マルチクラウドまたはマルチデータセンター環境の使用は、地理的に分散したトポロジや災害復旧計画にも役立ちます。実際、最近では人気が高まっているため、スプリットブレインの概念です。この種のシナリオではリスクが高まるため、ますます重要になっています。ビジネスにとって大きな問題となる可能性のある潜在的なデータ損失やデータの不整合を回避するために、スプリットブレインを防止する必要があります。
このブログでは、スプリットブレインとは何か、およびClusterControlがこの重要な問題を回避するのにどのように役立つかを説明します。
スプリットブレインとは何ですか?
PostgreSQLの世界では、スプリットブレインは、アプリケーションが書き込みを可能にする複数のプライマリノードが同時に利用可能である場合に発生します(マルチマスター環境を持つサードパーティツールなしで)両方のノードで。この場合、ノードごとに異なる情報があり、クラスター内でデータの不整合が発生します。データをマージする必要があるため、この問題を修正するのは難しい場合がありますが、これは不可能な場合もあります。
PostgreSQL用に次のマルチクラウドトポロジがあるとします(これは現在かなり一般的なトポロジです):
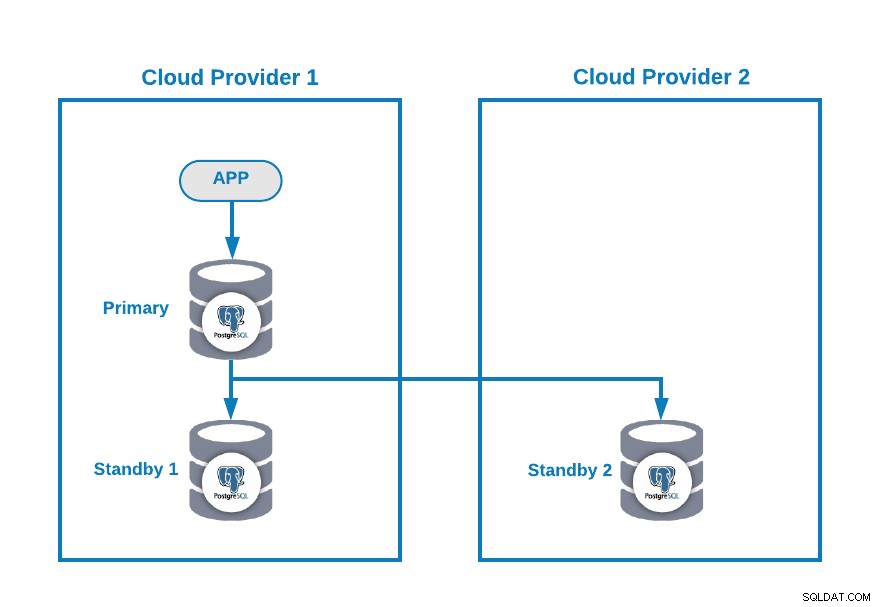
もちろん、この環境を改善するには、たとえば、クラウドプロバイダー2のアプリケーションサーバーですが、この場合は、この基本構成を使用しましょう。
プライマリノードがダウンしている場合は、スタンバイノードの1つを新しいプライマリとして昇格させ、この新しいプライマリノードを使用するようにアプリケーションのIPアドレスを変更する必要があります。
現時点では問題はありませんが、…古いプライマリノードが戻ってきた場合は、同じクラスターに同時に2つのプライマリノードがないことを確認する必要があります。 。
- STONITH:頭の中の他のノードを撃ちます。
- スミス:頭の中で自分を撃ちます。
PostgreSQLはこのプロセスを自動化する方法を提供していません。自分で作成する必要があります。
ClusterControlを使用してPostgreSQLでスプリットブレインを回避する方法
では、ClusterControlがこのタスクにどのように役立つかを見てみましょう。
まず、このブログ投稿でわかるように、これを使用してPostgreSQLマルチクラウド環境を簡単な方法でデプロイまたはインポートできます。
次に、ロードバランサー(HAProxy)を追加することでトポロジを改善できます。これは、このブログに続いてClusterControlを使用して行うこともできます。したがって、次のようなものになります:
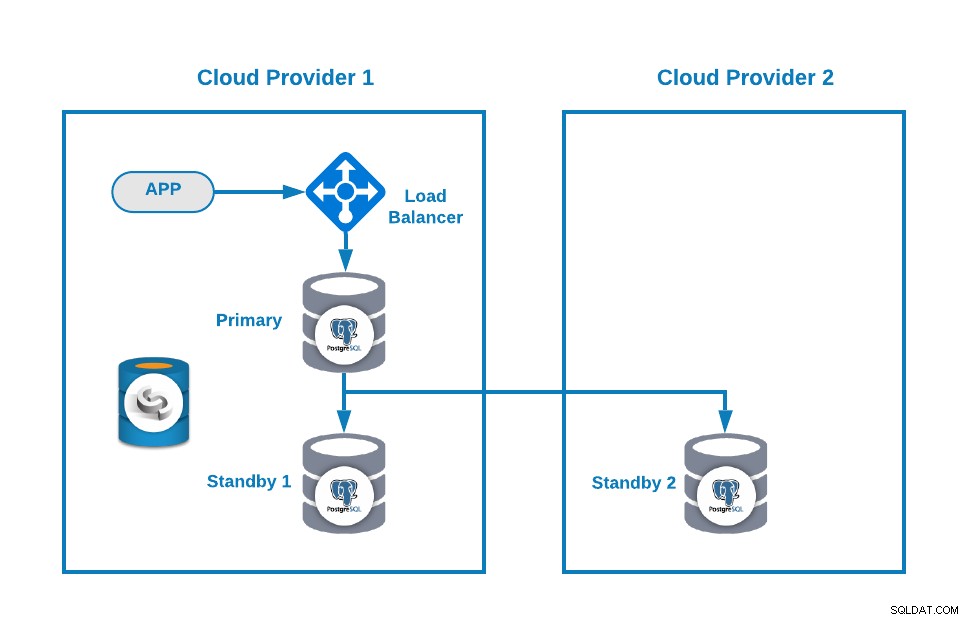
ClusterControlには、マスターの障害を検出してスタンバイを促進する自動フェイルオーバー機能があります最新のデータを新しいプライマリとして持つノード。また、残りのスタンバイノードをフェイルオーバーして、新しいプライマリノードから複製します。
HAProxyは、デフォルトで2つの異なるポート(1つは読み取り/書き込み、もう1つは読み取り専用)を使用してClusterControlによって構成されます。読み取り/書き込みポートでは、プライマリノードがオンラインで、残りのノードがオフラインであり、読み取り専用ポートでは、プライマリノードとスタンバイノードの両方がオンラインです。このようにして、ノード間の読み取りトラフィックのバランスをとることができますが、書き込み時に読み取り/書き込みポートが使用され、オンラインのサーバーであるプライマリノードに書き込みが行われるようにします。
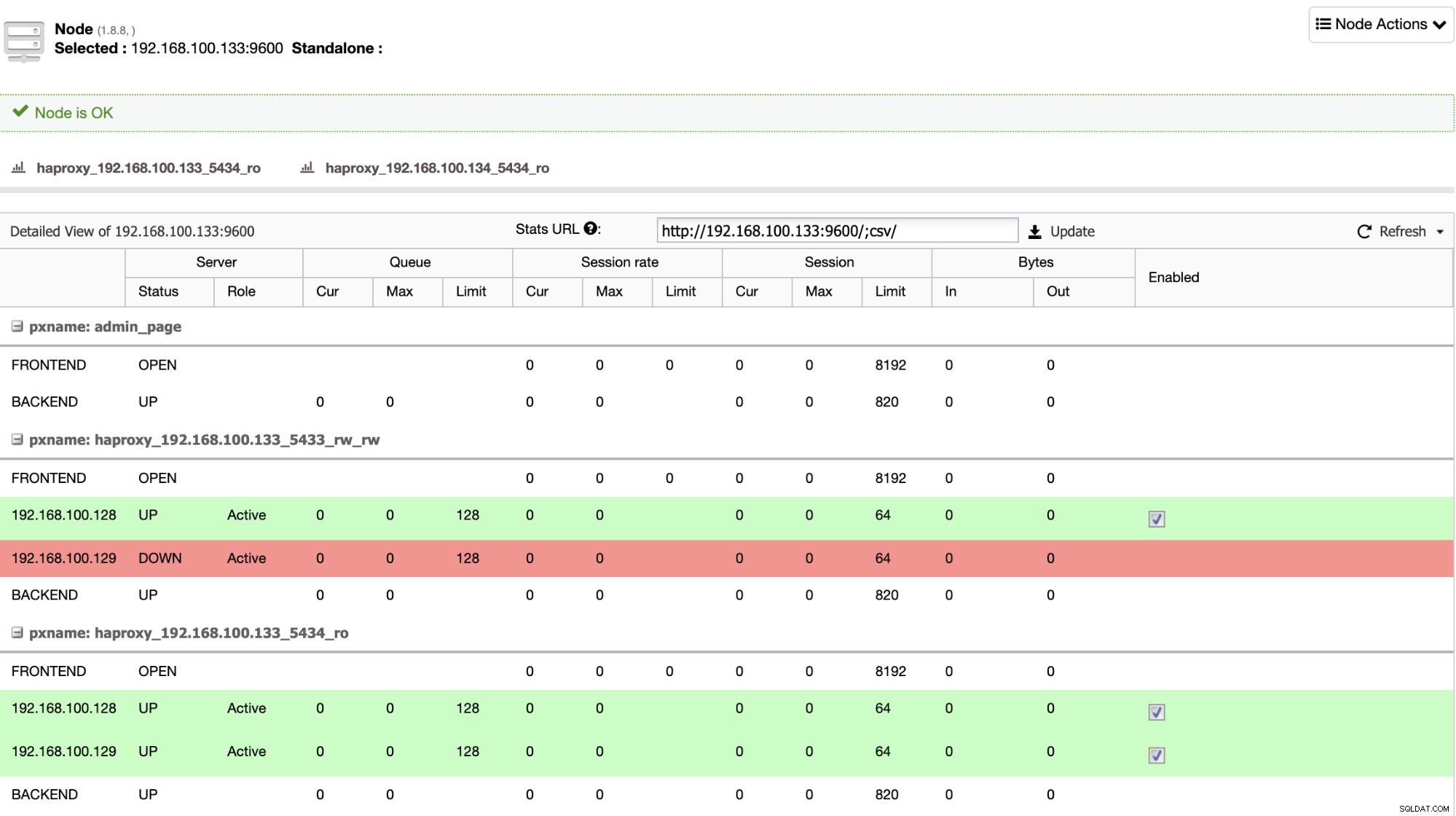
HAProxyが、プライマリまたはスタンバイのいずれかのノードがアクセスできない場合は、自動的にオフラインとしてマークされ、トラフィックの送信には考慮されません。このチェックは、デプロイメント時にClusterControlによって構成されたヘルスチェックスクリプトによって実行されます。これらは、インスタンスが稼働しているかどうか、回復中かどうか、または読み取り専用かどうかを確認します。
古いプライマリノードが戻ってきた場合、ClusterControlはそれを開始しないようにし、ロードバランサーを使用していない直接接続がある場合の潜在的なスプリットブレインを防ぎますが、追加することはできますClusterControl UIまたはCLIを使用して、自動または手動でスタンバイノードとしてクラスターに接続すると、問題が発生する前に実行していたのと同じトポロジを持つようにクラスターを昇格させることができます。
「自動回復」オプションをオンにすると、ClusterControlはこの自動フェイルオーバーを実行し、問題を通知します。このようにして、システムは介入なしで数秒で回復でき、PostgreSQLマルチクラウド環境でのスプリットブレインを回避できます。
このブログで説明されているCMONHA機能を使用してClusterControlノードを追加することで、高可用性環境を改善することもできます。