数日前に、ClusterControlの新しいバージョンである1.7.1がリリースされました。ここでは、いくつかの新機能を確認できます。主な機能の1つは、PostgreSQL11のサポートです。
PostgreSQL 11を手動でインストールするには、インフラストラクチャに応じて、最初にリポジトリを追加するか、インストールに必要なパッケージをダウンロードしてインストールし、正しく構成する必要があります。これらの手順はすべて時間がかかるので、これを回避する方法を見てみましょう。
このブログでは、ClusterControlを使用して数回クリックするだけでこの新しいPostgreSQLバージョンをデプロイする方法と、それを管理する方法を説明します。前提条件として、1.7.1バージョンのClusterControlを専用のホストまたはVMにインストールしてください。
PostgreSQL11をデプロイする
ClusterControlから新規インストールを実行するには、[展開]オプションを選択し、表示される指示に従います。 PostgreSQL 11インスタンスをすでに実行している場合は、代わりに[既存のサーバー/データベースのインポート]を選択する必要があることに注意してください。
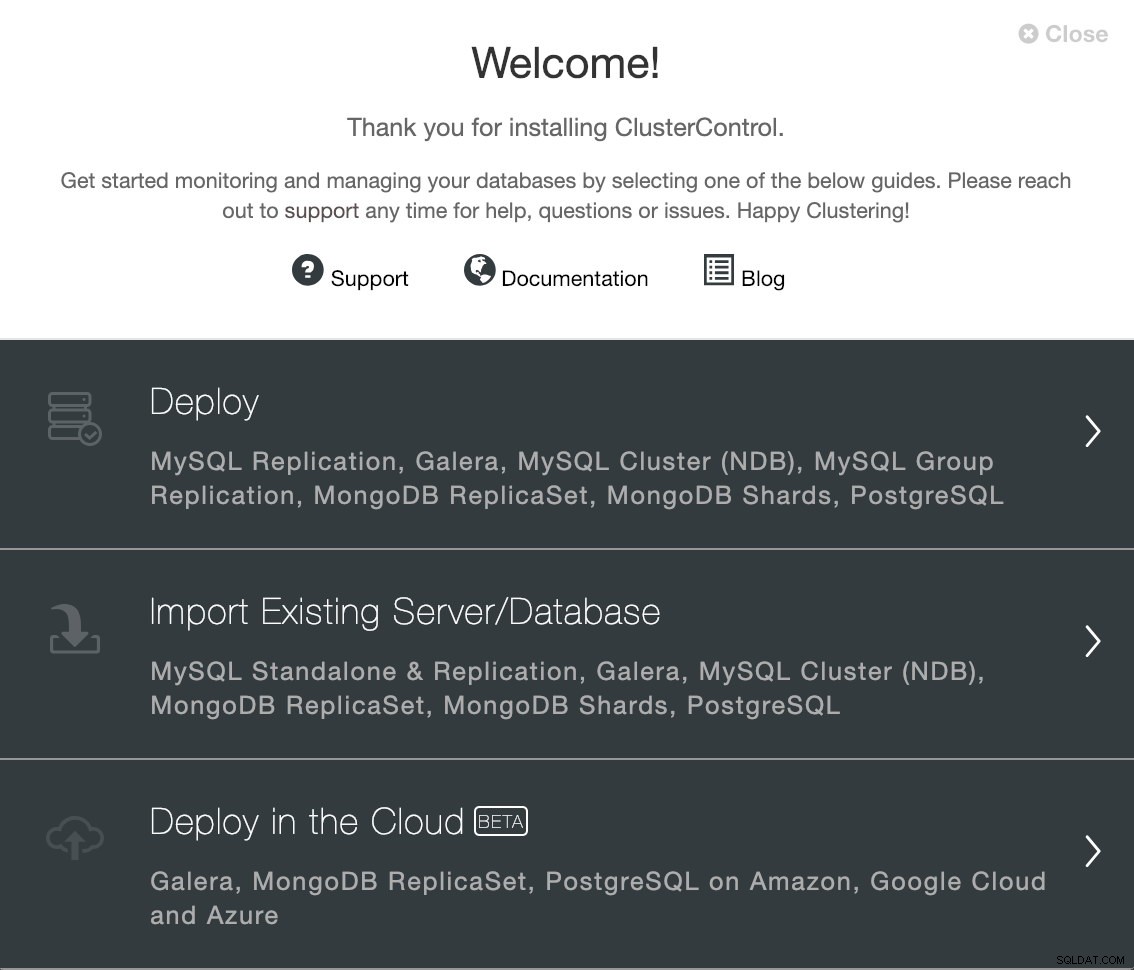 ClusterControlデプロイオプション
ClusterControlデプロイオプション PostgreSQLを選択するときは、SSHでPostgreSQLホストに接続するためのユーザー、キー、またはパスワードとポートを指定する必要があります。新しいクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合にも必要です。
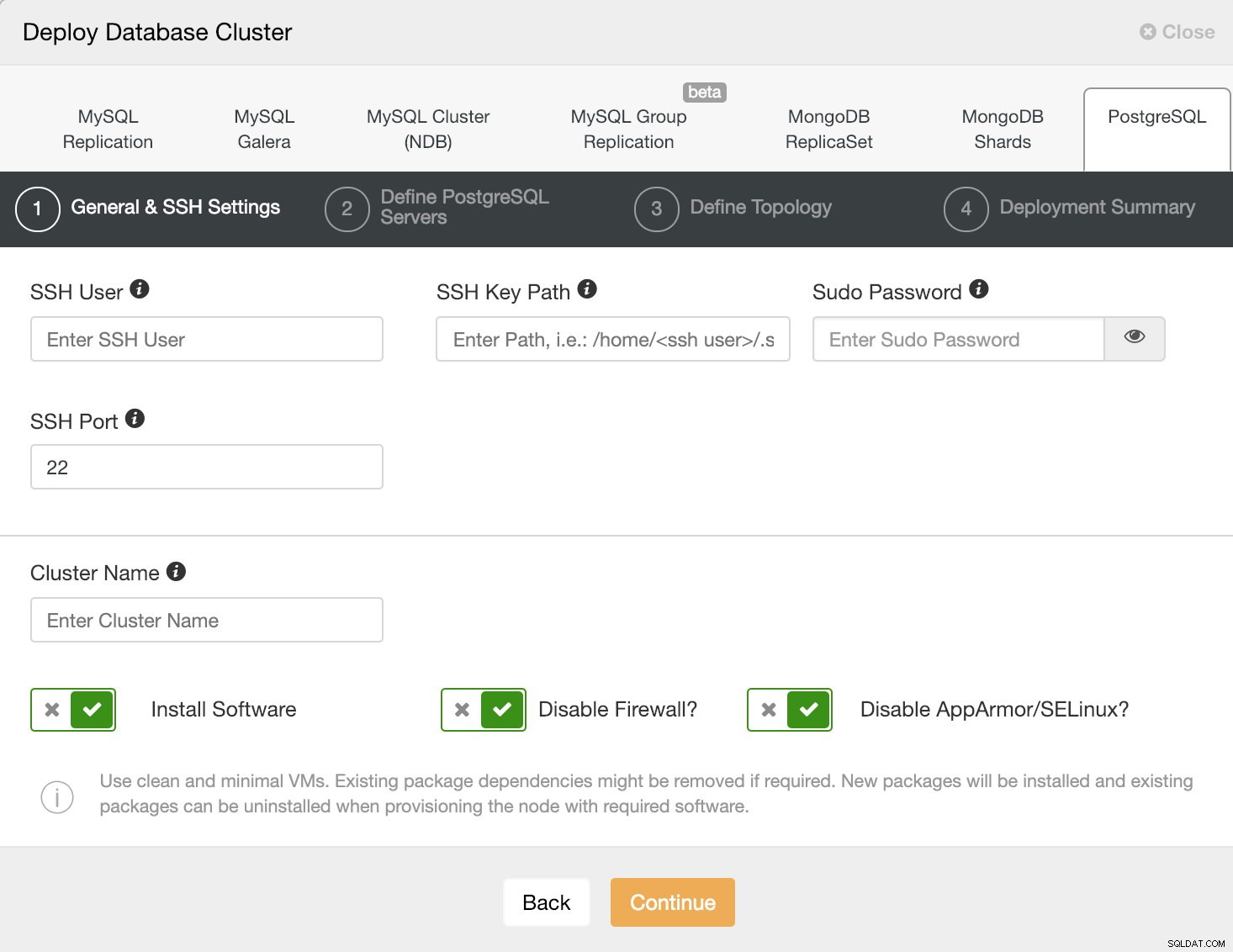 ClusterControlデプロイ情報1
ClusterControlデプロイ情報1 このタスクのClusterControlユーザー要件をここで確認してください。
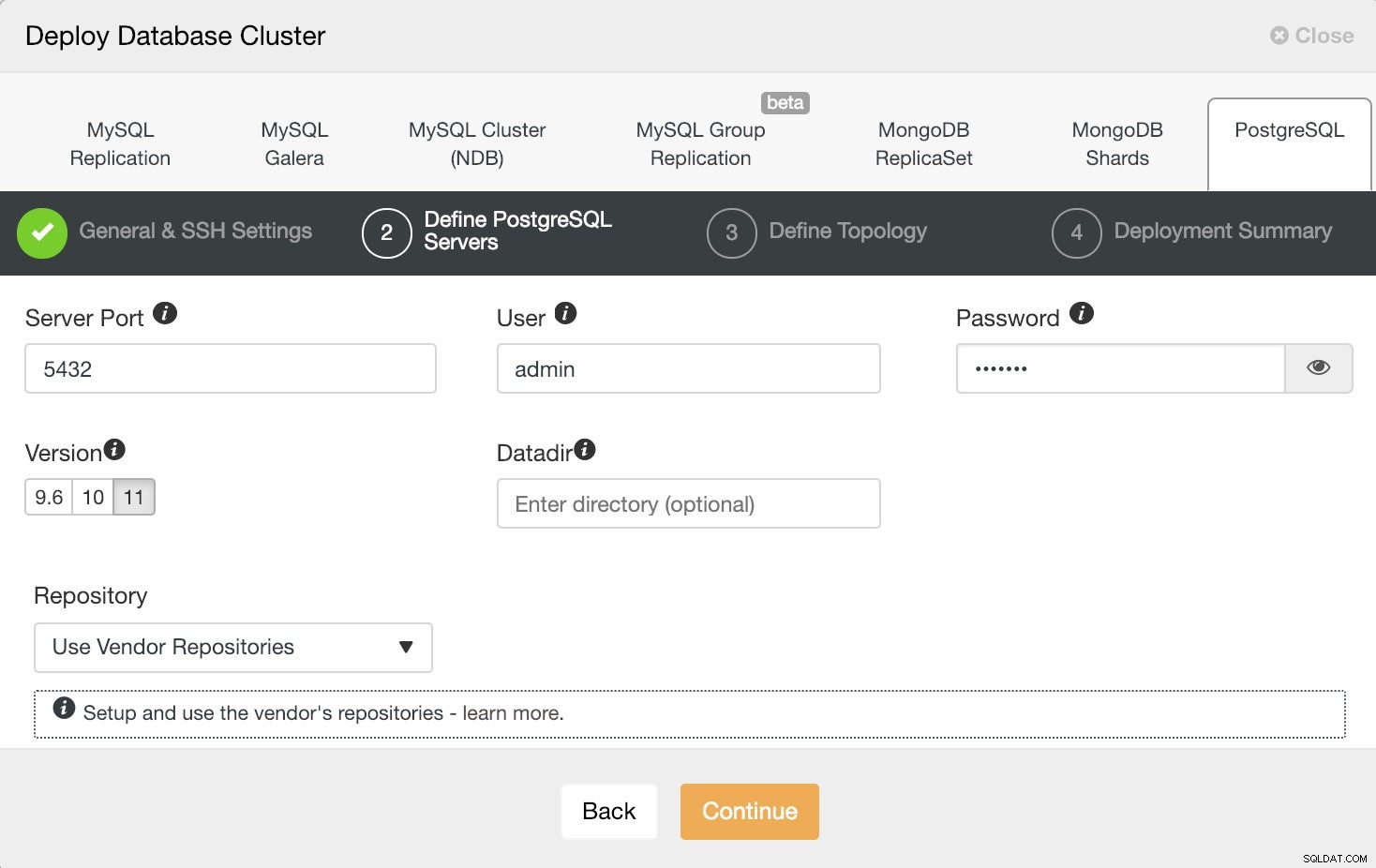 ClusterControlデプロイ情報2
ClusterControlデプロイ情報2 SSHアクセス情報を設定した後、データベースユーザー、バージョン、およびdatadir(オプション)を定義する必要があります。使用するリポジトリを指定することもできます。この場合、PostgreSQL 11をデプロイしたいので、それを選択して続行します。
次のステップでは、作成するクラスターにサーバーを追加する必要があります。
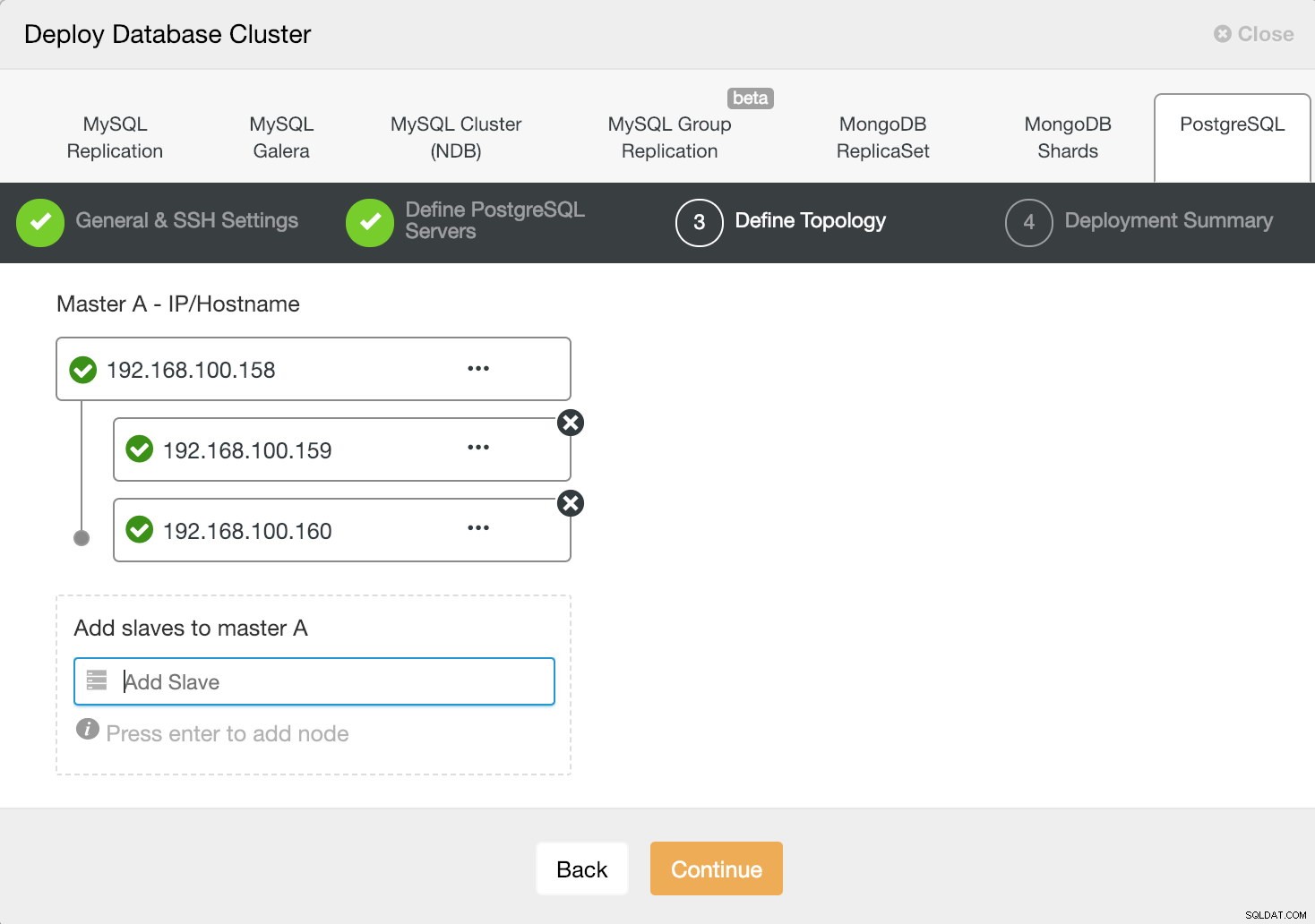 ClusterControlデプロイ情報3
ClusterControlデプロイ情報3 サーバーを追加するときに、IPまたはホスト名を入力できます。
最後のステップで、レプリケーションを同期にするか非同期にするかを選択できます。
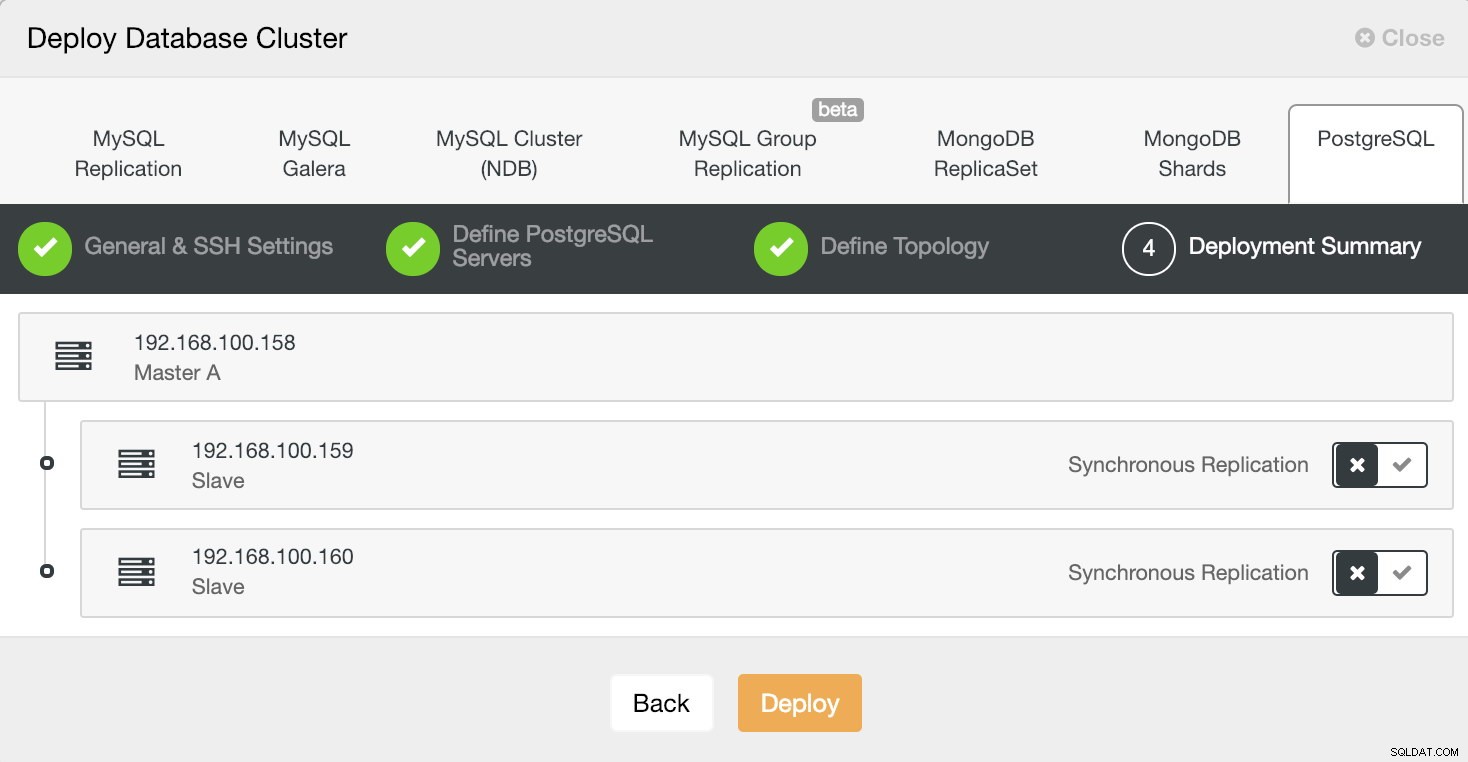 ClusterControlデプロイ情報4
ClusterControlデプロイ情報4 ClusterControlアクティビティモニターから新しいクラスターの作成ステータスを監視できます。
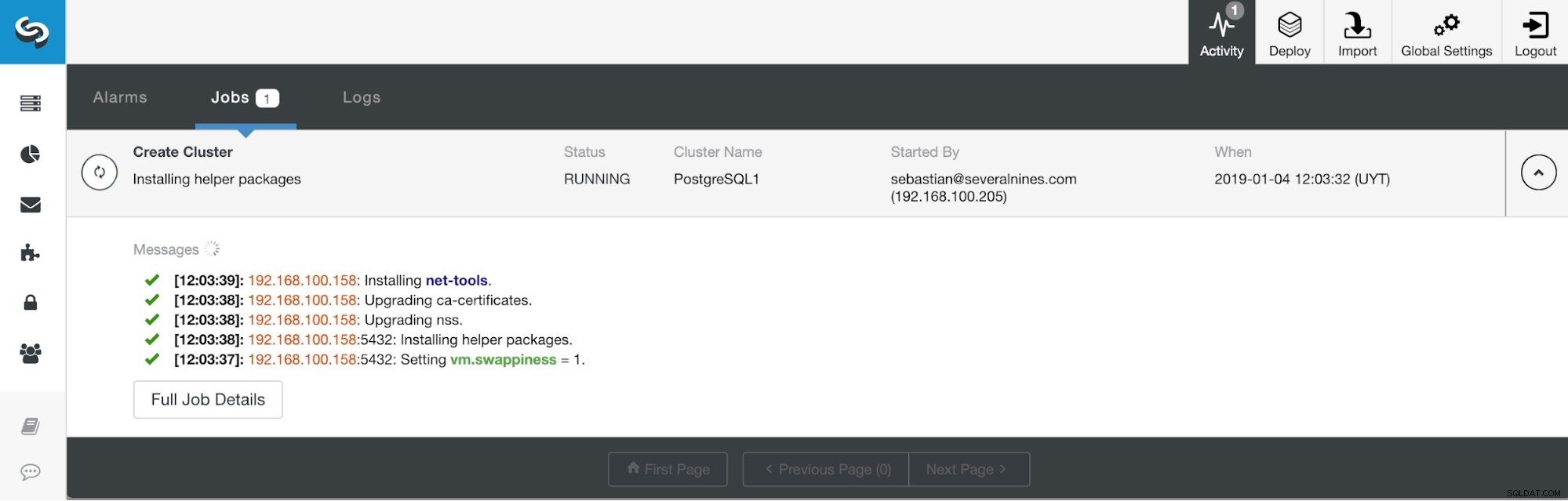 ClusterControlアクティビティセクション
ClusterControlアクティビティセクション タスクが完了すると、ClusterControlのメイン画面に新しいPostgreSQL11クラスターが表示されます。
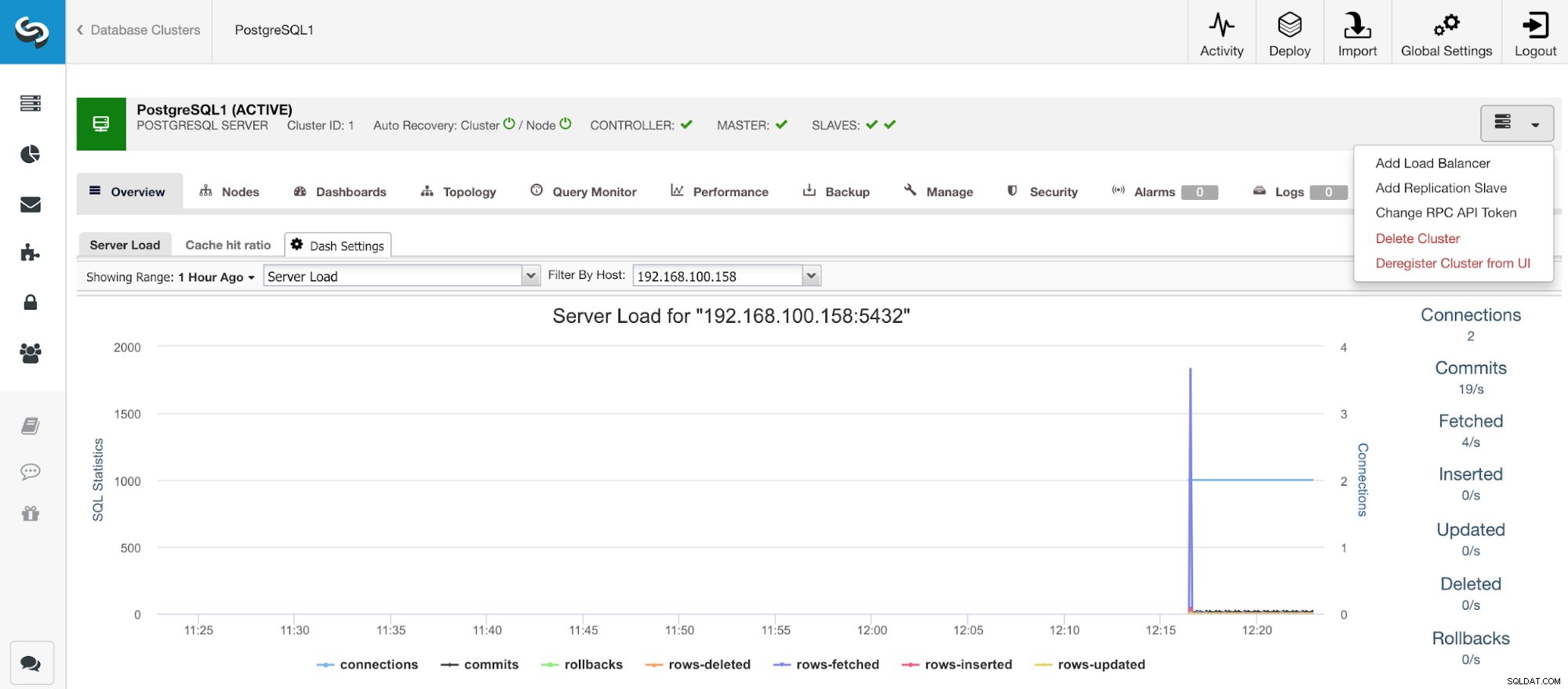
 ClusterControlのメイン画面
ClusterControlのメイン画面 クラスタを作成したら、ロードバランサ(HAProxy)や新しいレプリカの追加など、いくつかのタスクを実行できます。
 ClusterControlクラスターセクション
ClusterControlクラスターセクション PostgreSQL11のスケーリング
クラスタアクションに移動して[レプリケーションスレーブの追加]を選択すると、新しいレプリカを最初から作成するか、既存のPostgreSQLデータベースをレプリカとして追加できます。
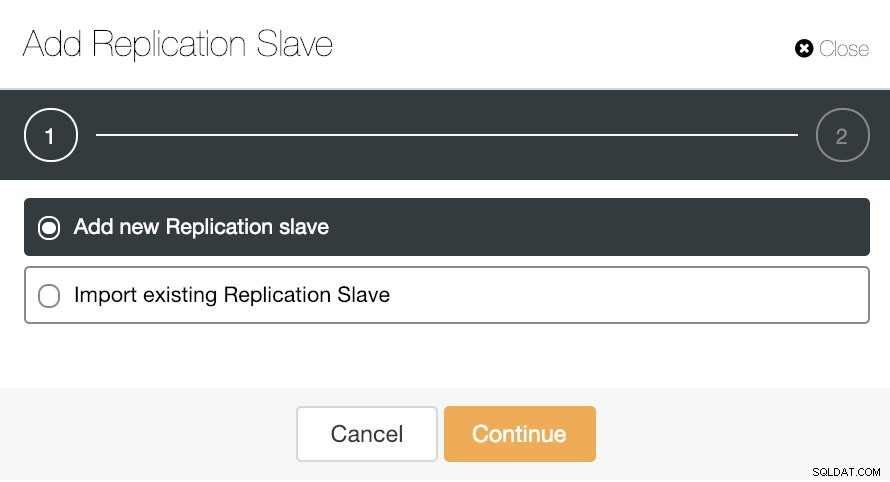 ClusterControlレプリケーションスレーブオプションの追加
ClusterControlレプリケーションスレーブオプションの追加 新しいレプリケーションスレーブを追加することが本当に簡単な作業になる方法を見てみましょう。
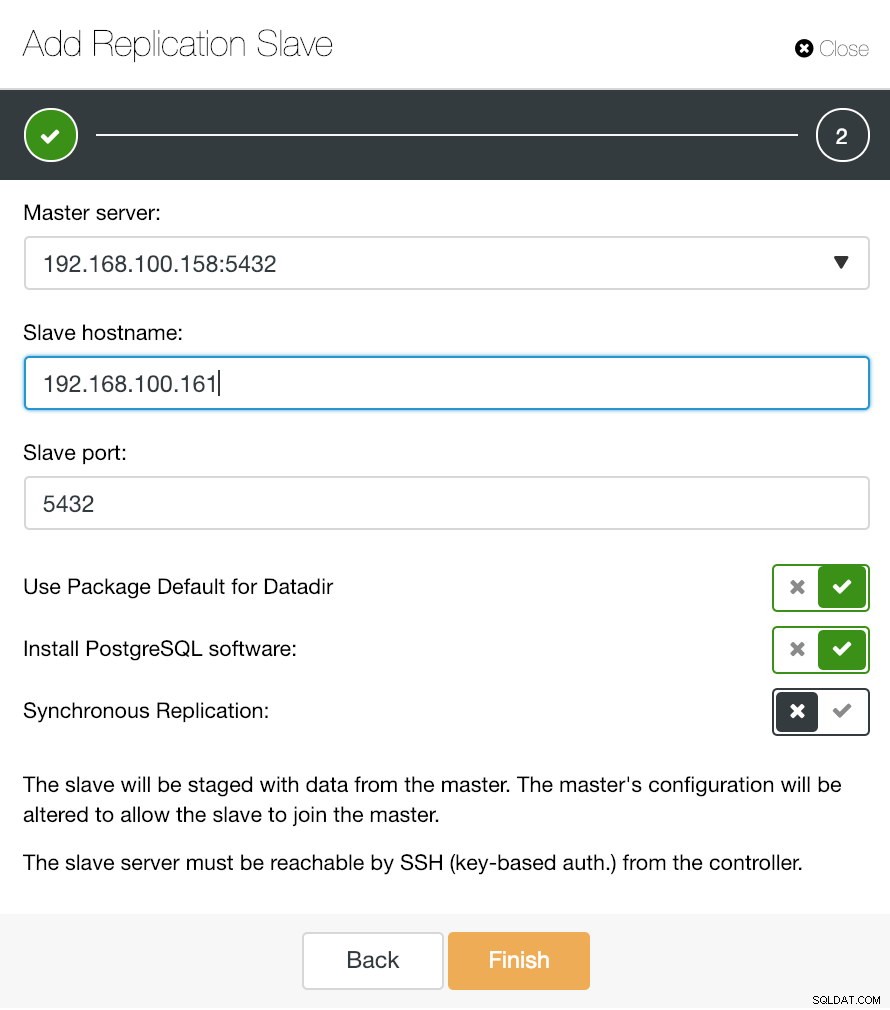 ClusterControlレプリケーションスレーブ情報の追加
ClusterControlレプリケーションスレーブ情報の追加 画像でわかるように、マスターサーバーを選択し、新しいスレーブサーバーのIPアドレスとデータベースポートを入力するだけです。次に、ClusterControlにソフトウェアをインストールさせるかどうか、およびレプリケーションスレーブを同期にするか非同期にするかを選択できます。
このようにして、必要な数のレプリカを追加し、ロードバランサーを使用してそれらの間で読み取りトラフィックを分散できます。これはClusterControlでも実装できます。
HA for PostgreSQLの詳細については、関連するブログをご覧ください。
ClusterControlから、ワンクリックで、ホストの再起動、レプリケーションスレーブの再構築、スレーブのプロモートなどのさまざまな管理タスクを実行することもできます。
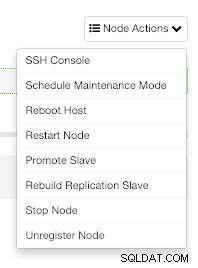 ClusterControlノードのアクション
ClusterControlノードのアクション バックアップ
以前のブログでは、PostgreSQLのバックアップ機能とPITRClusterControl機能について説明しました。現在、前回のClusterControlバージョンには、「スタンドアロンホストでのバックアップの確認/復元」機能と「既存のバックアップからクラスターを作成する」機能があります。
ClusterControlで、クラスターを選択し、[バックアップ]セクションに移動して、現在のバックアップを確認します。
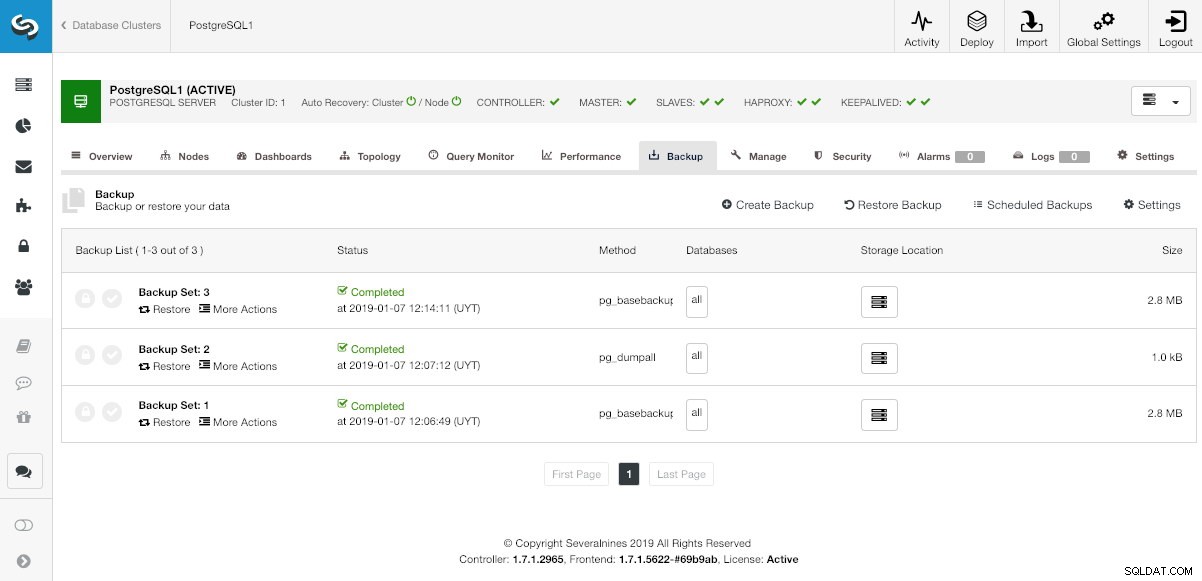 ClusterControlバックアップセクション
ClusterControlバックアップセクション [復元]オプションでは、最初に、復元するバックアップを選択できます。
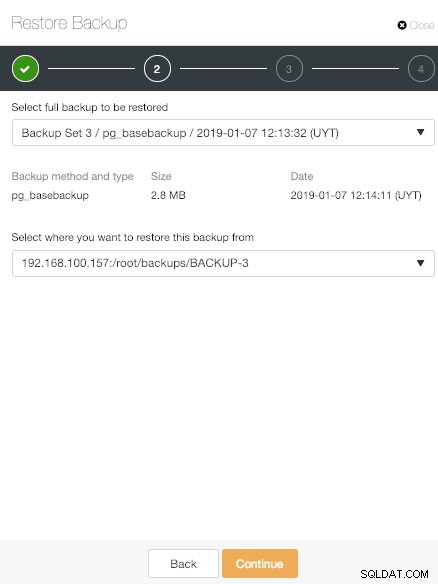 ClusterControl Restore Backup Option
ClusterControl Restore Backup Option そこでは、3つのオプションがあります。
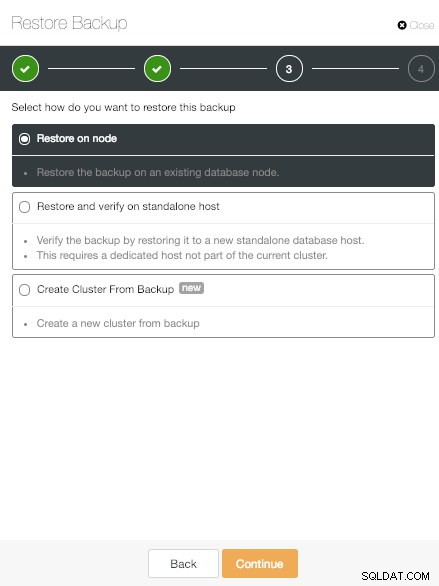 ノードオプションでのClusterControlの復元
ノードオプションでのClusterControlの復元 1つ目は、従来の「ノードで復元」オプションです。これにより、選択したバックアップが特定のノードに復元されます。
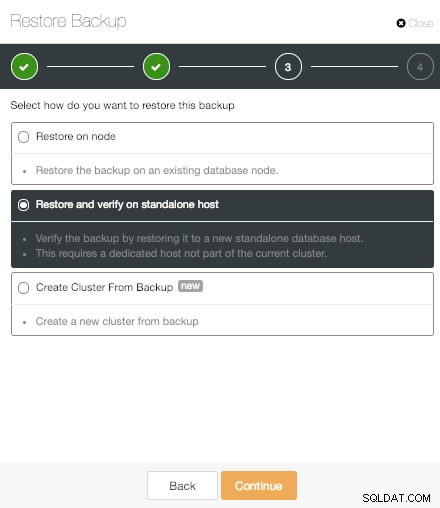 ClusterControlスタンドアロンホストでの復元と検証オプション
ClusterControlスタンドアロンホストでの復元と検証オプション 「スタンドアロンホストでの復元と検証」オプションは、ClusterControlPostgreSQLの新しい機能です。これにより、スタンドアロンホストに復元することで、生成されたバックアップをテストできます。これは、災害復旧シナリオでの予期しない事態を回避するのに非常に役立ちます。
この機能を使用するには、クラスターの一部ではない専用のホスト(またはVM)が必要です。
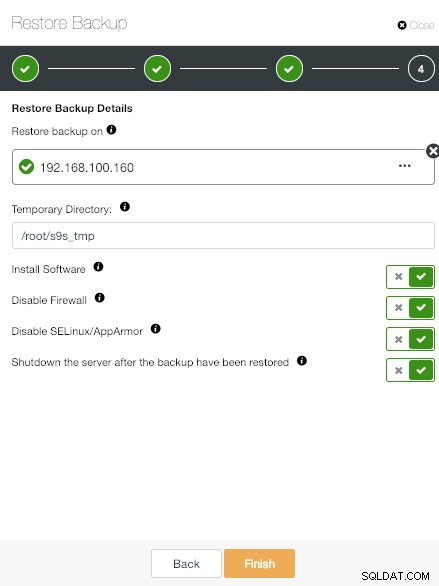 ClusterControlスタンドアロンホストでの復元と検証情報
ClusterControlスタンドアロンホストでの復元と検証情報 専用のホストIPアドレスを追加し、必要なオプションを選択します。
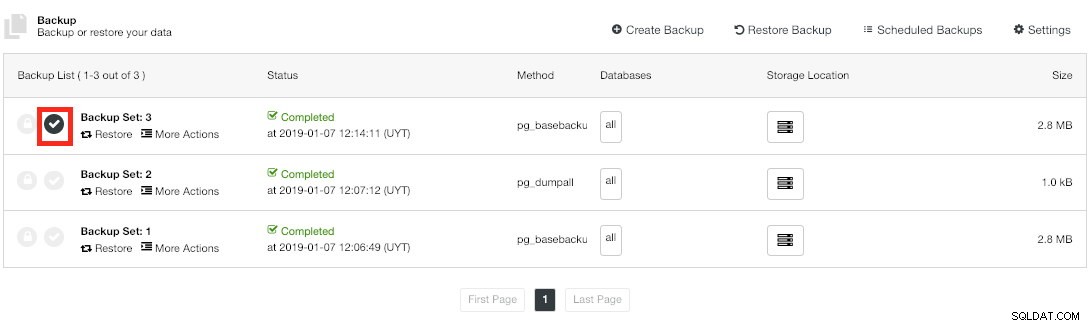 ClusterControl検証済みバックアップ
ClusterControl検証済みバックアップ バックアップが検証されると、バックアップリストに「検証済み」アイコンが表示されます。
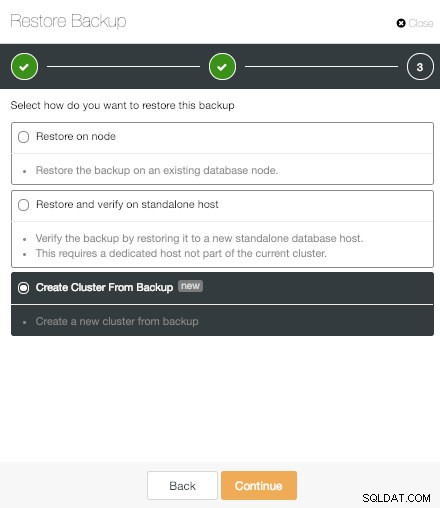 ClusterControlバックアップオプションからクラスターを作成
ClusterControlバックアップオプションからクラスターを作成 「バックアップからクラスターを作成する」は、ClusterControlPostgreSQLのもう1つの重要な機能です。
名前が示すように、この機能を使用すると、生成されたバックアップのデータを使用して新しいPostgreSQLクラスターを作成できます。
このオプションを選択した後、デプロイセクションで見たのと同じ手順に従う必要があります。
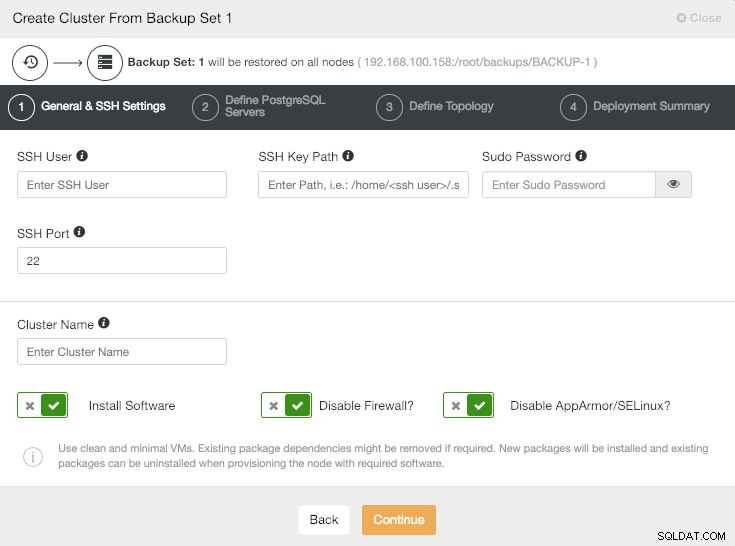 ClusterControlバックアップ情報からクラスターを作成
ClusterControlバックアップ情報からクラスターを作成
この新しいクラスターでは、ユーザー、ノード数、レプリケーションタイプなどのすべての構成が異なる可能性があります。
新しいクラスターが作成されると、ClusterControlのメイン画面に古いクラスターと新しいクラスターの両方が表示されます。
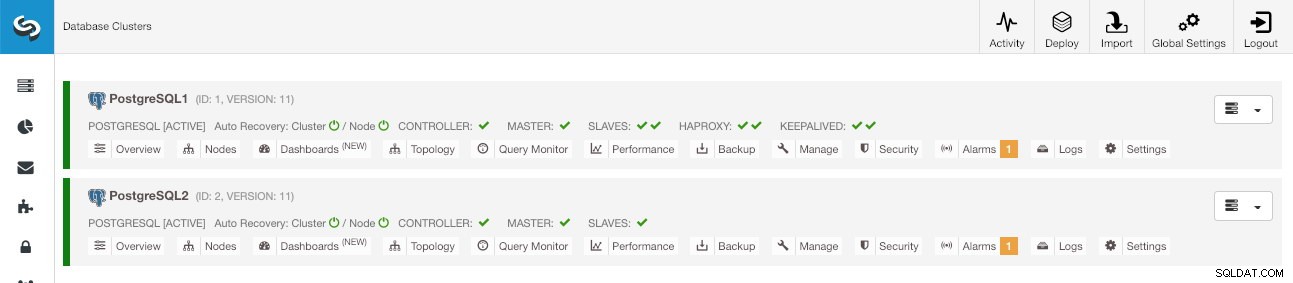 ClusterControlのメイン画面
ClusterControlのメイン画面 結論
上で見たように、ClusterControlを使用して最新のPostgreSQLリリースバージョン11をデプロイできるようになりました。 ClusterControlを導入すると、監視、アラート、自動フェイルオーバー、バックアップ、ポイントインタイムリカバリ、バックアップ検証から、リードレプリカのスケーリングまで、あらゆる機能が提供されます。これは、フレンドリーで直感的な方法でPostgresを管理するのに役立ちます。試してみてください!