監視は、どのシステムでも基本的なタスクの1つです。問題を検出してアクションを実行したり、単にシステムの現在の状態を知るのに役立ちます。ビジュアルディスプレイを使用すると、パフォーマンスの問題を簡単に検出できるため、より効果的になります。
このブログでは、SCUMMを使用してPostgreSQLデータベースを監視する方法と、このタスクに使用できるメトリックについて説明します。また、利用可能なダッシュボードについても説明するため、PostgreSQLインスタンスで実際に何が起こっているのかを簡単に把握できます。
SCUMMとは何ですか?
まず、SCUMM(Severalnines ClusterControl Unified Monitoring and Management)とは何かを見てみましょう。
これは、データベースノードにエージェントがインストールされた新しいエージェントベースのソリューションです。
SCUMMエージェントは、PostgreSQLなどのサービスからメトリックをPrometheusメトリックとしてエクスポートするPrometheusエクスポーターです。
Prometheusサーバーは、SCUMMエージェントから時系列データを取得して保存するために使用されます。
Prometheusは、もともとSoundCloudで構築されたオープンソースのシステム監視およびアラートツールキットです。現在はスタンドアロンのオープンソースプロジェクトであり、独立して維持されています。
Prometheusは信頼性を考慮して設計されており、停止時に問題を迅速に診断できるようにするためのシステムになります。
SCUMMの使い方は?
ClusterControlを使用する場合、クラスターを選択すると、データベースの概要と、問題を特定するために使用できるいくつかの基本的なメトリックを確認できます。以下のダッシュボードでは、1つのマスターと2つのスレーブ、HAProxyとKeepalivedを使用したマスタースレーブのセットアップを確認できます。
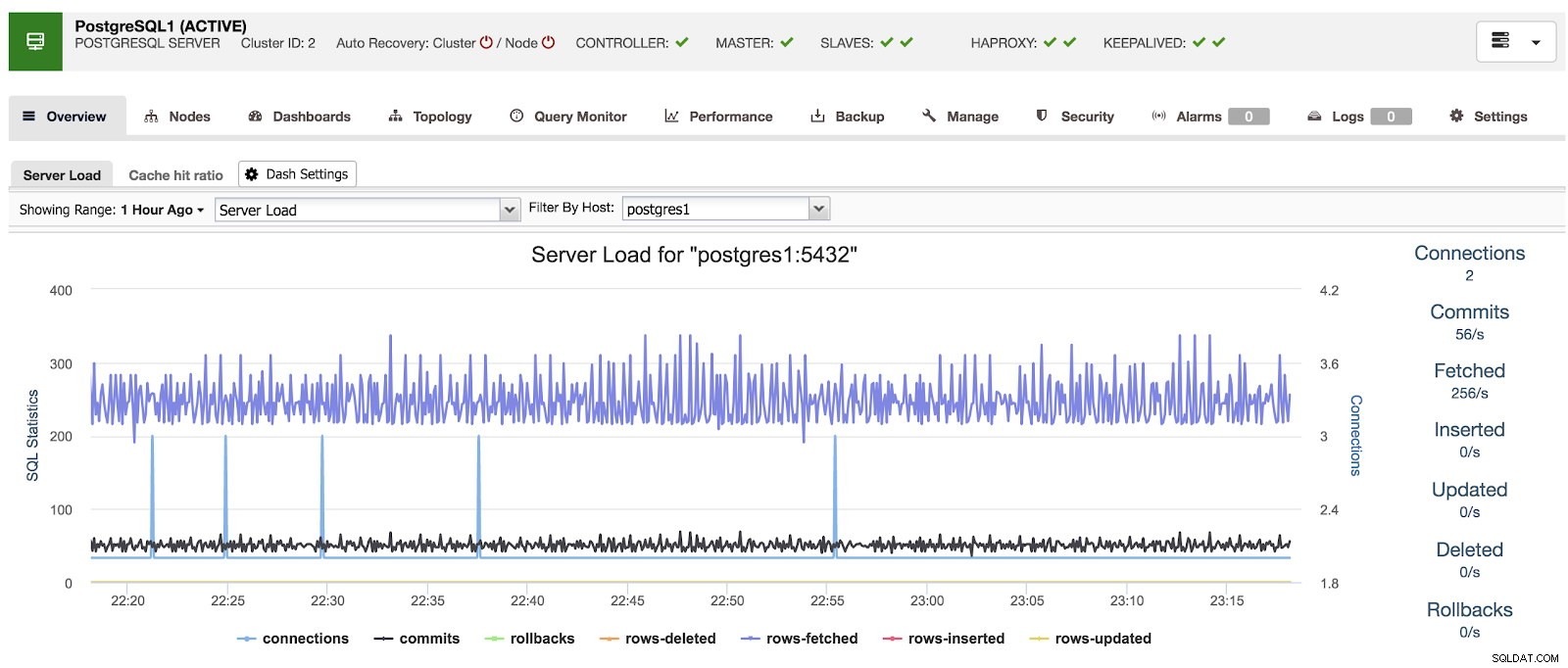 ClusterControlの概要
ClusterControlの概要 「ダッシュボード」オプションに移動すると、次のようなメッセージが表示されます。
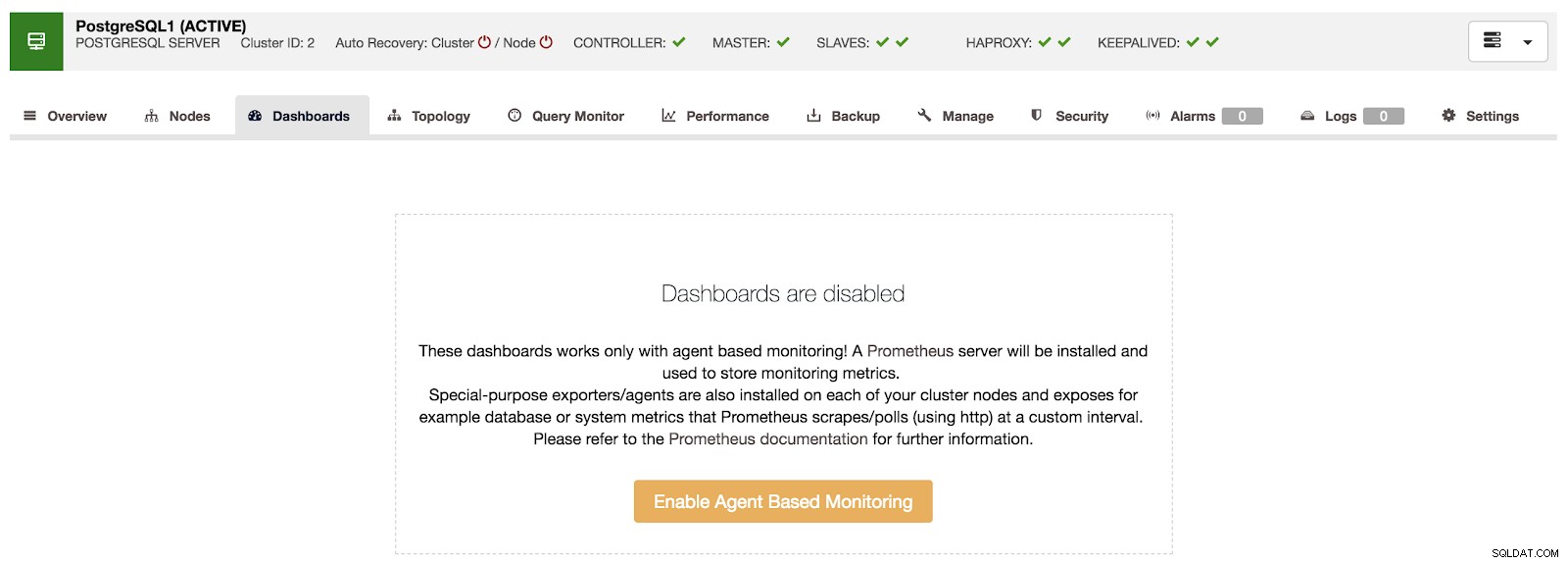 ClusterControlダッシュボードが無効になっています
ClusterControlダッシュボードが無効になっています この機能を使用するには、上記のエージェントを有効にする必要があります。このためには、このセクションの[エージェントベースの監視を有効にする]ボタンを押すだけです。
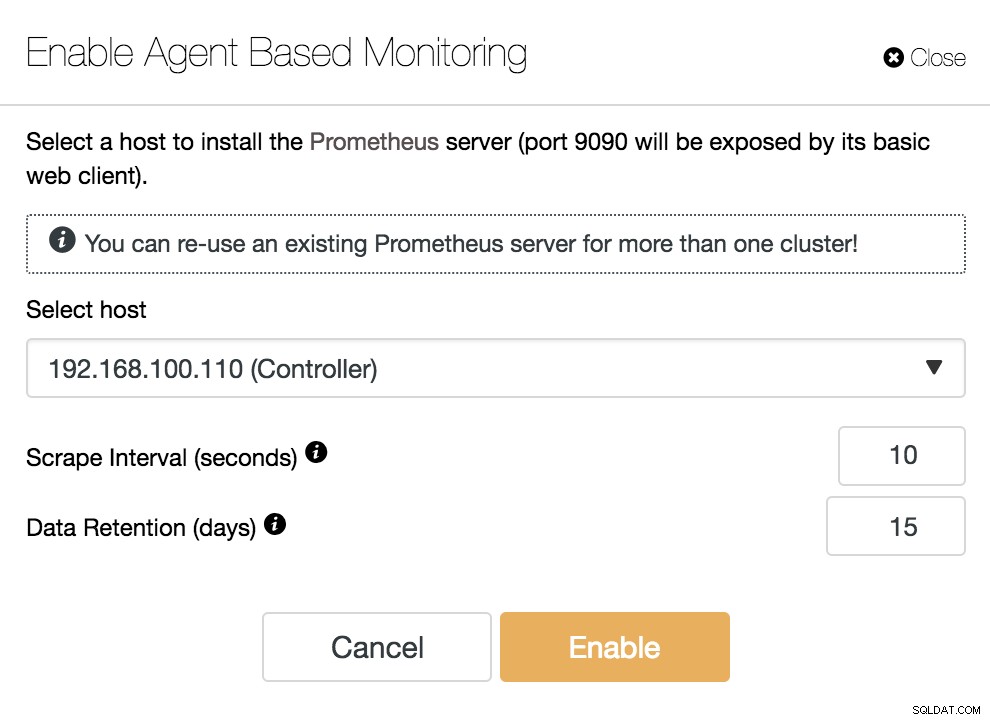 ClusterControlエージェントベースの監視を有効にする
ClusterControlエージェントベースの監視を有効にする エージェントを有効にするには、Prometheusサーバーをインストールするホストを指定する必要があります。このホストは、例でわかるように、ClusterControlサーバーにすることができます。
また、以下を指定する必要があります:
- スクレイプ間隔(秒):メトリックのためにノードがスクレイプされる頻度を設定します。デフォルトは10秒です。
- データ保持(日数):メトリックが削除されるまでに保持される期間を設定します。デフォルトは15日です。
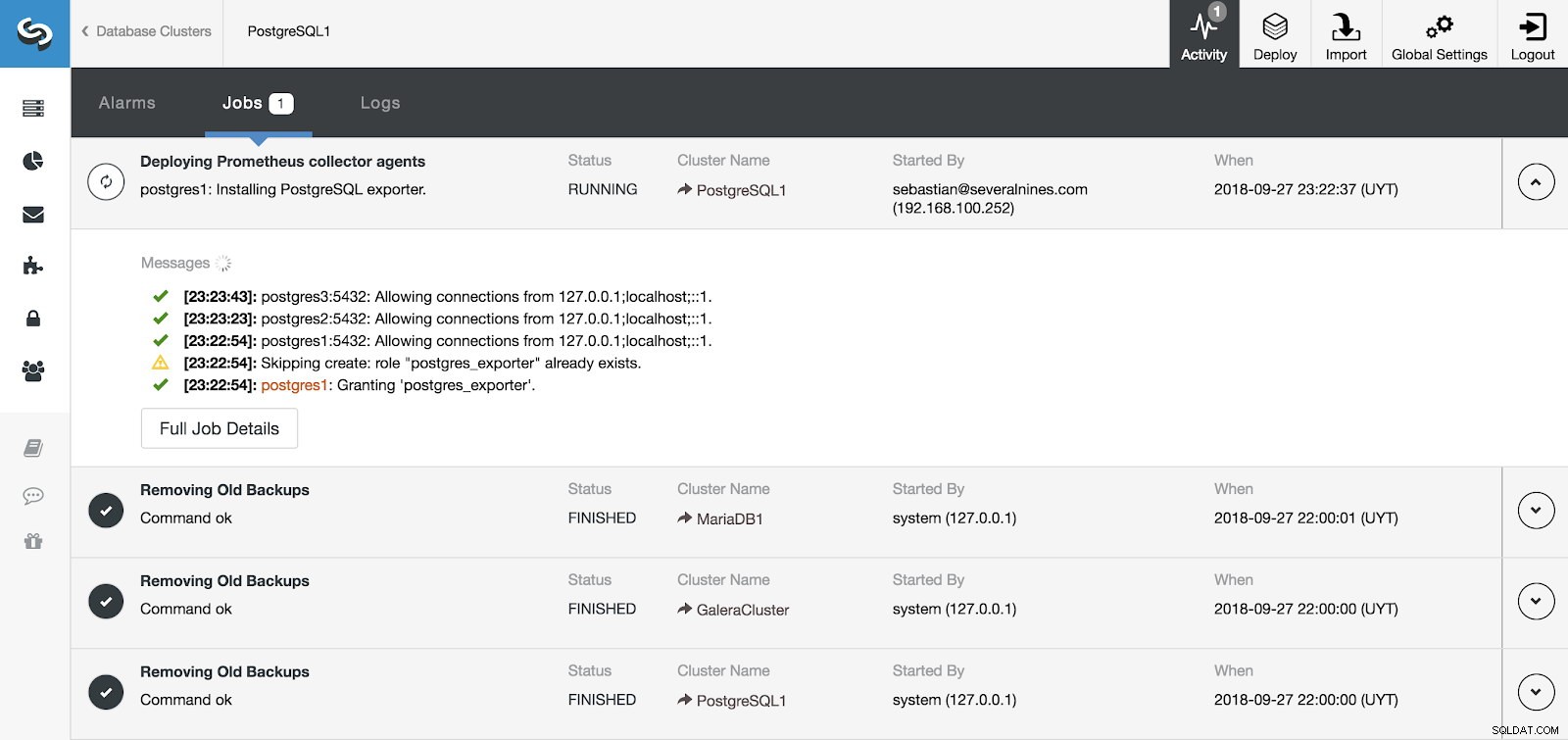 ClusterControlアクティビティセクション
ClusterControlアクティビティセクション ClusterControlの[アクティビティ]セクションからサーバーとエージェントのインストールを監視できます。完了したら、メインのClusterControl画面からエージェントが有効になっているクラスターを確認できます。
 ClusterControlエージェントを有効にする
ClusterControlエージェントを有効にする ダッシュボード
エージェントを有効にした状態で、[ダッシュボード]セクションに移動すると、次のように表示されます。
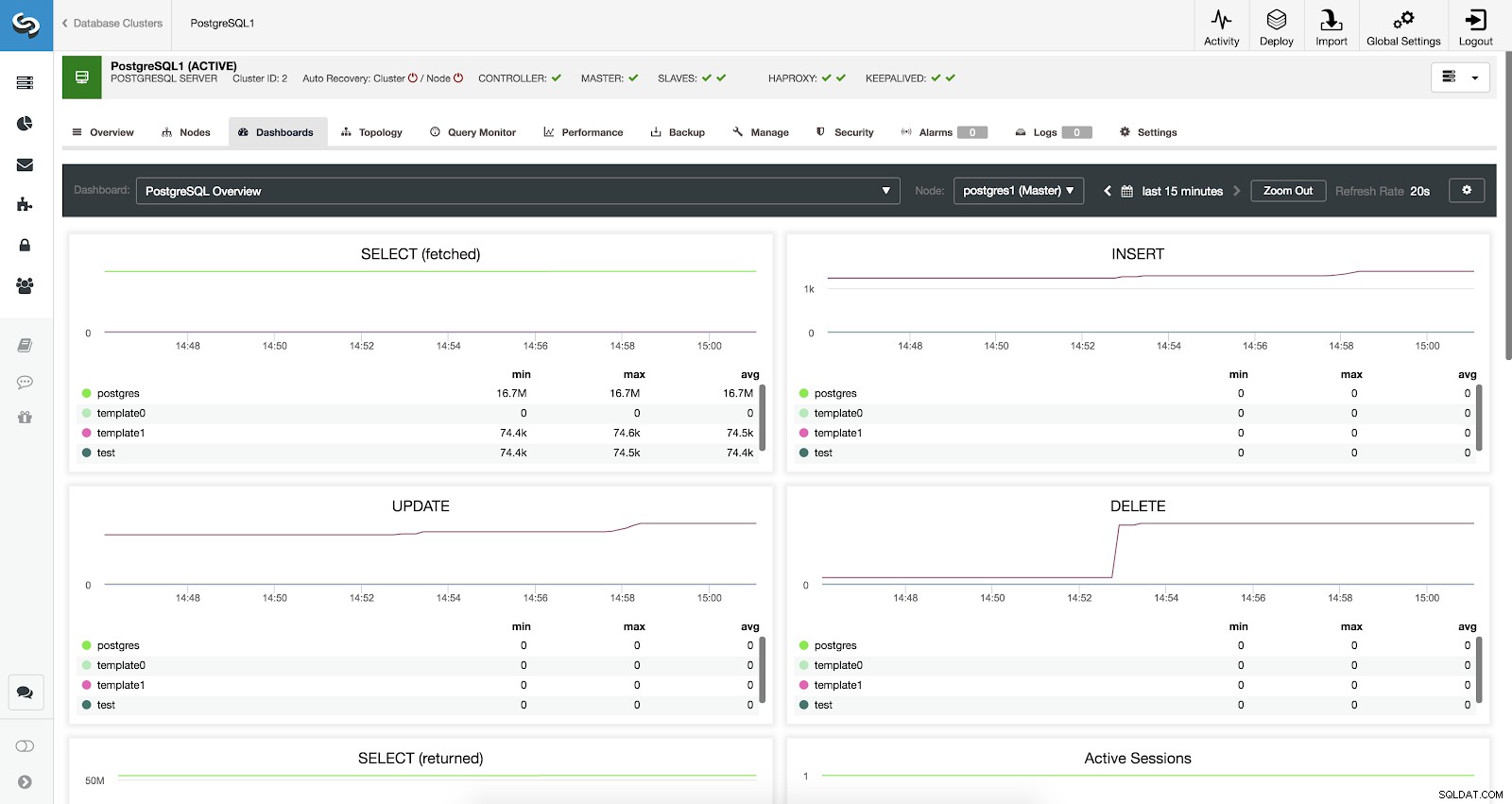 ClusterControlダッシュボードが有効
ClusterControlダッシュボードが有効 システムの概要、クロスサーバーグラフ、PostgreSQLの概要の3種類のダッシュボードを利用できます。最後のものは、このセクションに入るときにデフォルトで表示されるものです。
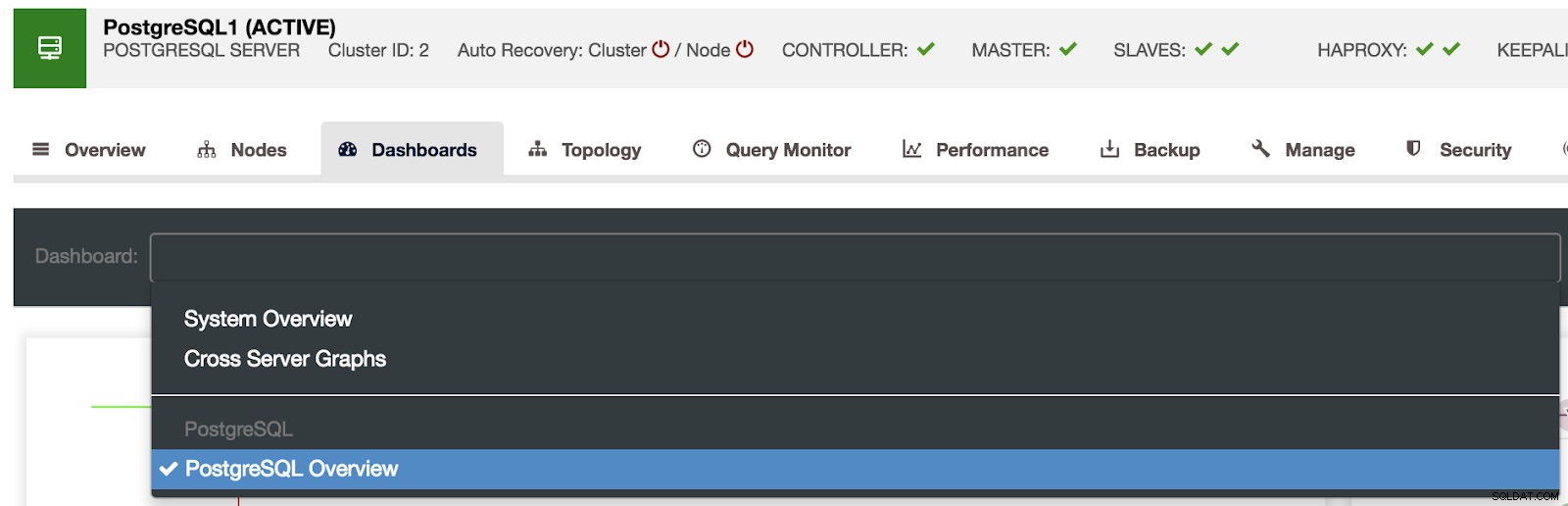 ClusterControlダッシュボードの選択
ClusterControlダッシュボードの選択 ここでは、監視するノード、時間範囲、リフレッシュレートを指定することもできます。
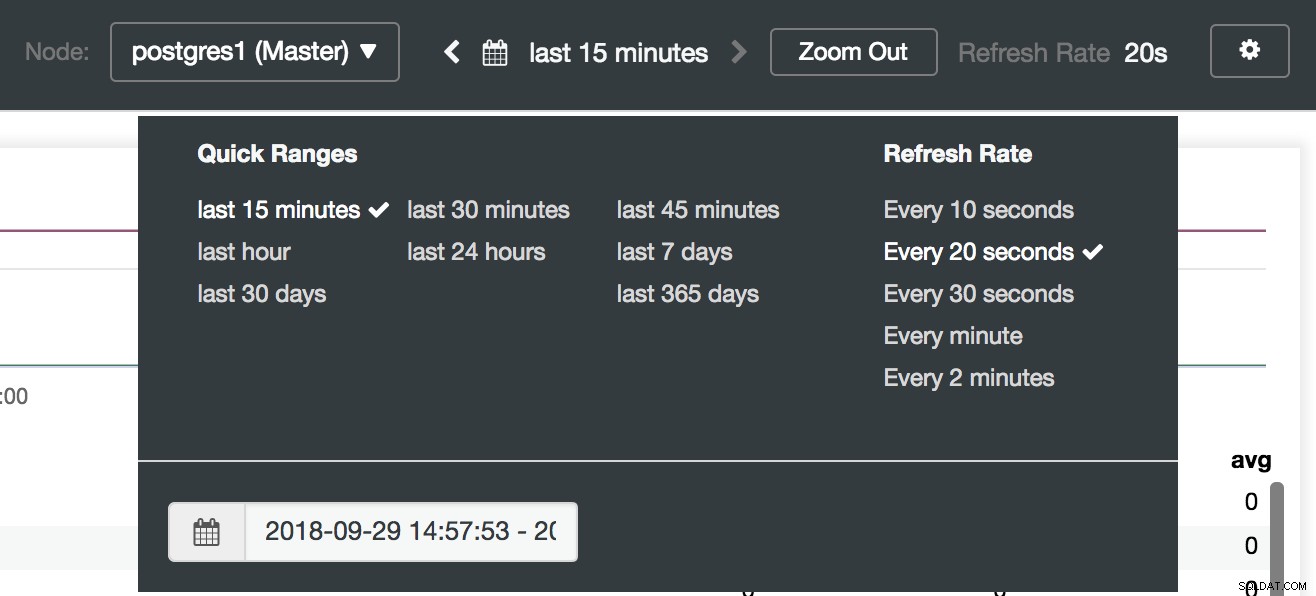 ClusterControlダッシュボードオプション
ClusterControlダッシュボードオプション 構成セクションでは、エージェント(エクスポーター)を有効または無効にし、エージェントのステータスを確認し、Prometheusサーバーのバージョンを確認できます。
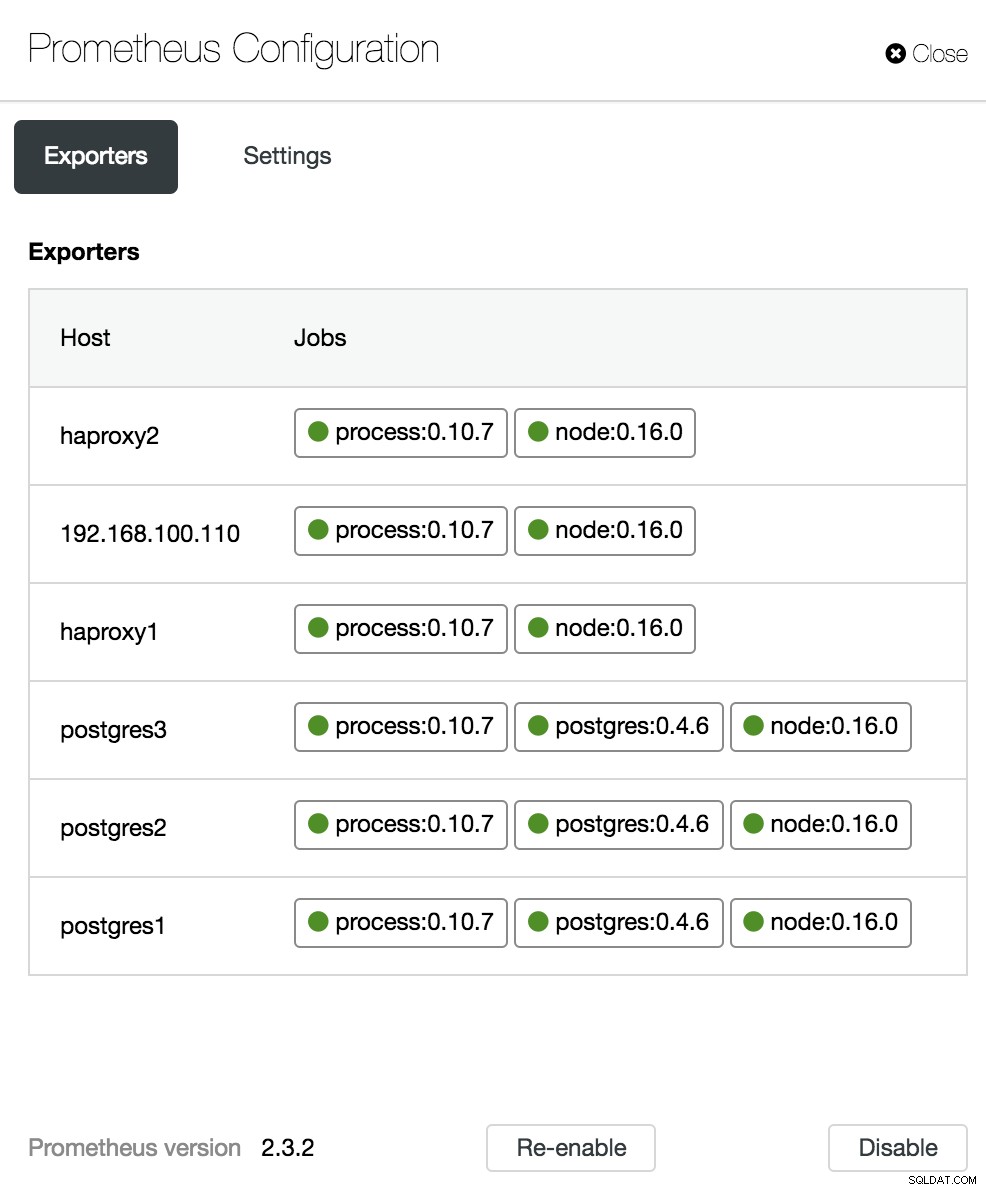 ClusterControlダッシュボードの構成
ClusterControlダッシュボードの構成 PostgreSQLの概要メトリクス
ここで、各PostgreSQLデータベース(選択したノードのすべてのデータベース)で使用できるメトリックを確認しましょう。
- SELECT(フェッチ済み):データベースごとに選択(フェッチ済み)された行の量。フェッチされた行は、テーブルからフェッチされたライブ行を参照します。
- SELECT(返された):データベースごとに選択された(返された)行の量。返される行は、テーブルから読み取られたすべての行を参照します。これには、デッド行が含まれ、まだコミットされていない行が含まれます(ライブタプルのみをカウントするフェッチされた行とは対照的です)。
- INSERT:データベースごとに挿入された行の量。
- UPDATE:データベースごとに更新された行の量。
- DELETE:データベースごとに削除された行の量。
- アクティブセッション:各データベースのアクティブセッションの量(最小、最大、平均)。
- アイドルセッション:各データベースのアイドルセッションの量(最小、最大、平均)。
- ロックテーブル:データベースごとにタイプ別に分けられたロックの量(最小、最大、平均)。
- ディスクIO使用率:サーバーディスクIO使用率。
- ディスク使用量:サーバーディスク使用率のパーセンテージ(最小、最大、平均)。
- ディスクレイテンシー:サーバーディスクレイテンシー。
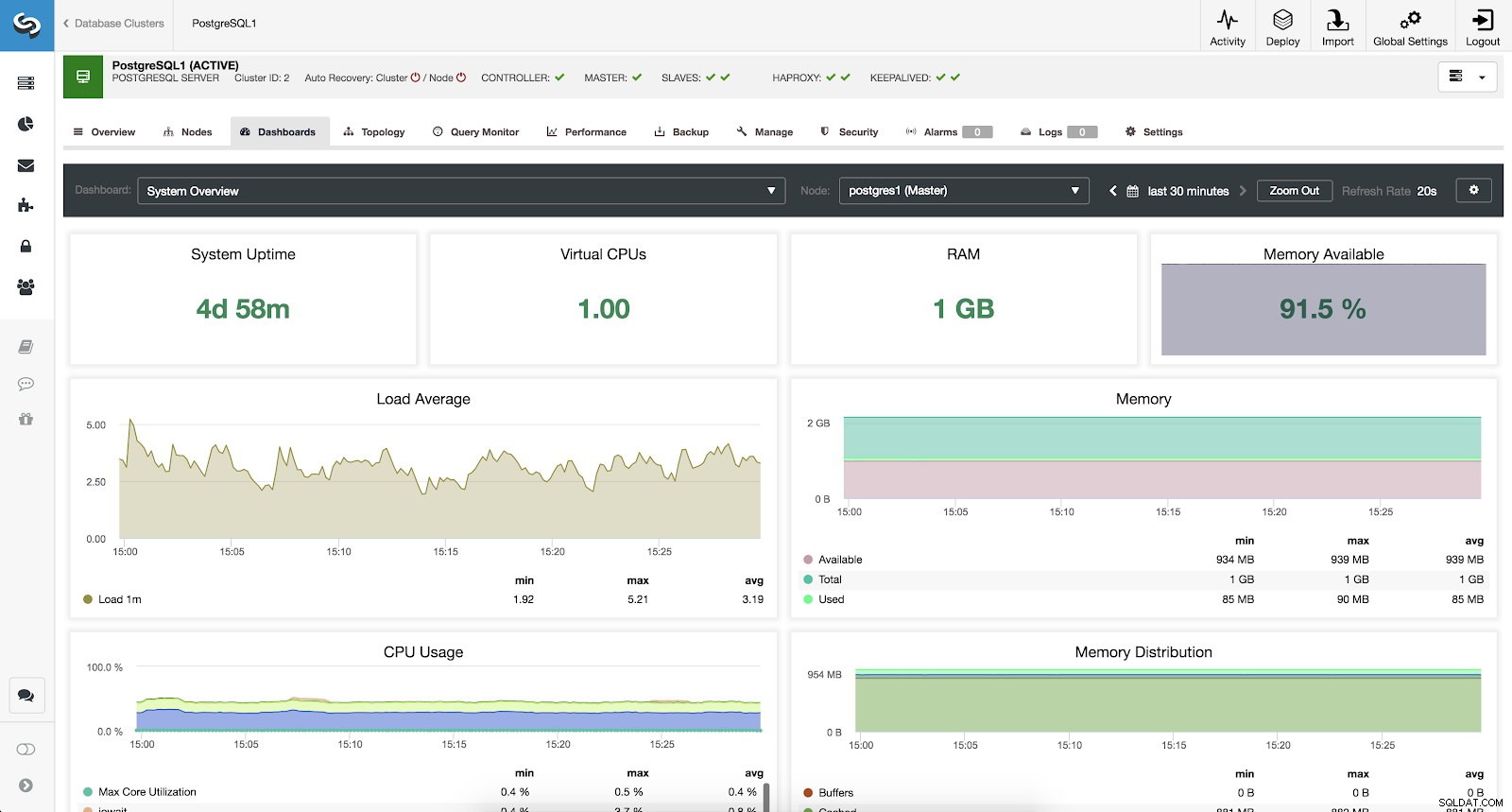
ClusterControlPostgreSQLの概要メトリクス システム概要メトリクス
システムを監視するために、サーバーごとに次のメトリックを使用できます(選択したノードのすべてのメトリック):
- システム稼働時間:サーバーが稼働してからの時間。
- CPU:CPUの数。
- RAM:RAMメモリの量。
- 使用可能なメモリ:使用可能なRAMメモリの割合。
- 平均負荷:最小、最大、平均のサーバー負荷。
- メモリ:使用可能な、合計および使用済みのサーバーメモリ。
- CPU使用率:サーバーの最小、最大、平均のCPU使用率情報。
- メモリ分散:選択したノードでのメモリ分散(バッファ、キャッシュ、空き、使用済み)。
- 飽和度メトリック:選択したノードのIO負荷とCPU負荷の最小、最大、平均。
- メモリの詳細:選択したノードのページ、バッファなどのメモリ使用量の詳細。
- フォーク:フォークプロセスの量。フォークは、プロセスがそれ自体のコピーを作成する操作です。これは通常、カーネルに実装されたシステムコールです。
- プロセス:オペレーティングシステムで実行中または待機中のプロセスの量。
- コンテキストスイッチ:コンテキストスイッチは、プロセスまたはスレッドの状態を保存するアクションです。
- 割り込み:割り込みの量。割り込みは、プログラムの通常の実行フローを変更するイベントであり、ハードウェアデバイスまたはCPU自体によって生成される可能性があります。
- ネットワークトラフィック:選択したノードでのインバウンドおよびアウトバウンドのネットワークトラフィック(キロバイト/秒)。
- 1時間ごとのネットワーク使用率:最終日に送受信されたトラフィック。
- スワップ:選択したノードでの使用量(無料および使用済み)をスワップします。
- スワップアクティビティ:スワップに関するデータの読み取りと書き込み。
- I / Oアクティビティ:IOでページインおよびページアウトします。
- ファイル記述子:ファイル記述子を割り当てて制限します。
 ClusterControlシステムの概要メトリック
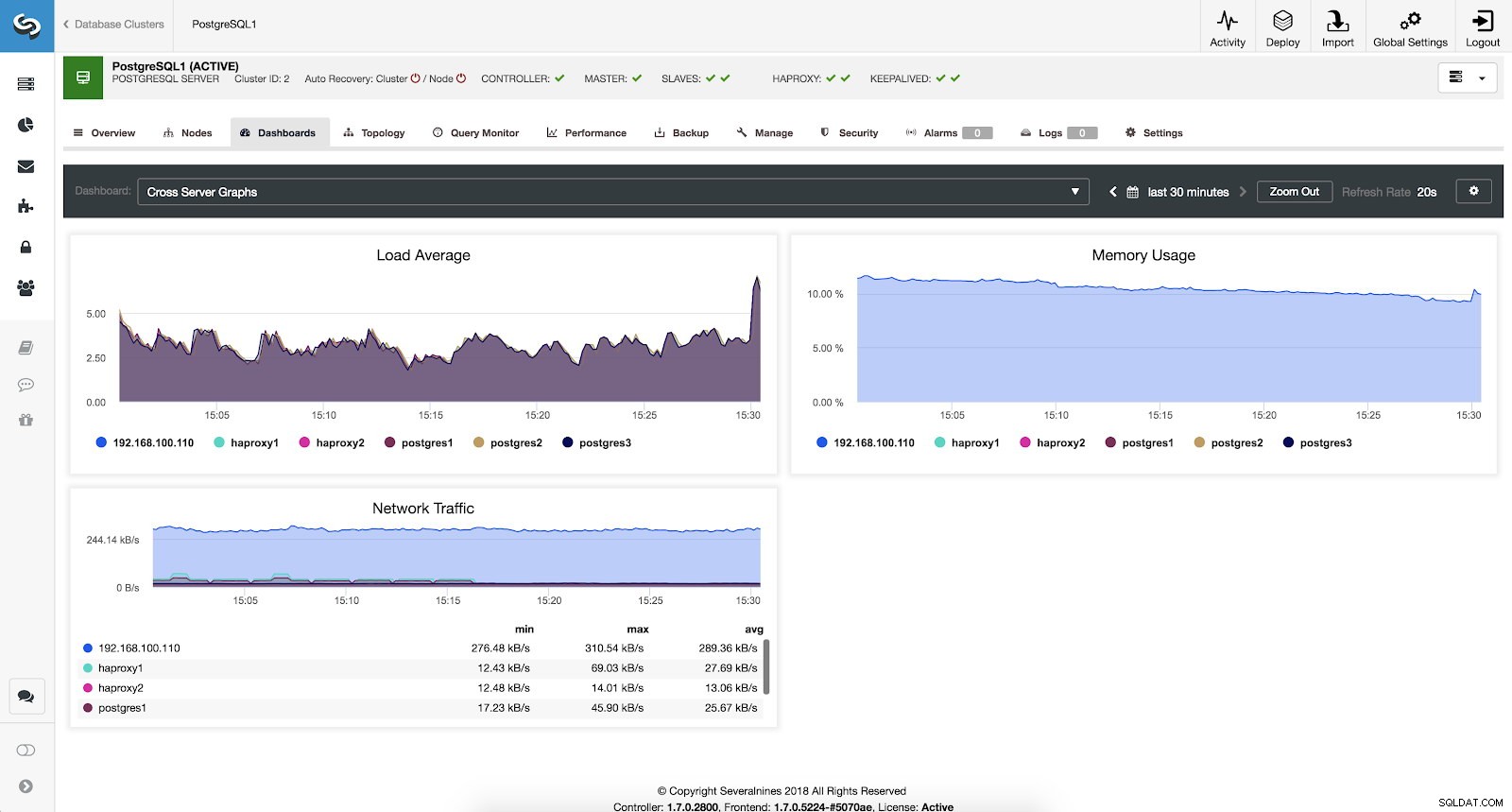
ClusterControlシステムの概要メトリック クロスサーバーグラフの指標
すべてのサーバーの一般的な状態を確認したい場合は、このダッシュボードを次のメトリックで使用できます。
- 平均負荷:サーバーは各サーバーの平均負荷です。
- メモリ使用量:各サーバーのメモリ使用量の割合。
- ネットワークトラフィック:1秒あたりのネットワークトラフィックの最小、最大、平均キロバイト。
 ClusterControlクロスサーバーグラフのメトリック
ClusterControlクロスサーバーグラフのメトリック 結論
PostgreSQLを監視する方法は複数あります。 ClusterControlは、Prometheusを介して、エージェントレスと現在のエージェントベースの両方の監視を提供します。高解像度の監視データと、データベースのパフォーマンスを理解するためのさまざまなダッシュボードを提供します。 ClusterControlは、アラート用にSlackやPagerDutyなどの外部ツールと統合することもできます。