このブログはJenkinsについての簡単なプレゼンテーションであり、このツールを使用してPostgreSQLの日常の管理および管理タスクの一部を支援する方法を示しています。
ジェンキンスについて
Jenkinsは、自動化のためのオープンソースソフトウェアです。これはJavaで開発されており、継続的インテグレーション(CI)および継続的デリバリー(CD)で最も人気のあるツールの1つです。
2010年、オラクルがSun Microsystemsを買収した後、「Hudson」ソフトウェアはオープンソースコミュニティと争っていました。この論争は、ジェンキンスプロジェクトの立ち上げの基礎となりました。
現在、「Hudson」(Eclipseパブリックライセンス)と「Jenkins」(MITライセンス)は、非常によく似た目的を持つ2つのアクティブで独立したプロジェクトです。
Jenkinsには、開発ライフサイクル全体の自動化を通じて開発フェーズをスピードアップするために使用できる数千のプラグインがあります。ビルド、ドキュメント化、テスト、パッケージ化、ステージング、展開。
Jenkinsは何をしますか?
Jenkinsの主な用途は継続的インテグレーション(CI)と継続的デリバリー(CD)ですが、このオープンソースには一連の機能があり、CIまたはCDからのコミットメントや依存なしに使用できるため、Jenkinsはいくつかの興味深い機能を提供します。探索する:
- 期間ジョブのスケジュール(従来の crontab を使用する代わりに) )
- クリーンビューによるジョブ、そのログ、およびアクティビティの監視(グループ化のオプションがあるため)
- 仕事の維持は簡単に行うことができます。 Jenkinsに一連のオプションがあると仮定します
- 同じホストまたは別のホストでのソフトウェアインストールのセットアップとスケジュール設定(Puppetを使用)。
- レポートの公開とメール通知の送信
JenkinsでのPostgreSQLタスクの実行
PostgreSQL開発者またはデータベース管理者が日常的に実行しなければならない一般的なタスクは3つあります。
- PostgreSQLスクリプトのスケジュールと実行
- 3つ以上のスクリプトで構成されるPostgreSQLプロセスを実行する
- PL / pgSQL開発のための継続的インテグレーション(CI)
これらの例を実行するために、JenkinsおよびPostgreSQL(少なくともバージョン9.5)サーバーがインストールされ、正しく機能していることを前提としています。
PostgreSQLスクリプトのスケジューリングと実行
ほとんどの場合、...
などの通常のタスクを実行するための毎日(または定期的に)PostgreSQLスクリプトを実装します。- バックアップの生成
- バックアップの復元をテストする
- レポート目的でのクエリの実行
- ログファイルのクリーンアップとアーカイブ
- PL/pgSQLプロシージャを呼び出してテーブルをパージする
crontabで定義されています :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shcrontabとして この種のスケジューリングを管理するのに最適なユーザーフレンドリーなツールではありません。Jenkinsで実行でき、次の利点があります...
- 進捗状況と現在のステータスを監視するための非常に使いやすいインターフェース
- ログはすぐに利用可能であり、ログにアクセスするために特別な許可は必要ありません
- スケジュールを設定する代わりに、Jenkinsでジョブを手動で実行できます
- ある種のジョブでは、Jenkinsが安全な方法で行うため、プレーンテキストファイルでユーザーとパスワードを定義する必要はありません。
- ジョブはAPI実行として定義できます
したがって、PostgreSQLタスクに関連するジョブをcrontabではなくJenkinsに移行することは良い解決策になる可能性があります。
一方、ほとんどのデータベース管理者と開発者はスクリプト言語に強いスキルを持っており、タスクを改善する目的で自動化されたプロセスを実装するために、これらのスクリプトを処理する小さなインターフェイスを開発するのは簡単です。ただし、Jenkinsにはそれを実行するための一連の関数がすでにある可能性が高く、これらの関数を使用することを選択した開発者はこれらの関数を使用することで作業が楽になります。
したがって、スクリプトの実行を定義するには、[新しいアイテム]オプションを選択して、新しいジョブを作成する必要があります。
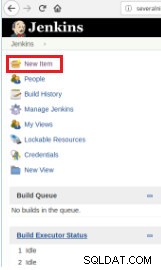 図1-PostgreSQLスクリプトを実行するジョブを定義するための「新しいアイテム」
図1-PostgreSQLスクリプトを実行するジョブを定義するための「新しいアイテム」 次に、名前を付けた後、「FreeStyleprojects」タイプを選択して[OK]をクリックします。
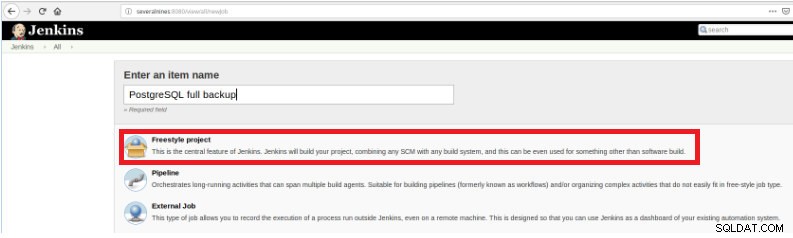 図2–ジョブ(アイテム)タイプの選択
図2–ジョブ(アイテム)タイプの選択 この新しいジョブの作成を完了するには、[ビルド]セクションで[スクリプトの実行]オプションを選択し、コマンドラインボックスで実行するスクリプトのパスとパラメーター化を選択する必要があります。
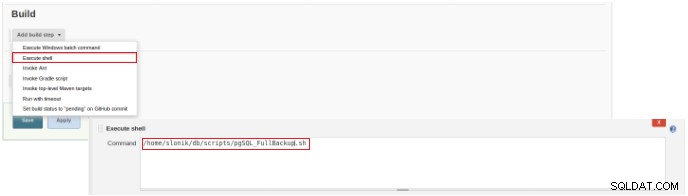 図3–実行するコマンドの仕様
図3–実行するコマンドの仕様 この種のジョブでは、少なくともファイルが属するグループと全員の実行を設定する必要があるため、スクリプトのアクセス許可を確認することをお勧めします。
この例では、スクリプト query.sh 全員の読み取りおよび実行権限、グループの読み取りおよび実行権限、およびユーザーの読み取り/書き込みおよび実行権限があります。
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ このスクリプトには非常に単純なステートメントのセットがあり、基本的にはクエリを実行するためにユーティリティpsqlを呼び出すだけです。
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.dat3つ以上のスクリプトで構成されるPostgreSQLプロセスの実行
この例では、機密データを非表示にするために3つの異なるスクリプトを実行するために必要なものについて説明します。そのために、以下の手順に従います...
- ファイルからデータをインポートする
- マスクするデータを準備する
- データがマスクされたデータベースのバックアップ
したがって、この新しいジョブを定義するには、Jenkinsのメインページで[新しいアイテム]オプションを選択し、名前を割り当てた後、[パイプライン]オプションを選択する必要があります。
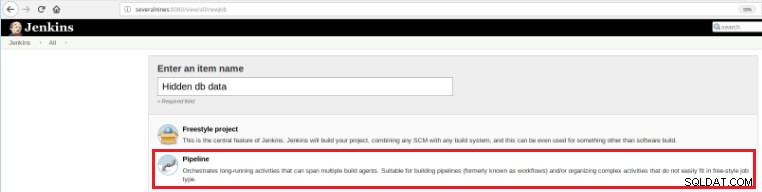 図5-ジェンキンスのパイプラインアイテム
図5-ジェンキンスのパイプラインアイテム [パイプライン]セクションの[プロジェクトの詳細オプション]タブでジョブを保存したら、次に示すように、[定義]フィールドを[パイプラインスクリプト]に設定する必要があります。
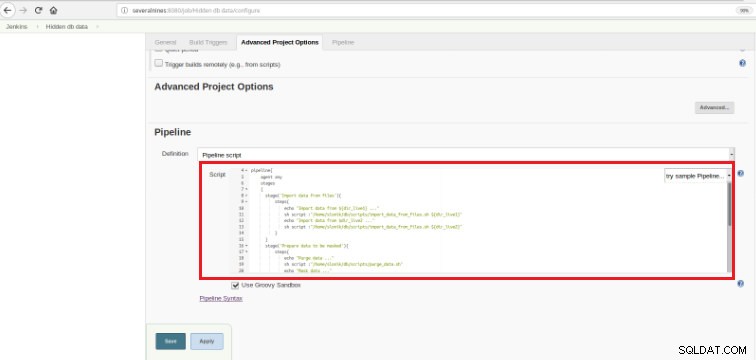 図6-パイプラインセクションのGroovyスクリプト
図6-パイプラインセクションのGroovyスクリプト この章の冒頭で述べたように、使用されているGroovyスクリプトは、3つのステージで構成されています。つまり、次のスクリプトに示すように、3つの異なる部分(ステージ)を意味します。
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovyは、Javaプラットフォーム用のJava構文互換のオブジェクト指向プログラミング言語です。 Python、Ruby、Perl、Smalltalkと同様の機能を備えた静的言語と動的言語の両方です。
この種のスクリプトはいくつかのステートメントに基づいているため、理解しやすいです…
ステージ
実行される3つのプロセスを意味します:「ファイルからデータをインポートする」、「マスクするデータを準備する」
および「データをマスクしたデータベースのバックアップ」。
ステップ
「ステップ」(「ビルドステップ」と呼ばれることもあります)は、シーケンスの一部である単一のタスクです。各ステージは、いくつかのステップで構成できます。この例では、最初のステージには2つのステップがあります。
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'データは2つの異なるソースからインポートされています。
前の例では、最初にグローバルスコープで定義された2つの変数があることに注意することが重要です。
dir_live1
dir_live2これらの3つのステップで使用されるスクリプトは、 psqlを呼び出しています。 、 pg_restore およびpg_dump ユーティリティ。
ジョブを定義したら、それを実行します。そのためには、[今すぐビルド]オプションをクリックするだけです。
 図7–実行ジョブ
図7–実行ジョブ ビルドの開始後、進行状況を確認できます。
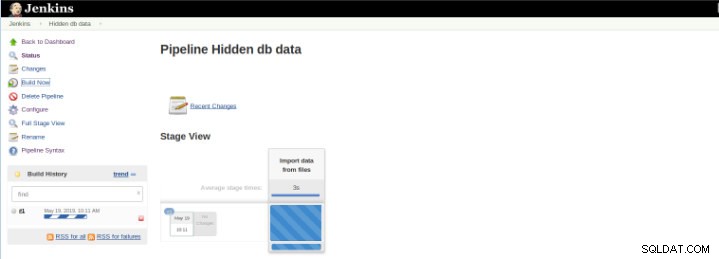 図8–「ビルド」の開始
図8–「ビルド」の開始 Pipeline Stage Viewプラグインには、StageViewの下のフロープロジェクトのインデックスページにパイプラインビルド履歴の拡張視覚化が含まれています。このビューは、タスクが完了するとすぐにビルドされ、各タスクは左から右に列で表され、サーバル実行の経過時間を表示および比較できます(Jenkinsでのビルドと呼ばれます)。
>実行(ビルドとも呼ばれます)が終了すると、終了したスレッド(赤いボックス)をクリックして、追加の詳細を取得できます。
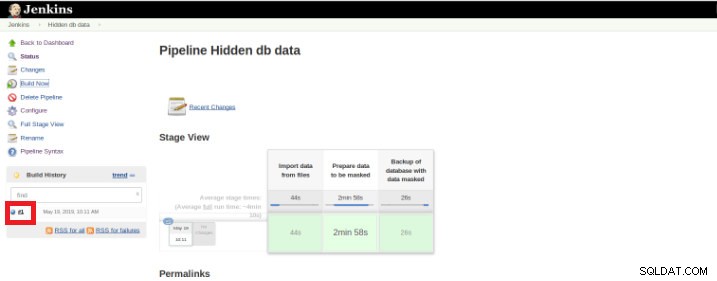 図9–「ビルド」の開始
図9–「ビルド」の開始 次に、「コンソール出力」オプションで。
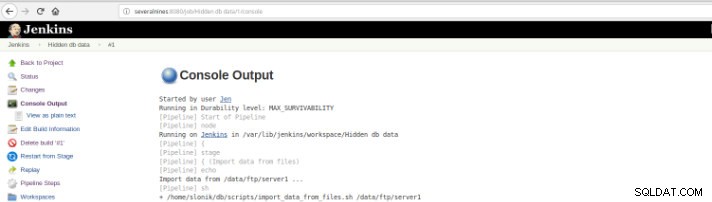 図10–コンソール出力
図10–コンソール出力 前のビューは、各ステージに必要なランタイムを認識できるため、非常に便利です。
ワークフローとも呼ばれるパイプラインは、アプリケーションのライフサイクルの定義を可能にするプラグインであり、Jenkins for Continuous Delivery(CD)で使用される機能です。vこのプラグインは、柔軟で拡張可能なスクリプトベースのCDワークフロー機能の要件に基づいて構築されました。念頭に置いてください。
この例は機密データを非表示にするためのものですが、パイプラインジョブで実行できるPostgreSQLデータベース管理者の日常的な例は他にもたくさんあります。
パイプラインはバージョン2.0以降Jenkinsで利用可能であり、すばらしいソリューションです!

PL / pgSQL開発のための継続的インテグレーション(CI)
データベース開発の継続的な統合は、データが失われる可能性があるため、他のプログラミング言語ほど簡単ではありません。そのため、特にスクリプトが存在する場合は、データベースをソース制御に維持し、専用サーバーにデプロイするのは簡単ではありません。 DDL(データ定義言語)およびDML(データ操作言語)ステートメントが含まれています。これは、これらの種類のステートメントがデータベースの現在の状態を変更し、他のプログラミング言語とは異なり、コンパイルするソースコードがないためです。
一方、他のプログラミング言語と同様に継続的インテグレーションが可能なデータベースステートメントのセットがあります。
この例は、プロシージャの開発のみに基づいており、次の関数のコードが格納されているPostgreSQLスクリプトがコードリポジトリにコミットされた後のJenkinsによる一連のテスト(Pythonで記述)のトリガーを示しています。
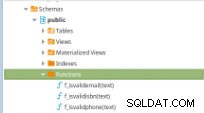 図11– PLpg/SQL関数
図11– PLpg/SQL関数 これらの関数は単純であり、そのコンテンツには PLpg / SQLのロジックまたはクエリがいくつかあります。 またはplperlu 関数としての言語f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;ここに示されているすべての機能は相互に依存しているわけではなく、その開発または展開のいずれにおいても優先順位はありません。また、事前に検証されるため、検証に依存することはありません。
したがって、コードリポジトリでコミットが実行されると、一連の検証スクリプトを実行するには、Jenkinsでビルドジョブ(新しいアイテム)を作成する必要があります。
 図12–継続的インテグレーションのための「フリースタイル」プロジェクト
図12–継続的インテグレーションのための「フリースタイル」プロジェクト この新しいビルドジョブは「フリースタイル」プロジェクトとして作成する必要があり、「ソースコードリポジトリ」セクションでリポジトリのURLとそのクレデンシャル(オレンジ色のボックス)を定義する必要があります:
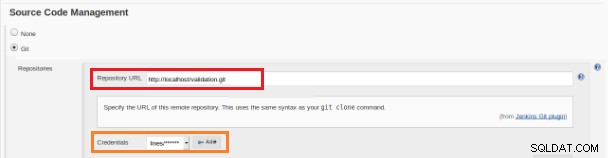 図13–ソースコードリポジトリ
図13–ソースコードリポジトリ 「ビルドトリガー」セクションで、「GITScmポーリング用のGitHubフックトリガー」オプションをチェックする必要があります:
 図14–「トリガーのビルド」セクション
図14–「トリガーのビルド」セクション 最後に、「ビルド」セクションで「シェルの実行」オプションを選択し、コマンドボックスで開発された機能の検証を行うスクリプトを選択する必要があります。
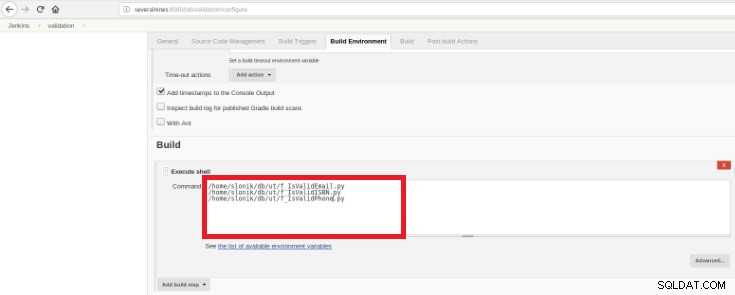 図15–「ビルド環境」セクション
図15–「ビルド環境」セクション 目的は、開発された関数ごとに1つの検証スクリプトを用意することです。
このPythonスクリプトには、データベースからこれらのプロシージャを呼び出し、いくつかの事前定義された期待される結果をもたらす単純なステートメントのセットがあります。
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()このスクリプトは、提示された PLpg / SQLをテストします またはplperlu 関数であり、開発のリグレッションを回避するために、コードリポジトリで各コミット後に実行されます。
このジョブビルドが実行されると、ログの実行を確認できます。
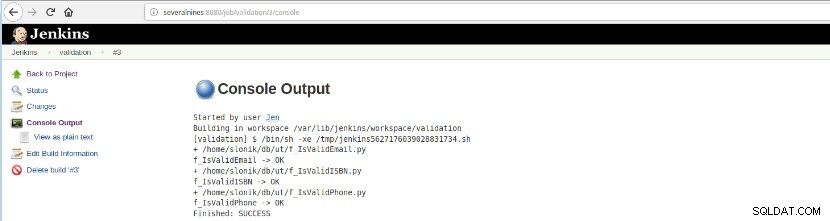 図16–「コンソール出力」
図16–「コンソール出力」 このオプションは、最終ステータスを示します:SUCCESSまたはFAILURE、ワークスペース、実行されたファイル/スクリプト、作成された一時ファイル、およびエラーメッセージ(失敗したものの場合)!
結論
要約すると、Jenkinsは継続的インテグレーション(CI)と継続的デリバリー(CD)の優れたツールとして知られていますが、次のようなさまざまな機能に使用できます。
- タスクのスケジュール
- スクリプトの実行
- プロセスの監視
実行ごとにこれらすべての目的(Jenkins語彙に基づいて構築)について、ログと経過時間を分析できます。
利用可能なプラグインが多数あるため、特定の目的での開発を回避できます。おそらく、探しているものを正確に実行するプラグインがあります。アップデートセンターを検索するか、Jenkinsを管理する>>プラグインを管理するだけです。 Webアプリケーション。