これが私たちです。 21世紀に入ってからほぼ20年が経ち、より多くの計算能力の必要性は依然として問題です。テクノロジー企業は、この大規模な問題に正面から取り組むために舗装を叩いています。ハードウェアエンジニアは、コンピューターの中央処理装置(CPU)の設計と製造の方法を変更することで、解決策を見つけました。現在、複数のコアが含まれているため、同時実行が可能です。次に、ソフトウェア開発者は、このハードウェアの変更に適応するようにプログラムを作成する方法を調整しました。
PostgreSQLコミュニティは、これらのマルチコアCPUを最大限に活用して、クエリのパフォーマンスを向上させています。バージョン9.6以降に更新するだけで、クエリ並列処理と呼ばれる機能を利用してさまざまな操作を実行できます。タスクを小さな部分に分割し、各タスクを複数のCPUコアに分散します。各コアは同時にタスクを処理できます。ハードウェアの制限により、これは、将来的にコンピュータのパフォーマンスを向上させる唯一の方法です。
PostgreSQLデータベースで並列処理機能を使用する前に、クエリを並列化する方法を認識することが重要です。発生した問題をデバッグして解決できるようになります。
クエリの並列処理はどのように機能しますか?
並列処理がどのように実行されるかをよりよく理解するには、クライアントレベルから始めることをお勧めします。 PostgreSQLにアクセスするには、クライアントはpostmasterと呼ばれるデータベースサーバーに接続要求を送信する必要があります。ポストマスターは認証を完了してから、接続ごとに新しいサーバープロセスを作成するためにフォークします。また、バッファプールを含む共有メモリの領域を作成する役割も果たします。バッファプールは、共有メモリとストレージ間のデータ転送を監視します。したがって、接続が確立されるとすぐに、バッファプールがデータを転送し、クエリの並列処理を実行できるようになります。
すべてのクエリが並列である必要はありません。必要なデータが少なく、1つのコアで迅速に処理できる場合があります。この機能は、クエリの完了にかなりの時間がかかる場合にのみ使用されます。データベースオプティマイザは、並列処理を実行するかどうかを決定します。必要に応じて、データベースは動的共有メモリ(DSM)と呼ばれるメモリの追加部分を使用します。これにより、リーダープロセスと並列対応ワーカープロセスがクエリを複数のコアに分割し、関連データを収集できるようになります。
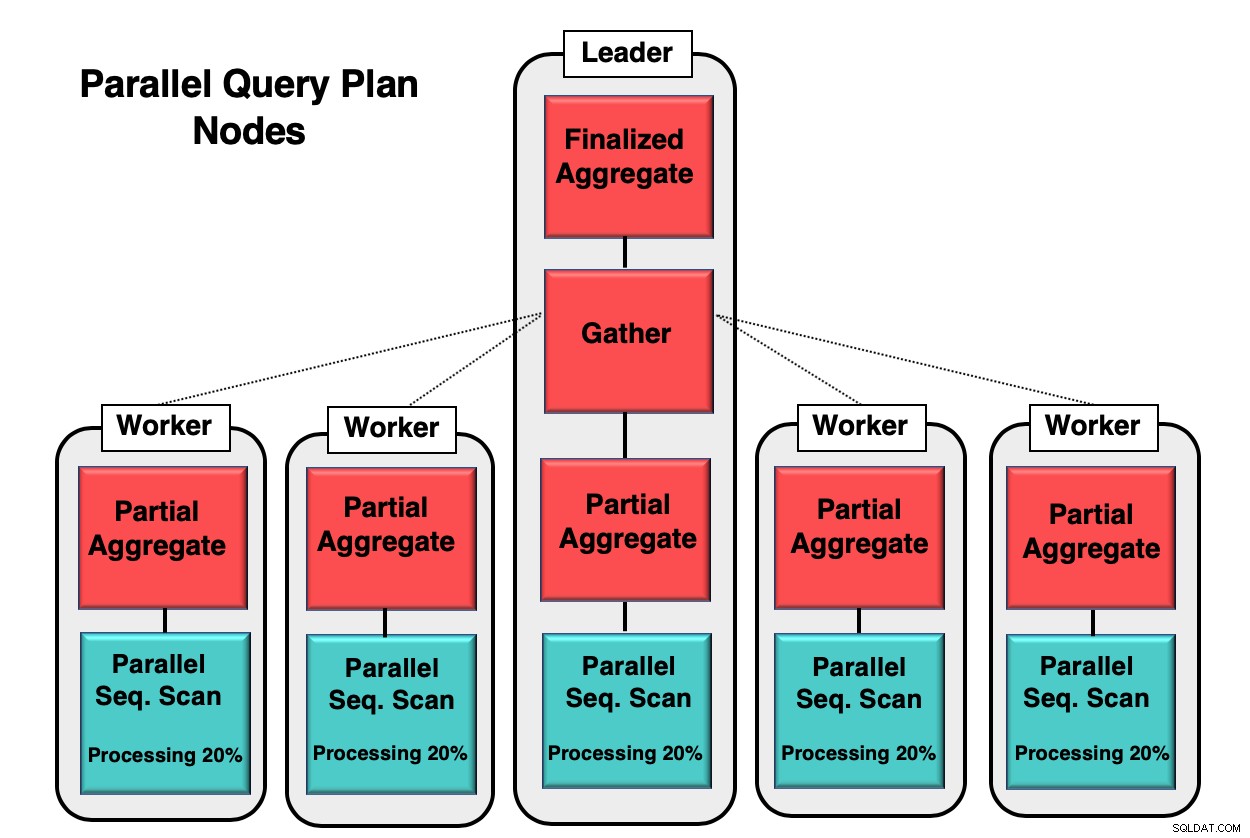
図1は、データベース内で並列処理がどのように行われるかの例を示しています。リーダープロセスは最初のクエリを実行し、個々のワーカープロセスは同じプロセスのコピーを開始します。部分集約ノード(CPUコア)は、データベーステーブルの並列シーケンシャルスキャンの実装を担当します。
この場合、各シーケンシャルスキャンノードは8kbブロックのデータの20%を処理しています。これらの同じノードは、並列認識と呼ばれる手法を使用して、それらのアクティビティを調整できます。各ノードは、どのデータがすでに処理されているか、およびクエリを完了するためにテーブルでどのデータをスキャンする必要があるかについて完全な知識を持っています。タプルが完全に収集されると、収集ノードに送信されてコンパイルおよびファイナライズされます。
並列操作
さまざまなタイプのクエリを使用して、データベースからデータをフェッチし、結果セットを生成できます。複数のコアの使用を効果的に活用する機能を提供する特定の操作は次のとおりです。
シーケンシャルスキャン
これは、テーブル内のデータを最初から最後まで読み取ってデータを収集する操作です。ワークロードを複数のコアに均等に分散して、クエリの処理速度を向上させます。各コアアクティビティを認識しているため、クエリ全体が完了したかどうかを簡単に判断できます。収集ノードは、クエリに基づいて抽出されたデータを受け取ります。
集約
大量のデータを取得し、それを少数の行に凝縮する標準的な操作。これは、クエリに基づいて適切な情報をテーブルまたはインデックスから抽出するだけで、並列処理中に発生します。特定のデータの平均を実行することは、集計の優れた例です。
ハッシュ結合
2つのテーブル間でデータを結合するために使用される手法。これは最速の結合アルゴリズムであり、通常、小さなテーブルと大きなテーブルで実行されます。最初にハッシュテーブルを作成し、1つのテーブルからそこにすべてのデータをロードします。次に、並列順次スキャンを使用して、ハッシュと2番目のテーブルからすべてのデータをスキャンできます。スキャンから抽出された各タプルは、ハッシュテーブルと比較され、一致するものがあるかどうかが確認されます。一致するものが特定されると、データは結合されます。 PostgreSQL 11のリリースでは、並列処理を使用してハッシュ結合を完了すると、以前の処理時間の約3分の1がかかります。
マージ参加
オプティマイザがハッシュ結合がメモリ容量を超えると判断した場合、代わりにマージ結合を実行します。このプロセスでは、2つのソートされたリストを同時にスキャンし、同じ要素を結合します。項目が等しくない場合、データは結合されません。
ネストされたループ結合
この操作は、Quick Basic、Pythonなどの異なるプログラミング言語を含む2つのテーブルを結合する必要がある場合に使用されます。各テーブルは、複数のコアを使用してスキャンおよび処理されます。データが一致する場合、データは結合される収集ノードに送信されます。インデックスもスキャンされるため、このプロセスにはデータを取得するための複数のループが含まれています。平均して、並列プロセスを使用して結合を完了するのにかかる時間はわずか3分の1です。
Bツリーインデックススキャン
この操作は、ソートされたデータのツリーをスキャンして、特定の情報を見つけます。レコードの検索中に多くの待機が発生するため、このプロセスは通常のシーケンシャルスキャンよりも時間がかかります。ただし、適切なデータをスキャンする作業は、複数のプロセッサ間で分割されます。
ビットマップヒープスキャン
この操作を使用すると、複数のインデックスをマージできます。インデックスがあるので、最初に同じ数のビットマップを作成する必要があります。たとえば、インデックスが3つある場合は、最初に3つのビットマップを作成する必要があります。各ビットマップは、クエリに基づいてタプルをフェッチしてコンパイルします。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするパーティションの並列処理
PostgreSQLデータベース内で実行できる並列処理の別の形式があります。ただし、テーブルをスキャンしてタスクを分割することから生じるものではありません。データを特定の値で分割または分割できます。たとえば、バリューバイヤーを取得し、1つのコアにそのバリュー内でのみデータを処理させることができます。そうすれば、各コアがいつでも何を処理しているかを正確に知ることができます。
ハッシュ分割
この操作は、テーブルの行をサブテーブルに分散することによって使用されます。繰り返しますが、通常、除算はテーブルからの個別の値または値リストによって決定されます。これは、すべてのデバイスで効率的なストレージ管理手法がない場合に使用する優れた方法です。 I / Oのボトルネックを防ぐために、パーティショニングを使用してデータをランダムに分散することをお勧めします。
パーティションごとの参加
テーブルをパーティションごとに分割し、類似したパーティションを一致させることによってテーブルを結合するために使用される手法。たとえば、米国全土からの購入者の大規模なテーブルがある場合があります。最初にテーブルをさまざまな都市ごとに分類し、次に各州の地域に基づいていくつかの都市を結合することができます。パーティション単位の結合により、データが簡素化され、テーブルの操作が可能になります。
パラレルアンセーフ
オプティマイザがこれがクエリを完了するための最速の方法であると判断した場合、PostgreSQL11はクエリの並列処理を自動的に実行します。使用しているPostgreSQLのバージョンが高いほど、データベースの並列機能が向上します。残念ながら、機能がある場合でも、すべてのクエリを並行して実行する必要はありません。実行するクエリの種類には特定の制限がある場合があり、1つのコアのみがすべての処理を完了する必要があります。これにより、システムのパフォーマンスが低下しますが、受信したデータ全体が保証されます。
クエリが危険にさらされないようにするために、開発者は並列安全ではないという関数を作成しました。データベースオプティマイザを手動でオーバーライドし、クエリが並列にならないように要求できます。並列処理のプロセスは実行されません。
PostgreSQLデータベース内の並列処理は、データベースのバージョンごとにのみ改善されている機能です。テクノロジーの将来は不透明ですが、この機能の使用は今後も続くようです。
詳細については、以下をチェックしてください...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“ divide-and-conquer-joins-between-partitioned-table