フェイルオーバーとは、何らかの障害が発生した場合でもシステムが機能し続ける機能です。これは、プライマリコンポーネントに障害が発生した場合、または必要になった場合に、システムの機能がセカンダリコンポーネントによって引き継がれることを示しています。したがって、PostgreSQLマルチクラウド環境に変換すると、プライマリクラウドプロバイダーでプライマリノードに障害が発生した場合(または次のセクションで説明する別の理由)、スタンバイノードを昇格できる必要があります。システムを実行し続けるためにセカンダリにあります。
通常、すべてのクラウドプロバイダーは、同じクラウドプロバイダーでフェイルオーバーオプションを提供しますが、別の異なるクラウドプロバイダーにフェイルオーバーする必要がある場合もあります。もちろん、手動で行うこともできますが、自動フェイルオーバーやスレーブアクションのプロモートなどのClusterControl機能の一部を使用して、これをフレンドリーで簡単な方法で行うこともできます。
このブログでは、フェイルオーバーが必要な理由、手動でフェイルオーバーを実行する方法、およびこのタスクにClusterControlを使用する方法について説明します。 ClusterControlがインストールされており、データベースクラスターが2つの異なるクラウドプロバイダーで作成されていることを前提としています。
フェイルオーバーは何に使用されますか?
プライマリノードがダウンしている場合、またはメインのクラウドプロバイダーに問題がある場合でも、システムの可用性を確保するためにフェイルオーバーする必要があります。この場合、ダウンタイムを減らすために、これを自動的に行う方法が必要になる可能性があります。
ダウンタイムを最小限に抑えてシステムをあるクラウドプロバイダーから別のクラウドプロバイダーに移行する場合は、フェイルオーバーを使用できます。セカンダリクラウドプロバイダーでレプリカを作成できます。同期したら、システムを停止し、レプリカをプロモートしてフェイルオーバーしてから、システムをセカンダリクラウドプロバイダーの新しいプライマリノードにポイントする必要があります。
PostgreSQLプライマリノードでメンテナンスタスクを実行する必要がある場合は、レプリカをプロモートし、タスクを実行して、古いプライマリをスタンバイノードとして再構築できます。
この後、古いプライマリをプロモートし、スタンバイノードで再構築プロセスを繰り返して初期状態に戻すことができます。
このようにして、メンテナンスタスクの実行中にオフラインになったり、情報を失ったりするリスクを冒すことなく、サーバーで作業できます。
PostgreSQLのバージョンをアップグレードすることも(PostgreSQL 10以降)、他のエンジンで実行できるように、ダウンタイムがゼロの論理レプリケーションを使用してオペレーティングシステムをアップグレードすることもできます。
手順は、新しいクラウドプロバイダーに移行する場合と同じですが、レプリカが新しいPostgreSQLまたはOSバージョンになり、ストリーミングを使用できないため、論理レプリケーションを使用する必要があります。異なるバージョン間の複製。
フェイルオーバーは、データベースだけでなく、アプリケーションにも関係します。彼らはどのデータベースに接続するかをどうやって知るのですか?アプリケーションを変更する必要はないでしょう。これはダウンタイムを延長するだけなので、プライマリノードがダウンしたときに、プロモートされたサーバーを自動的に指すようにロードバランサーを構成できます。
単一のロードバランサーインスタンスを持つことは、単一障害点になる可能性があるため、最善のオプションではありません。したがって、Keepalivedなどのサービスを使用して、ロードバランサーのフェイルオーバーを実装することもできます。このように、プライマリロードバランサーに問題がある場合、Keepalivedは仮想IPをセカンダリロードバランサーに移行し、すべてが透過的に機能し続けます。
もう1つのオプションは、DNSの使用です。セカンダリクラウドプロバイダーでスタンバイノードをプロモートすることにより、プライマリノードを指すホスト名IPアドレスを直接変更します。このようにして、アプリケーションを変更する必要がなくなります。自動的に変更することはできませんが、ロードバランサーを実装したくない場合の代替手段です。
手動フェイルオーバーを実行する前に、レプリケーションステータスを確認する必要があります。フェイルオーバーが必要な場合、ネットワーク障害、高負荷、またはその他の問題が原因でスタンバイノードが最新ではない可能性があるため、スタンバイノードにすべて(またはほぼすべて)情報。複数のスタンバイノードがある場合は、どのノードが最も高度なノードであるかを確認し、フェイルオーバーするノードを選択する必要があります。
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)新しいプライマリノードを選択するときは、最初にpg_lsclustersコマンドを実行してクラスター情報を取得できます。
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.log次に、プロモートアクションを指定してpg_ctlclusterコマンドを実行する必要があります。
$ pg_ctlcluster 12 main promote前のコマンドの代わりに、次の方法でpg_ctlコマンドを実行できます。
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promoted次に、スタンバイノードがプライマリに昇格し、新しいプライマリノードで次のクエリを実行して検証できます。
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)結果が「f」の場合、それは新しいプライマリノードです。
ここで、アプリケーション、ロードバランサー、DNS、または使用している実装のプライマリデータベースのIPアドレスを変更する必要があります。これを手動で変更すると、ダウンタイムが増加します。また、可能性のあるプロバイダー間の接続が正しく機能していること、アプリケーションが新しいプライマリノードにアクセスできること、アプリケーションユーザーが別のクラウドプロバイダーからアクセスする権限を持っていること、およびスタンバイノードを再構築する必要があることを確認する必要があります。リモートまたはローカルクラウドプロバイダーでさえ、新しいプライマリから複製します。そうしないと、必要に応じて新しいフェイルオーバーオプションがありません。
ClusterControlを使用してPostgreSQLをフェイルオーバーする方法
ClusterControlには、PostgreSQLレプリケーションと自動フェイルオーバーに関連する多くの機能があります。 ClusterControlサーバーがインストールされており、Multi-CloudPostgreSQL環境を管理していることを前提としています。
ClusterControlを使用すると、ネットワークIPの制限なしに、必要な数のスタンバイノードまたはロードバランサーノードを追加できます。これは、スタンバイノードが同じプライマリノードネットワークにある必要はなく、同じクラウドプロバイダーにある必要もないことを意味します。フェイルオーバーに関しては、ClusterControlを使用すると手動または自動でフェイルオーバーを実行できます。
手動フェイルオーバーを実行するには、ClusterControl-> Select Cluster-> Nodesに移動し、いずれかのスタンバイノードのノードアクションで、[PromoteSlave]を選択します。
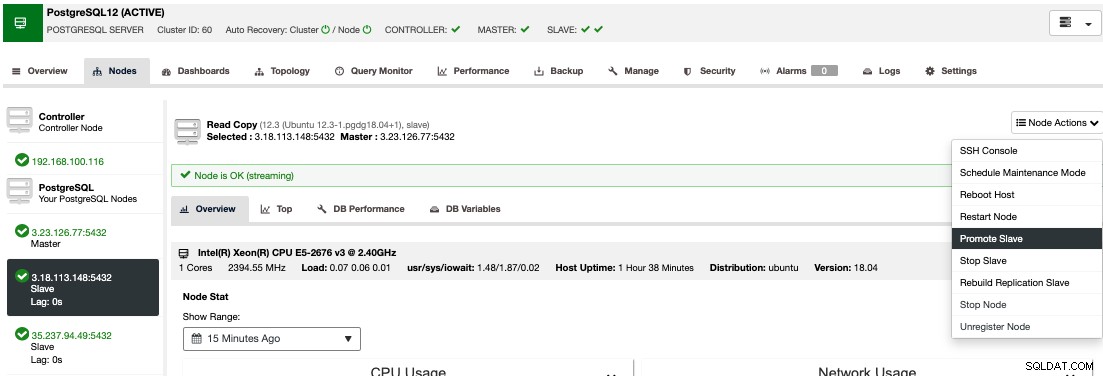
このようにして、数秒後にスタンバイノードがプライマリになります。以前はプライマリでしたが、スタンバイになりました。したがって、レプリカが別のクラウドプロバイダーにあった場合、新しいプライマリノードがそこにあり、稼働しています。
自動フェイルオーバーの場合、ClusterControlはプライマリノードの障害を検出し、最新のデータを新しいプライマリとして使用してスタンバイノードをプロモートします。また、残りのスタンバイノードでも機能して、この新しいプライマリから複製します。

「自動回復」オプションをオンにすると、ClusterControlは次のように自動フェイルオーバーを実行します。問題を通知するだけでなく。このようにして、システムは数秒で、介入なしで回復できます。
ClusterControlを使用すると、ホワイトリスト/ブラックリストを構成して、主要な候補を決定するときにサーバーをどのように考慮するか(または考慮しないか)を定義できます。
ClusterControlは、フェイルオーバープロセスに対していくつかのチェックも実行します。たとえば、デフォルトでは、障害が発生した古いプライマリノードを回復できた場合、プライマリノードとしてもクラスターとしても自動的にクラスターに再導入されません。スタンバイとして、手動で行う必要があります。これにより、障害時にスタンバイ(プロモートした)が遅延した場合のデータ損失や不整合の可能性を回避できます。問題を詳細に分析することもできますが、クラスターに追加すると、診断情報が失われる可能性があります。
前述したように、ロードバランサーは、特にデータベーストポロジで自動フェイルオーバーを使用する場合に、フェイルオーバーを検討するための重要なツールです。
フェイルオーバーをユーザーとアプリケーションの両方に対して透過的にするには、新しいプライマリノードを昇格させるだけでは不十分なため、間にコンポーネントが必要です。このために、HAProxy+Keepalivedを使用できます。
ClusterControlを使用してこのソリューションを実装するには、PostgreSQLクラスターで[クラスターアクション]->[ロードバランサーの追加]->[HAProxy]に移動します。ロードバランサーにフェイルオーバーを実装する場合は、少なくとも2つのHAProxyインスタンスを構成してから、Keepalivedを構成できます([クラスターアクション]->[ロードバランサーの追加]->[Keepalived])。この実装の詳細については、このブログ投稿を参照してください。
この後、次のトポロジになります。

HAProxyは、デフォルトで2つの異なるポート(1つは読み取り/書き込み)と1つは読み取り専用です。
読み取り/書き込みポートでは、プライマリノードがオンラインで、残りのノードがオフラインになっています。読み取り専用ポートでは、プライマリノードとスタンバイノードの両方がオンラインになっています。このようにして、ノード間の読み取りトラフィックのバランスをとることができます。書き込み時には、現在のプライマリノードを指す読み取り/書き込みポートが使用されます。

HAProxyが、プライマリまたはスタンバイのいずれかのノードがアクセスできない場合は、自動的にオフラインとしてマークされます。 HAProxyはそれにトラフィックを送信しません。このチェックは、デプロイメント時にClusterControlによって構成されたヘルスチェックスクリプトによって実行されます。これらは、インスタンスが稼働しているかどうか、回復中かどうか、または読み取り専用かどうかを確認します。
ClusterControlが新しいプライマリノードをプロモートすると、HAProxyは古いノードをオフラインとしてマークし(両方のポートに対して)、プロモートされたノードを読み取り/書き込みポートでオンラインにします。このようにして、システムは引き続き正常に動作します。
アクティブなHAProxy(システムが接続する仮想IPアドレスを割り当てている)に障害が発生した場合、Keepalivedはこの仮想IPをパッシブなHAProxyに自動的に移行します。これは、システムが正常に機能し続けることができることを意味します。
マルチクラウド環境を構築するには、PostgreSQLクラスターに対してClusterControl Add Slaveアクションを使用できますが、クラスター間レプリケーション機能も使用できます。現時点では、この機能にはPostgreSQLの制限があり、リモートノードを1つだけ持つことができますが、将来のリリースでその制限をすぐに削除するよう取り組んでいます。
デプロイするには、このブログ投稿の「クラウドでのクラスター間レプリケーション」セクションを確認してください。

配置されている場合、生成されるリモートクラスターをプロモートできますプライマリノードがセカンダリクラウドプロバイダーで実行されている独立したPostgreSQLクラスター。

したがって、必要な場合は、同じクラスターを実行しますわずか数秒で新しいクラウドプロバイダーに。
ダウンタイムをできるだけ少なくしたい場合は、自動フェイルオーバープロセスを用意する必要があります。また、HAProxyやKeepalivedなどのさまざまなテクノロジーを使用すると、このフェイルオーバーが改善されます。
上記のClusterControl機能を使用すると、さまざまなクラウドプロバイダー間ですばやくフェイルオーバーし、簡単で使いやすい方法でセットアップを管理できます。
異なるクラウドプロバイダー間でフェイルオーバープロセスを実行する前に考慮すべき最も重要なことは、接続性です。フェイルオーバーの場合は、メインクラウドプロバイダーとセカンダリクラウドプロバイダーを使用して、アプリケーションまたはデータベース接続が通常どおり機能することを確認する必要があります。また、セキュリティ上の理由から、既知のソースからのトラフィックのみを制限する必要があります。つまり、クラウド間のみを制限する必要があります。プロバイダーであり、外部ソースからの許可は許可されていません。