高可用性は、PostgreSQLを使用する世界中のほぼすべての企業の要件です。PostgreSQLがレプリケーション方法としてストリーミングレプリケーションを使用することはよく知られています。 PostgreSQL Streaming Replicationはデフォルトで非同期であるため、スタンバイサーバーにまだレプリケートされていない一部のトランザクションをプライマリノードでコミットすることができます。これは、潜在的なデータ損失の可能性があることを意味します。
コミットプロセスのこの遅延は非常に小さいと思われます...スタンバイサーバーが負荷に追いつくのに十分強力である場合。この小さなデータ損失のリスクが社内で受け入れられない場合は、デフォルトの代わりに同期レプリケーションを使用することもできます。
同期レプリケーションでは、書き込みトランザクションの各コミットは、コミットがプライマリサーバーとスタンバイサーバーの両方のディスクの先行書き込みログに書き込まれたことの確認まで待機します。
この方法は、データ損失の可能性を最小限に抑えます。データ損失が発生するためには、プライマリとスタンバイの両方が同時に失敗する必要があります。
この方法の欠点は、すべての同期方法で同じです。この方法では、各書き込みトランザクションの応答時間が長くなります。これは、トランザクションがコミットされたというすべての確認まで待つ必要があるためです。幸い、読み取り専用トランザクションはこれによる影響を受けませんが、書き込みトランザクションのみ。
このブログでは、PostgreSQLクラスターを最初からインストールし、非同期レプリケーション(デフォルト)を同期レプリケーションに変換する方法を紹介します。また、以前の状態に簡単に戻ることができるため、応答時間が許容できない場合にロールバックする方法についても説明します。プロセス全体で1つのツールのみを使用して、ClusterControlを使用してPostgreSQL同期レプリケーションを簡単にデプロイ、構成、および監視する方法を説明します。
PostgreSQLクラスターのインストール
非同期PostgreSQLレプリケーションのインストールと構成を始めましょう。これは、PostgreSQLクラスターで使用される通常のレプリケーションモードです。 CentOS7ではPostgreSQL11を使用します。
PostgreSQLのインストール
PostgreSQLの公式インストールガイドに従って、このタスクは非常に簡単です。
まず、リポジトリをインストールします:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmPostgreSQLクライアントおよびサーバーパッケージをインストールします:
$ yum install postgresql11 postgresql11-server$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11スタンバイノードでは、バイナリバックアップを復元してストリーミングレプリケーションを作成するため、最後のコマンド(データベースサービスの開始)を回避できます。
次に、非同期PostgreSQLレプリケーションに必要な構成を見てみましょう。
PostgreSQLプライマリノードで、次の基本構成を使用して非同期レプリケーションを作成する必要があります。変更されるファイルはpostgresql.confとpg_hba.confです。通常、これらはデータディレクトリ(/ var / lib / pgsql / 11 / data /)にありますが、データベース側で確認できます:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
postgresql.conf構成ファイルで次のパラメーターを変更または追加します。
ここで、リッスンするIPアドレスを追加する必要があります。デフォルト値は「localhost」です。この例では、サーバー内のすべてのIPアドレスに「*」を使用します。
listen_addresses = '*' port = 5432 WALに書き込まれる情報の量を決定します。可能な値は、最小、レプリカ、または論理です。 hot_standby値はレプリカにマップされ、以前のバージョンとの互換性を維持するために使用されます。
wal_level = hot_standbymax_wal_senders = 16pg_walディレクトリに保持するWALファイルの最小量を設定します。
wal_keep_segments = 32これらのパラメータを変更するには、データベースサービスを再起動する必要があります。
$ systemctl restart postgresql-11Pg_hba.conf
pg_hba.conf構成ファイルで次のパラメーターを変更または追加します。
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5ご覧のとおり、ここでユーザーアクセス許可を追加する必要があります。最初の列は接続タイプであり、ホストまたはローカルにすることができます。次に、データベース(レプリケーション)、ユーザー、送信元IPアドレス、および認証方法を指定する必要があります。このファイルを変更するには、データベースサービスをリロードする必要があります。
$ systemctl reload postgresql-11この構成は、プライマリノードとスタンバイノードの両方に追加する必要があります。障害が発生した場合にスタンバイノードをマスターに昇格させる場合に必要になるためです。
次に、レプリケーションユーザーを作成する必要があります。
ROLE(ユーザー)は、ストリーミングレプリケーションで使用するためにREPLICATION権限を持っている必要があります。
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLE対応するファイルを構成してユーザーを作成したら、プライマリノードから一貫性のあるバックアップを作成し、スタンバイノードに復元する必要があります。
スタンバイノードで、/ var / lib / pgsql / 11 /ディレクトリに移動し、現在のdatadirを移動または削除します。
$ cd /var/lib/pgsql/11/
$ mv data data.bk次に、pg_basebackupコマンドを実行して、現在のプライマリdatadirを取得し、正しい所有者を割り当てます(postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataここで、非同期レプリケーションを作成するには、次の基本構成を使用する必要があります。変更されるファイルはpostgresql.confであり、新しいrecovery.confファイルを作成する必要があります。どちらも/var/ lib / pgsql /11/にあります。
Recovery.conf
standby_mode = 'on'primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'recovery_target_timeline = 'latest'trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
postgresql.conf構成ファイルで次のパラメーターを変更または追加します。
WALに書き込まれる情報の量を決定します。可能な値は、最小、レプリカ、または論理です。 hot_standby値はレプリカにマップされ、以前のバージョンとの互換性を維持するために使用されます。この値を変更するには、サービスを再起動する必要があります。
wal_level = hot_standbyhot_standby = on必要な構成がすべて整ったので、スタンバイノードでデータベースサービスを開始するだけです。
$ systemctl start postgresql-11そして、/ var / lib / pgsql / 11 / data /log/のデータベースログを確認します。次のようなものが必要です:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1次のクエリを実行して、プライマリノードのレプリケーションステータスを確認することもできます。
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)ご覧のとおり、非同期レプリケーションを使用しています。
次に、この非同期レプリケーションを同期レプリケーションに変換します。このためには、プライマリノードとスタンバイノードの両方を構成する必要があります。
PostgreSQLプライマリノードでは、以前の非同期構成に加えて、この基本構成を使用する必要があります。
Postgresql.conf
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'synchronous_commit = onPostgreSQLスタンバイノードで、primary_conninfoパラメータに'application_name値を追加してrecovery.confファイルを変更する必要があります。
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'プライマリノードとスタンバイノードの両方でデータベースサービスを再起動します:
$ service postgresql-11 restartこれで、同期ストリーミングレプリケーションが稼働しているはずです:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)非同期PostgreSQLレプリケーションに戻る必要がある場合は、プライマリノードのpostgresql.confファイルで実行された変更をロールバックする必要があります。
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = on$ service postgresql-11 restartこれで、非同期レプリケーションを再度実行する必要があります。
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)ClusterControlを使用してPostgreSQL同期レプリケーションをデプロイする方法
ClusterControlを使用すると、展開、構成、および監視のタスクを同じジョブから1つにまとめて実行でき、同じUIから管理できます。
ClusterControlがインストールされており、SSH経由でデータベースノードにアクセスできることを前提としています。 ClusterControlアクセスを構成する方法の詳細については、公式ドキュメントを参照してください。
ClusterControlに移動し、[展開]オプションを使用して新しいPostgreSQLクラスターを作成します。
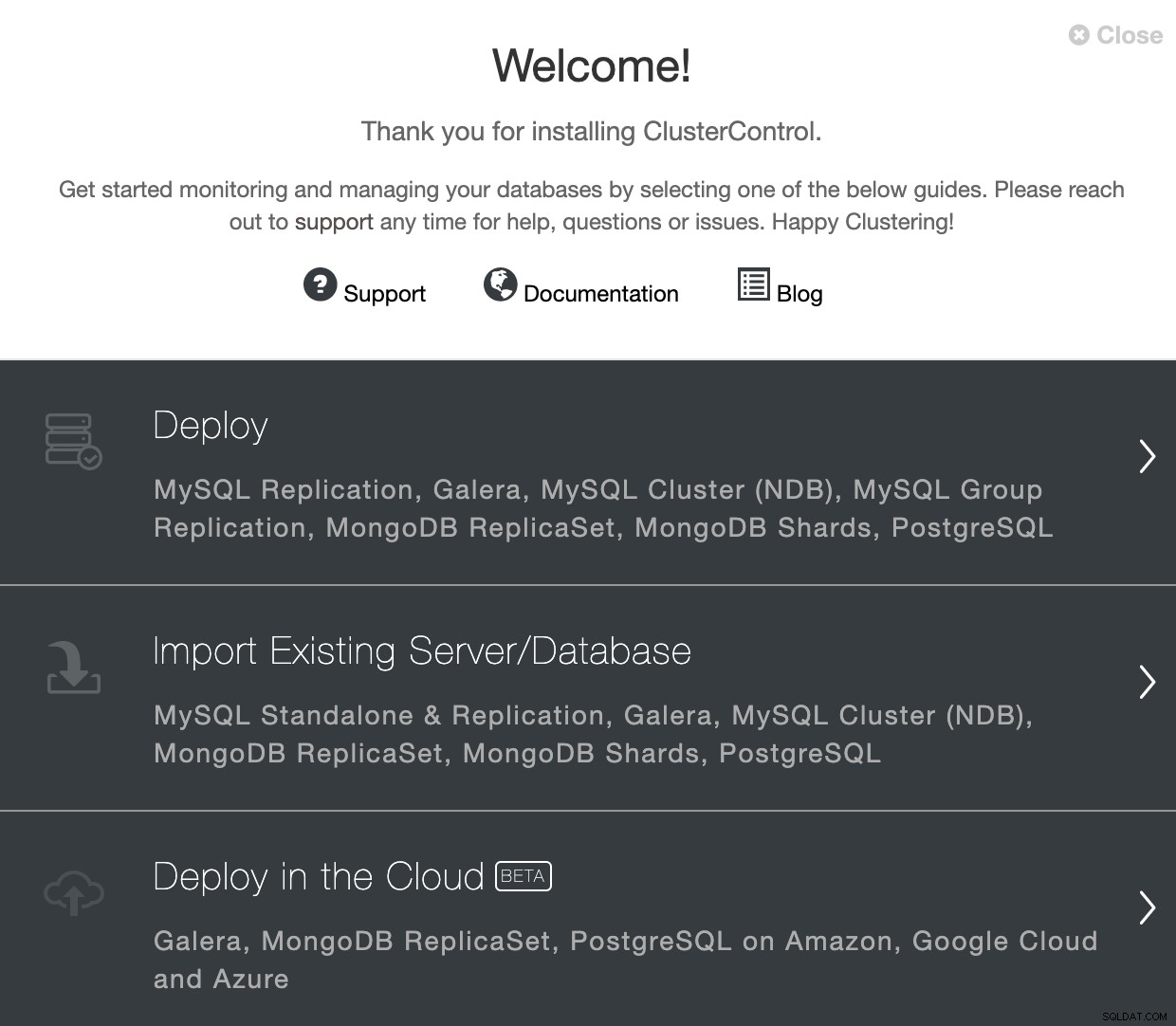
PostgreSQLを選択するときは、ユーザー、キー、またはパスワードを指定する必要があります。 SSHでサーバーに接続するためのポート。また、新しいクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合も必要です。
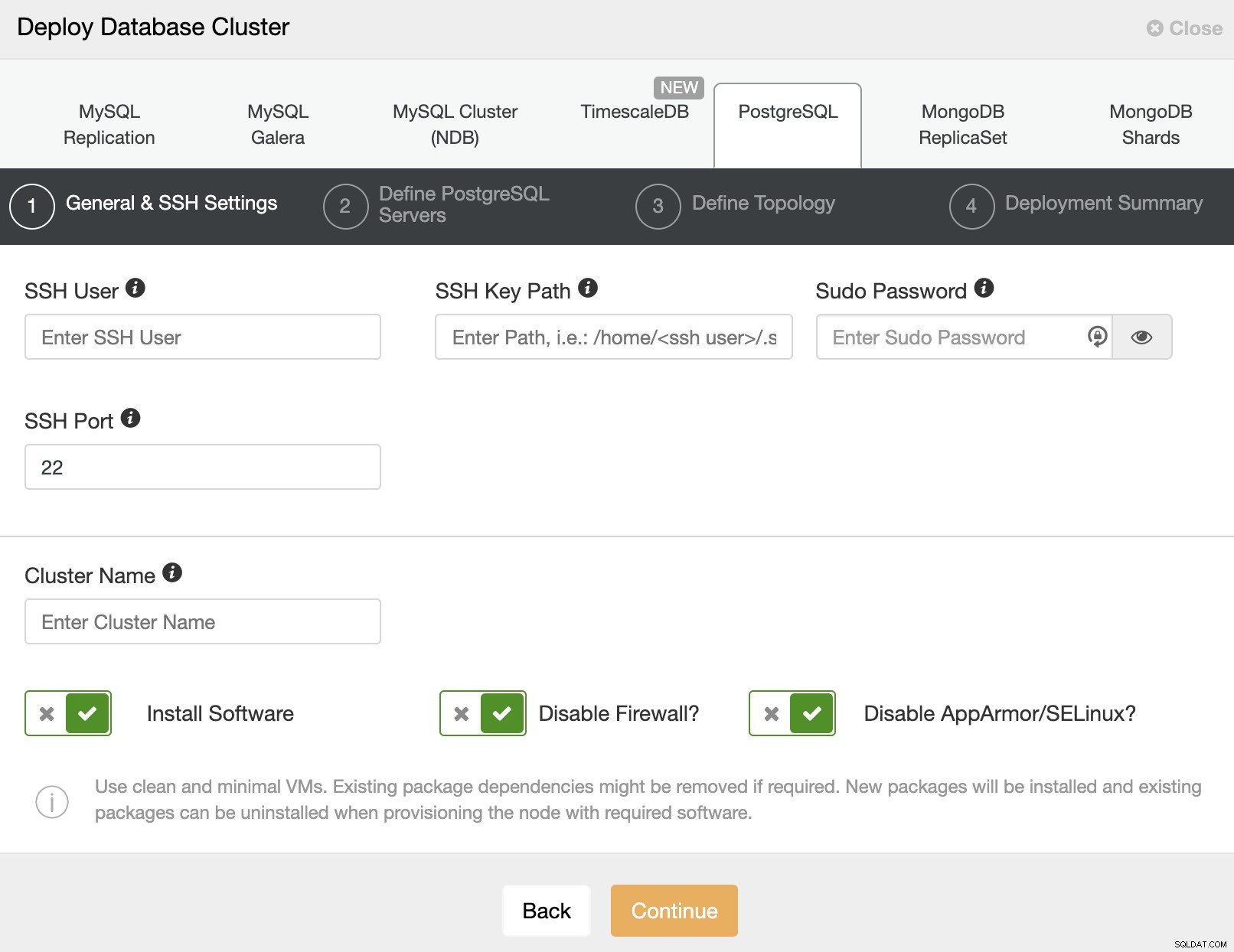
SSHアクセス情報を設定した後、アクセスするデータを入力する必要がありますあなたのデータベース。使用するリポジトリを指定することもできます。
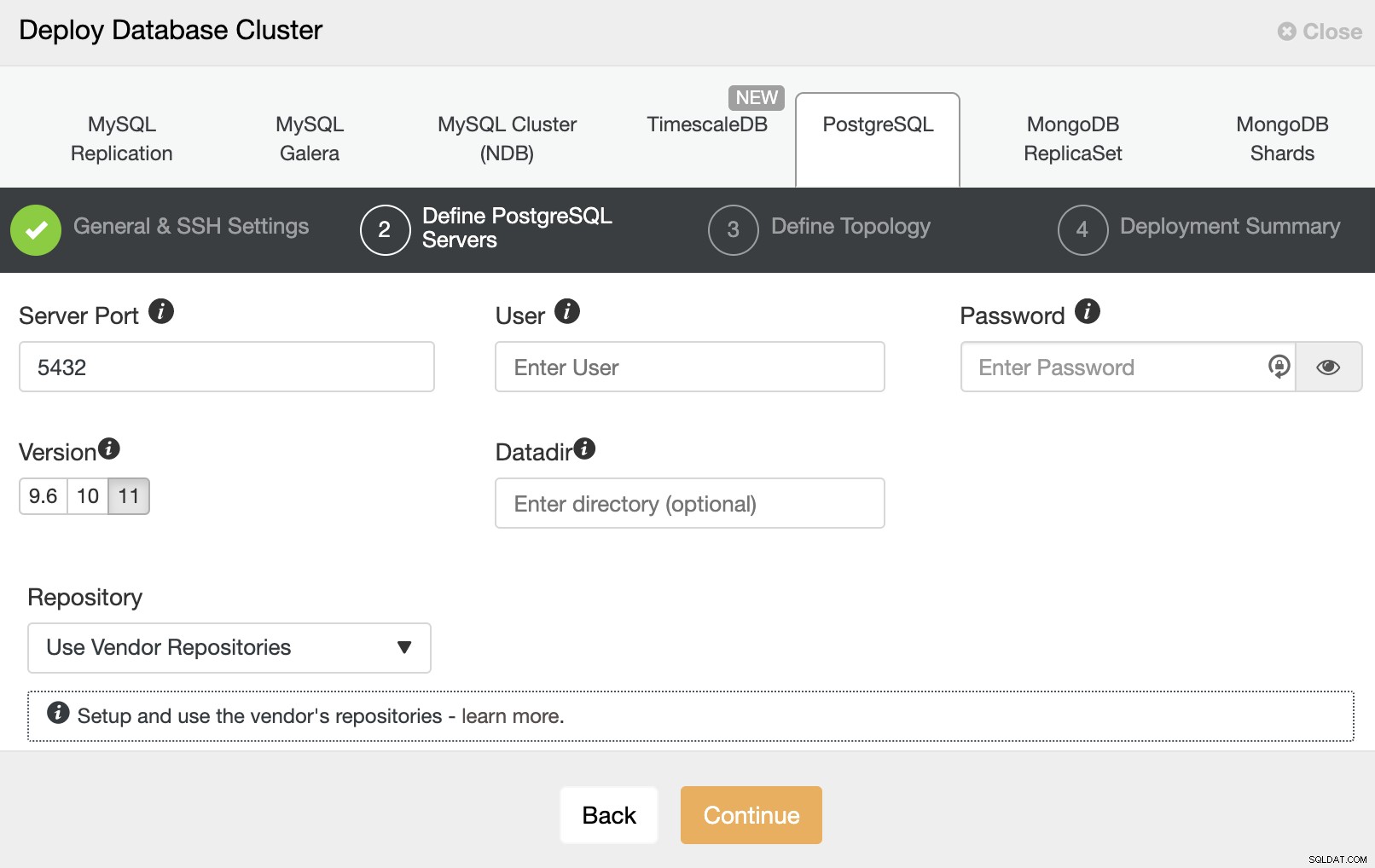
次のステップでは、サーバーをクラスターに追加する必要があります。作成します。サーバーを追加するときに、IPまたはホスト名を入力できます。
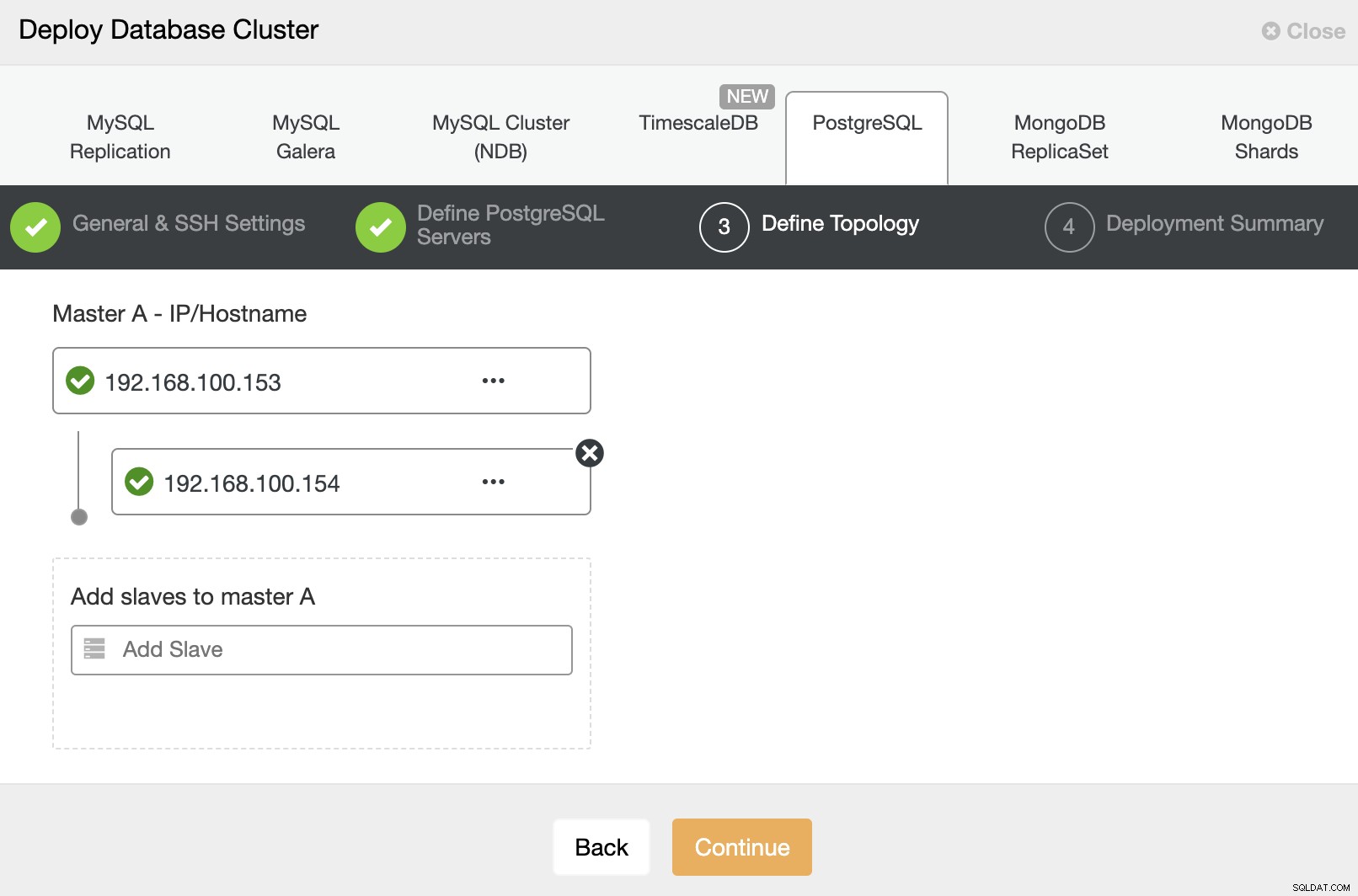
最後に、最後のステップで、レプリケーション方法を選択できます。非同期または同期レプリケーションにすることができます。
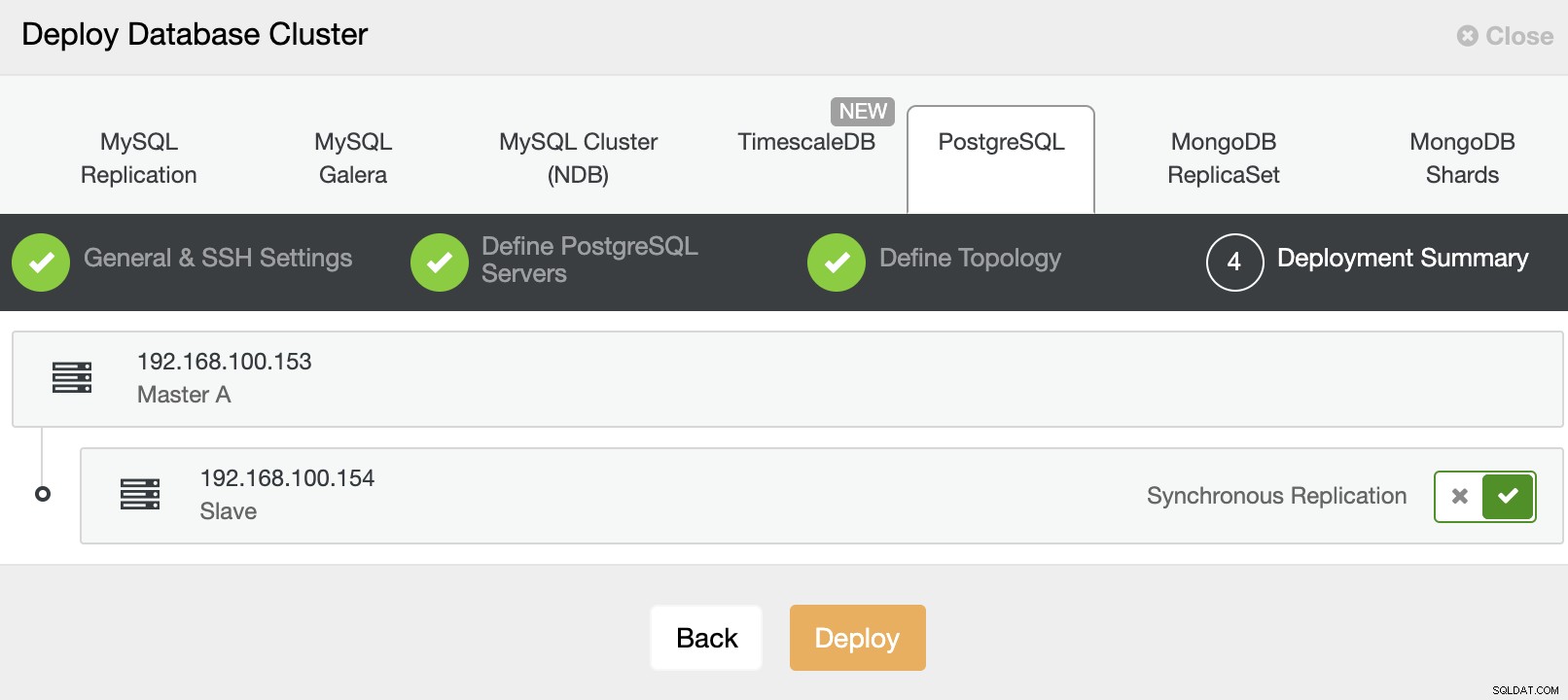
以上です。 ClusterControlアクティビティセクションでジョブのステータスを監視できます。
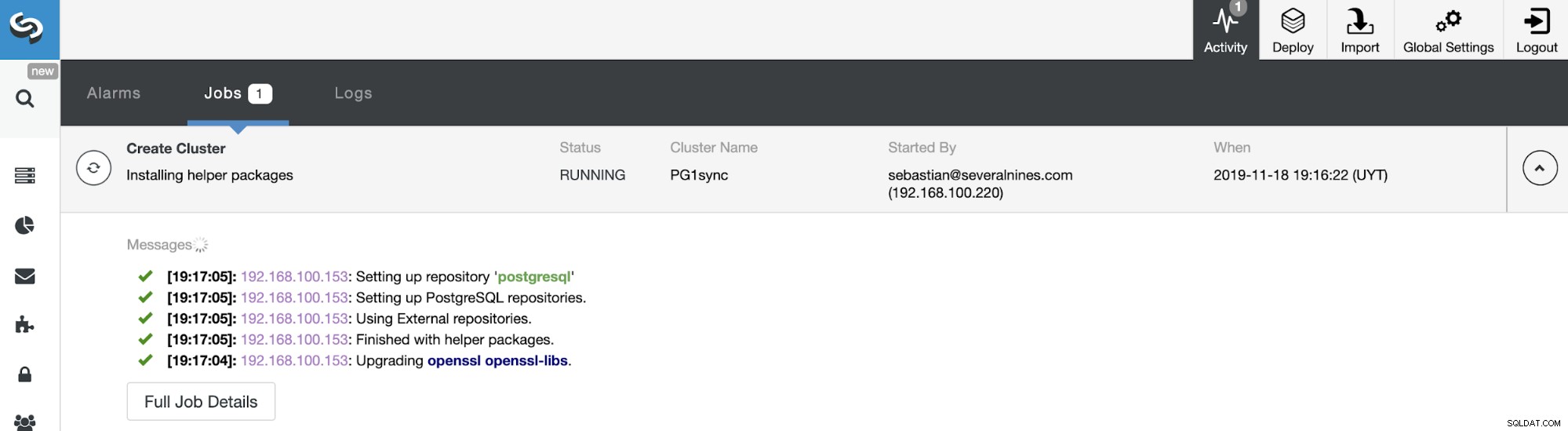
そして、このジョブが終了すると、PostgreSQL同期クラスターがインストールされます。 ClusterControlによって構成および監視されます。
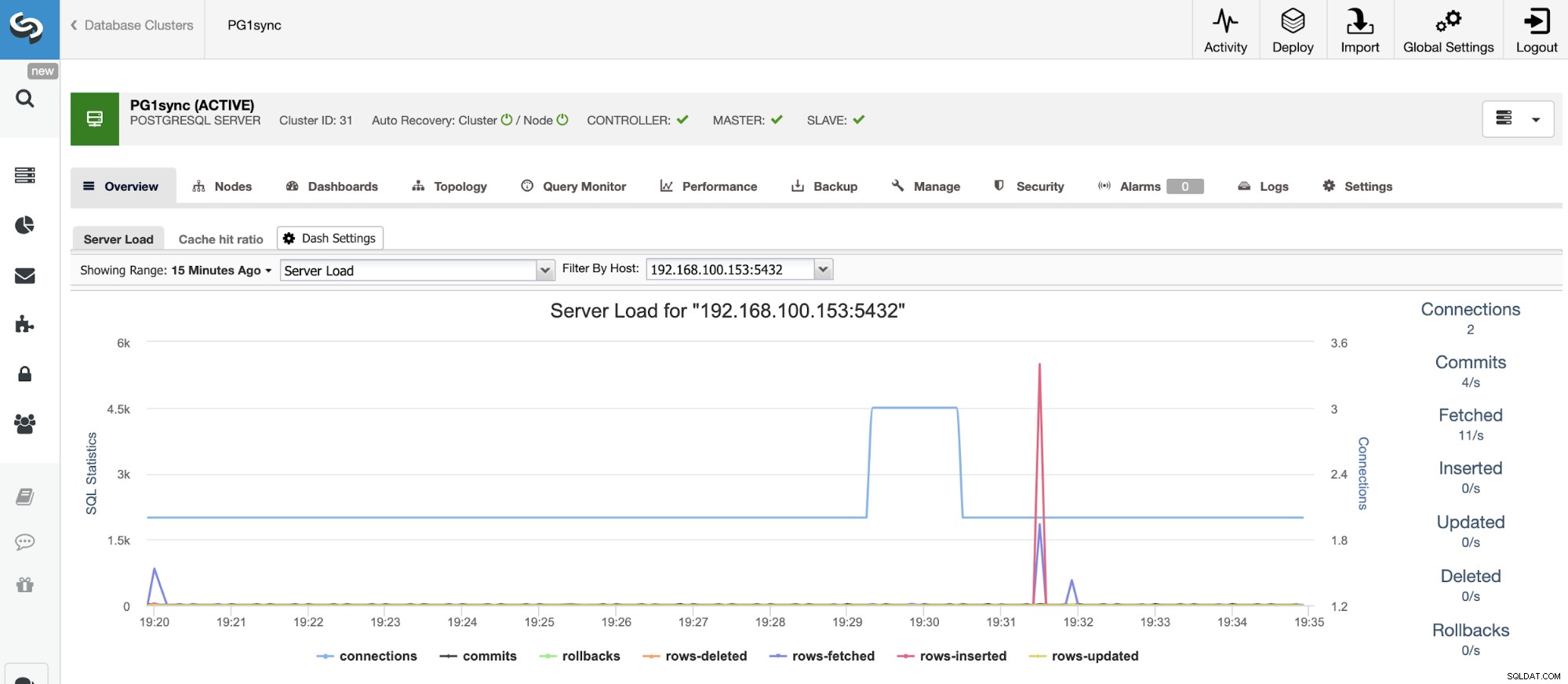
このブログの冒頭で述べたように、高可用性はすべての企業の要件であるため、使用中の各テクノロジーで高可用性を実現するための利用可能なオプションを知っておく必要があります。 PostgreSQLの場合、同期ストリーミングレプリケーションを最も安全な実装方法として使用できますが、この方法はすべての環境とワークロードで機能するわけではありません。
高可用性ソリューションではなく、問題となる可能性のある各トランザクションの確認を待つことによって発生する遅延に注意してください。