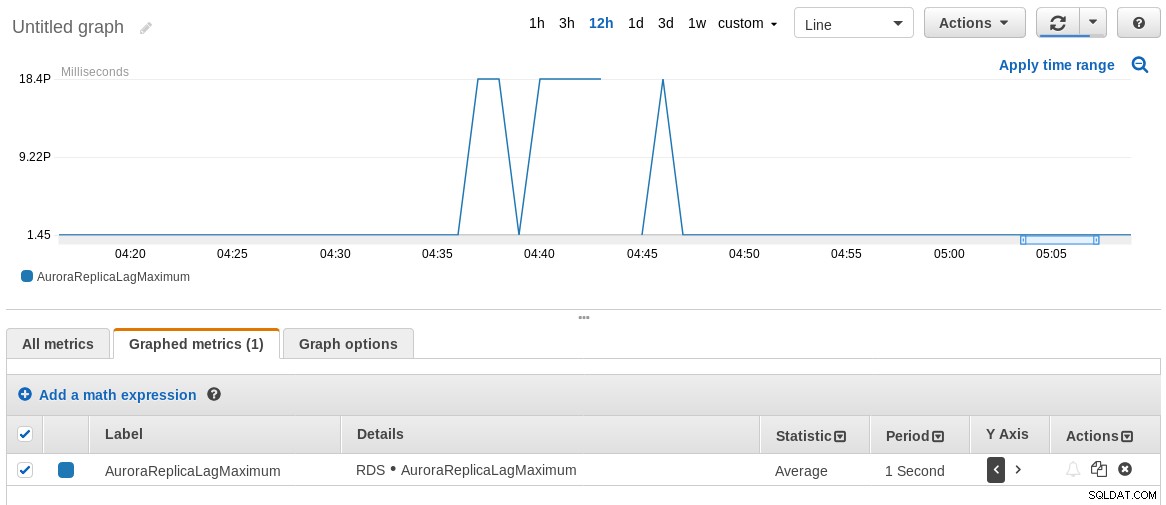 RDSCloudWatchmaxレプリカラググラフ
RDSCloudWatchmaxレプリカラググラフ セキュリティ
-
暗号化は利用可能であり、後で変更することはできないため、データベースの作成時に有効にする必要があります。
トラブルシューティング
この短いセクションは重要です。PostgreSQLのwork_memが適切に調整されていることを確認して、並べ替え操作でデータがディスクに書き込まれないようにします。
セットアップ
AWSコンソールのセットアップウィザードに従ってください:
-
Amazon RDSを開きます 管理コンソール。
 RDS管理コンソール
RDS管理コンソール -
Amazon Auroraを選択します およびPostgreSQL エディション。
 AuroraPostgreSQLウィザード
AuroraPostgreSQLウィザード -
DBの詳細を指定し、AuroraPostgreSQLのパスワードの制限に注意してください。
Master Password must be at least eight characters long, as in "mypassword". Can be any printable ASCII character except "/", """, or "@". AuroraPostgreSQLウィザードデータベースの詳細
AuroraPostgreSQLウィザードデータベースの詳細 -
データベースオプションを構成します:
- この記事の執筆時点では、PostgreSQL9.6のみが利用可能です。ベータプレビューなど、より新しいバージョンのサポートが必要な場合は、AmazonRDSでPostgreSQLを使用してください。
-
フェイルオーバーの優先度を構成し、レプリカの数を選択します。
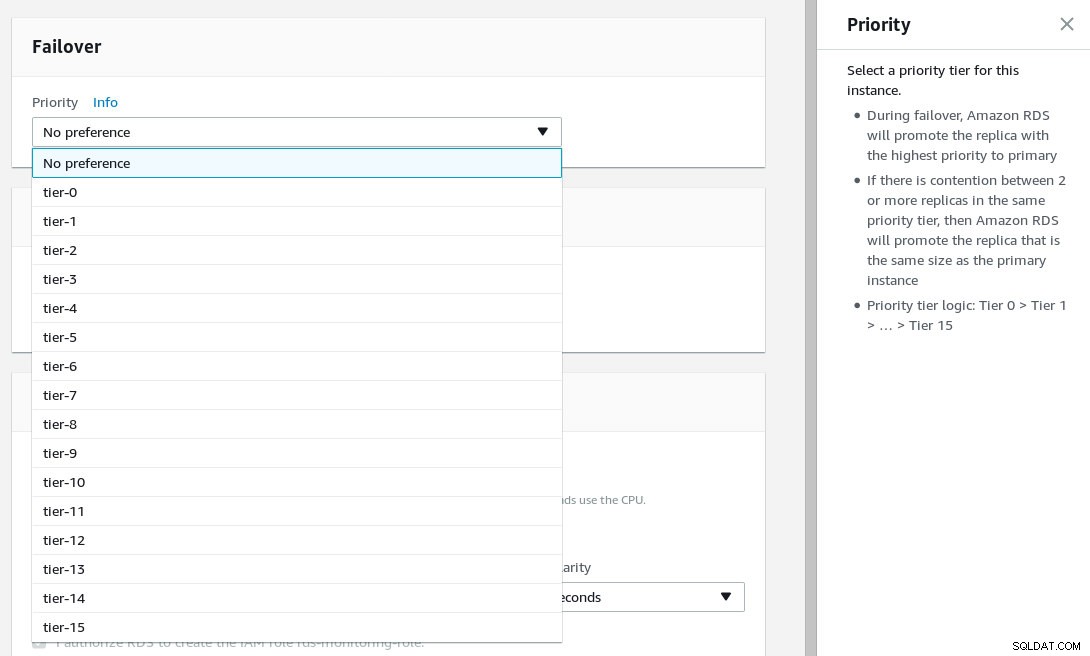 写真の説明
写真の説明 -
バックアップの保持を設定します(最大35日)。
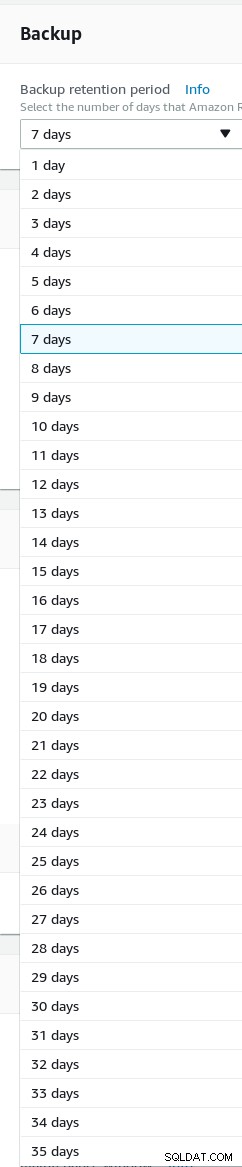 AuroraPostgreSQLウィザードのバックアップ保持
AuroraPostgreSQLウィザードのバックアップ保持 -
メンテナンススケジュールを選択します。自動マイナーバージョンアップグレードを利用できますが、PostgreSQLプロジェクトが緊急の更新をリリースした場合に備えて、パッチスケジュールを迅速化できるかどうかをAWSサポートに確認することが重要です。たとえば、AWSが2018-05-10アップデートをプッシュするのに2か月以上かかりました。
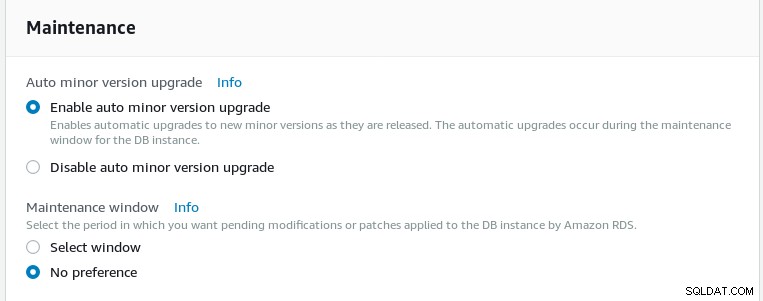 AuroraPostgreSQLウィザードのメンテナンススケジュール
AuroraPostgreSQLウィザードのメンテナンススケジュール -
データベースが正常に作成されると、データベースへの接続方法の説明へのリンクが表示されます。
 AuroraPostgreSQLウィザードのセットアップが完了しました
AuroraPostgreSQLウィザードのセットアップが完了しました
データベースへの接続
インフラストラクチャの設定に基づいて、利用可能な接続オプションの詳細な手順を確認します。最も単純なシナリオでは、接続はパブリックEC2インスタンスを介して行われます。
注:クライアントはPostgreSQL9.6.3以降と互換性がある必要があります。
[example@sqldat.com ~]# psql -U dbadmin -h c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com template1
Password for user dbadmin:
psql (9.6.8, server 9.6.3)
SSL connection (protocol: TLSv1.2, cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.監視
Amazonは、データベースを監視するためのさまざまなメトリックを提供しています。以下の例は、インスタンスのメトリックを示しています。
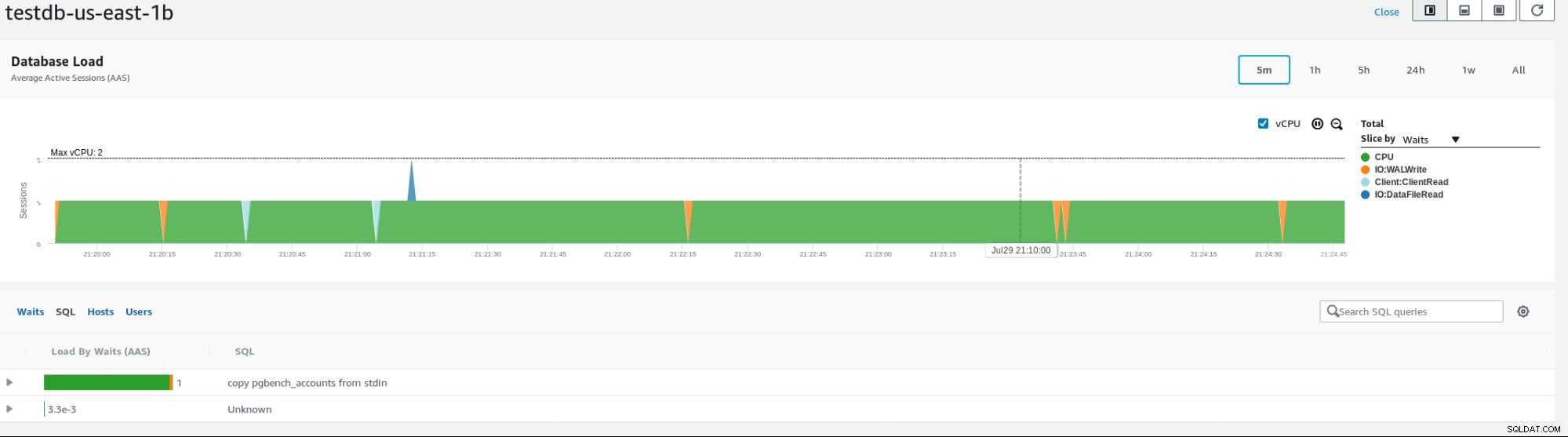 RDSインスタンスメトリクス今日のホワイトペーパーをダウンロードClusterControlを使用したPostgreSQLの管理と自動化デプロイ、モニタリング、 PostgreSQLの管理とスケーリングホワイトペーパーをダウンロード
RDSインスタンスメトリクス今日のホワイトペーパーをダウンロードClusterControlを使用したPostgreSQLの管理と自動化デプロイ、モニタリング、 PostgreSQLの管理とスケーリングホワイトペーパーをダウンロード RDS for PostgreSQL
これは、構成の選択に関してより細分性を可能にするオファリングです。たとえば、独自のストレージシステムを使用するAuroraとは対照的に、RDSは、汎用SSD(GP2)、プロビジョンドIOPS、または磁気(非推奨)のいずれかであるEBSボリュームを使用して構成可能なストレージを提供します。
Aurora製品では利用できないカスタマイズを必要とする大規模なインストールを支援するために、Amazonは最近、RDSでのみ利用可能なベストプラクティスの推奨事項をリリースしました。
高可用性は手動で構成する必要があり(または既知のAWSツールのいずれかを使用して自動化する必要があります)、マルチAZデプロイメントをセットアップすることをお勧めします。
レプリケーションは、PostgreSQLネイティブレプリケーションを使用して実装されます。
考慮する必要のあるPostgreSQLDBインスタンスにはいくつかの制限があります。
上記の注意事項を念頭に置いて、RDSPostgreSQLマルチAZ環境をセットアップするためのウォークスルーを次に示します。
-
RDS管理コンソールから ウィザードを開始します
 RDSPostgreSQLウィザード
RDSPostgreSQLウィザード -
本番セットアップと開発セットアップのどちらかを選択します。
 RDSPostgreSQLウィザードデータベースのユースケースの選択
RDSPostgreSQLウィザードデータベースのユースケースの選択 -
新しいデータベースクラスタに関する詳細を入力します。
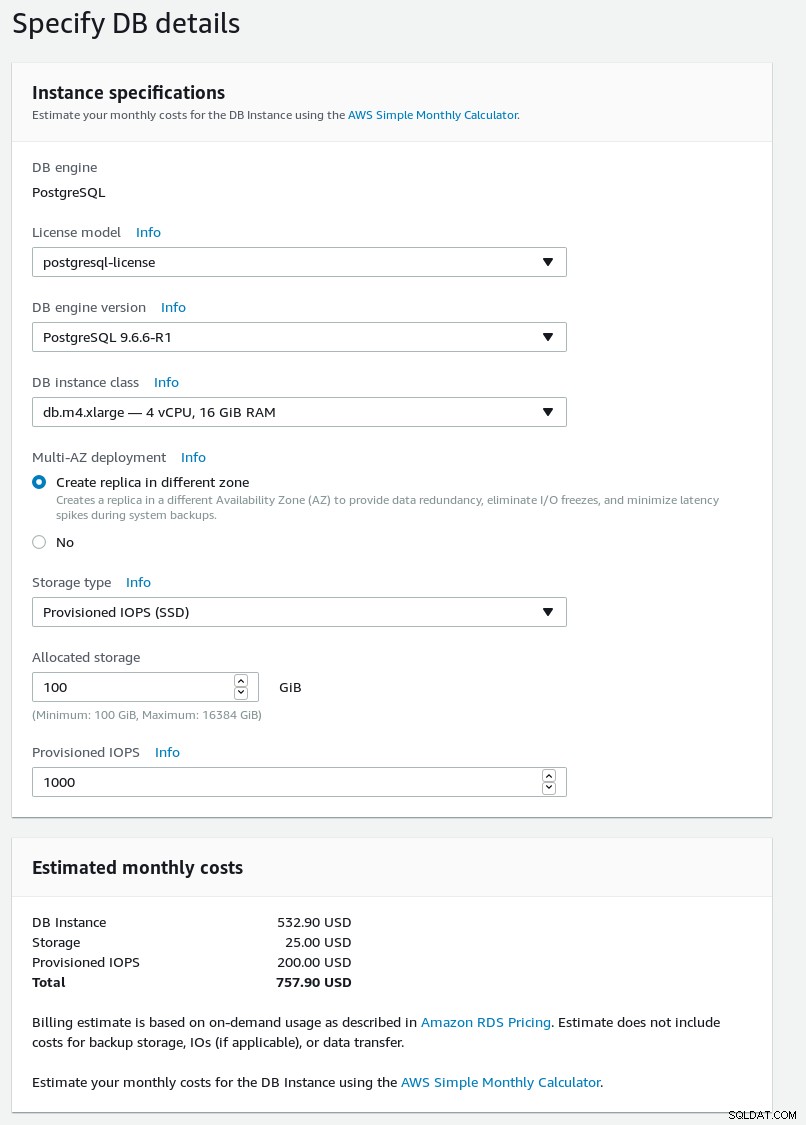 RDSPostgreSQLウィザードDBの詳細
RDSPostgreSQLウィザードDBの詳細 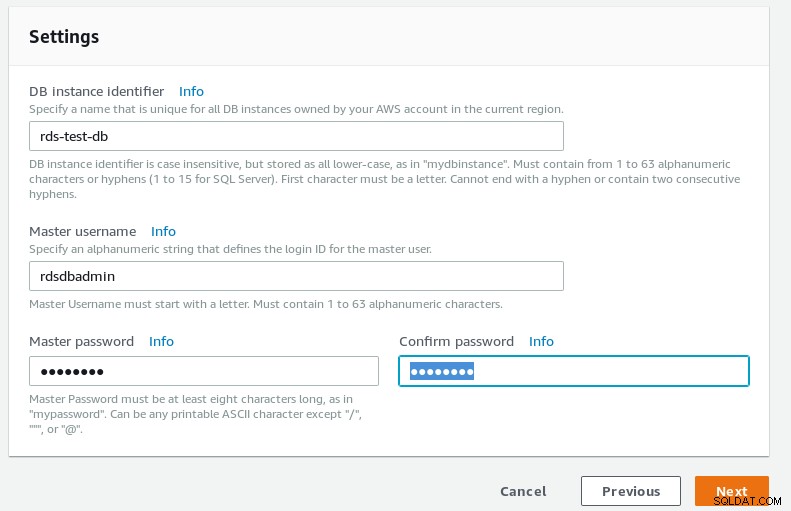 RDSPostgreSQLウィザードのデータベース設定
RDSPostgreSQLウィザードのデータベース設定 -
次のページで、ネットワーク、セキュリティ、およびメンテナンスのスケジュールを設定します。
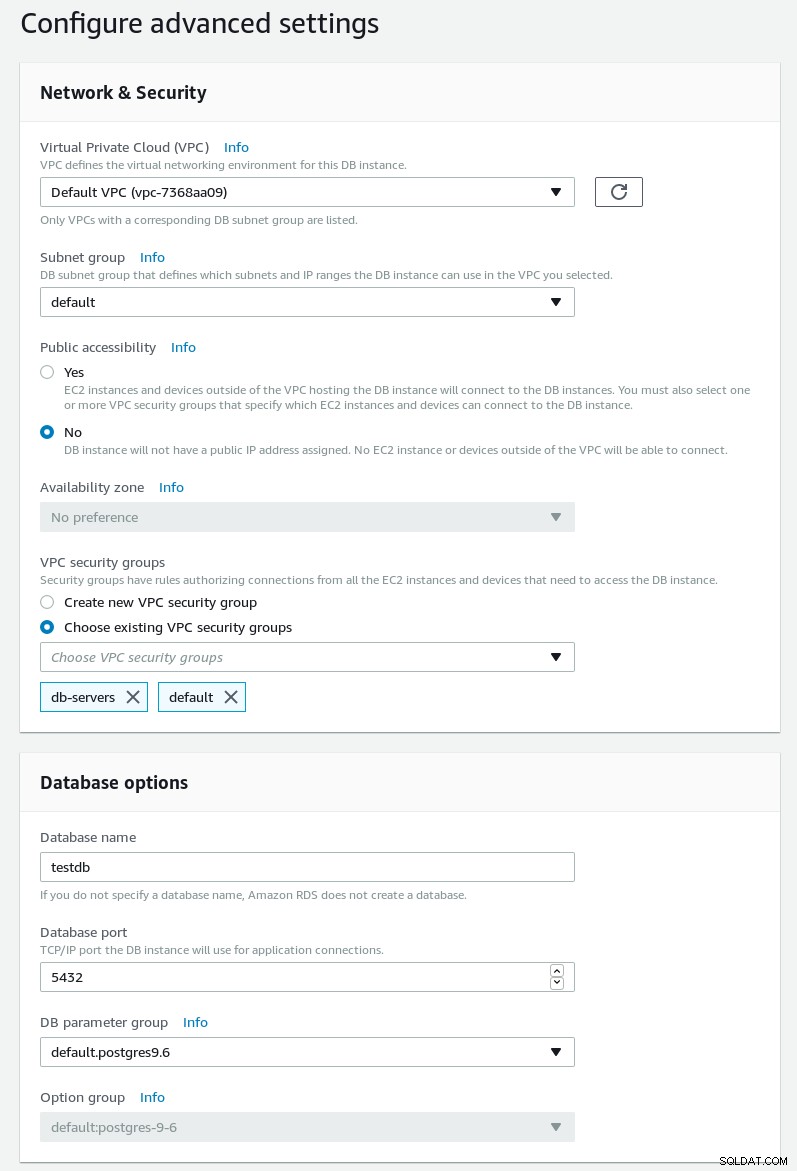 RDSPostgreSQLウィザードの詳細設定
RDSPostgreSQLウィザードの詳細設定 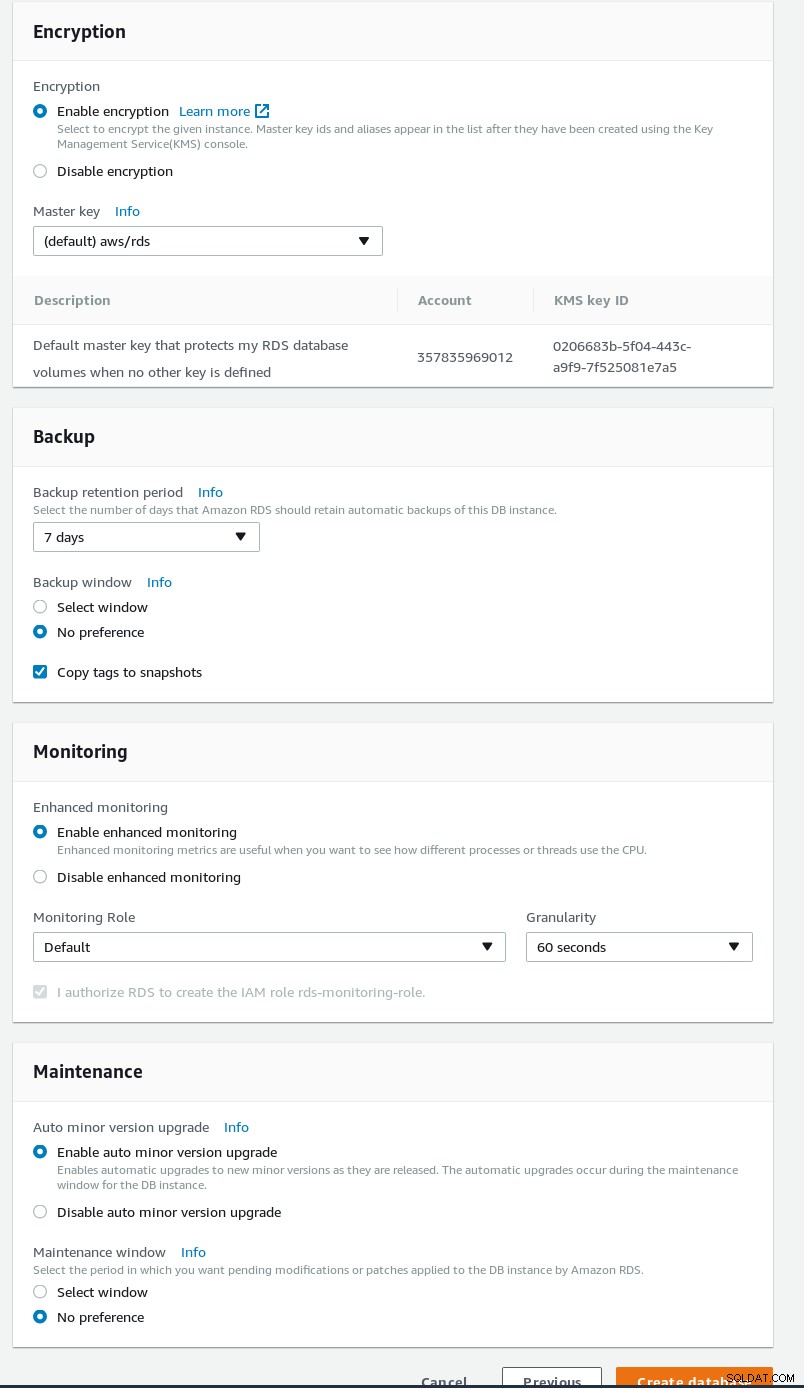 RDSPostgreSQLウィザードのセキュリティとメンテナンス
RDSPostgreSQLウィザードのセキュリティとメンテナンス
結論
PostgreSQL用のAmazonRDSサービスには、RDSPostgreSQLとAuroraPostgreSQLが含まれ、どちらもマネージドDaaSオファリングです。豊富な機能と堅牢なバックエンドストレージが満載されているため、従来のセットアップに比べていくつかの制限がありますが、慎重に計画することで、これらの製品はバランスの取れたコストと機能の比率を提供できます。 Amazon RDS for PostgreSQLは、環境を構成するためにより多くのオプションを必要とするユーザーを対象としており、一般的にはより高価です。大多数のユーザーは、Aurora PostgreSQLを起動して、より複雑な構成に移行することでメリットを得ることができます。