PostgreSQLのレプリケーションラグの問題は、ほとんどのセットアップで広く見られる問題ではありません。ただし、発生する可能性があり、発生すると本番環境のセットアップに影響を与える可能性があります。 PostgreSQLは、クエリの並列処理やワーカースレッドのデプロイなど、複数のスレッドを処理して、構成で割り当てられた値に基づいて特定のタスクを処理するように設計されています。 PostgreSQLは、重くてストレスの多い負荷を処理するように設計されていますが、(構成が不適切なために)サーバーが南に移動する場合があります。
PostgreSQLでレプリケーションラグを特定することは複雑な作業ではありませんが、問題を調査するためのいくつかの異なるアプローチがあります。このブログでは、PostgreSQLレプリケーションが遅れているときに何を確認するかを見ていきます。
PostgreSQLのレプリケーションの種類
トピックに飛び込む前に、レプリケーションを処理する際のさまざまなアプローチとソリューションのセットとして、PostgreSQLでのレプリケーションがどのように進化するかを最初に見てみましょう。
PostgreSQLのウォームスタンバイはバージョン8.2(2006年に遡る)で実装され、ログ配布方法に基づいていました。これは、WALレコードが1つのデータベースサーバーから別のデータベースサーバーに直接移動されて適用されること、または単にPITRに類似したアプローチ、またはrsyncで行っていることと非常によく似ていることを意味します。
このアプローチは、たとえ古いものであっても、今日でも使用されており、一部の機関は実際にこの古いアプローチを好みます。このアプローチでは、WALレコードを一度に1つのファイル(WALセグメント)に転送することにより、ファイルベースのログ配布を実装します。欠点はありますが、プライマリサーバーでの重大な障害。まだ出荷されていないトランザクションは失われます。データ損失のウィンドウがあります(これは、archive_timeoutパラメーターを使用して調整できます。このパラメーターは数秒に設定できますが、このような低い設定では、ファイルの転送に必要な帯域幅が大幅に増加します)。
PostgreSQLバージョン9.0では、ストリーミングレプリケーションが導入されました。この機能により、ファイルベースのログ配布と比較して、より最新の状態を保つことができました。そのアプローチは、マスターサーバーと1つまたは複数のスタンバイサーバー間で、WALレコード(WALファイルはWALレコードで構成されます)をオンザフライ(単なるレコードベースのログ配布)で転送することです。このプロトコルは、ファイルベースのログ配布とは異なり、WALファイルがいっぱいになるのを待つ必要はありません。実際には、スタンバイサーバーで実行されているWALレシーバーと呼ばれるプロセスは、TCP/IP接続を使用してプライマリサーバーに接続します。プライマリサーバーには、WAL送信者という名前の別のプロセスが存在します。この役割は、WALレジストリが発生したときにスタンバイサーバーに送信することを担当します。
ストリーミングレプリケーションでの非同期レプリケーションの設定では、データ損失やスレーブラグなどの問題が発生する可能性があるため、バージョン9.1では同期レプリケーションが導入されています。同期レプリケーションでは、書き込みトランザクションの各コミットは、コミットがプライマリサーバーとスタンバイサーバーの両方のディスクの先行書き込みログに書き込まれたという確認が受信されるまで待機します。この方法では、データ損失の可能性を最小限に抑えます。その場合、マスターとスタンバイの両方で同時に障害が発生する必要があります。
この構成の明らかな欠点は、すべての関係者が応答するまで待機する必要があるため、各書き込みトランザクションの応答時間が長くなることです。 MySQLとは異なり、MySQLの準同期環境などのサポートはありません。タイムアウトが発生した場合、非同期にフェールバックします。したがって、PostgreSQLの場合、コミットの時間は(少なくとも)プライマリとスタンバイの間のラウンドトリップです。読み取り専用トランザクションはその影響を受けません。
PostgreSQLは進化するにつれて継続的に改善されていますが、その複製は多様です。たとえば、物理ストリーミング非同期レプリケーションを使用したり、論理ストリーミングレプリケーションを使用したりできます。レプリケーションを介してデータを送信するときに同じアプローチを使用しますが、両方とも異なる方法で監視されますが、レプリケーションは引き続きストリーミングされます。詳細については、レプリケーションを処理する際のPostgreSQLのさまざまなタイプのソリューションのマニュアルを確認してください。
PostgreSQLレプリケーションラグの原因
以前のブログで定義されているように、レプリケーションラグは、プライマリ/マスターとスタンバイ/スレーブ間の実行の時間差によって計算されるトランザクションまたは操作の遅延のコストです。ノード。
PostgreSQLはストリーミングレプリケーションを使用しているため、WALレシーバーによってインターセプトされた一連のログレコード(バイトごと)として変更が記録され、これらのログレコードが書き込まれるため、高速に設計されています。 WALファイルに。次に、PostgreSQLによる起動プロセスがそのWALセグメントからのデータを再生し、ストリーミングレプリケーションが開始されます。 PostgreSQLでは、レプリケーションの遅延は次の要因によって発生する可能性があります。
- ビジーノード(プライマリおよびスタンバイ)。外部プロセスまたはリソースを大量に消費する原因となったいくつかの不正なクエリが原因である可能性があります
- 大量のトランザクション要求(または大量の変更)の処理中に設定されるmax_wal_sendersの数が少ないなど、PostgreSQLの構成が不十分です。
PostgreSQLレプリケーションラグで何を探すべきか
PostgreSQLレプリケーションはまだ多様ですが、レプリケーションの状態の監視は微妙ですが複雑ではありません。このアプローチでは、非同期ストリーミングレプリケーションを使用したプライマリスタンバイセットアップに基づいていることを紹介します。論理レプリケーションは、ここで説明しているほとんどの場合にメリットはありませんが、ビューpg_stat_subscriptionは情報の収集に役立ちます。ただし、このブログではこれに焦点を当てません。
pg_stat_replicationビューの使用
最も一般的なアプローチは、プライマリノードでこのビューを参照するクエリを実行することです。このビューを使用してプライマリノードからのみ情報を収集できることを忘れないでください。このビューには、以下に示すように、PostgreSQL11に基づく次のテーブル定義が含まれています。
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | フィールドが(PG <10バージョンを含む)として定義されている場合
- pid :walsenderプロセスのプロセスID
- usesysid :ストリーミングレプリケーションに使用されるユーザーのOID。
- ユーザー名 :ストリーミングレプリケーションに使用されるユーザーの名前
- application_name :マスターに接続されているアプリケーション名
- client_addr :スタンバイ/ストリーミングレプリケーションのアドレス
- client_hostname :スタンバイのホスト名。
- client_port :スタンバイがWAL送信者と通信するTCPポート番号
- backend_start :SRがマスターに接続したときの開始時刻。
- backend_xmin :hot_standby_feedbackによって報告されたスタンバイのxminホライズン。
- 状態 :現在のWAL送信者の状態、つまりストリーミング
- send_lsn / send_location :スタンバイに送信された最後のトランザクションの場所。
- write_lsn / write_location :スタンバイ時にディスクに書き込まれた最後のトランザクション
- flush_lsn / flush_location :スタンバイ時のディスクでの最後のトランザクションフラッシュ。
- replay_lsn / replay_location :スタンバイ時のディスクでの最後のトランザクションフラッシュ。
- write_lag :プライマリからスタンバイへのコミットされたWAL中の経過時間(ただし、スタンバイではまだコミットされていません)
- flush_lag :プライマリからスタンバイへのコミットされたWALの経過時間(WALはすでにフラッシュされていますが、まだ適用されていません)
- replay_lag :プライマリからスタンバイへのコミットされたWAL中の経過時間(スタンバイノードで完全にコミットされた)
- sync_priority :同期スタンバイとして選択されているスタンバイサーバーの優先度
- sync_state :スタンバイの同期状態(非同期か同期か)
サンプルクエリはPostgreSQL9.6では次のようになります
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncこれは基本的に、書き込み、フラッシュ、または適用されたWALセグメント内の場所のブロックを示します。レプリケーションステータスの詳細な見落としを提供します。
スタンバイノードには、これを軽減してクエリにし、スタンバイレプリケーションの状態の概要を提供できる機能がサポートされています。これを行うには、以下のクエリを実行できます(クエリはPGバージョン> 10に基づいています)、
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00古いバージョンでは、次のクエリを使用できます:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06クエリは何を示していますか?関数はここでそれに応じて定義されます
- pg_is_in_recovery ():(ブール値)回復がまだ進行中の場合はtrue。
- pg_last_wal_receive_lsn ()/ pg_last_xlog_receive_location():(pg_lsn)ストリーミングレプリケーションによって受信され、ディスクに同期された先行書き込みログの場所。
- pg_last_wal_replay_lsn ()/ pg_last_xlog_replay_location():(pg_lsn)リカバリ中に再生された最後の先行書き込みログの場所。回復がまだ進行中の場合、これは単調に増加します。
- pg_last_xact_replay_timestamp ():(タイムゾーン付きのタイムスタンプ)リカバリ中に再生された最後のトランザクションのタイムスタンプを取得します。
いくつかの基本的な数学を使用して、これらの関数を組み合わせることができます。 DBAが使用する最も一般的に使用される関数は次のとおりです。
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;このクエリは実際に使用されており、DBAによって使用されています。それでも、ラグの正確なビューは提供されません。なんで?これについては次のセクションで説明しましょう。
WALセグメントの不在によって引き起こされたラグの特定
リカバリモードのPostgreSQLスタンバイノードは、レプリケーションで起こっていることの正確な状態を報告しません。 PGログを表示しない限り、何が起こっているかに関する情報を収集できます。これを決定するために実行できるクエリはありません。ほとんどの場合、組織や小規模な機関でさえ、アラームが発生したときにアラートを受け取ることができるサードパーティのソフトウェアを考え出します。
これらの1つはClusterControlです。これは、可観測性を提供し、アラームが発生したときにアラートを送信したり、災害や大災害が発生した場合にノードを回復したりします。このシナリオを考えてみましょう。プライマリスタンバイの非同期ストリーミングレプリケーションクラスターが失敗しました。何かがおかしいのかどうかどうやってわかりますか?以下を組み合わせてみましょう:
ステップ1:ラグがあるかどうかを判断する
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0ステップ2:プライマリから受信したWALセグメントを特定し、スタンバイノードと比較します
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70古いバージョンのPG<10の場合は、pg_current_xlog_locationを使用します。
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00ステップ3:それがどれほど悪いかを判断する
では、ステップ#1とステップ#2の式を混ぜ合わせて、差分を取得しましょう。これを行う方法として、PostgreSQLにはpg_wal_lsn_diffという関数があります。これは
として定義されています。pg_wal_lsn_diff(lsn pg_lsn、lsn pg_lsn)/ pg_xlog_location_diff(location pg_lsn、location pg_lsn):(数値)2つの先行書き込みログの場所の差を計算します
では、これを使用してラグを決定しましょう。静的な値を提供するだけなので、どのPGノードでも実行できます:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 18009131041800913104の金額を見積もりましょう。これは、スタンバイノードに約1.6GiBが存在しなかった可能性があると思われます。
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68最後に、続行するか、クエリの前に、tail -5fを使用してログを確認し、何が起こっているかを確認することができます。これは、プライマリノードとスタンバイノードの両方に対して行います。この例では、問題があることがわかります。
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...この問題が発生した場合は、スタンバイノードを再構築することをお勧めします。 ClusterControlでは、ワンクリックで簡単に実行できます。 [ノード/トポロジ]セクションに移動し、次のようにノードを再構築します。
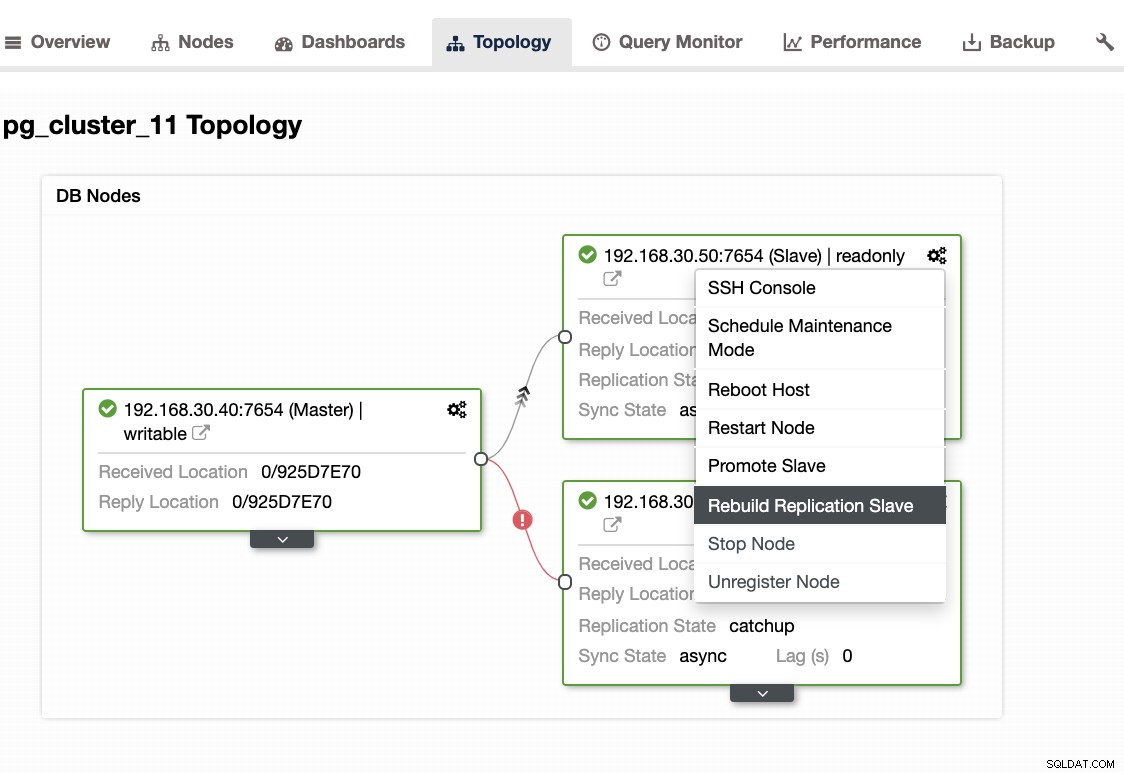
ps、top、iostat、netstatの組み合わせなどのシステムツールを使用して、以前のブログ(MySQL)と同じアプローチを使用できます。たとえば、スタンバイノードから現在回復されているWALセグメントを取得することもできます。
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027ClusterControlはどのように役立ちますか?
ClusterControlは、プライマリノードからスレーブノードまでデータベースノードを監視する効率的な方法を提供します。 [概要]タブに移動すると、レプリケーションの状態がすでに表示されています。
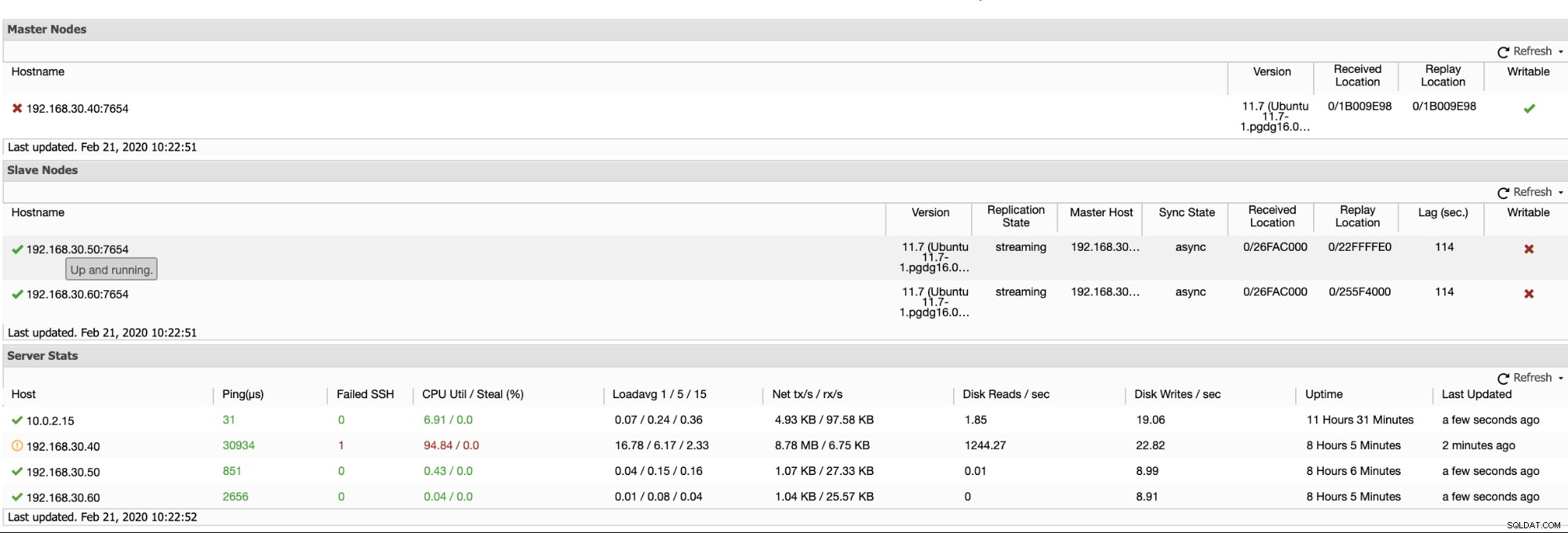
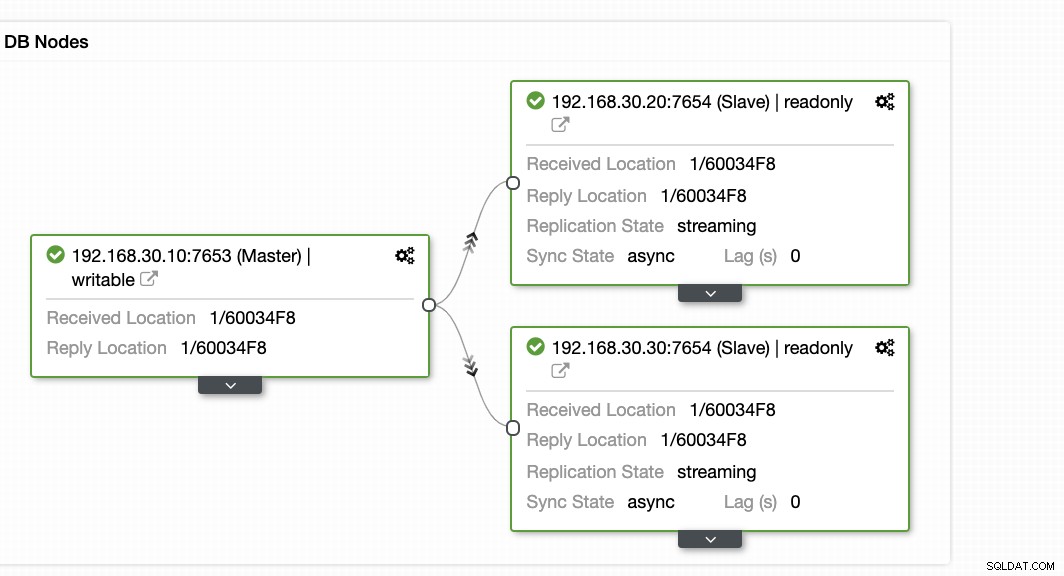
基本的に、上記の2つのスクリーンショットは、レプリケーションの状態と現在の状態を示しています。 WALセグメント。それはまったくありません。 ClusterControlは、クラスターで起こっていることの現在のアクティビティも表示します。
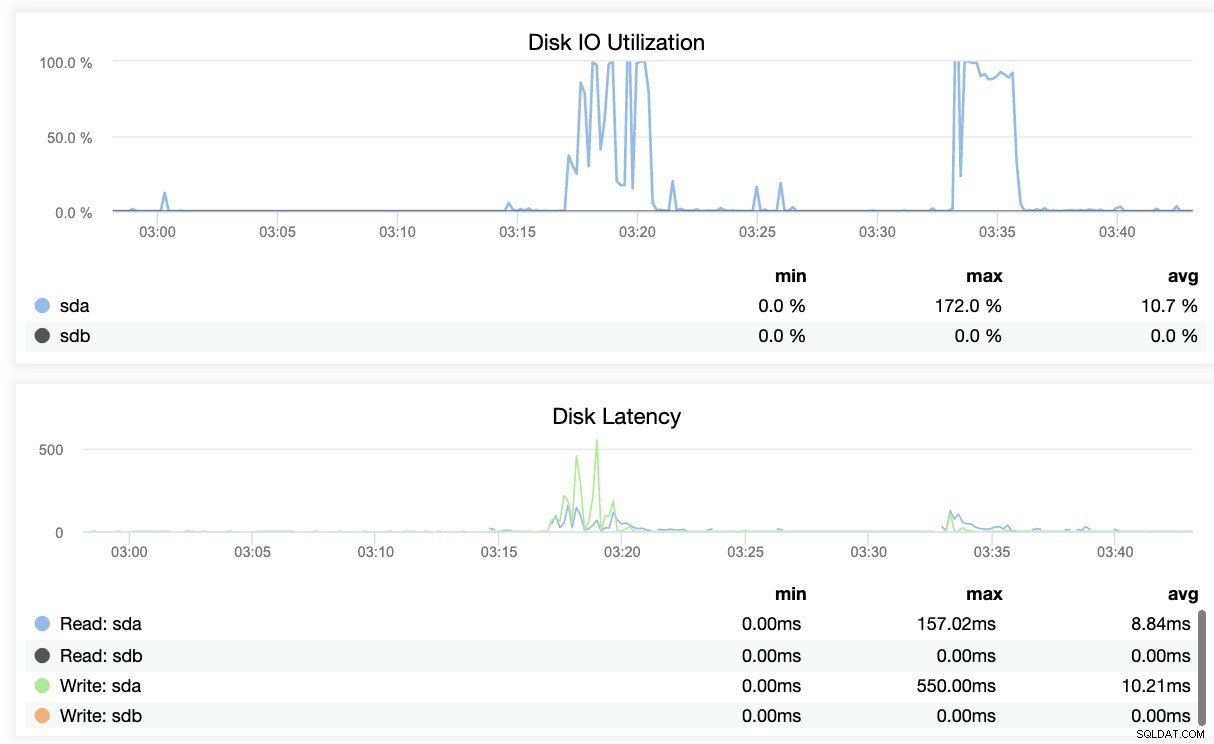
PostgreSQLでレプリケーションの状態を監視することは、ニーズを満たすことができる限り、別のアプローチで終わる可能性があります。災害が発生した場合に通知できる可観測性を備えたサードパーティのツールを使用することは、オープンソースであろうと企業であろうと、完璧なルートです。最も重要なことは、そのようなトラブルに先立って、ディザスタリカバリ計画とビジネス継続性を計画していることです。