異なるサーバーにデータベースクラスターを展開すると、データの可用性を向上させるというレプリケーションの利点が得られます。ただし、プロセスを追跡し、それらが実行されているかどうかを確認する必要があります。このプロセスで使用されるプログラムの1つは、特定のクラスター内の1つ以上のシステム上のリソースの存在をチェックおよび検証する機能を備えたHeartbeatです。 PostgreSQLとPostgreSQLデータが保存されているファイルシステムに加えて、DRBDは、Heartbeatプログラムの使用方法についてこの記事で説明するリソースの1つです。
HAハートビート
DRBDブログで前述したように、データの高可用性は、サーバーのさまざまなインスタンスを実行しながら同じデータを提供することで実現されます。これらの実行中のサーバーインスタンスは、ハートビートに関連するクラスターとして定義できます。基本的に、各サーバーインスタンスは、そのクラスター内の他のサーバーインスタンスと同じサービスを物理的に提供できます。ただし、データの高可用性を確保する目的で、一度に1つのインスタンスのみがアクティブにサービスを提供できます。したがって、他のインスタンスを「ホットスペア」として定義できます。これは、マスターに障害が発生した場合にサービスを開始できます。 Heartbeatパッケージはこのリンクからダウンロードできます。このパッケージをインストールした後、以下の手順でシステムで動作するようにパッケージを構成できます。ハートビート構成の単純な構造は次のとおりです。
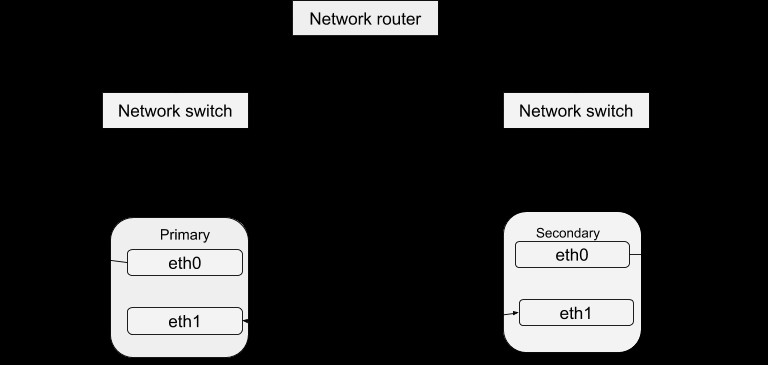
ハートビートの構成
このディレクトリ/etc/ha.dを調べると、構成プロセスで使用されるファイルがいくつか見つかります。 ha.cfファイルは、メインのハートビート構成を形成します。これには、使用するメディアパスのタイプとそれらの構成方法にハートビートを指示する以外に、障害を特定するためのすべてのノードと時間のリストが含まれています。クラスタのセキュリティ情報は、authkeysファイルに記録されます。これらのファイルに記録される情報は、クラスター内のすべてのホストで同一である必要があります。これは、すべてのホスト間で同期することで簡単に実現できます。つまり、1つのホストでの情報の変更は、他のすべてのホストにコピーする必要があります。
Ha.cfファイル
ha.cfファイルの基本的な概要は次のとおりです
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:これは、メッセージの記録に使用する必要があるsyslogロギング機能をハートビートに指示するために使用されます。最も一般的に使用される値は、auth、authpriv、user、local0、syslog、およびdaemonです。ログを作成しないように決定して、値をnoneに設定することもできます。つまり
logfacility none - キープアライブ:これは、ハートビート間の時間、つまり、ハートビート信号が他のホストに送信される頻度です。上記のサンプルコードでは、3秒に設定されています。
- デッドタイム:ノードに障害が発生したと宣言されるまでの秒単位の遅延です。
- 警告時間:ノードに接続できなくなったことを示す警告がログに記録されるまでの秒単位の遅延です。
- Initdead:これは、システムの起動中に他のホストがダウンしていると見なされるまで待機する秒単位の時間です。
- Mcast:ハートビート信号を送信するための定義済みのメソッド手順です。上記のサンプルコードでは、マルチキャストネットワークアドレスが制限付きネットワークデバイス上で使用されています。複数のクラスターの場合、マルチキャストアドレスはクラスターごとに一意である必要があります。マルチキャストを介したシリアル接続を選択することもできます。または、複数のネットワークインターフェイスが存在するように設定する場合は、例のようにハートビート接続に両方を使用します。両方を使用する利点は、無効な障害イベントを引き起こす可能性のある一時的な障害の可能性を克服することです。
- Auto_failback:これにより、フェールバックされたサーバーが使用可能になった場合にクラスターに再接続されます。ただし、サーバーの電源を入れてから別の時間にオンラインになると、混乱が生じる可能性があります。 DRBDに関連して、適切に構成されていない場合、同じサーバーに複数のデータセットが存在する可能性があります。したがって、常にオフに設定することをお勧めします。
- ノード:ハートビートクラスターグループ内のノードの概要を示します。それぞれに少なくとも1つのノードが必要です。
追加の構成
次のような追加の構成情報を設定することもできます:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:これは、サーバーのパブリックインターフェイスでの接続と、別のホストへの接続を確保するために重要です。宛先マシンのホスト名ではなく、IPアドレスを考慮することが重要です。
- リスポーン:これは、障害が発生したときに実行するコマンドです。
- Apiauth:失敗の権限です。コマンドの実行に使用するユーザーIDとグループIDを構成する必要があります。 authkeysファイルは、Heartbeatクラスターの認証情報を保持します。このキーは、特定のHeartbeatクラスター内のマシンを検証するために非常に一意です。
- デッドピング:無応答が失敗を引き起こす前のタイムアウトを定義します。
ハートビートとPostgresおよびDRBDの統合
前述のように、マスターサーバーに障害が発生すると、特定のクラスターを持つ別のサーバーが動作を開始して、同じサービスを提供します。ハートビートは、障害が発生した場合にサーバーの選択を強化するリソースの構成に役立ちます。たとえば、障害が発生したときに起動または破棄する個々のサーバーを定義します。 /etc/ha.dディレクトリのharesourcesファイルにチェックインすると、管理できるリソースの概要が表示されます。リソースファイルのパスは/etc/ha.d/resource.dであり、リソース定義は次の1行にあります。
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(空白に注意してください。)
- Drbd1:サービスを処理するためのデフォルトのマスターとして通常使用されるサーバーをより分離する優先ホストの名前を指します。 DRBDブログで述べたように、サーバー用のリソースが必要であり、これらはdrbddisk、filesystem、postgresとして行で定義されています。最後のフィールドは、サービスを共有するために使用する必要がある仮想IPアドレスです。つまり、Postgresサーバーに接続します。デフォルトでは、ハートビートの開始時にアクティブなサーバーに割り当てられます。障害が発生すると、これらのリソースは、対応するスクリプトが呼び出されたときに配置された順序でバックアップサーバー上で開始されます。この設定では、スクリプトによってセカンダリホストのDRBDディスクがプライマリモードに切り替わり、デバイスが読み取り/書き込み可能になります。
- ファイルシステム:これはファイルシステムリソースを管理します。この場合、DRBDが選択されているため、リソーススクリプトの呼び出し中にマウントされます。
- Postgres:これによりPostgresサーバーが起動または管理されます
電子メールで通知を受け取りたい場合があります。これを行うには、警告テキストを受信するための電子メールとともに、この行をリソースファイルに追加します。
MailTo:: example@sqldat.com::DRBDFailureハートビートを開始するには、コマンドを実行できます
/etc/ha.d/heartbeat startまたは、プライマリサーバーとセカンダリサーバーの両方を再起動します。コマンドを実行すると
$ /usr/lib64/heartbeat/hb_standby現在のノードがトリガーされ、そのリソースが他のノードにクリーンに放棄されます。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするシステムレベルのエラーの処理
サーバーカーネルが破損している可能性があるため、サーバーに潜在的な問題があることを示しています。問題が発生したときにサーバーをクラスターから削除するようにサーバーを構成する必要があります。この問題はカーネルパニックと呼ばれることが多く、その結果、マシンのハードリブートがトリガーされます。カーネル制御ファイル/etc/sysctl.confのkernel.panicおよびkernel.panic_on_oopを設定することにより、強制的に再起動できます。つまり
kernel.panic_on_oops = 1
kernel.panic = 1もう1つのオプションは、sysctlコマンドを使用してコマンドラインから実行することです。例:
$ sysctl -w kernel.panic=1このコマンドを使用して、sysctl.confファイルを編集して構成情報を再ロードすることもできます。
sysctl -pこの値は、再起動するまで待機する秒数を示します。次に、2番目のハートビートノードがサーバーがダウンしていることを検出し、フェイルオーバーホストを切り替えます。
結論
ハートビートは、アクティブなサーバーに障害が発生したときに、セカンダリサーバーをプライマリシステムとバックアップシステムに選択できるようにするサブシステムです。また、他のすべてのサーバーが稼働しているかどうかも判別します。また、新しいプライマリノードへのリソースの転送も保証します