現在、使用しているテクノロジーに関係なく、多くのシステムでは高可用性が必要です。重要なアプリケーションやシステムが依存するデータをデータベースに保存するため、これはデータベースにとって特に重要です。高可用性を実現するための最も一般的な戦略はレプリケーションです。たとえば、プライマリサーバーが応答を停止した場合に、複数のサーバー間でデータを複製し、トラフィックをフェイルオーバーするさまざまな方法があります。
PostgreSQLの高可用性アーキテクチャ
PostgreSQLに高可用性を実装するためのアーキテクチャはいくつかありますが、基本的なアーキテクチャはプライマリ-スタンバイアーキテクチャとプライマリ-プライマリアーキテクチャです。
Primary-Standbyは、セットアップできる最も基本的なHAアーキテクチャであり、多くの場合、実装と保守が最も簡単です。これは、1つ以上のスタンバイサーバーを備えた1つのプライマリデータベースに基づいています。これらのスタンバイデータベースは、レプリケーションが同期であるか非同期であるかに応じて、プライマリノードと同期(またはほぼ同期)されたままになります。プライマリサーバーに障害が発生した場合、スタンバイサーバーにはプライマリサーバーのデータのほとんどすべてが含まれており、すぐに新しいプライマリデータベースサーバーに変えることができます。
レプリケーションの性質に基づいて、2種類のスタンバイデータベースを実装できます。
- 論理スタンバイ–プライマリとスタンバイ間のレプリケーションはSQLステートメントを介して行われます。
- 物理スタンバイ–プライマリとスタンバイ間のレプリケーションは、内部データ構造の変更を介して行われます。
PostgreSQLの場合、先行書き込みログ(WAL)レコードのストリームを使用して、スタンバイデータベースの同期を維持します。これは同期または非同期であり、データベースサーバー全体が複製されます。
バージョン10以降、PostgreSQLには、先行書き込みログの情報から論理データ変更のストリームを構築する論理レプリケーションを設定するための組み込みオプションが含まれています。このレプリケーション方法では、プライマリサーバーを指定しなくても、個々のテーブルからのデータ変更をレプリケートできます。また、データを複数の方向に流すこともできます。
残念ながら、プライマリスタンバイのセットアップでは、障害を処理する必要があるため、高可用性を効果的に確保するには不十分です。障害を処理するには、障害を検出できる必要があります。プライマリノードのエラーや応答しないノードなどの障害があることがわかったら、スタンバイノードを選択して、障害が発生したノードを可能な限り最小の遅延で置き換えることができます。このプロセスは、アプリケーションの全機能を復元するために可能な限り効率的である必要があります。 PostgreSQL自体には自動フェイルオーバーメカニズムが含まれていないため、この自動化にはカスタムスクリプトまたはサードパーティツールが必要になります。
フェイルオーバーが発生した後、新しいプライマリの使用を開始するには、それに応じてアプリケーションに通知する必要があります。また、フェイルオーバー後のアーキテクチャの状態を評価する必要があります。これは、新しいプライマリのみが実行されている状況に遭遇する可能性があるためです(たとえば、問題が発生する前にプライマリノードとスタンバイが1つしかなかった場合)。その場合、スタンバイノードを追加して、高可用性のために元々持っていたプライマリスタンバイセットアップを再作成する必要があります。
Primary-Primaryアーキテクチャは、他のノードがすべてのトラフィックを処理できるため、一方のノードでのエラーの影響を最小限に抑える方法を提供しますが、パフォーマンスにわずかな影響を与える可能性があります。しかし、機能を失うことはありません。プライマリ-プライマリアーキテクチャは、高可用性環境を作成し、水平方向にスケーリングするという2つの目的で使用されることがよくあります(サーバーにリソースを追加する垂直スケーラビリティの概念と比較して)。
PostgreSQLはまだこのアーキテクチャを「ネイティブに」サポートしていないため、サードパーティのツールと実装を参照する必要があります。ソリューションを選択するときは、多くのプロジェクト/ツールがあることに注意する必要がありますが、それらの一部はサポートされなくなっていますが、その他は新しく、本番環境でのバトルテストが行われていない可能性があります。
ロードバランサーは、アプリケーションからのトラフィックを管理してデータベースアーキテクチャを最大限に活用するために使用できるツールです。
これらのツールは、データベースの負荷のバランスを取るのに役立つだけでなく、アプリケーションが使用可能な/正常なノードにリダイレクトされ、異なる役割を持つポートを指定するのにも役立ちます。
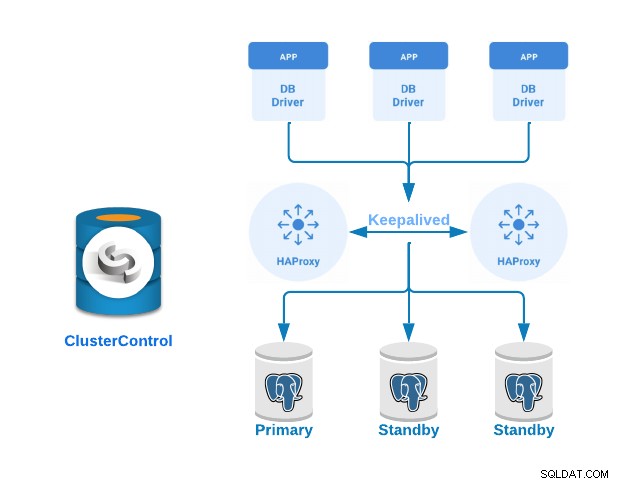
HAProxyは、1つの発信元から1つ以上の宛先にトラフィックを分散し、このタスクの特定のルールやプロトコルを定義できるロードバランサーです。いずれかの宛先が応答を停止すると、それらはオフラインとしてマークされ、トラフィックは残りの利用可能な宛先に送信されます。
Keepalivedは、サーバーのアクティブ/パッシブグループ内で仮想IPアドレスを構成できるようにするサービスです。この仮想IPアドレスは、アクティブなサーバーに割り当てられます。このサーバーに障害が発生した場合、IPアドレスは自動的に「セカンダリ」パッシブサーバーに移行され、システムに対して透過的な方法で同じIPアドレスを引き続き使用できるようになります。
ここで、ロードバランサーサーバーとそれらの間にキープアライブを構成したプライマリスタンバイPostgreSQLクラスターを実装する方法を見てみましょう。 ClusterControlの使いやすいインターフェースを使用してこれをデモンストレーションします。
この例では、以下を作成します:
- 3台のPostgreSQLサーバー(1台のプライマリサーバーと2台のスタンバイ)
- 2つのHAProxyロードバランサー。
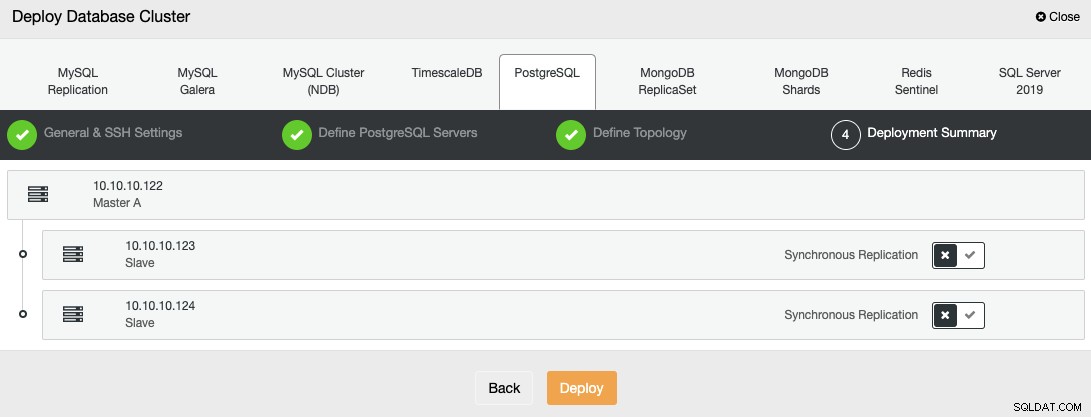
ClusterControlを使用してデータベースをデプロイするには、[デプロイ]オプションを選択し、表示される指示に従います。
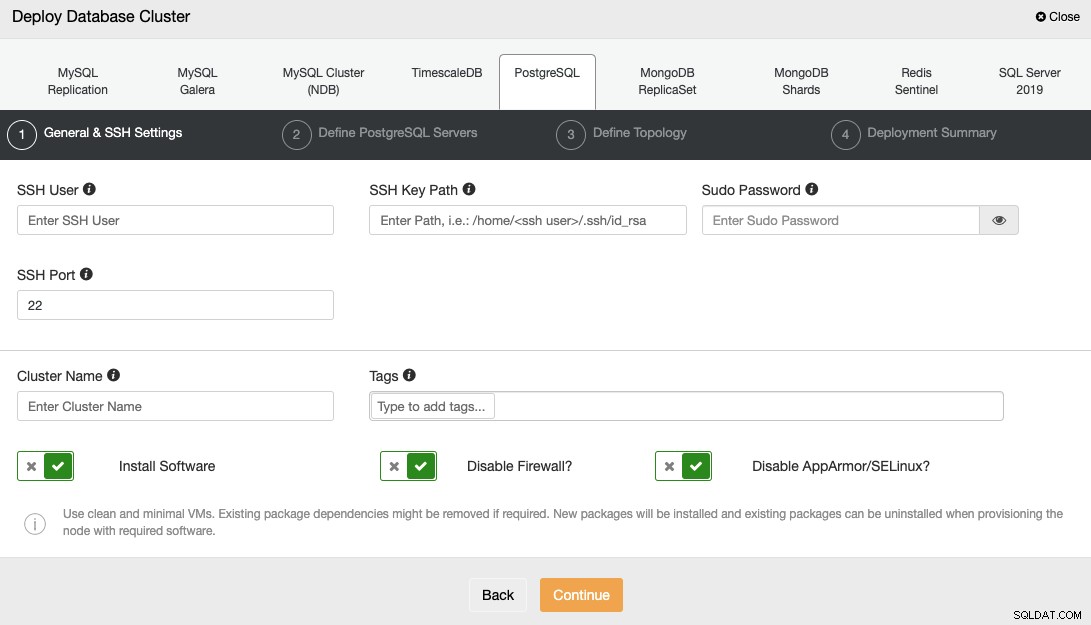
PostgreSQLを選択するときは、ユーザー、キー、またはパスワードを指定する必要があります。 SSHでサーバーに接続するためのポート。また、新しいクラスターの名前が必要であり、ClusterControlに対応するソフトウェアと構成をインストールするかどうかを選択します。
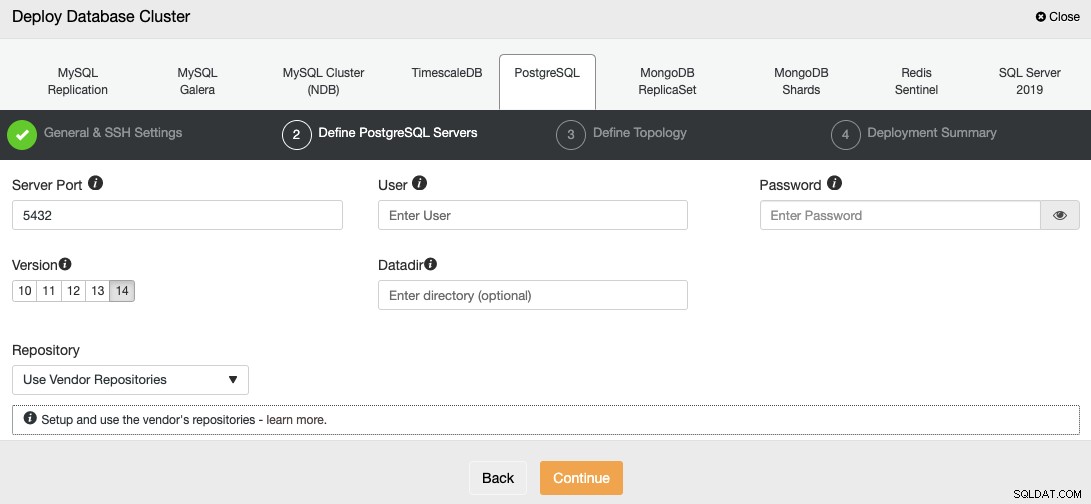
SSHアクセス情報を設定した後、データベースユーザーを定義する必要があります。 version、およびdatadir(オプション)。使用するリポジトリを指定することもできます。デフォルトでは、公式のベンダーリポジトリが使用されます。
次のステップでは、作成するクラスターにサーバーを追加する必要があります。
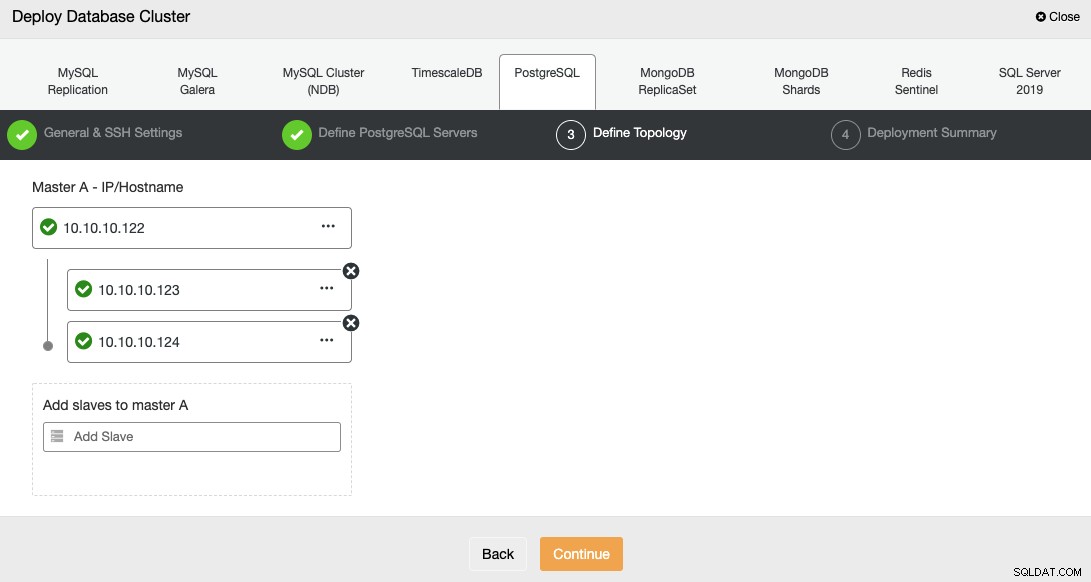
サーバーを追加するときに、IPまたはホスト名を入力できます。
>最後のステップで、レプリケーションを同期にするか非同期にするかを選択できます。
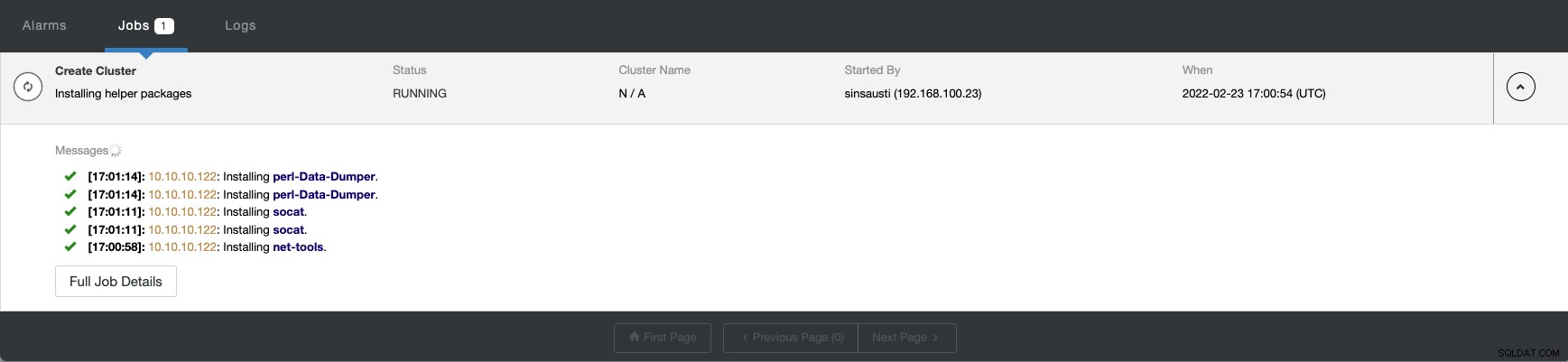
ClusterControlから新しいクラスターの作成ステータスを監視できますアクティビティモニター。
タスクが完了すると、メインのClusterControlにクラスターが表示されます。画面。
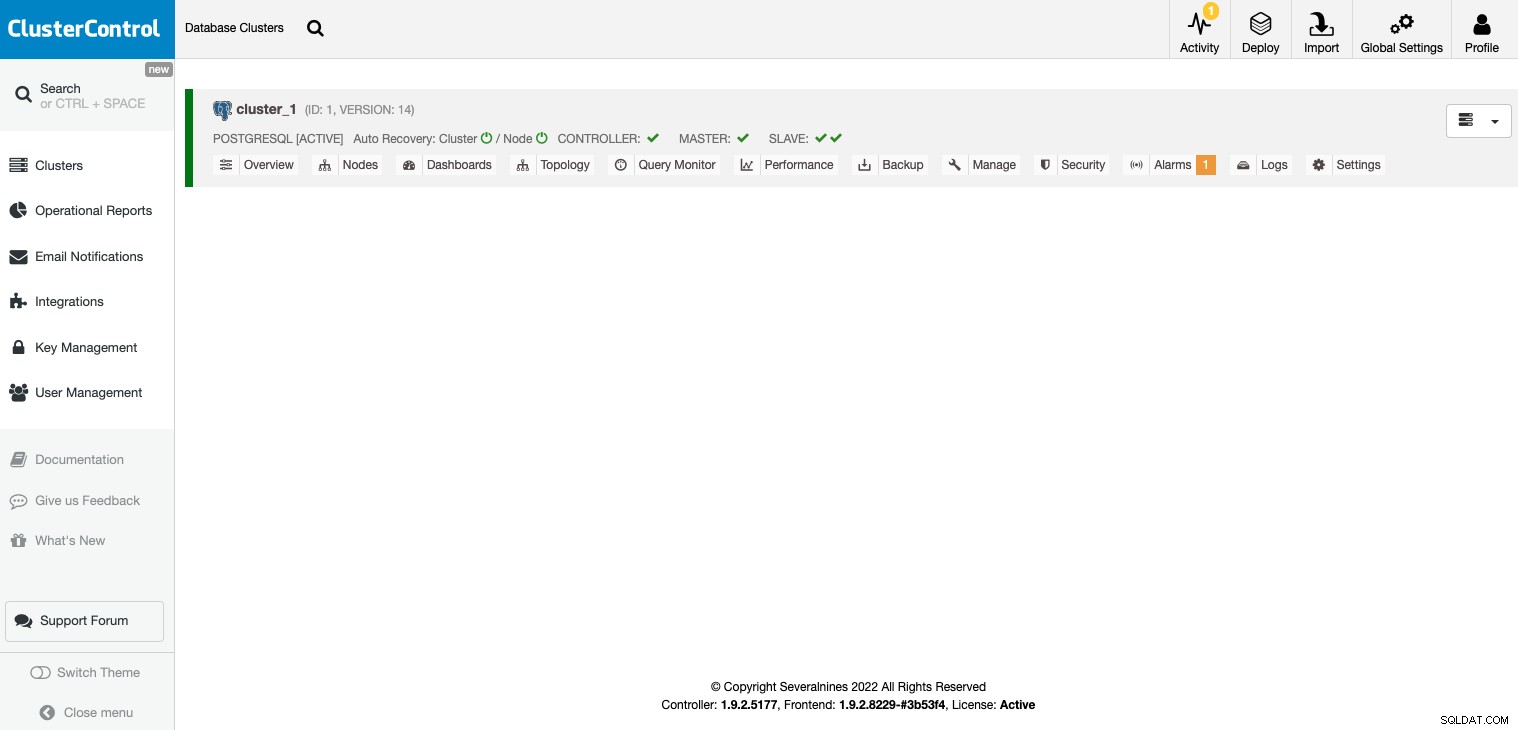
クラスターが作成されると、次のようないくつかのタスクを実行できます。ロードバランサー(HAProxy)または新しいレプリカ。
ロードバランサーのデプロイを実行するには、クラスターアクションで[ロードバランサーの追加]オプションを選択し、要求された情報を入力します。
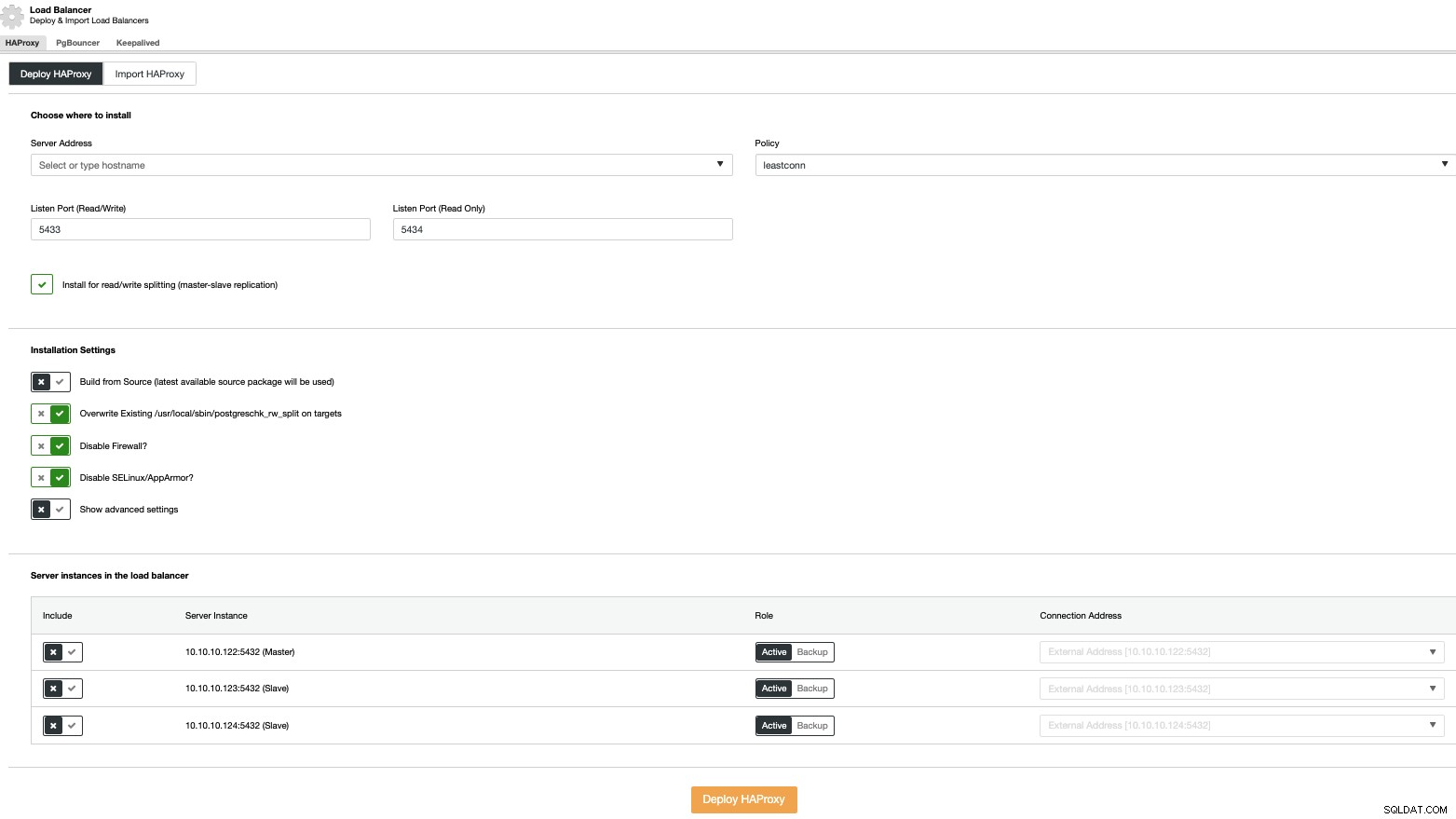
必要なのは、IPアドレスまたはホスト名、ポート、ポリシー、ロードバランサーで構成するノード。
キープアライブ展開を実行するには、クラスターを選択し、[管理]メニューと[ロードバランサー]セクションに移動して、[キープアライブ]オプションを選択します。
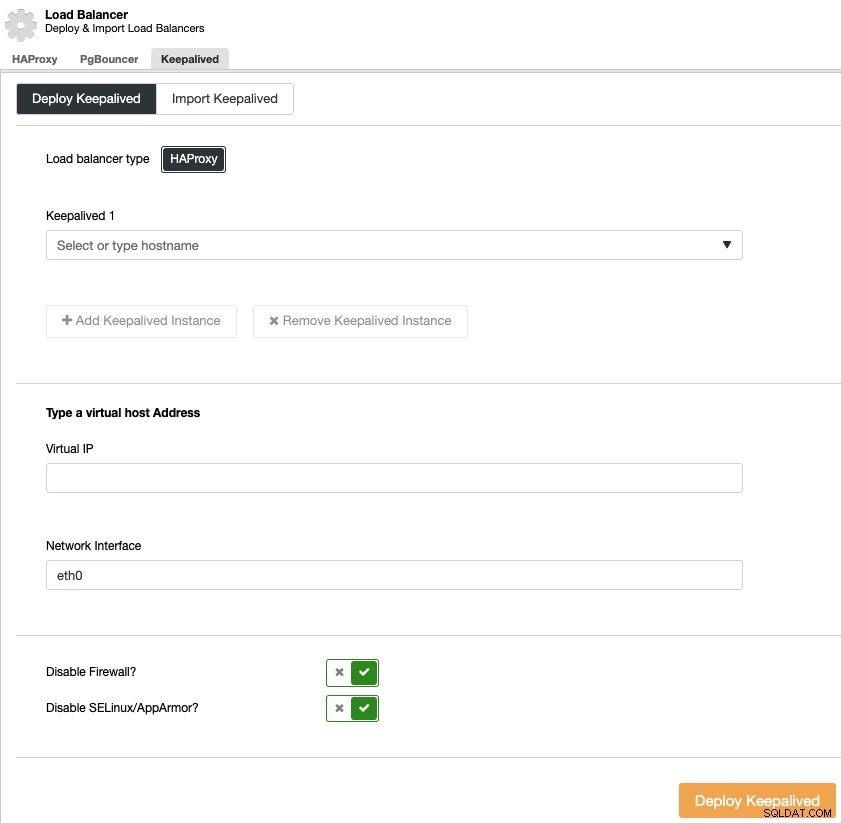
高可用性のロードバランサーサーバーと仮想IPアドレスを選択する必要があります可用性環境。
Keepalivedは仮想IPアドレスを使用し、障害が発生した場合に1つのロードバランサーから別のロードバランサーに移行するため、システムは引き続き正常に機能します。
前の手順に従った場合は、次のトポロジが必要です。
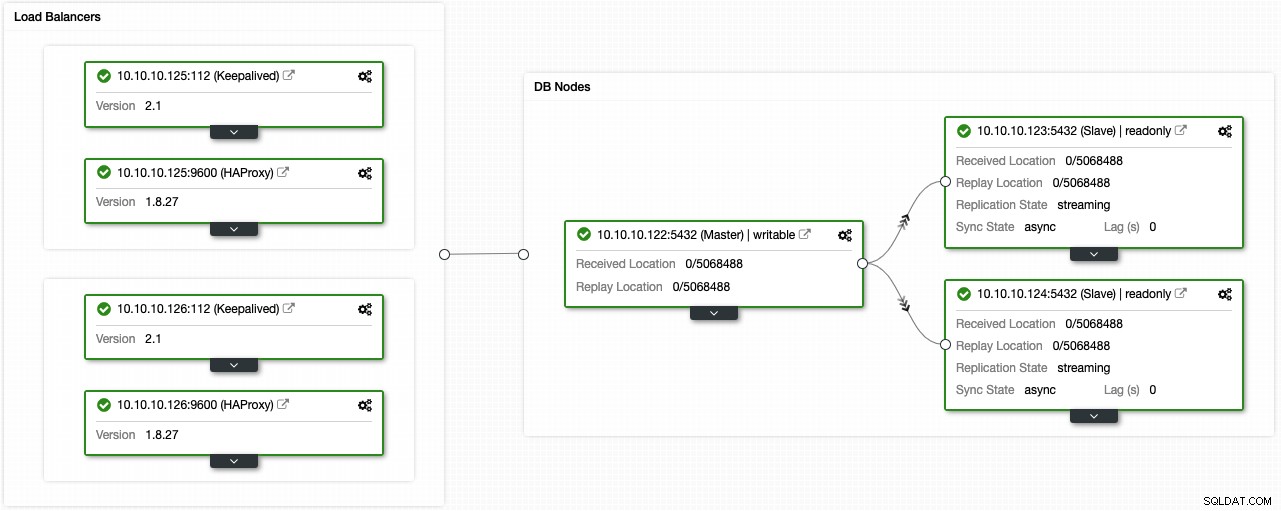
PgBouncerのような接続プールを追加することで、この高可用性環境を改善できます。必須ではありませんが、パフォーマンスを向上させ、障害が発生した場合にアクティブな接続を処理するのに役立つ可能性があります。最も良いのは、ClusterControlを使用してデプロイすることもできることです。
ClusterControlフェイルオーバー
ClusterControlサーバーで「自動回復」オプションがオンになっているとします。プライマリに障害が発生した場合、ClusterControlは最も高度なスタンバイ(ブラックリストにない場合)をプライマリに昇格させ、問題を通知します。また、残りのスタンバイノードをフェイルオーバーして、新しいプライマリから複製します。
HAProxyは、デフォルトで2つの異なるポートで構成されています。読み取り/書き込みおよび読み取り専用ポート。
読み取り/書き込みポートでは、プライマリサーバーがオンラインで、残りのノードがオフラインであり、読み取り専用ポートでは、プライマリサーバーとスタンバイの両方がオンラインです。
>HAProxyは、プライマリまたはスタンバイのいずれかのノードにアクセスできないことを検出すると、自動的にオフラインとしてマークします。トラフィックを送信する際には考慮されません。検出は、ClusterControlがデプロイメント時に構成するヘルスチェックスクリプトによって実行されます。これらは、インスタンスが稼働しているかどうか、回復中かどうか、または読み取り専用かどうかを確認します。
ClusterControlがスタンバイをプライマリにプロモートすると、HAProxyは両方のポートで古いプライマリをオフラインとしてマークし、プロモートされたノードを読み取り/書き込みポートでオンラインにします。
システムが接続する仮想IPアドレスを割り当てたアクティブHAProxyに障害が発生した場合、KeepalivedはこのIPアドレスをパッシブHAProxyに自動的に移行します。これは、システムが正常に機能し続けることができることを意味します。
このようにして、システムは手動で介入しなくても期待どおりに動作し続けます。
障害が発生した古いプライマリノードを回復できた場合、デフォルトではクラスターに自動的に再導入されません。手動で行う必要があります。この理由の1つは、障害発生時にレプリカが遅延し、ClusterControlが古いプライマリをクラスターに追加した場合、ノード間での情報の損失またはデータの不整合を意味するためです。また、問題を詳細に分析することもできます。 ClusterControlが障害のあるノードをクラスターに再導入しただけの場合、診断情報が失われる可能性があります。
また、フェイルオーバーが失敗した場合、それ以上の試行は行われません。問題を分析し、対応するアクションを実行するには、手動による介入が必要です。これは、高可用性マネージャーとしてのClusterControlが次のスタンバイと次のスタンバイをプロモートしようとする状況を回避するためです。問題がある可能性があるため、これを確認する必要があります。
高可用性環境で本番環境に移行する前に忘れてはならない重要なことの1つは、セキュリティを確保することです。
考慮すべきセキュリティの側面には、暗号化、役割管理、IPアドレスによるアクセス制限などがあります。これについては、以前のブログで詳しく説明しました。
PostgreSQLデータベースには、クライアント認証を処理するpg_hba.confファイルがあります。接続の種類、送信元IPアドレスまたはネットワーク、接続できるデータベース、およびユーザーを制限できます。したがって、このファイルはPostgreSQLのセキュリティにとって重要な部分です。
postgresql.confファイルからPostgreSQLデータベースを構成できるため、特定のネットワークインターフェイスと、デフォルトのポート(5432)とは異なるポートでのみリッスンするため、不要なソースからの基本的な接続試行を回避できます。 。
安全なパスワードを使用するか、アクセスと特権を制限する適切なユーザー管理は、セキュリティ設定のもう1つの重要な部分です。すべてのユーザーに可能な限り最小限の特権を割り当て、可能であれば接続のソースを指定することをお勧めします。
転送中または保存中のデータ暗号化を有効にして、権限のない人が情報にアクセスするのを防ぐこともできます。
監査ログは、データベースで何が起こっているか、または何が起こったかを理解するのに役立ちます。 PostgreSQLでは、ロギング用にいくつかのパラメーターを構成したり、このタスクにpgAudit拡張機能を使用したりすることができます。
最後になりましたが、セキュリティリスクを回避するために、データベースとサーバーを最新のパッチで最新の状態に保つことをお勧めします。このため、ClusterControlを使用すると、運用レポートを生成して、利用可能な更新があるかどうかを確認したり、データベースサーバーの更新に役立てたりすることができます。
特に、さまざまなアーキテクチャとそれらを正しく構成するために必要なコンポーネントを理解する場合、高可用性の展開を実現するのは難しいように思われる場合があります。
HAを手動で管理している場合は、PostgreSQLのレプリケーショントポロジの変更の実行を確認してください。多くの人が、完全な高可用性環境のためのデプロイメント、ロードバランサー、フェイルオーバー、セキュリティなどの管理に役立つClusterControlなどのツールを探します。 ClusterControlを30日間無料でダウンロードして、高可用性データベースインフラストラクチャの管理の負担を軽減する方法を確認できます。
ただし、高可用性PostgreSQLデータベースを管理することを選択した場合は、TwitterまたはLinkedInでフォローするか、ニュースレターを購読して、データベース設定を管理するための最新の更新とベストプラクティスを入手してください。