IT業界で働いていると、おそらく「フェイルオーバー」という言葉を何度も耳にしますが、次のような疑問が生じることもあります。実際のフェイルオーバーとは何ですか。何に使えますか?それを持つことは重要ですか?どうすればいいですか?
それらはかなり基本的な質問に見えるかもしれませんが、どのデータベース環境でもそれらを考慮に入れることが重要です。そして、多くの場合、私たちは基本を考慮していません...
まず、いくつかの基本的な概念を見てみましょう。
フェイルオーバーとは何ですか?
フェイルオーバーとは、何らかの障害が発生した場合でもシステムが機能し続ける機能です。これは、プライマリコンポーネントに障害が発生した場合に、システムの機能がセカンダリコンポーネントによって引き継がれることを示唆しています。
PostgreSQLの場合、障害に強いデータベースクラスターを実装できるさまざまなツールがあります。 PostgreSQLでネイティブに利用できる冗長メカニズムの1つは、レプリケーションです。そして、PostgreSQL 10の目新しさは、論理レプリケーションの実装です。
レプリケーションとは何ですか?
これは、1つ以上のデータベースノードでデータをコピーして更新し続けるプロセスです。変更を受け取るマスターノードと、変更が複製されるスレーブノードの概念を使用します。
レプリケーションを分類する方法はいくつかあります:
- 同期レプリケーション:マスターノードが失われた場合でもデータが失われることはありませんが、マスターのコミットはスレーブからの確認を待機する必要があり、パフォーマンスに影響を与える可能性があります。
- 非同期レプリケーション:マスターノードを失うと、データが失われる可能性があります。インシデント発生時に何らかの理由でレプリカが更新されていない場合、コピーされていない情報が失われる可能性があります。
- 物理レプリケーション:ディスクブロックがコピーされます。
- 論理レプリケーション:データ変更のストリーミング。
- ウォームスタンバイスレーブ:接続をサポートしていません。
- ホットスタンバイスレーブ:読み取り専用接続をサポートし、レポートやクエリに役立ちます。
フェイルオーバーは何に使用されますか?
フェイルオーバーにはいくつかの用途があります。いくつかの例を見てみましょう。
移行
ダウンタイムを最小限に抑えて、あるデータセンターから別のデータセンターに移行する場合は、フェイルオーバーを使用できます。
マスターがデータセンターAにあり、システムをデータセンターBに移行したいとします。
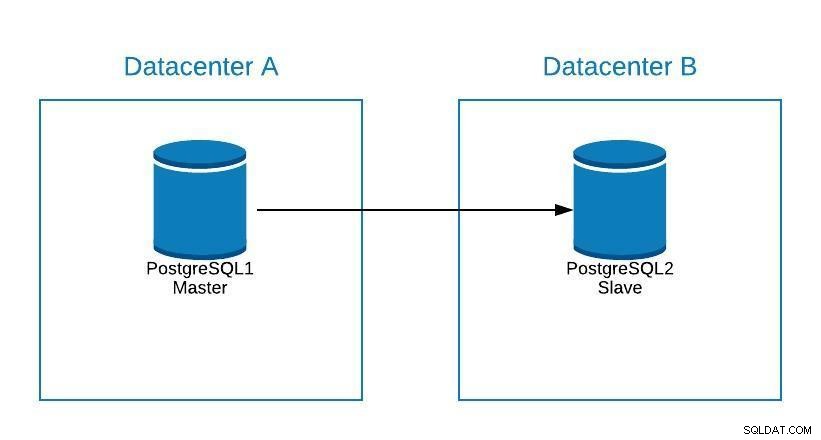 移行図1
移行図1 データセンターBにレプリカを作成できます。同期したら、システムを停止し、レプリカを新しいマスターに昇格させてフェイルオーバーしてから、システムをデータセンターBの新しいマスターにポイントする必要があります。
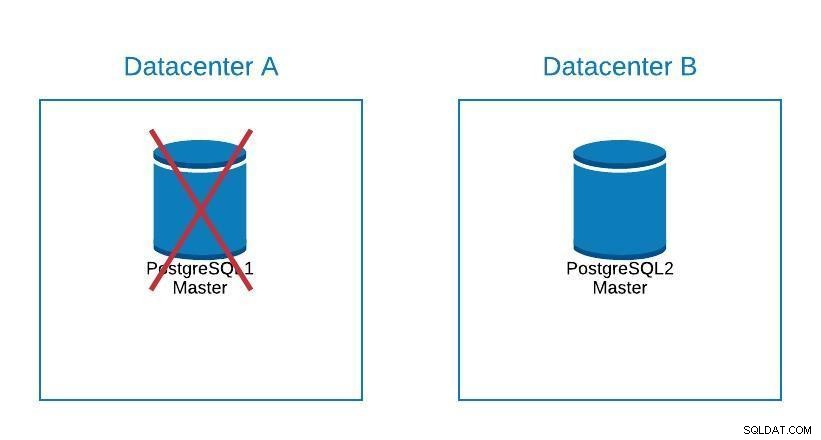 移行図2
移行図2 フェイルオーバーは、データベースだけでなく、アプリケーションにも関係します。彼らはどのデータベースに接続するかをどうやって知るのですか?ダウンタイムを延長するだけなので、アプリケーションを変更する必要はありません。したがって、マスターを停止したときに、昇格する次のサーバーを自動的に指すようにロードバランサーを構成できます。
もう1つのオプションは、DNSの使用です。新しいデータセンターでマスターレプリカをプロモートすることにより、マスターを指すホスト名のIPアドレスを直接変更します。このようにして、アプリケーションを変更する必要がなくなります。自動的に変更することはできませんが、ロードバランサーを実装したくない場合の代替手段です。
単一のロードバランサーインスタンスを持つことは、単一障害点になる可能性があるため、優れていません。したがって、keepalivedなどのサービスを使用して、ロードバランサーのフェイルオーバーを実装することもできます。このように、プライマリロードバランサーに問題が発生した場合、keepalivedはIPをセカンダリロードバランサーに移行する責任があり、すべてが透過的に機能し続けます。
メンテナンス
postgreSQLマスターデータベースサーバーでメンテナンスを実行する必要がある場合は、スレーブを昇格させ、タスクを実行し、古いマスターでスレーブを再構築できます。
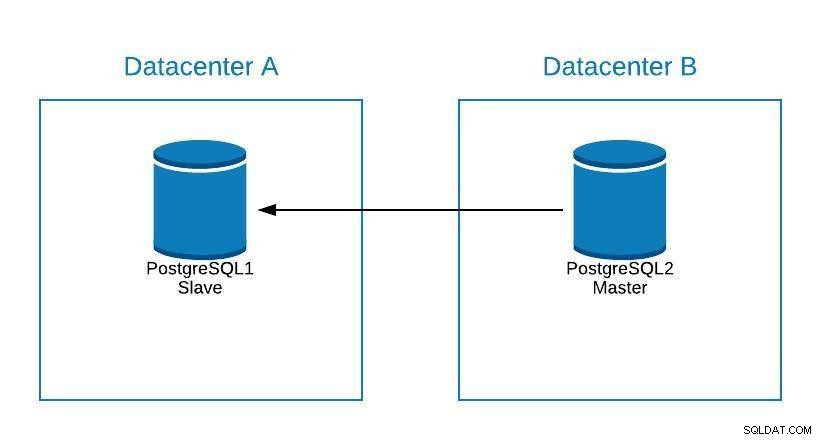 メンテナンス図1
メンテナンス図1 この後、古いマスターを再昇格させ、スレーブの再構築プロセスを繰り返して、初期状態に戻すことができます。
保守図2 このようにして、メンテナンスの実行中にオフラインになったり情報を失ったりするリスクを冒すことなく、サーバーで作業することができました。
アップグレード
PostgreSQL 11はまだ利用できませんが、他のエンジンで実行できるため、論理レプリケーションを使用してPostgreSQLバージョン10から技術的にアップグレードすることは可能です。
手順は、新しいデータセンターに移行する場合と同じです(移行セクションを参照)。ただし、スレーブはPostgreSQL11にあります。
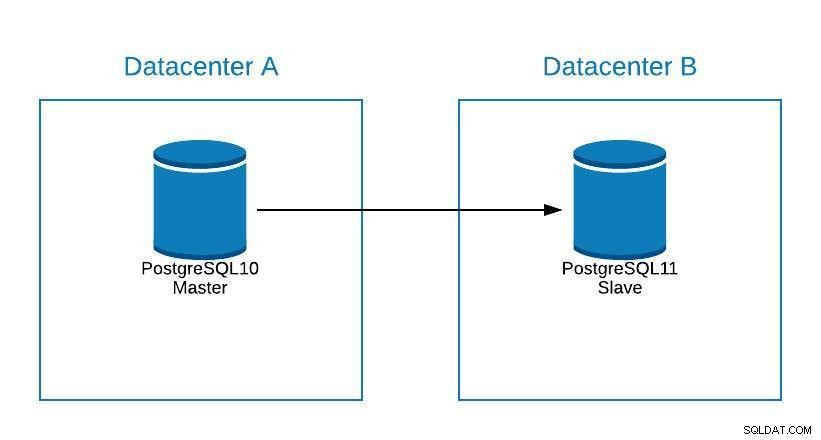 アップグレード図1
アップグレード図1 問題
フェイルオーバーの最も重要な機能は、メインデータベースに問題が発生した場合に、ダウンタイムを最小限に抑えるか、情報の損失を回避することです。
何らかの理由でマスターデータベースが失われた場合は、フェイルオーバーを実行してスレーブをマスターに昇格させ、システムを実行し続けることができます。
これを行うために、PostgreSQLは自動化されたソリューションを提供していません。手動で行うことも、スクリプトや外部ツールを使用して自動化することもできます。
スレーブをマスターに昇格させるには:
-
pg_ctlpromoteを実行します
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - データディレクトリのrecovery.confに追加する必要のあるファイルtrigger_fileを作成します。
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
フェイルオーバー戦略を実装するには、それを計画し、さまざまな障害シナリオを徹底的にテストする必要があります。障害はさまざまな方法で発生する可能性があるため、ソリューションはほとんどの一般的なシナリオで理想的に機能するはずです。これを自動化する方法を探している場合は、ClusterControlが提供するものを確認できます。
PostgreSQLフェイルオーバー用のClusterControl
ClusterControlには、PostgreSQLレプリケーションと自動フェイルオーバーに関連する多くの機能があります。
スレーブを追加
不測の事態として、またはシステムを移行するために、別のデータセンターにスレーブを追加する場合は、クラスターアクションに移動し、[レプリケーションスレーブの追加]を選択できます。
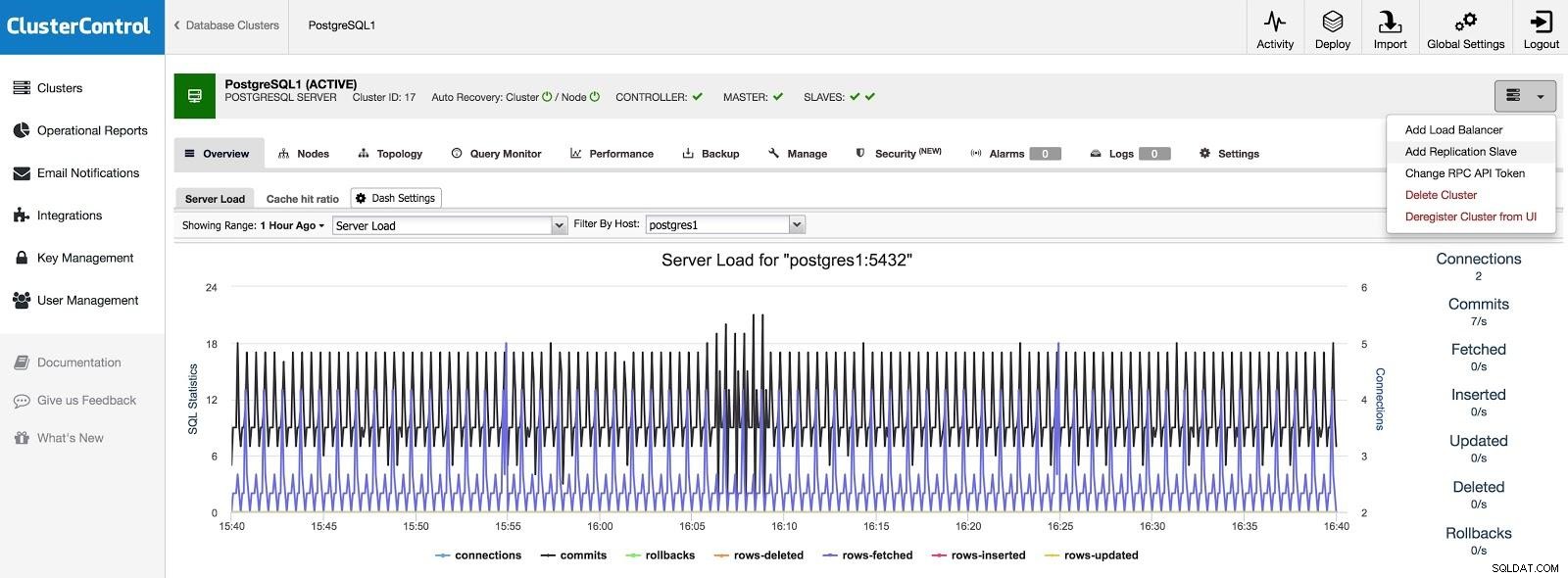 ClusterControl Add Slave 1
ClusterControl Add Slave 1 IPまたはホスト名、データディレクトリ(オプション)、同期または非同期スレーブなどの基本データを入力する必要があります。数秒後にスレーブを稼働させる必要があります。
別のデータセンターを使用する場合は、非同期スレーブを作成することをお勧めします。そうしないと、レイテンシがパフォーマンスに大きな影響を与える可能性があります。
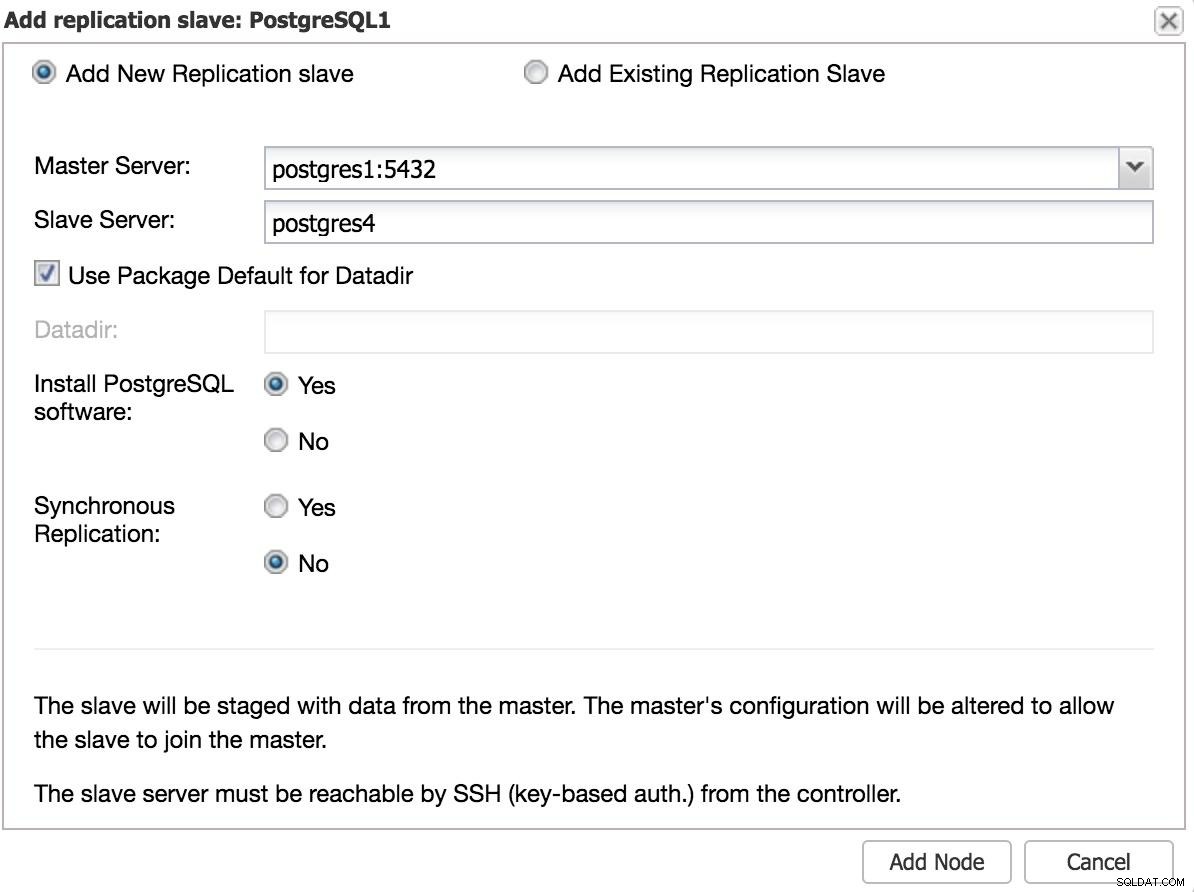 ClusterControl Add Slave 2
ClusterControl Add Slave 2 手動フェイルオーバー
ClusterControlを使用すると、フェイルオーバーを手動または自動で実行できます。
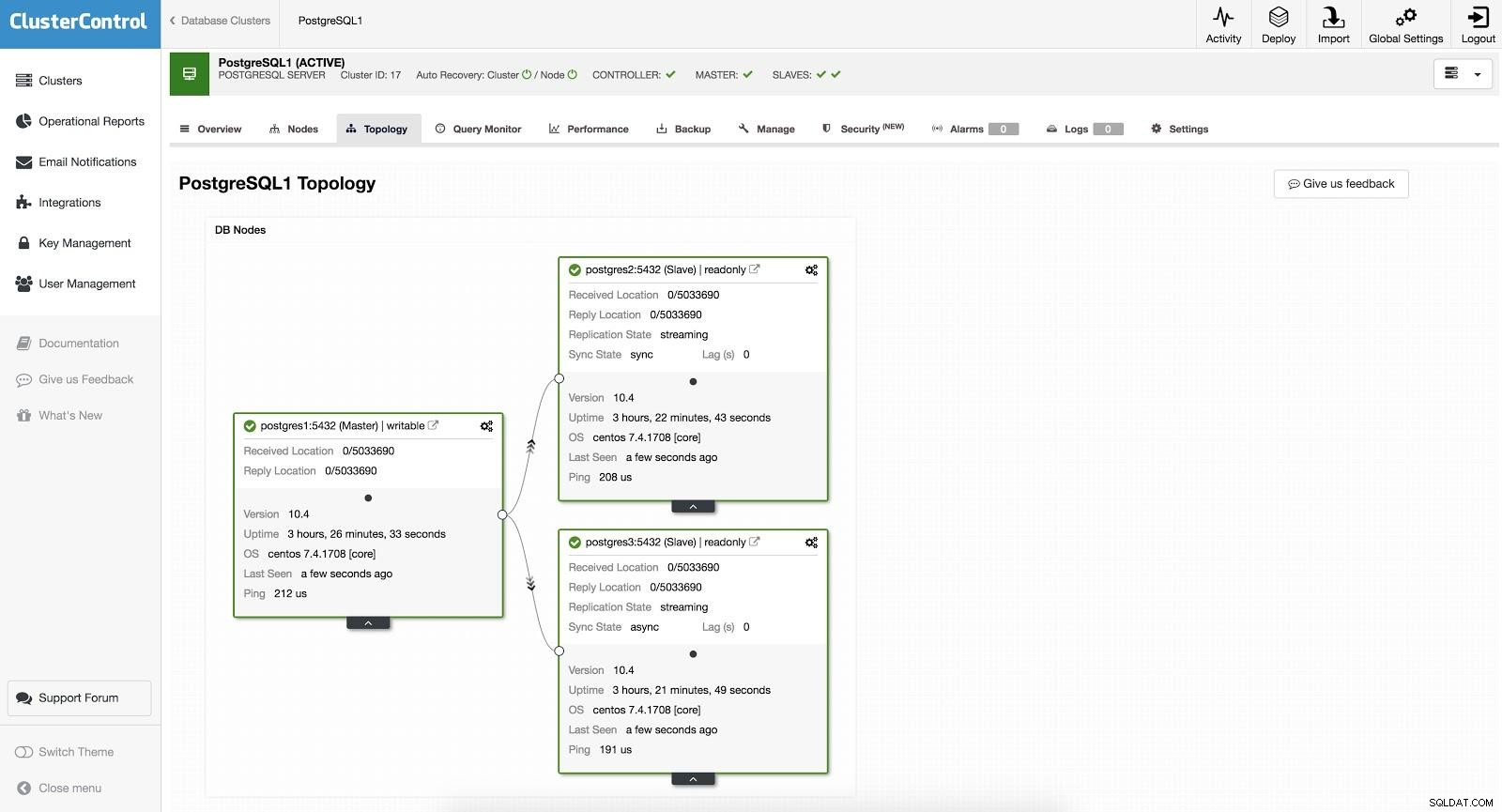 ClusterControlフェイルオーバー1
ClusterControlフェイルオーバー1 手動フェイルオーバーを実行するには、ClusterControl-> Select Cluster-> Nodesに移動し、いずれかのスレーブのアクションノードで[PromoteSlave]を選択します。このようにして、数秒後にスレーブがマスターになり、以前はマスターであったものがスレーブに変わります。
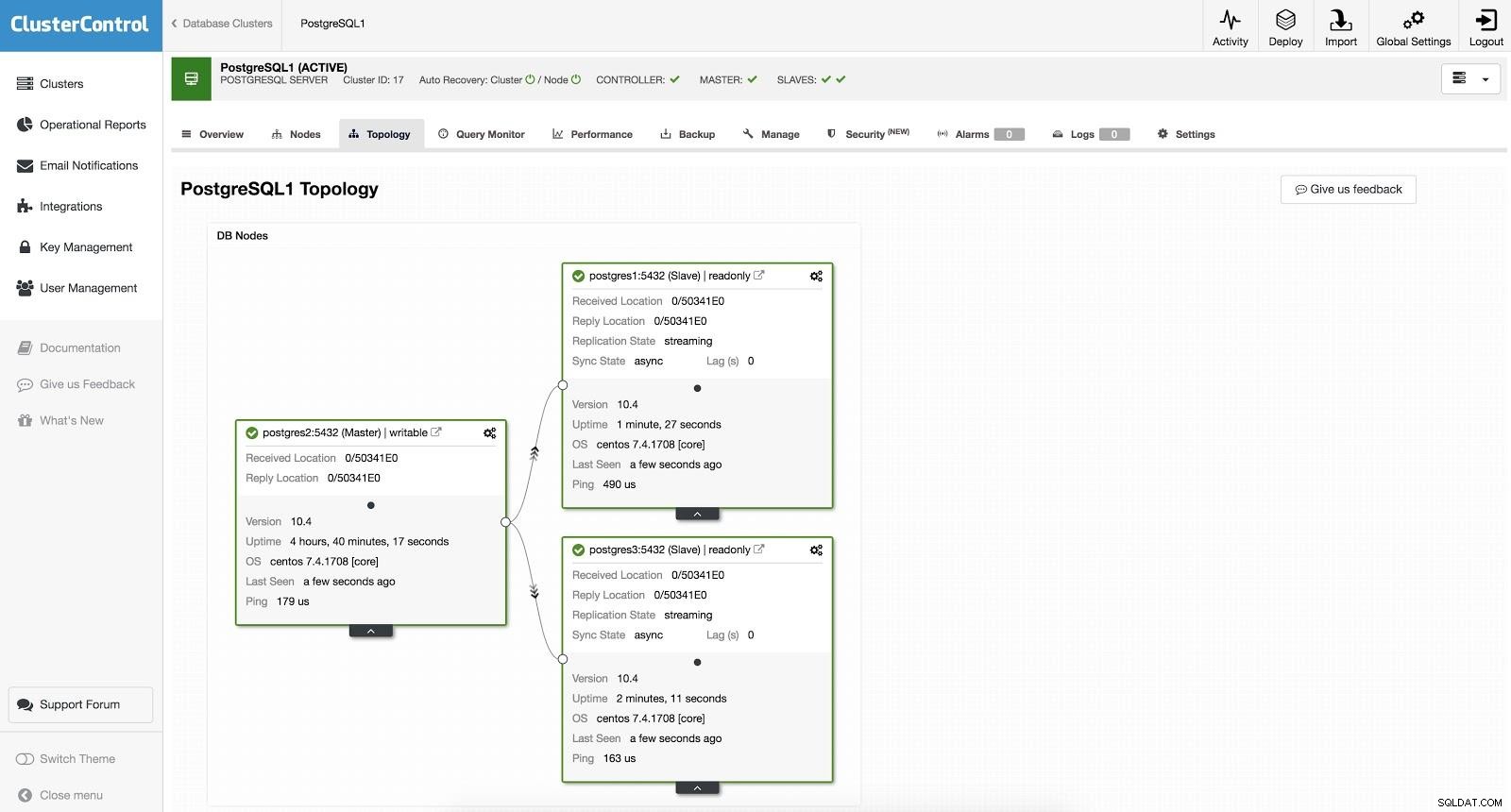 ClusterControlフェイルオーバー2
ClusterControlフェイルオーバー2 上記は、以前に見た移行、保守、およびアップグレードのタスクに役立ちます。
自動フェイルオーバー
自動フェイルオーバーの場合、ClusterControlはマスターの障害を検出し、最新のデータを持つスレーブを新しいマスターとして昇格させます。また、残りのスレーブでも機能して、新しいマスターから複製します。
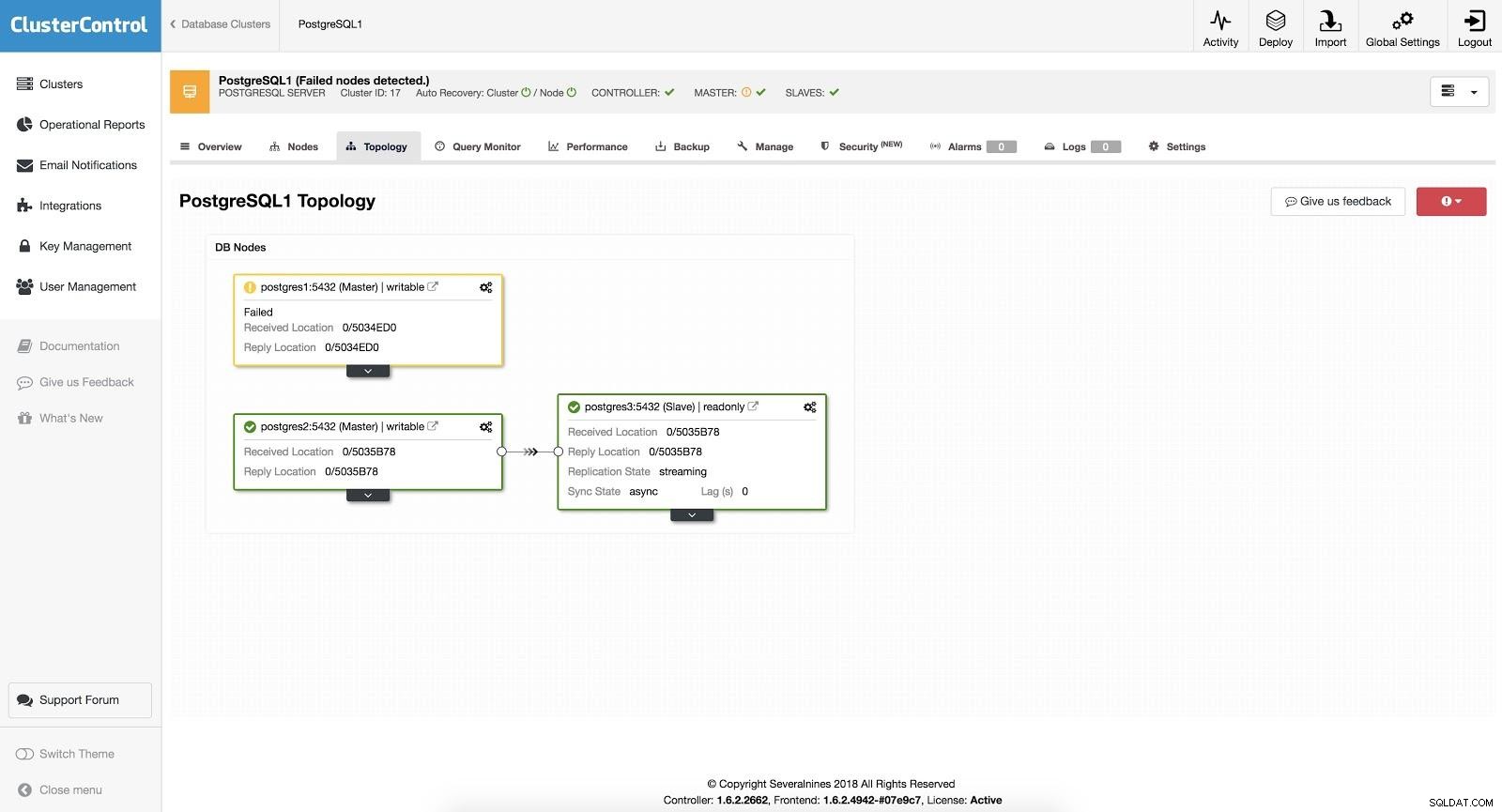 ClusterControlフェイルオーバー3
ClusterControlフェイルオーバー3 「自動回復」オプションをオンにすると、ClusterControlは自動フェイルオーバーを実行し、問題を通知します。このようにして、システムは数秒で、介入なしで回復できます。
Cluster Controlを使用すると、ホワイトリスト/ブラックリストを構成して、マスター候補を決定するときにサーバーをどのように考慮するか(または考慮しないか)を定義できます。
上記の構成に従って使用可能なものから、ClusterControlは、データベースのバージョンに応じてpg_current_xlog_location(PostgreSQL 9+)またはpg_current_wal_lsn(PostgreSQL 10+)を使用して、最も高度なスレーブを選択します。
ClusterControlは、いくつかの一般的な間違いを回避するために、フェイルオーバープロセスに対していくつかのチェックも実行します。 1つの例は、障害が発生した古いマスターを回復できた場合、マスターとしてもスレーブとしても、クラスターに自動的に再導入されないことです。手動で行う必要があります。これにより、障害時に(昇格した)スレーブが遅延した場合に、データの損失や不整合が発生する可能性を回避できます。問題を詳細に分析することもできますが、クラスターに追加すると、診断情報が失われる可能性があります。
また、フェイルオーバーが失敗した場合、それ以上の試行は行われず、問題を分析して対応するアクションを実行するために手動の介入が必要です。これは、高可用性マネージャーとしてのClusterControlが次のスレーブと次のスレーブを昇格させようとする状況を回避するためです。問題がある可能性があり、複数のフェイルオーバーを試行して事態を悪化させたくはありません。
ロードバランサー
前述したように、ロードバランサーは、特にデータベーストポロジで自動フェイルオーバーを使用する場合に、フェイルオーバーを検討するための重要なツールです。
フェイルオーバーをユーザーとアプリケーションの両方に対して透過的にするには、マスターをスレーブに昇格させるだけでは不十分なため、間にコンポーネントが必要です。このために、HAProxy+Keepalivedを使用できます。
HAProxyとは何ですか?
HAProxyは、1つの発信元から1つ以上の宛先にトラフィックを分散し、このタスクの特定のルールやプロトコルを定義できるロードバランサーです。いずれかの宛先が応答を停止すると、オフラインとしてマークされ、トラフィックは残りの使用可能な宛先に送信されます。これにより、トラフィックがアクセスできない宛先に送信されるのを防ぎ、有効な宛先にトラフィックを転送することでこのトラフィックの損失を防ぎます。
キープアライブとは何ですか?
Keepalivedを使用すると、サーバーのアクティブ/パッシブグループ内に仮想IPを構成できます。この仮想IPは、アクティブな「プライマリ」サーバーに割り当てられます。このサーバーに障害が発生した場合、IPはパッシブであることが判明した「セカンダリ」サーバーに自動的に移行され、システムに対して透過的な方法で同じIPを引き続き使用できるようになります。
ClusterControlを使用してこのソリューションを実装するために、スレーブを追加するかのように開始しました。 Cluster Actionsに移動し、Add Load Balancerを選択します(ClusterControl Add Slave 1イメージを参照)。
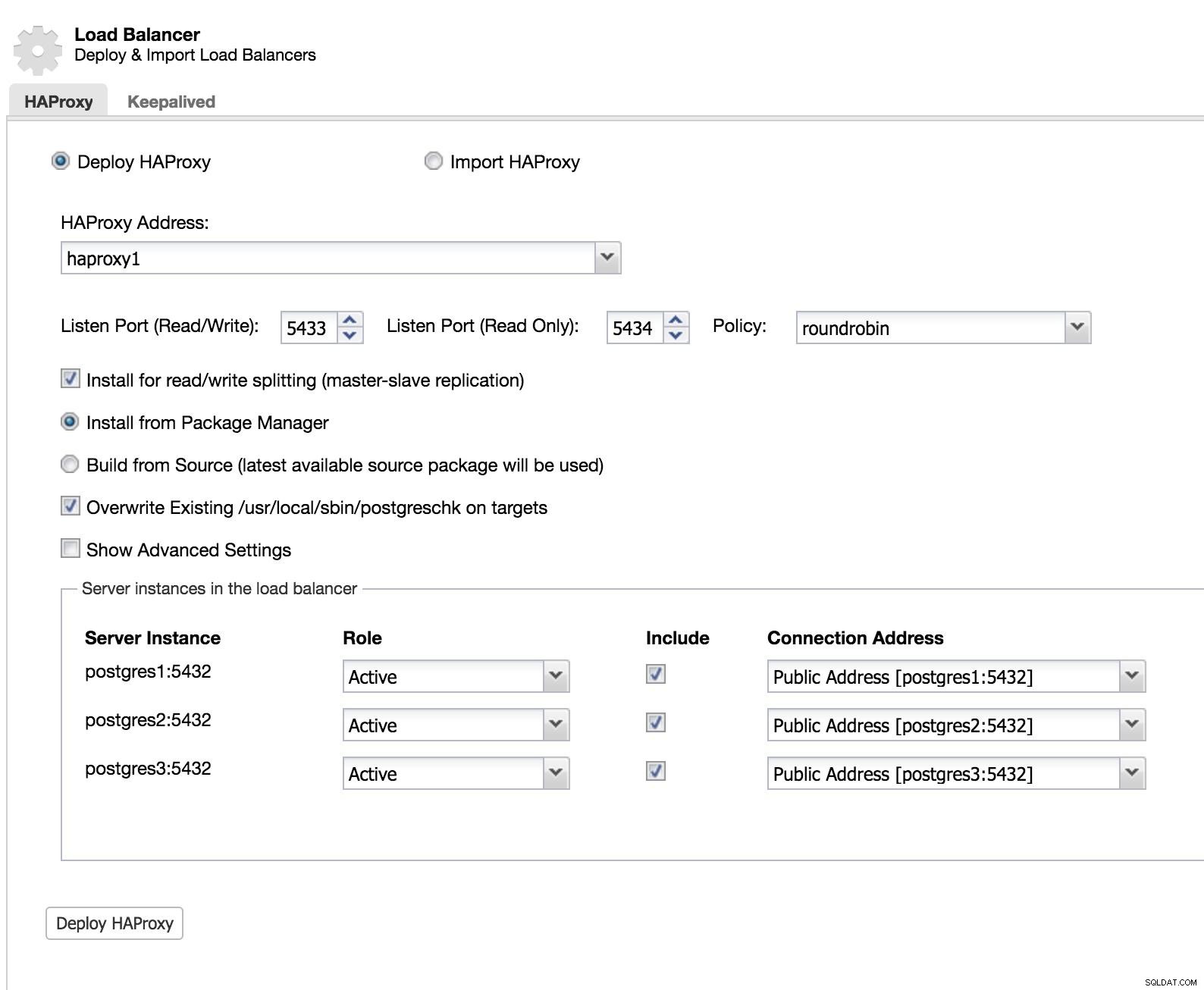 ClusterControlロードバランサー1
ClusterControlロードバランサー1 新しいロードバランサーの情報とその動作方法(ポリシー)を追加します。
ロードバランサーにフェイルオーバーを実装する場合は、少なくとも2つのインスタンスを構成する必要があります。
次に、Keepalivedを構成できます([クラスター]->[管理]->[ロードバランサー]->[Keepalived]を選択します)。
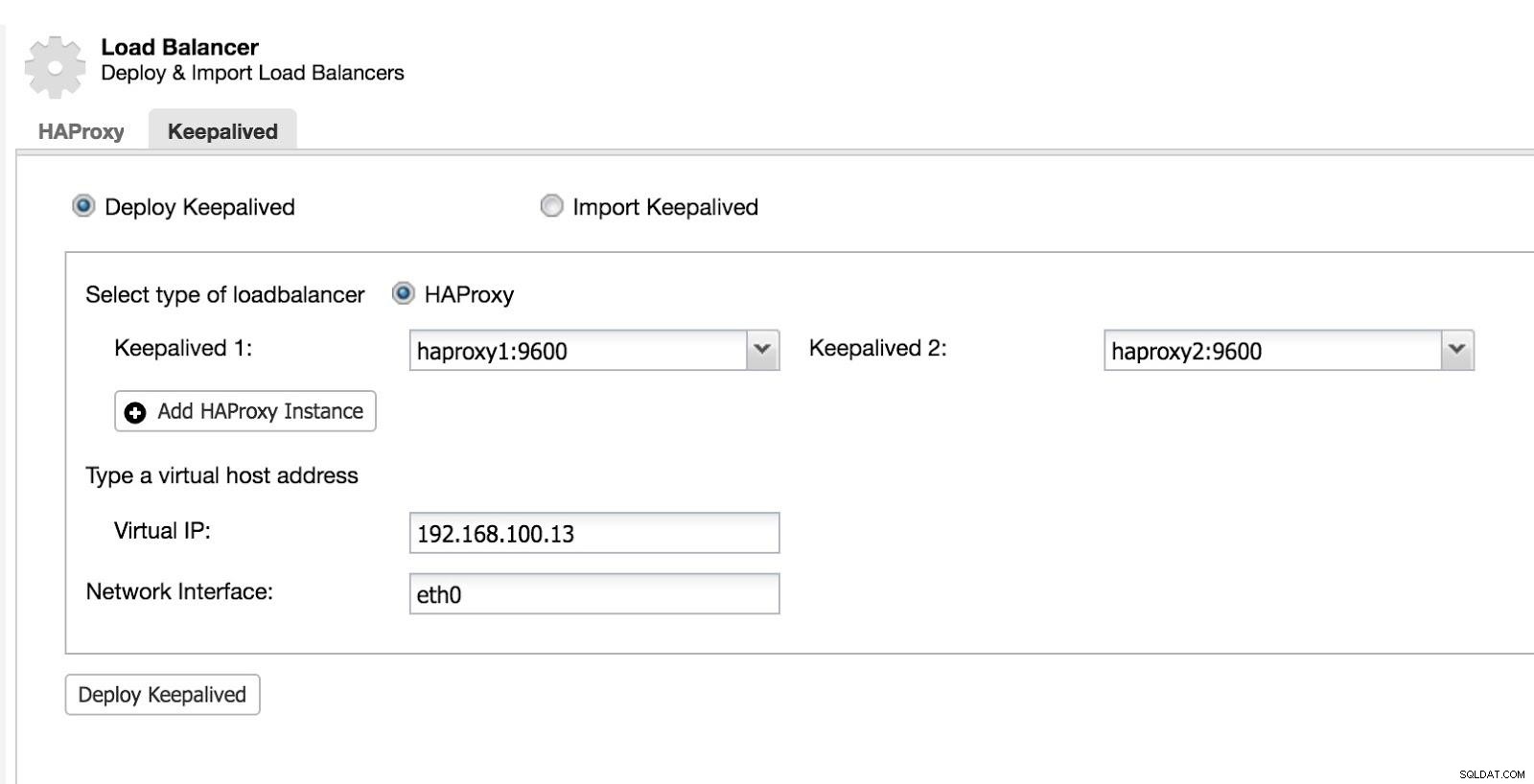 ClusterControlロードバランサー2
ClusterControlロードバランサー2 この後、次のトポロジが作成されます。
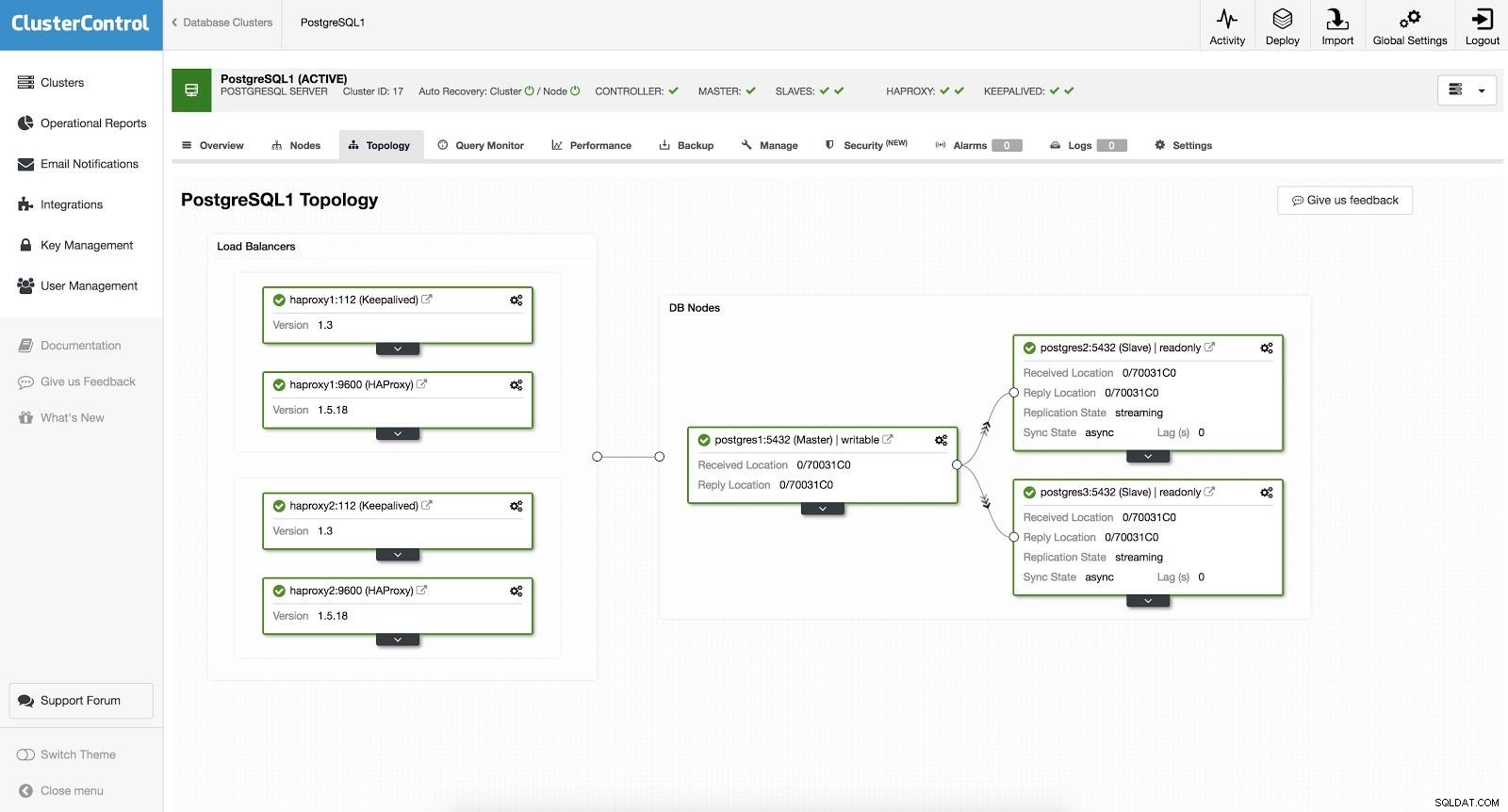 ClusterControlロードバランサー3
ClusterControlロードバランサー3 HAProxyは、読み取り/書き込みと読み取り専用の2つの異なるポートで構成されています。
読み取り/書き込みポートでは、マスターサーバーがオンラインで、残りのノードがオフラインになっています。読み取り専用ポートでは、マスターとスレーブの両方がオンラインになっています。このようにして、ノード間の読み取りトラフィックのバランスをとることができます。書き込み時には、マスターを指す読み取り/書き込みポートが使用されます。
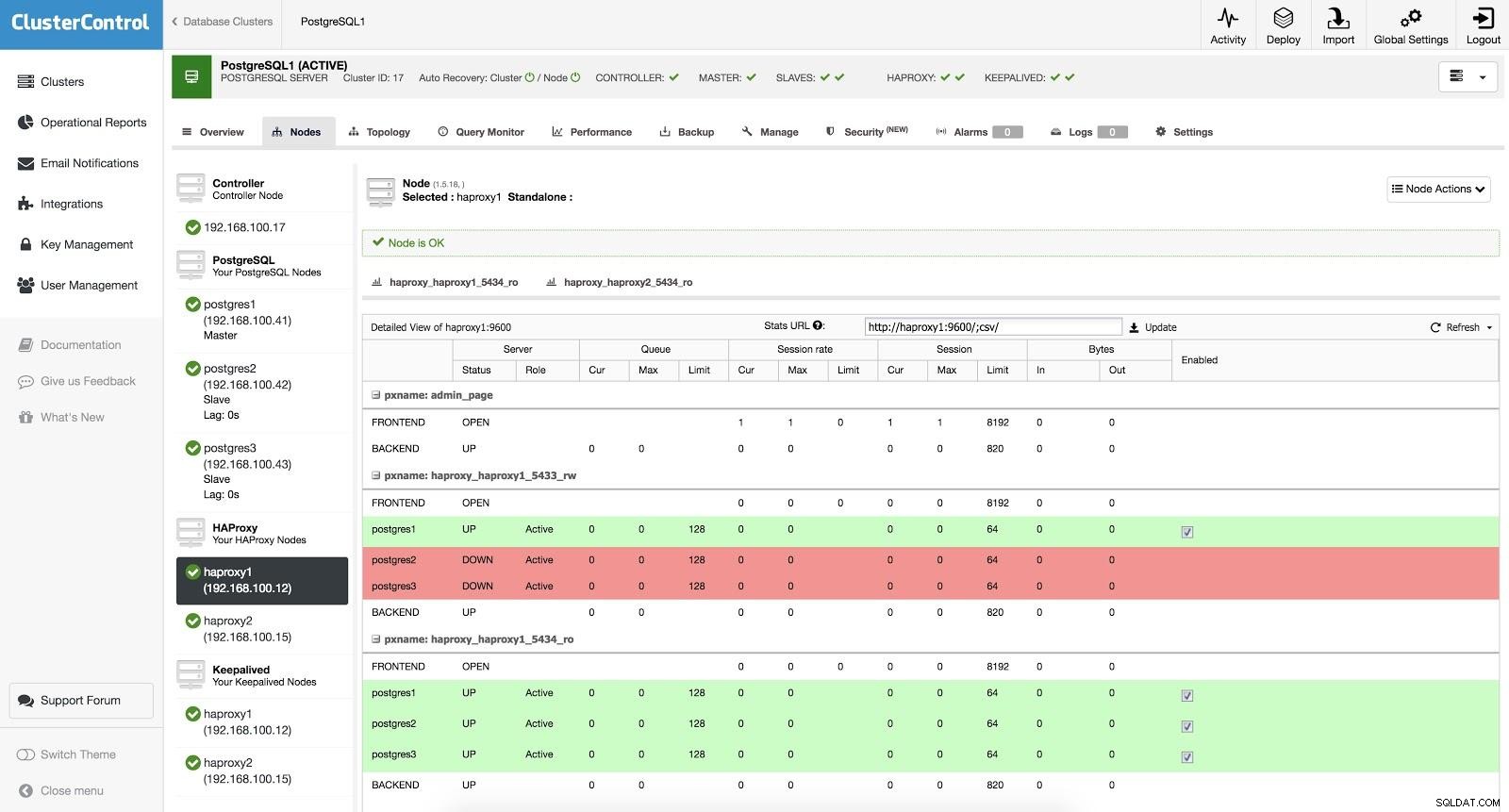 ClusterControlロードバランサー3
ClusterControlロードバランサー3 HAProxyは、マスターまたはスレーブのいずれかのノードにアクセスできないことを検出すると、自動的にオフラインとしてマークします。 HAProxyはそれにトラフィックを送信しません。このチェックは、デプロイメント時にClusterControlによって構成されたヘルスチェックスクリプトによって実行されます。これらは、インスタンスが稼働しているかどうか、回復中かどうか、または読み取り専用かどうかを確認します。
ClusterControlがスレーブをマスターにプロモートすると、HAProxyは古いマスターをオフライン(両方のポート)としてマークし、プロモートされたノードをオンライン(読み取り/書き込みポート)にします。このようにして、システムは引き続き正常に動作します。
アクティブなHAProxy(システムが接続する仮想IPアドレスが割り当てられている)に障害が発生した場合、KeepalivedはこのIPをパッシブなHAProxyに自動的に移行します。これは、システムが正常に機能し続けることができることを意味します。
結論
ご覧のとおり、フェイルオーバーは本番データベースの基本的な部分です。一般的なメンテナンスタスクや移行を実行するときに役立ちます。このブログがトピックの紹介として役立ち、独自のフェイルオーバー戦略を調査して作成できることを願っています。