このブログは、PostgreSQLのマルチデータセンターセットアップの実装の第2部です。このブローでは、このタイプの環境にPostgreSQLをデプロイする方法と、ClusterControl自動回復機能を使用してマスターに障害が発生した場合にフェイルオーバーする方法を示します。
この時点で、データセンター間の接続があり(このブログの最初の部分で見たように)、このタスクに必要なサーバーがあると想定します(前の部分)。
PostgreSQLクラスターをデプロイする
このタスクにはClusterControlを使用するため、インストールされていると想定します(同じロードバランサーサーバーにインストールできますが、別のサーバーを使用できる場合はさらに適切です)。
ClusterControlサーバーに移動し、[展開]オプションを選択します。すでにPostgreSQLインスタンスを実行している場合は、代わりに[既存のサーバー/データベースのインポート]を選択する必要があります。
PostgreSQLを選択するときは、ユーザー、キー、またはパスワードを指定し、ポートを次のように指定する必要があります。 SSHでPostgreSQLホストに接続します。新しいクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合にも必要です。
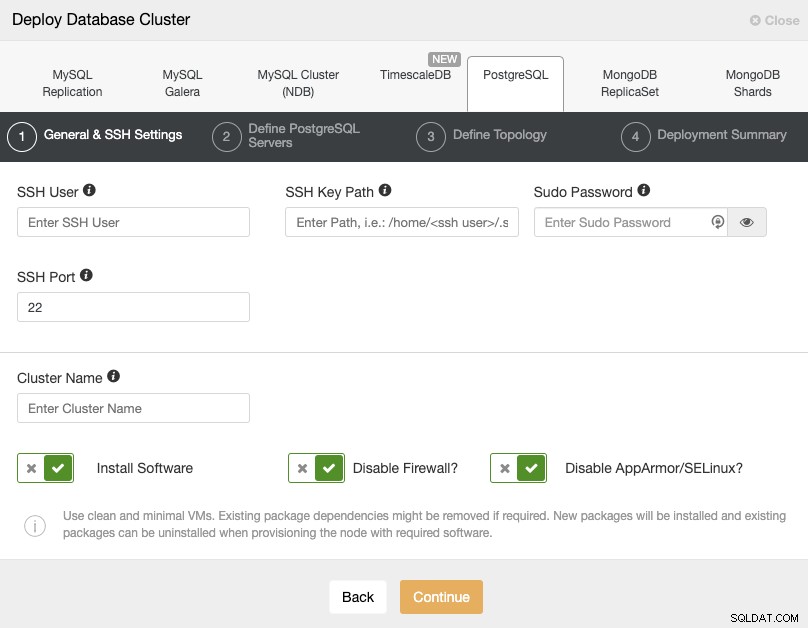
ここで、このタスクのClusterControlユーザー要件を確認してください。以前のブログでは、ここで「リモート」ユーザーと正しいSSHポートを使用する必要があります(前述のように、VPNの代わりにパブリックIPアドレスを使用してアクセスする場合は、別のユーザーを使用することをお勧めします)。
>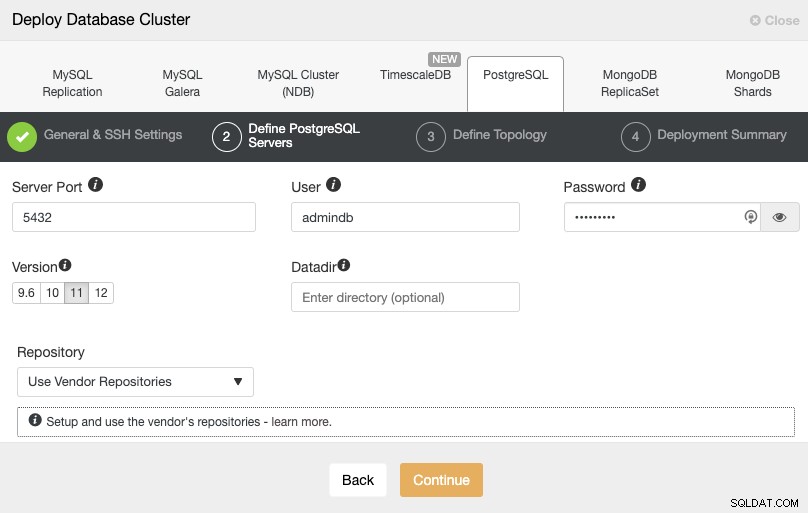
SSHアクセス情報を設定した後、データベースユーザーを定義する必要があります。 versionとdatadir(オプション)。使用するリポジトリを指定することもできます。次のステップでは、作成するクラスターにサーバーを追加する必要があります。
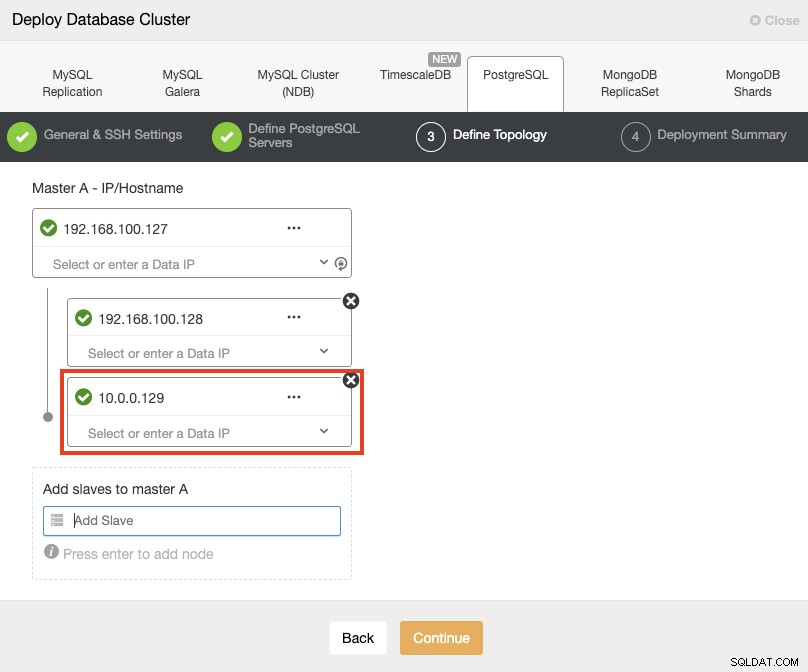
サーバーを追加するときに、IPまたはホスト名を入力できます。このパートでは、サーバーのパブリックIPアドレスを使用します。赤いボックスでわかるように、2番目のスタンバイノードに別のネットワークを使用しています。 ClusterControlには、使用するネットワークに関する制限はありません。これに関する唯一の要件は、ノードへのSSHアクセスが必要です。
したがって、前の例に従うと、これらのIPアドレスは次のようになります。
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)最後のステップで、レプリケーションを同期にするか非同期にするかを選択できます。
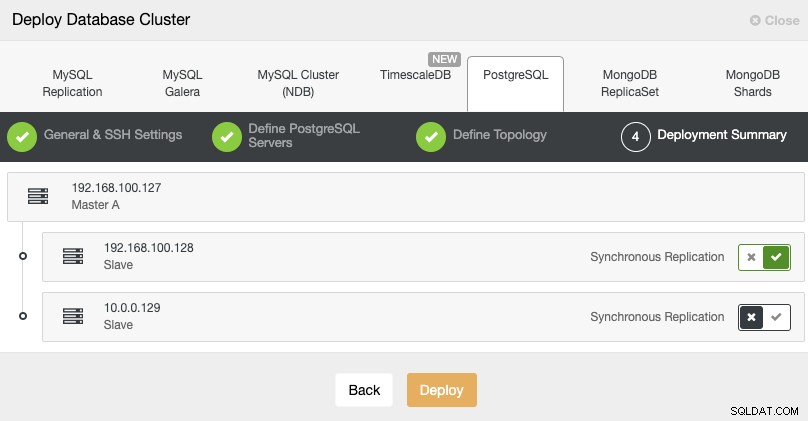
この場合、リモートノードに非同期レプリケーションを使用することが重要です。そうでない場合、クラスタは遅延またはネットワークの問題の影響を受ける可能性があります。
ClusterControlアクティビティモニターから新しいクラスターの作成ステータスを監視できます。
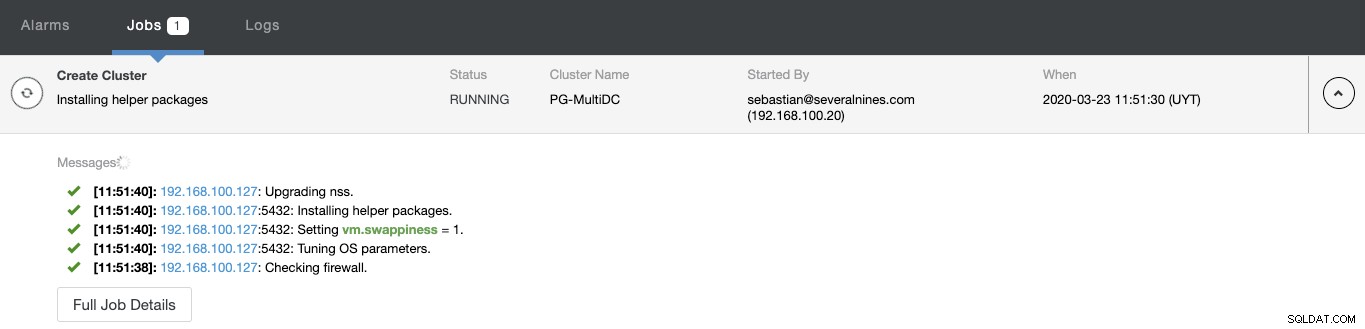
タスクが完了すると、新しいPostgreSQLクラスターがClusterControlのメイン画面。

PostgreSQLロードバランサー(HAProxy)の追加
クラスターを作成したら、ロードバランサー(HAProxy)や新しいレプリカの追加など、いくつかのタスクを実行できます。
前の例に従うために、前述のように、HA環境の管理に役立つロードバランサーを追加しましょう。これを行うには、ClusterControl-> PostgreSQL Cluster-> Cluster Actions-> AddLoadBalancerを選択します。
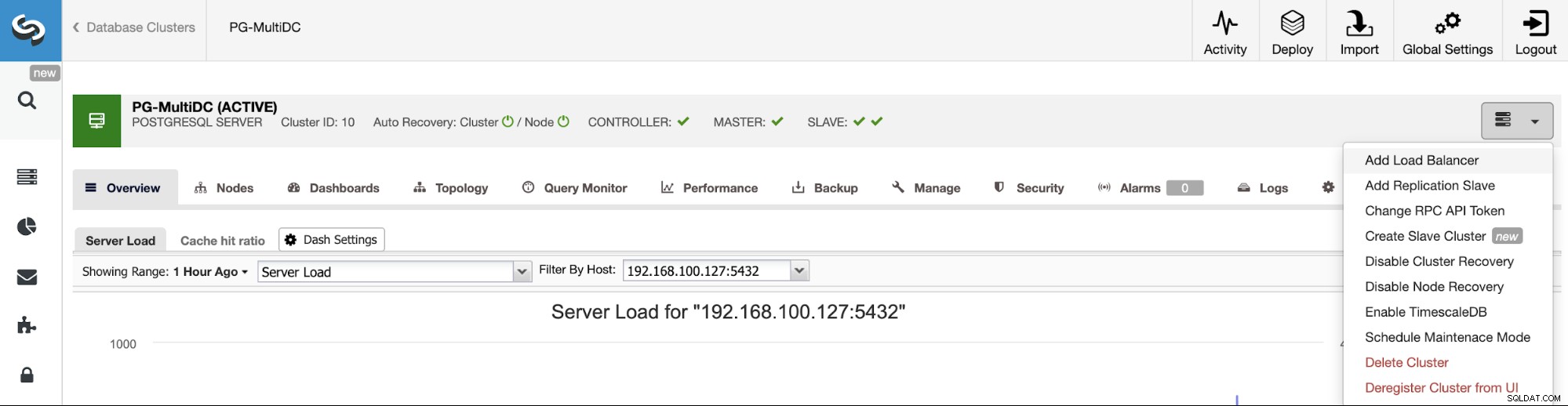
ここで、ClusterControlがインストールと構成に使用する情報を追加する必要があります。 HAProxyロードバランサー。このロードバランサーは同じClusterControlサーバーにインストールできますが、別のサーバーを使用できる場合はさらに優れています。
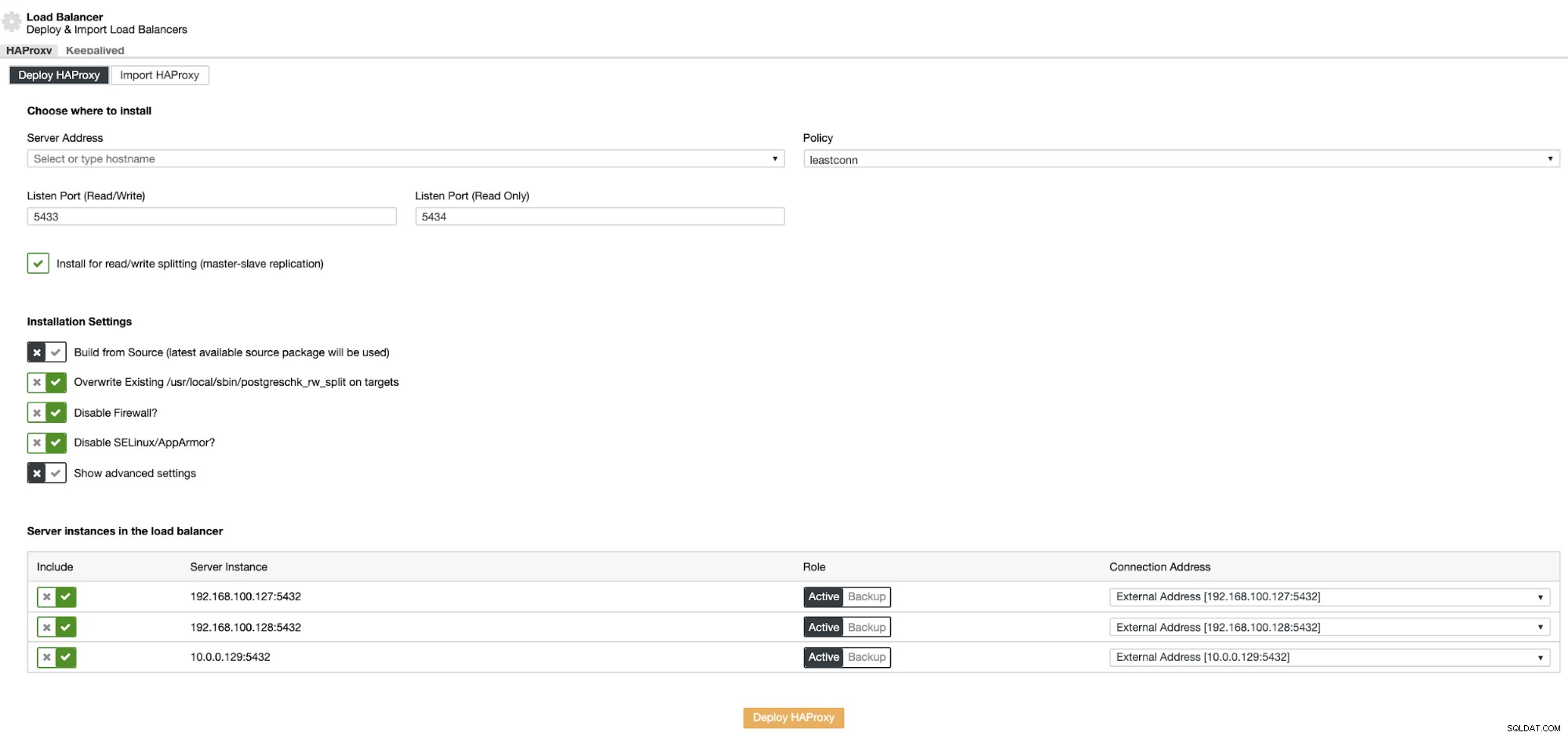
紹介する必要のある情報は次のとおりです。
アクション:デプロイまたはインポート。
サーバーアドレス:HAProxyサーバーのIPアドレス(同じClusterControl IPアドレスにすることができます)。
リッスンポート(読み取り/書き込み):読み取り/書き込みモードのポート。
リッスンポート(読み取り専用):読み取り専用モードのポート。
ポリシー:次のようになります:
- lessonconn:接続数が最も少ないサーバーが接続を受信します。
- ラウンドロビン:各サーバーは、その重みに応じて順番に使用されます。
- source:送信元IPアドレスがハッシュされ、実行中のサーバーの総重量で除算されて、リクエストを受信するサーバーを指定します。
読み取り/書き込み分割用のインストール:マスター/スレーブレプリケーション用。
ソースからビルド:パッケージマネージャーからインストールするか、ソースからビルドするかを選択できます。
そして、HAProxy構成に追加するサーバーを選択する必要があります。
また、管理者ユーザー、バックエンド名、タイムアウトなどの詳細設定を構成できます。
構成を完了してデプロイを確認したら、ClusterControlUIの[アクティビティ]セクションで進行状況を確認できます。
これが終了したら、ClusterControl->ノード->に移動できます。 HAProxyノード、および現在のステータスを確認します。
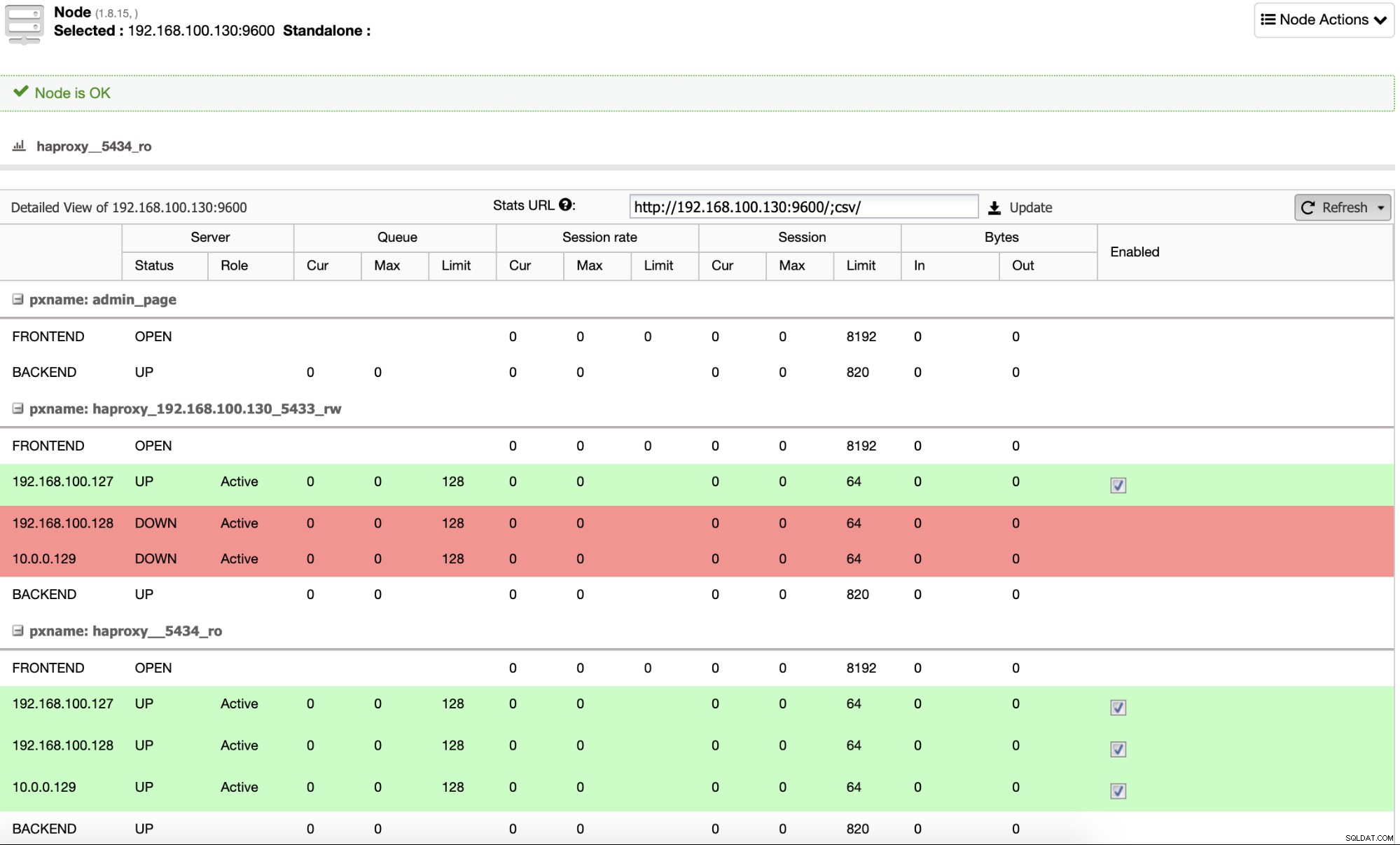
デフォルトでは、ClusterControlは2つの異なるポート(1つは読み取り用)でHAProxyを構成します。アプリケーションまたはユーザーがデータを書き込む(および読み取る)ために使用される書き込みと、すべてのノード間で読み取りトラフィックのバランスを取るために使用される読み取り専用用の書き込み。読み取り/書き込みポートでは、マスターノードのみが有効になり、マスターに障害が発生した場合、ClusterControlは最も高度なスレーブをマスターに昇格させ、このポートを再構成して古いマスターを無効にし、新しいマスターを有効にします。このように、トラフィックはロードバランサーによって正しいノードにリダイレクトされるため、マスターデータベースに障害が発生した場合でもアプリケーションは機能します。
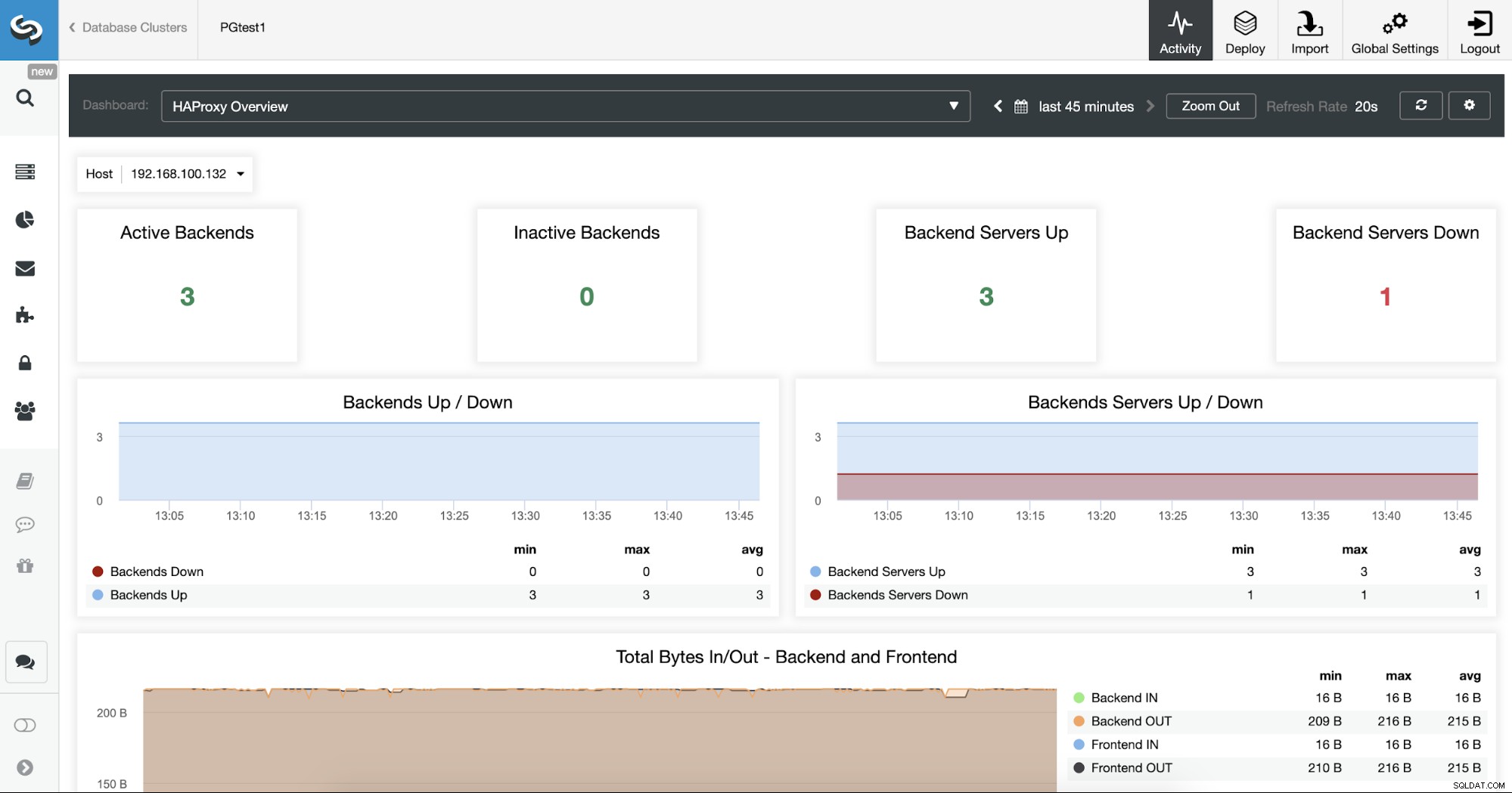
これで、HA設計を改善して新しいHAProxyノードを追加できます。リモートデータセンターとそれらの間のKeepalivedサービスの構成。 Keepalivedを使用すると、アクティブなロードバランサーノードに割り当てられている仮想IPアドレスを使用できます。このノードに障害が発生した場合、この仮想IPはセカンダリHAProxyノードに移行されるため、アプリケーションでこのIPを構成すると、ロードバランサーの問題が発生した場合でもすべてを機能させることができます。
この構成はすべて、ClusterControlを使用して実行できます。
この2部構成のブログをフォローすることで、VPN構成の複雑さを回避するために、高可用性とデータセンター間のSSH接続を備えたPostgreSQLのマルチデータセンターセットアップを実装できます。
リモートノードに非同期レプリケーションを使用すると、遅延とネットワークパフォーマンスに関連する問題を回避でき、ClusterControlを使用すると、(他のいくつかの機能の中でも)障害が発生した場合に自動(または手動)フェイルオーバーが可能になります。これは、このトポロジに到達するための最も簡単な方法である可能性があり、これがあなたにとって役立つことを願っています。