これは、テーブル式に関するシリーズの13番目で最後の記事です。今月は、先月始めたインラインテーブル値関数(iTVF)についての議論を続けます。
先月、SQL Serverが入力として定数を使用してクエリされるiTVFをインライン化すると、デフォルトでパラメーター埋め込みの最適化が適用されることを説明しました。パラメータの埋め込みとは、SQL Serverがクエリ内のパラメータ参照を現在の実行からのリテラル定数値に置き換え、定数を含むコードが最適化されることを意味します。このプロセスにより、より最適なクエリプランを実現できる簡素化が可能になります。今月は、このトピックについて詳しく説明し、定数畳み込み、動的フィルタリング、順序付けなどの単純化の特定のケースについて説明します。パラメータ埋め込みの最適化について復習する必要がある場合は、先月の記事と、Paul Whiteの優れた記事「パラメータのスニッフィング、埋め込み、およびRECOMPILEオプション」を参照してください。
私の例では、TSQLV5というサンプルデータベースを使用します。これを作成してデータを設定するスクリプトはここにあり、そのER図はここにあります。
定数畳み込み
クエリ処理の初期段階で、SQL Serverは定数を含む特定の式を評価し、それらを結果の定数にフォールドします。たとえば、式40 + 2は定数42に折りたたむことができます。折り畳み可能および折り畳み不可能な式の規則は、「定数畳み込みと式の評価」にあります。
iTVFに関して興味深いのは、パラメータ埋め込みの最適化のおかげで、入力として定数を渡すiTVFを含むクエリは、適切な状況で定数畳み込みの恩恵を受けることができるということです。折りたたみ式と折りたたみ不可の式のルールを知っていると、iTVFの実装方法に影響を与える可能性があります。場合によっては、式に非常に微妙な変更を加えることで、インデックスをより有効に活用して、より最適な計画を実現できます。
例として、Sales.MyOrdersと呼ばれるiTVFの次の実装について考えてみます。
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO iTVFに関連する次のクエリを発行します(これをクエリ1と呼びます):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
クエリ1の計画を図1に示します。
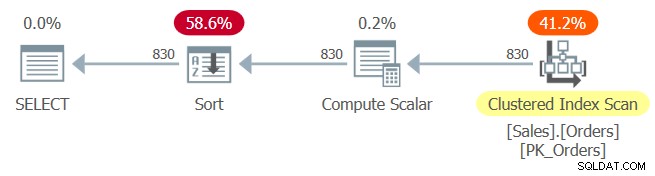 図1:クエリ1の計画
図1:クエリ1の計画
クラスター化されたインデックスPK_Ordersは、orderidをキーとして定義されます。パラメータの埋め込み後に定数畳み込みがここで行われた場合、順序式orderid + 1 –10248はorderid– 10247に折りたたまれます。この式は、orderidに関して順序保持式と見なされ、そのため、インデックスの順序に依存するオプティマイザ。残念ながら、プラン内の明示的な並べ替え演算子から明らかなように、そうではありません。どうしたの?
定数畳み込み規則は厄介です。列1+定数1–定数2の式は、定数畳み込みの目的で左から右に評価されます。最初の部分、column1+constant1は折りたたまれていません。この式を1と呼びましょう。評価される次の部分は、式1 –定数2として扱われ、どちらも折りたたまれていません。折りたたまない場合、column1 + constant1 – constant2の形式の式は、column1に関して順序を保持しているとは見なされないため、column1にサポートインデックスがある場合でも、インデックスの順序に依存することはできません。同様に、式constant1 + column1 –constant2は定数フォールダブルではありません。ただし、式constant1 – constant2+column1は折りたたみ可能です。より具体的には、最初の部分の定数1 –定数2は単一の定数に折りたたまれ(定数3と呼びます)、式constant3+column1になります。この式は、column1に関して順序を保持する式と見なされます。最後の形式を使用して式を記述している限り、オプティマイザがインデックスの順序に依存できるようにすることができます。
次のクエリ(クエリ2、クエリ3、クエリ4と呼びます)を検討し、クエリプランを確認する前に、プランで明示的な並べ替えが含まれるクエリと含まれないクエリを確認してください。
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
次に、図2に示すように、これらのクエリの計画を調べます。
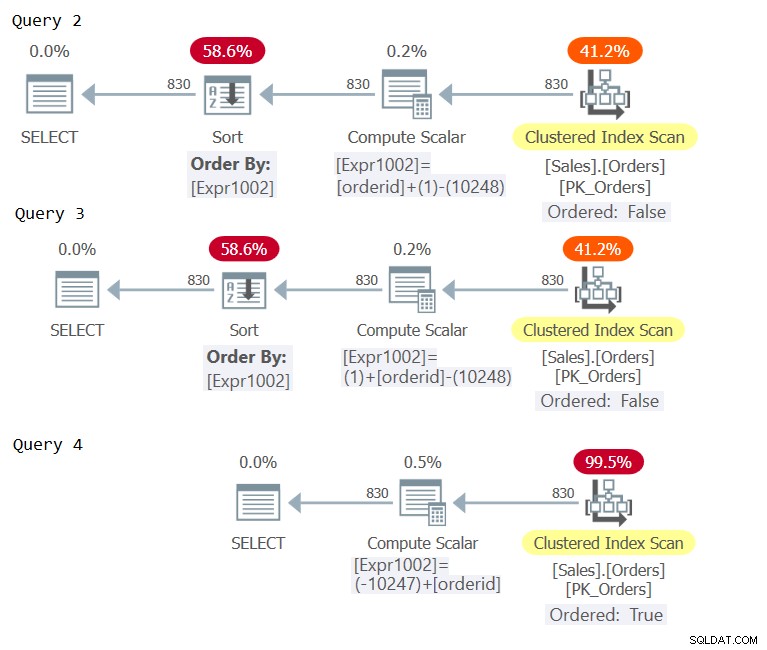 図2:クエリ2、クエリ3、およびクエリ4の計画>
図2:クエリ2、クエリ3、およびクエリ4の計画>
3つの計画のComputeScalar演算子を調べます。クエリ4のプランのみで定数畳み込みが発生し、orderidに関して順序が保持されていると見なされる順序式が生成され、明示的な並べ替えが回避されました。
定数畳み込みのこの側面を理解すると、次のように、式orderid + @add –@subtractを@add– @subtract + orderidに変更することで、iTVFを簡単に修正できます。
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO 関数を再度クエリします(これをクエリ5と呼びます):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
このクエリの計画を図3に示します。
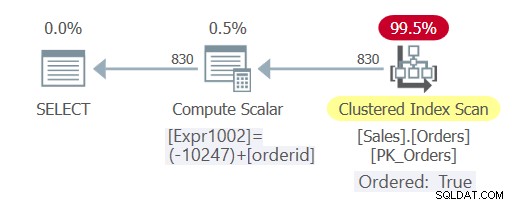 図3:クエリ5の計画
図3:クエリ5の計画
ご覧のとおり、今回はクエリで定数畳み込みが発生し、オプティマイザはインデックスの順序付けに依存して、明示的な並べ替えを回避できました。
この最適化手法を示すために簡単な例を使用したので、少し不自然に思えるかもしれません。この手法の実用的なアプリケーションは、番号シリーズジェネレータチャレンジソリューション–パート1の記事にあります。
動的フィルタリング/順序付け
先月、SQL ServerがiTVFでクエリを最適化する方法と、ストアドプロシージャで同じクエリを最適化する方法の違いについて説明しました。 SQL Serverは通常、入力として定数を使用するiTVFを含むクエリにデフォルトでパラメーター埋め込みの最適化を適用しますが、ストアドプロシージャ内のクエリのパラメーター化された形式を最適化します。ただし、ストアドプロシージャのクエリにOPTION(RECOMPILE)を追加すると、SQL Serverは通常、この場合にもパラメータ埋め込みの最適化を適用します。 iTVFの場合の利点には、クエリに含めることができるという事実が含まれます。繰り返し一定の入力を渡す限り、以前にキャッシュされたプランを再利用できる可能性があります。ストアドプロシージャでは、それをクエリに含めることはできません。また、OPTION(RECOMPILE)を追加してパラメーター埋め込みの最適化を取得する場合、プランを再利用することはできません。ストアドプロシージャを使用すると、使用できるコード要素の柔軟性が大幅に向上します。
これらすべてが、従来のパラメータの埋め込みと順序付けのタスクでどのように機能するかを見てみましょう。以下は、Paulが彼の記事で使用したものと同様の動的フィルタリングと並べ替えを適用する簡略化されたストアドプロシージャです。
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
ストアドプロシージャの現在の実装では、クエリにOPTION(RECOMPILE)が含まれていないことに注意してください。
次のストアドプロシージャの実行を検討してください。
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
この実行の計画を図4に示します。
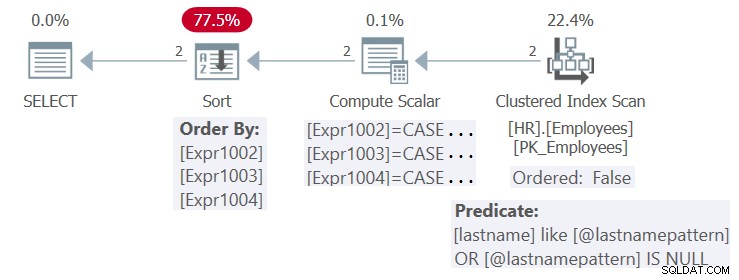 図4:プロシージャHR.GetEmpsPの計画
図4:プロシージャHR.GetEmpsPの計画
姓の列にインデックスが定義されています。理論的には、現在の入力では、インデックスは、クエリのフィルタリング(シークを使用)と順序付け(順序付け:真の範囲スキャンを使用)の両方のニーズに役立つ可能性があります。ただし、デフォルトではSQL Serverはクエリのパラメータ化された形式を最適化し、パラメータの埋め込みを適用しないため、フィルタリングと順序付けの両方の目的でインデックスを利用できるようにするために必要な簡略化は適用されません。したがって、計画は再利用可能ですが、最適ではありません。
パラメータ埋め込みの最適化によって状況がどのように変化するかを確認するには、次のようにOPTION(RECOMPILE)を追加してストアドプロシージャクエリを変更します。
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
以前に使用したのと同じ入力を使用して、ストアドプロシージャを再度実行します。
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
この実行の計画を図5に示します。
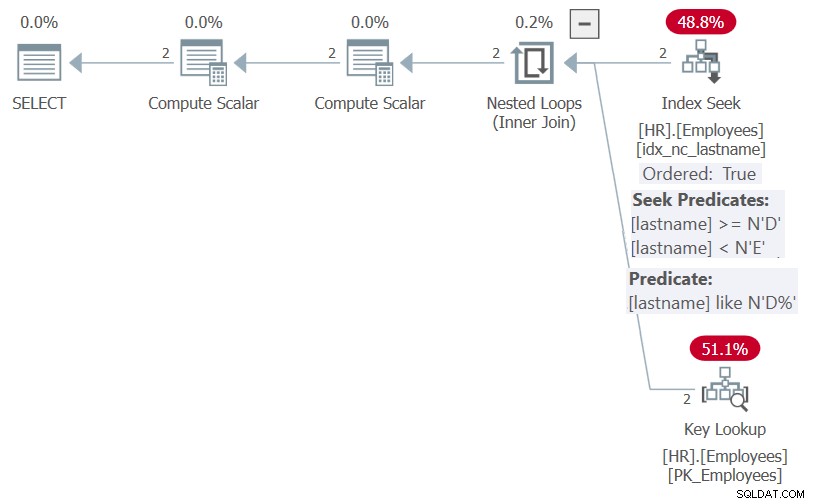 図5:OPTION(RECOMPILE)を使用したプロシージャHR.GetEmpsPの計画>
図5:OPTION(RECOMPILE)を使用したプロシージャHR.GetEmpsPの計画>
ご覧のとおり、パラメーター埋め込みの最適化のおかげで、SQL Serverは、フィルター述語をsargable述語lastname LIKE N'D%'に、順序リストをNULL、NULL、lastnameに単純化することができました。どちらの要素も姓のインデックスの恩恵を受ける可能性があるため、計画ではインデックスにシークが表示され、明示的な並べ替えは表示されません。
理論的には、iTVFでクエリを実装すると、同様の単純化が得られると期待されます。したがって、同様の最適化のメリットがありますが、同じ入力値が再利用されるときにキャッシュされたプランを再利用できます。では、試してみましょう…
iTVFに同じクエリを実装する試みは次のとおりです(このコードはまだ実行しないでください):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO このコードを実行する前に、この実装の問題を確認できますか?このシリーズの最初の方で、テーブル式はテーブルであると説明したことを思い出してください。テーブルの本体は行のセット(またはマルチセット)であるため、順序はありません。したがって、通常、テーブル式として使用されるクエリにORDERBY句を含めることはできません。実際、このコードを実行しようとすると、次のエラーが発生します。
メッセージ1033、レベル15、状態1、プロシージャGetEmps、16行目[バッチ開始行128]ORDER BY句は、TOP、OFFSETを除き、ビュー、インライン関数、派生テーブル、サブクエリ、および一般的なテーブル式では無効です。またはFORXMLも指定されます。
確かに、エラーが示すように、TOPやOFFSET-FETCHなどのフィルタリング要素を使用するとSQL Serverは例外を作成します。これは、フィルターの順序付けの側面を定義するためにORDERBY句に依存します。ただし、この例外のおかげで内部クエリにORDER BY句を含めても、独自のORDER BY句がない限り、テーブル式に対する外部クエリの結果の順序は保証されません。 。
それでもiTVFでクエリを実装する場合は、内部クエリで動的フィルタリング部分を処理できますが、動的順序付けは処理できません。
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
もちろん、次のコードのように、外部クエリに特定の順序付けのニーズを処理させることができます(これをクエリ6と呼びます):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
このクエリの計画を図6に示します。
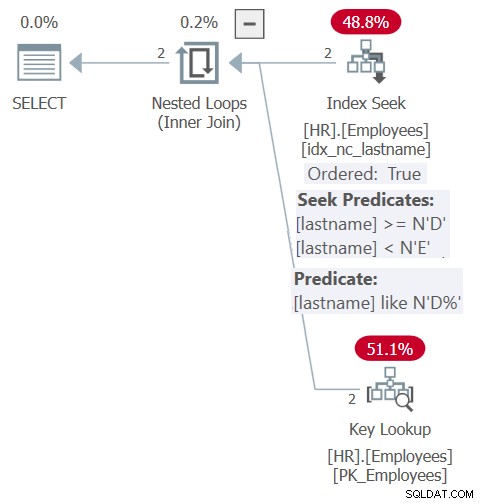 図6:クエリ6の計画
図6:クエリ6の計画
インライン化とパラメーターの埋め込みのおかげで、プランは、図5のストアドプロシージャクエリで前に示したものと似ています。プランは、フィルタリングと順序付けの両方の目的でインデックスに効率的に依存しています。ただし、ストアドプロシージャの場合のように、動的な順序付け入力の柔軟性は得られません。関数に対するクエリのORDERBY句の順序を明示する必要があります。
次の例には、フィルタリングや順序付けの要件がない関数に対するクエリがあります(これをクエリ7と呼びます):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
このクエリの計画を図7に示します。
 図7:クエリ7の計画
図7:クエリ7の計画
インライン化とパラメーターの埋め込みの後、クエリは単純化されてフィルター述語と順序付けがなくなり、クラスター化されたインデックスの完全な順序付けされていないスキャンで最適化されます。
最後に、入力の姓のフィルタリングパターンとしてN'D%'を使用して関数をクエリし、結果を名の列で並べ替えます(これをクエリ8と呼びます):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
このクエリの計画を図8に示します。
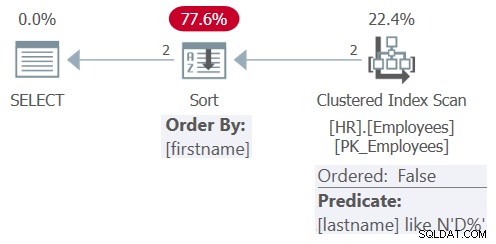 図8:クエリ8の計画
図8:クエリ8の計画
簡略化した後、クエリには、フィルタリング述語lastname LIKE N'D%'と順序付け要素firstnameのみが含まれます。今回、オプティマイザーは、クラスター化された索引の順序付けられていないスキャンを適用することを選択し、残りの述語はLIKE N'D%'であり、その後に明示的なソートが続きます。インデックスがカバーするものではなく、テーブルが非常に小さく、インデックスの順序が現在のクエリの順序のニーズに役立たないため、姓のインデックスにシークを適用しないことを選択しました。また、名の列にはインデックスが定義されていないため、とにかく明示的な並べ替えを適用する必要があります。
結論
iTVFのデフォルトのパラメーター埋め込み最適化により、定数畳み込みが発生し、より最適な計画が可能になります。ただし、式を最適に定式化する方法を決定するには、定数畳み込み規則に注意する必要があります。
iTVFにロジックを実装することには、ストアドプロシージャにロジックを実装することと比較して、長所と短所があります。パラメータ埋め込みの最適化に関心がない場合は、ストアドプロシージャのデフォルトのパラメータ化されたクエリの最適化により、プランのキャッシュと再利用の動作がより最適化される可能性があります。パラメータ埋め込みの最適化に関心がある場合は、通常、デフォルトでiTVFを使用して取得します。ストアドプロシージャでこの最適化を行うには、RECOMPILEクエリオプションを追加する必要がありますが、そうするとプランを再利用できなくなります。少なくともiTVFでは、同じパラメーター値が繰り返されれば、プランを再利用できます。繰り返しになりますが、iTVFで使用できるクエリ要素の柔軟性は低くなります。たとえば、プレゼンテーションのORDERBY句を使用することは許可されていません。
テーブル式に関するシリーズ全体に戻ると、このトピックはデータベースの専門家にとって非常に重要であることがわかりました。より完全なシリーズには、iTVFとして実装されているナンバーシリーズジェネレーターのサブシリーズが含まれます。このシリーズには、合計で次の19のパートが含まれています。
- テーブル式の基礎、パート1
- テーブル式の基礎、パート2 –派生テーブル、論理的な考慮事項
- テーブル式の基礎、パート3 –派生テーブル、最適化の考慮事項
- テーブル式の基礎、パート4 –派生テーブル、最適化の考慮事項、続き
- テーブル式の基礎、パート5 – CTE、論理的な考慮事項
- テーブル式の基礎、パート6 –再帰的CTE
- テーブル式の基礎、パート7 – CTE、最適化の考慮事項
- テーブル式の基礎、パート8 – CTE、最適化の考慮事項の続き
- テーブル式の基礎、パート9 –派生テーブルおよびCTEと比較したビュー
- テーブル式の基礎、パート10 –ビュー、SELECT *、およびDDLの変更
- テーブル式の基礎、パート11 –ビュー、変更に関する考慮事項
- テーブル式の基礎、パート12 –インラインテーブル値関数
- テーブル式の基礎、パート13 –インラインテーブル値関数、続き
- チャレンジが始まりました!最速の数級数ジェネレータを作成するためのコミュニティの呼びかけ
- ナンバーシリーズジェネレータチャレンジソリューション–パート1
- ナンバーシリーズジェネレータチャレンジソリューション–パート2
- ナンバーシリーズジェネレータチャレンジソリューション–パート3
- ナンバーシリーズジェネレータチャレンジソリューション–パート4
- ナンバーシリーズジェネレータチャレンジソリューション–パート5