企業の分析システムを実装する必要がある場合、データをどこに保存するかという問題がよくあります。すべての要件に最適なオプションが常にあるとは限りません。それは、予算、データの量、および会社のニーズによって異なります。
PostgreSQLは、最も高度なオープンソースデータベースとして非常に柔軟性があり、単純なリレーショナルデータベース、時系列データデータベース、さらには効率的で低コストのデータウェアハウジングソリューションとしても機能します。いくつかの分析ツールと統合することもできます。
広く互換性があり、低コストでパフォーマンスの高いデータウェアハウスを探している場合、最適なデータベースオプションはPostgreSQLですが、なぜでしょうか。このブログでは、データウェアハウスとは何か、なぜそれが必要なのか、そしてなぜPostgreSQLがここで最良の選択肢となるのかを説明します。
データウェアハウスとは
データウェアハウスは、標準化され、一貫性があり、統合されたシステムであり、レポートおよびデータ分析に使用される1つ以上のソースからの現在または過去のデータが含まれています。これは、ビジネスインテリジェンスのコアコンポーネントと見なされています。これは、企業がその商業的コンテキストをよりよく理解するために使用する戦略とテクノロジーです。
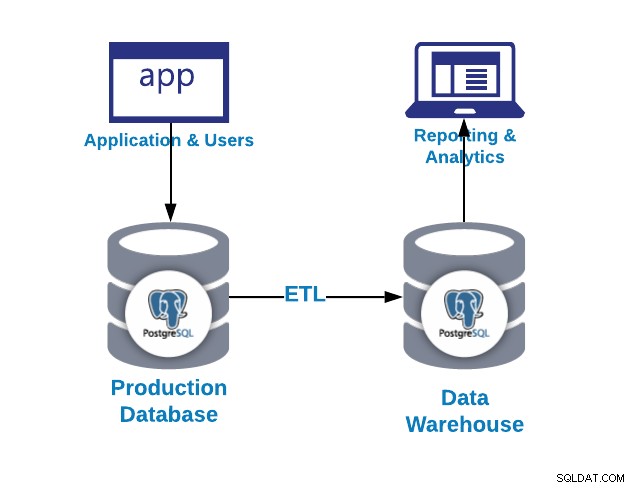
最初に尋ねる質問は、なぜデータウェアハウスが必要なのかということです。
- 統合:複数のシステム/データベースからのデータを統合/一元化する
- 標準化:すべてのデータを同じ形式で標準化します
- 分析:履歴コンテキストでデータを分析します
データウェアハウスの利点のいくつかは...
- 複数のソースからのデータを単一のデータベースに統合する
- 長時間実行されるクエリによる本番環境のロックやロードを回避します
- 履歴情報を保存する
- 分析要件に合うようにデータを再構築します
前の画像でわかるように、OLAPとOLTPの両方の提案にPostgreSQLを使用できます。違いを見てみましょう。
- OLTP:オンライントランザクション処理。一般に、ユーザーアクティビティによって生成される多数の短いオンライントランザクション(INSERT、UPDATE、DELETE)があります。これらのシステムは、マルチアクセス環境での非常に高速なクエリ処理とデータの整合性の維持に重点を置いています。ここで、有効性は1秒あたりのトランザクション数で測定されます。 OLTPデータベースには、詳細な最新データが含まれています。
- OLAP:オンライン分析処理。一般に、大規模なレポートによって生成される複雑なトランザクションの量は少なくなります。応答時間は有効性の尺度です。これらのデータベースは、集約された履歴データを多次元スキーマに格納します。 OLAPデータベースは、複数のソースと観点から多次元データを分析するために使用されます。
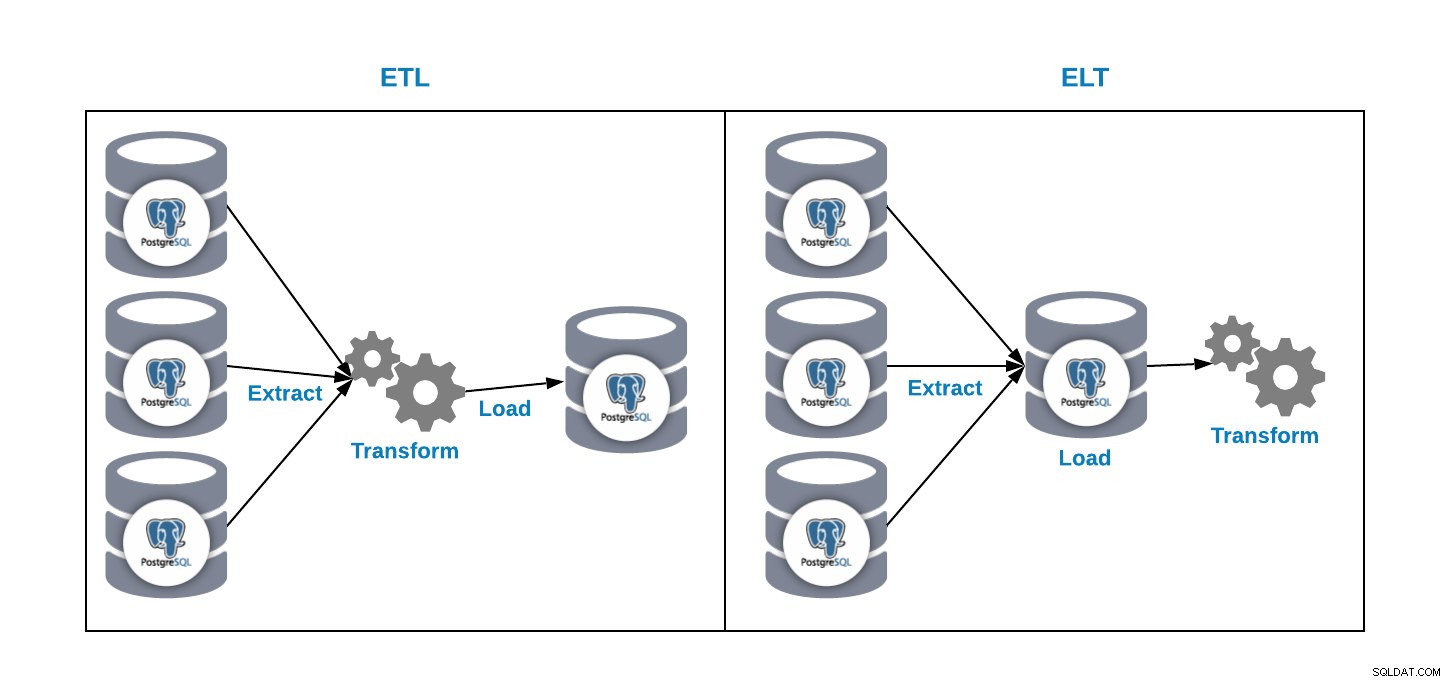
分析データベースにデータをロードする方法は2つあります。
- ETL:抽出、変換、および読み込み。これは、データウェアハウスを生成する方法です。まず、本番データベースからデータを抽出し、要件に応じてデータを変換してから、データウェアハウスにデータを読み込みます。
- ELT:抽出、ロード、変換。まず、本番データベースからデータを抽出し、データベースにロードしてから、データを変換します。この方法はデータレイクと呼ばれ、ビッグデータを管理するための新しい概念です。
そして今、2番目の質問i、データウェアハウスにPostgreSQLを使用する必要があるのはなぜですか?
データウェアハウスとしてのPostgreSQLの利点
PostgreSQLをデータウェアハウスとして使用する利点のいくつかを見てみましょう...
- コスト:オンプレミス環境を使用している場合、製品自体のコストは0ドルになります。クラウドで製品を使用している場合でも、PostgreSQLベースの製品のコストはおそらく以下になります。残りの製品。
- スケール:必要な数のレプリカノードを追加することで、簡単な方法で読み取りをスケールできます。
- パフォーマンス:正しい構成では、PostgreSQLはさまざまなescenariosで非常に優れたパフォーマンスを発揮します。
- 互換性:PostgreSQLを、データマイニング、OLAP、およびレポート用の外部ツールまたはアプリケーションと統合できます。
- 拡張性:PostgreSQLにはユーザー定義のデータ型と関数があります。
データウェアハウス情報の管理に役立つPostgreSQLの機能もいくつかあります...
- 一時テーブル:データベースセッションの期間中に存在する短期間のテーブルです。 PostgreSQLは、セッションまたはトランザクションの終了時に一時テーブルを自動的に削除します。
- ストアドプロシージャ:複数の言語(PL / pgSQL、PL / Perl、PL / Pythonなど)でプロシージャまたは関数を作成するために使用できます。
- パーティショニング:これは、データベースのメンテナンス、パーティションキーを使用したクエリ、およびINSERTのパフォーマンスに非常に役立ちます。
- マテリアライズドビュー:クエリ結果は表として表示されます。
- 表領域:データの場所を別のディスクに変更できます。このようにして、ディスクアクセスを並列化できます。
- PITR互換:ポイントインタイムリカバリ互換のバックアップを作成できるため、障害が発生した場合に、特定の期間にデータベースの状態を復元できます。
- 巨大なコミュニティ:そして最後になりましたが、PostgreSQLには、さまざまな問題のサポートを見つけることができる巨大なコミュニティがあります。
データウェアハウスで使用するためのPostgreSQLの構成
すべての場合およびすべてのデータベーステクノロジで使用するのに最適な構成はありません。これは、ハードウェア、使用法、システム要件などの多くの要因によって異なります。以下は、正しい方法でデータウェアハウスとして機能するようにPostgreSQLデータベースを構成するためのヒントです。
メモリベース
- max_connections:データウェアハウスデータベースとして、大量の接続は必要ありません。これは、レポートと分析の作業に使用されるため、このパラメーターを使用して最大接続数を制限できます。
- shared_buffers:データベースサーバーが共有メモリバッファに使用するメモリの量を設定します。妥当な値は、RAMメモリの15%から25%です。
- effective_cache_size:この値は、メモリに収まる場合と収まらない場合があるプランを考慮に入れるためにクエリプランナーによって使用されます。これは、インデックスを使用する場合のコスト見積もりで考慮されます。値が高いとインデックススキャンが使用される可能性が高くなり、値が低いとシーケンシャルスキャンが使用される可能性が高くなります。妥当な値は、RAMメモリの約75%です。
- work mem:ディスク上の一時ファイルに書き込む前に、ORDER BY、DISTINCT、JOIN、およびハッシュテーブルの内部操作によって使用されるメモリの量を指定します。この値を構成するときは、複数のセッションがこれらの操作を同時に実行していることを考慮する必要があります。各操作は、一時ファイルへのデータの書き込みを開始する前に、この値で指定された量のメモリを使用できます。妥当な値は、RAMメモリの約2%です。
- maintenance_work_mem:VACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEYなど、メンテナンス操作が使用するメモリの最大量を指定します。妥当な値は、RAMメモリの約15%です。
CPUベース
- Max_worker_processes:システムがサポートできるバックグラウンドプロセスの最大数を設定します。妥当な値はCPUの数です。
- Max_parallel_workers_per_gather:単一のGatherまたはGatherMergeノードで開始できるワーカーの最大数を設定します。妥当な値は、CPU数の50%です。
- Max_parallel_workers:システムが並列クエリでサポートできるワーカーの最大数を設定します。妥当な値はCPUの数です。
データウェアハウスに読み込まれるデータは変更されないため、PostgreSQLデータベースへの余分な負荷を回避するためにAutovacuumをオフに設定することもできます。 VacuumおよびAnalyzeプロセスは、バッチロードプロセスの一部にすることができます。
結論
広く互換性があり、低コストで高性能なデータウェアハウスをお探しの場合は、データウェアハウスデータベースのオプションとしてPostgreSQLを検討する必要があります。 PostgreSQLには、パーティショニングやストアドプロシージャなど、データウェアハウスの管理に役立つ多くの利点と機能があります。