製品ID421の履歴テーブルトランザクションIDを返す次のAdventureWorksクエリについて考えてみます。
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
クエリオプティマイザは、SQL Sentry Plan Explorerに示されているように、カーディナリティ(行数)の見積もりが正確に正しい効率的な実行プランをすばやく見つけます。

ここで、「MetalPlate2」という名前のAdventureWorks製品の履歴トランザクションIDを検索するとします。このクエリをT-SQLで表現する方法はたくさんあります。自然な定式化の1つは次のとおりです。
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); 実行計画は次のとおりです。
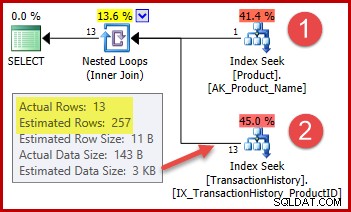
戦略は次のとおりです。
- 指定された名前からProductテーブルで製品IDを検索します
- 履歴テーブルでその製品IDの行を見つけます
使用されるインデックスは一意であると宣言されており、製品名のみに基づいているため、ステップ1の推定行数は正確に正しいです。したがって、「Metal Plate 2」の同等性テストでは、正確に1行(存在しない製品名を指定した場合は0行)が返されることが保証されます。
ステップ2で強調表示されている257行の見積もりは、精度が低くなります。実際に検出されるのは13行のみです。この不一致は、オプティマイザが「メタルプレート2」という名前の製品に関連付けられている特定の製品IDを認識していないために発生します。値を不明として扱い、平均密度情報を使用してカーディナリティ推定値を生成します。計算では、以下に示す統計オブジェクトの要素を使用します。
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
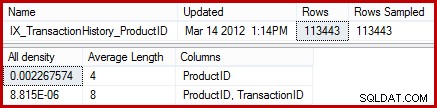
統計によると、テーブルには441の一意の製品ID(1 / 0.002267574 =441)を持つ113443行が含まれています。製品ID全体の行の分布が均一であると仮定すると、カーディナリティ推定では、製品IDが平均して(113443/441)=257.24行に一致すると予想されます。結局のところ、分布は特に均一ではありません。 「MetalPlate2」製品は13列しかありません。
傍白
257行の見積もりの方が正確であると考えているかもしれません。たとえば、製品IDと名前の両方が一意になるように制約されている場合、SQLServerはこの1対1の関係に関する情報を自動的に維持できます。次に、「MetalPlate2」が製品ID479に関連付けられていることがわかり、その洞察を使用して、ProductIDヒストグラムを使用してより正確な見積もりを生成します。
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
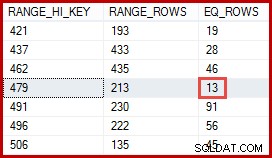
この方法で導き出された13行の見積もりは、正確に正しいはずです。それにもかかわらず、利用可能な統計情報と、今日のカーディナリティ推定によって適用される通常の単純化の仮定(一様分布など)を考えると、257行の推定は不合理なものではありませんでした。正確な見積もりは常に良いですが、「合理的な」見積もりも完全に受け入れられます。
2つのクエリの組み合わせ
製品IDが421またはであるすべてのトランザクション履歴IDを表示したいとします。 商品名は「メタルプレート2」。前の2つのクエリを組み合わせる自然な方法は次のとおりです。
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); 実行プランはもう少し複雑になりましたが、それでも単一述語プランの認識可能な要素が含まれています:
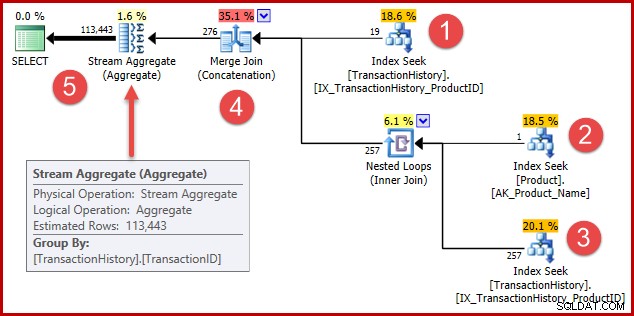
戦略は次のとおりです。
- 製品421の履歴レコードを検索する
- 「MetalPlate2」という名前の製品の製品IDを検索します
- 手順2で見つかった製品IDの履歴レコードを検索します
- 手順1と3の行を組み合わせる
- 重複を削除します(製品421は「MetalPlate2」という名前の製品でもある可能性があるため)
手順1〜3は、前とまったく同じです。同じ理由で同じ見積もりが生成されます。ステップ4は新しいものですが、非常に単純です。予想される19行と予想される257行を連結して、276行の見積もりを出します。
ステップ5は興味深いものです。重複を削除するStreamAggregateの推定入力は276行、推定出力は113443行です。受信するよりも多くの行を出力する集計は不可能に思えますよね?
* 2014年より前のカーディナリティ推定モデルを使用している場合は、ここに102099行の推定値が表示されます。
カーディナリティ推定のバグ
この例で不可能なStreamAggregate推定は、カーディナリティ推定のバグが原因です。これは興味深い例なので、もう少し詳しく見ていきます。
サブクエリの削除
SQLServerクエリオプティマイザがサブクエリを直接処理しないことを知って驚かれるかもしれません。これらは、コンパイルプロセスの早い段階で論理クエリツリーから削除され、オプティマイザが機能するように設定されている同等の構造に置き換えられます。オプティマイザには、サブクエリを削除するいくつかのルールがあります。これらは、次のクエリを使用して名前で一覧表示できます(参照されるDMVは最小限に文書化されていますが、サポートされていません):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
結果(SQL Server 2014の場合):
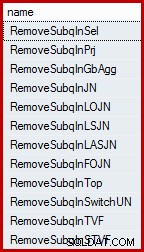
結合されたテストクエリには、履歴テーブルに2つの述語(関係用語での「選択」)があり、ORで接続されています。 。これらの述語の1つには、サブクエリが含まれています。サブツリー全体(述語とサブクエリの両方)は、リストの最初のルール(「選択中のサブクエリの削除」)によって、個々の述語の和集合を介した半結合に変換されます。この内部変換の結果をT-SQL構文を使用して正確に表すことはできませんが、次のようになります。
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); サブクエリを削除した後の内部ツリーのT-SQL近似にサブクエリが含まれているのは少し残念ですが、クエリプロセッサの言語では含まれていません(半結合です)。 T-SQLに相当するものを試すのではなく、生の内部フォームを表示したい場合は、すぐに実行されることを確認してください。
上記のT-SQLに含まれている文書化されていないクエリのヒントは、実行プラン形式で変換されたロジックを確認したい人のために、その後の変換を防ぐためのものです。以下の注釈は、変換後の2つの述語の位置を示しています。
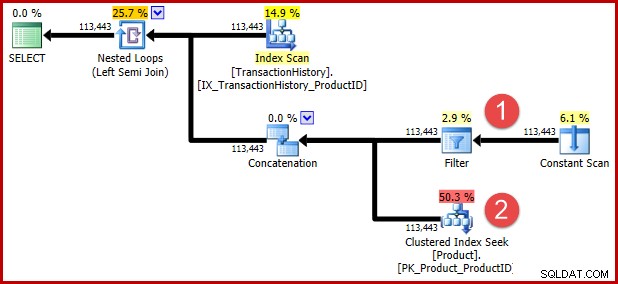
変換の背後にある直感は、いずれかの述語が満たされている場合、履歴行が適格であるということです。おおよそのT-SQLと実行プランの図がどれほど役立つかに関わらず、書き直しが元のクエリと同じ要件を表現していることが少なくとも合理的に明らかであることを願っています。
オプティマイザーは、文字通り代替T-SQL構文を生成したり、中間段階で完全な実行プランを生成したりしないことを強調する必要があります。上記のT-SQLと実行プランの表現は、純粋に理解を助けることを目的としています。生の詳細に興味がある場合は、変換されたクエリツリーの約束された内部表現(明確さ/スペースのために少し編集されています)は次のとおりです。
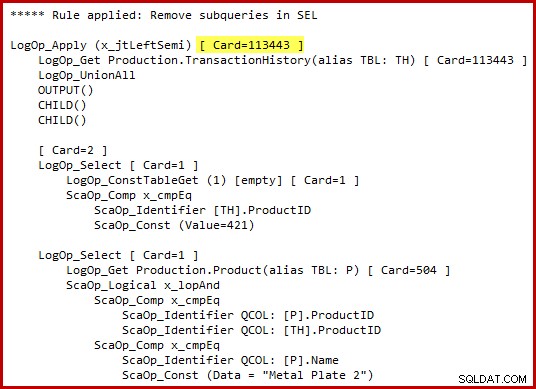
強調表示された適用セミジョインカーディナリティ推定に注意してください。 2014カーディナリティ推定器を使用する場合は113443行です(古いCEを使用する場合は102099行)。 AdventureWorks履歴テーブルには合計113443行が含まれているため、これは100%の選択性(古いCEでは90%)を表すことに注意してください。
これらの述語のいずれかを単独で適用すると、一致する数が少なくなることを以前に見ました。製品ID 421の場合は19行、「金属プレート2」の場合は13行(推定257)です。論理和(OR)を推定する 2つの述語のうち、ベーステーブルのすべての行が返されます。
バグの詳細
半結合の選択性計算の詳細は、SQL Server 2014で、(文書化されていない)トレースフラグ2363で新しいカーディナリティ推定器を使用した場合にのみ表示されます。拡張イベントと同様の結果が表示される可能性がありますが、トレースフラグの出力の方が便利です。ここで使用します。出力の関連セクションを以下に示します。
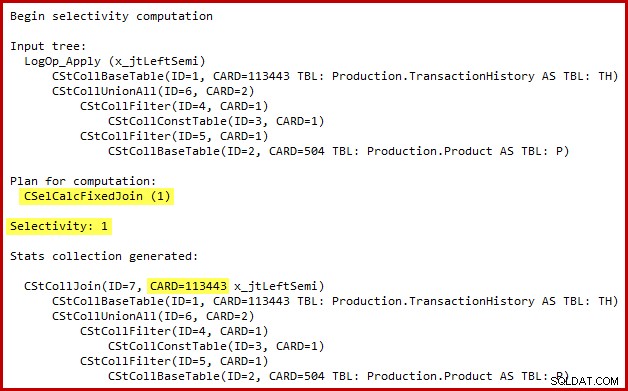
カーディナリティ推定器は、100%の選択性を持つ固定結合計算機を使用します。結果として、セミジョインの推定出力カーディナリティはその入力と同じです。つまり、履歴テーブルの113443行すべてが適格であると予想されます。
バグの正確な性質は、半結合選択性の計算で、入力ツリー内のすべての和集合を超えて配置された述語が欠落していることです。次の図では、半結合自体に述語がないことは、すべての行が適格であることを意味すると解釈されます。連結の下の述語の影響を無視します(すべてを結合します)。
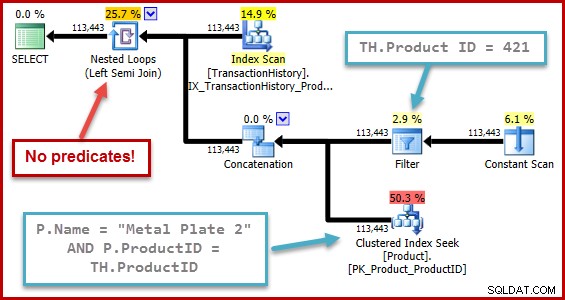
オプティマイザーがそれ自体で生成したツリー表現で選択性の計算が機能していることを考えると、この動作はさらに驚くべきものです(ツリーの形状と述語の配置は、サブクエリを削除した結果です)。
2014年以前のカーディナリティ推定量でも同様の問題が発生しますが、最終的な推定値は、推定されたセミジョイン入力の90%に固定されます(逆に固定された10%の述語推定値に関連する面白い理由により、取得するにはあまりにも多くの迂回が必要です)に)。
例
上記のように、このバグは、すべての和集合を超えて配置された関連する述語を使用して半結合に対して推定が実行された場合に発生します。この内部配置がクエリ最適化中に発生するかどうかは、元のT-SQL構文と内部最適化操作の正確なシーケンスによって異なります。次の例は、バグが発生する場合と発生しない場合を示しています。
例1
この最初の例では、テストクエリに簡単な変更を加えています。
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); 推定実行計画は次のとおりです。
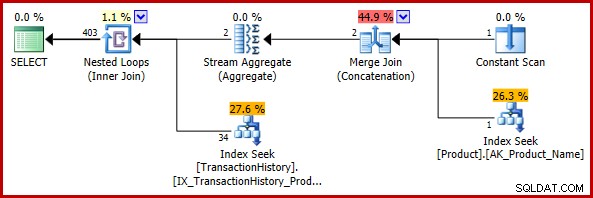
403行の最終的な見積もりは、ネストされたループ結合の入力見積もりと矛盾しますが、それでも妥当なものです(前述の意味で)。バグが発生した場合、最終的な見積もりは113443行(または2014年以前のCEモデルを使用した場合は102099行)になります。
例2
このバグを回避するために、すべての定数比較を急いで簡単なサブクエリとして書き直そうとした場合は、別の簡単な変更を行った場合にどうなるかを見てください。今回は、2番目の述語の等価性テストをINに置き換えます。クエリの意味は変わりません:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); バグが返されます:
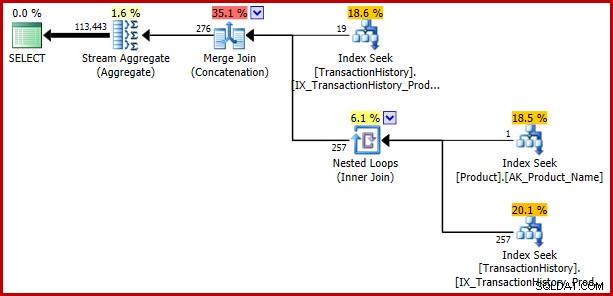
例3
この記事はこれまでサブクエリを含む分離述語に焦点を当ててきましたが、次の例は、EXISTSとUNIONALLを使用して表現された同じクエリ仕様も脆弱であることを示しています。
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); 実行計画:
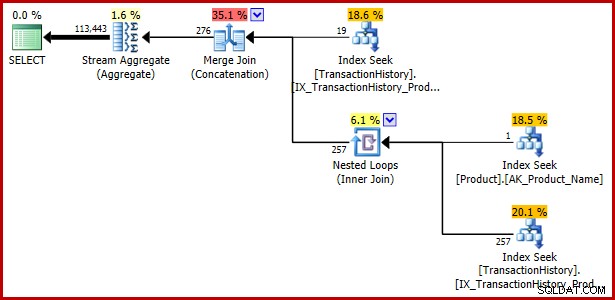
例4
T-SQLで同じ論理クエリを表現する方法は他に2つあります。
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; どちらのクエリもバグに遭遇せず、どちらも同じ実行プランを生成します:
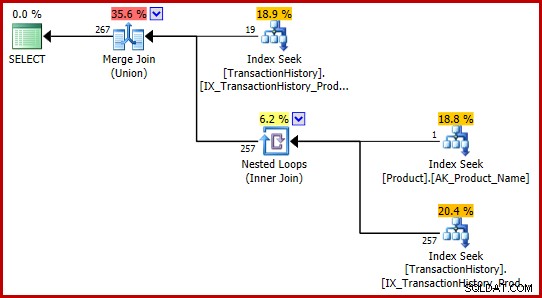
これらのT-SQLの定式化により、完全に一貫した(そして合理的な)見積もりを備えた実行プランが作成されます。
例5
不正確な見積もりが重要かどうか疑問に思われるかもしれません。これまでに提示されたケースでは、少なくとも直接ではありません。より大きなクエリでバグが発生すると問題が発生し、誤った見積もりが他の場所でのオプティマイザの決定に影響します。最小限に拡張された例として、テストクエリの結果をランダムな順序で返すことを検討してください。
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New 実行プランは、誤った見積もりが後の操作に影響することを示しています。たとえば、これはソート用に予約されたメモリ許可の基礎です:
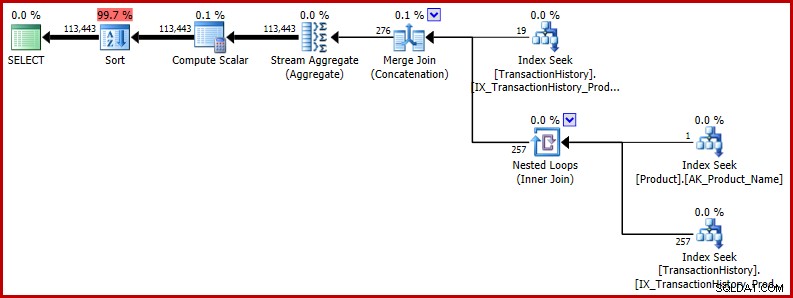
このバグの潜在的な影響のより現実的な例を確認したい場合は、SQLPerformance.comのQ&Aサイトanswers.SQLPerformance.comのRichardMansellからのこの最近の質問をご覧ください。
まとめと最終的な考え
このバグは、特定の状況で、オプティマイザーがセミジョインのカーディナリティ推定を実行したときにトリガーされます。いくつかの理由から、発見して回避するのは難しいバグです。
- 半結合を指定する明示的なT-SQL構文がないため、特定のクエリがこのバグに対して脆弱であるかどうかを事前に知ることは困難です。
- オプティマイザはさまざまな状況でセミジョインを導入できますが、そのすべてが明らかなセミジョインの候補であるとは限りません。
- 問題のある半結合は、後のオプティマイザアクティビティによって別の何かに変換されることが多いため、最終的な実行プランに半結合操作があることに依存することさえできません。
- すべての奇妙に見えるカーディナリティ推定がこのバグによって引き起こされるわけではありません。実際、このタイプの多くの例は、通常のオプティマイザー操作の予想される無害な副作用です。
- 誤った半結合選択性の推定値は、常に入力の90%または100%になりますが、これは通常、計画で使用されるテーブルのカーディナリティに対応しません。さらに、計算で使用されるセミジョイン入力カーディナリティは、最終的な実行プランでも表示されない場合があります。
- 通常、T-SQLで同じ論理クエリを表現する方法はたくさんあります。これらのいくつかはバグを引き起こしますが、他は引き起こしません。
これらの考慮事項により、このバグを見つけたり回避したりするための実用的なアドバイスを提供することは困難です。 「とんでもない」見積もりの実行計画を確認し、予想よりもはるかに悪いパフォーマンスでクエリを調査することは確かに価値がありますが、これらの両方にこのバグとは関係のない原因がある可能性があります。とはいえ、述語とサブクエリの論理和を含むクエリを特にチェックする価値はあります。この記事の例が示すように、これがバグに遭遇する唯一の方法ではありませんが、私はそれが一般的なものであると期待しています。
運が良ければ、新しいカーディナリティ推定機能を有効にしてSQL Server 2014を実行できる場合は、トレースフラグ2363の出力を手動でチェックして、セミジョインでの固定100%選択性推定を行うことで、バグを確認できる可能性がありますが、これはほとんど便利ではありません。当然のことながら、本番システムで文書化されていないトレースフラグを使用することは望ましくありません。
この問題のユーザーボイスのバグレポートは、ここにあります。この問題の調査(および場合によっては修正)をご希望の場合は、投票してコメントしてください。