ハイブリッドクラウドは、どの企業でも一般的なアーキテクチャ設計です。このコンセプトは、パブリッククラウド、プライベートクラウド、さらにはオンプレミスソリューションを組み合わせたものであり、企業はデータの保存場所と使用方法に柔軟性を持たせることができます。また、高可用性環境の実装にも役立ちます。問題は、この種の環境を展開することは、困難で時間のかかる作業になる可能性があることです。このブログでは、Hybrid Cloudとは何か、使用する前に考慮すべきいくつかの考慮事項、およびClusterControlを使用してこの環境をデプロイする方法について説明します。
これは、プライベートクラウドとパブリッククラウド、さらにはオンプレミスサービスを組み合わせて使用するトポロジです。マルチクラウド環境に似ているように聞こえますが、主な違いは、この概念がパブリックとプライベートの組み合わせを具体的に参照していることです。これには、オンプレミスも含まれる可能性があります。
ハイブリッド環境への移行は、独自のデータセット、要件、制限、およびそれに伴うプロセスがあるため、企業ごとに異なります。
-
コンプライアンス:業界を専門とし、独自のコンプライアンス対策に精通しているベンダーを選択してください。それがHIPAA、FISMA、PCI、またはあなたの会社が加入しているあらゆる規制であるかどうかにかかわらず満たされなければなりません。最終的に、データベース管理戦略は、ビジネスのニーズを最もよく満たし、成長に合わせて拡張できるアーキテクチャによって決定する必要があります。
-
ワークロード:データベースごとに異なるワークロードがあります。それらのいくつかは、パブリッククラウド、オンプレミス、およびプライベートクラウドでうまくいくでしょう。データベースに最適な組み合わせを見つけるには、ワークロードを知ることが不可欠です。
-
管理と保守:新しい環境とは、環境を管理し、データを保守するための新しい方法を意味します。ジャンプする前に、これらの新しい環境を管理するための適切な要素と人員を決定する必要があることを確認してください。
ClusterControlのインストールが実行されており、すでに2つの異なるクラウドプロバイダーアカウントを作成していることを前提としています。同じクラウドプロバイダーでパブリッククラウドとプライベートクラウドを使用している場合、またはクラウド環境とオンプレミス環境の組み合わせ。
まず、メインのクラウドプロバイダーで環境を作成する必要があります。この場合、2つのPostgreSQLノードでAWSを使用します:

ClusterControlサーバーからのSSHおよびPostgreSQLトラフィックが許可されていることを確認してください。セキュリティグループの編集:

次に、セカンダリクラウドプロバイダー、またはプライベートサーバーまたはオンプレミスサーバーに移動し、スタンバイノードとなる仮想マシンを少なくとも1台作成します。

また、ClusterControlサーバーからのSSHおよびPostgreSQLトラフィックを許可していることを確認してください。

この場合、ソースに制限のないトラフィックを許可していますが、これは単なる例であり、実際には推奨されていません。
PostgreSQLクラスターの導入
ClusterControlサーバーに移動し、[展開]オプションを選択します。すでにPostgreSQLインスタンスを実行している場合は、代わりに「既存のサーバー/データベースのインポート」を選択する必要があります。
PostgreSQLを選択するときは、ユーザー、キー、またはパスワード、およびSSHでPostgreSQLノードに接続するためのポートを指定する必要があります。新しいクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合にも必要です。
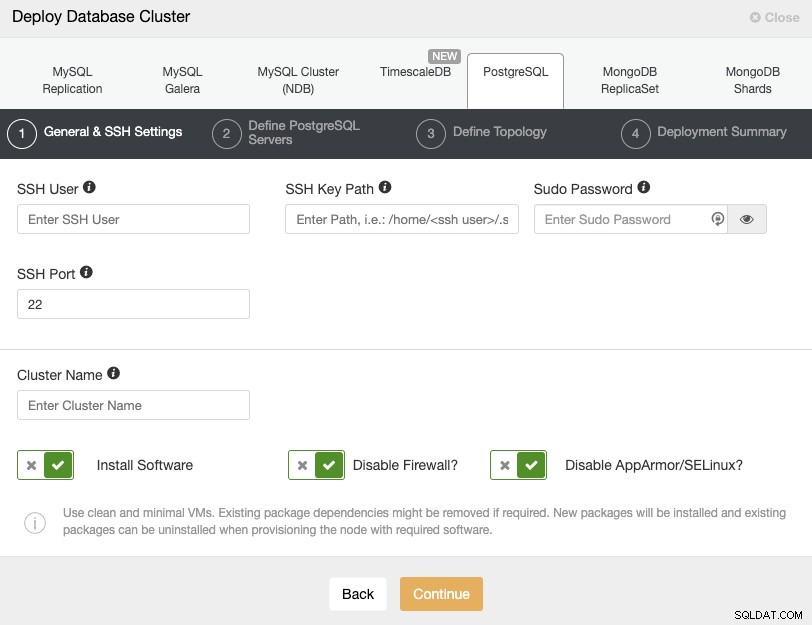
この手順の詳細については、ClusterControlのユーザー要件を確認してください。
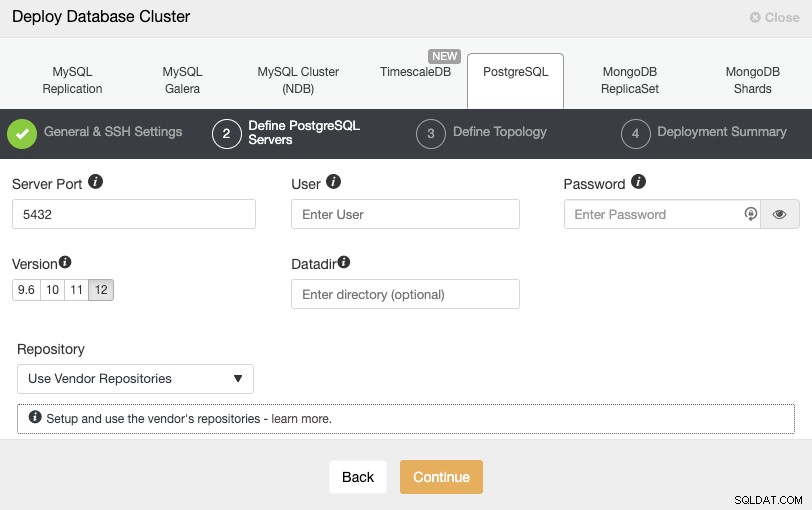
SSHアクセス情報を設定した後、データベースユーザー、バージョン、およびdatadir(オプション)を定義する必要があります。使用するリポジトリを指定することもできます。次のステップでは、作成するクラスターにサーバーを追加する必要があります。
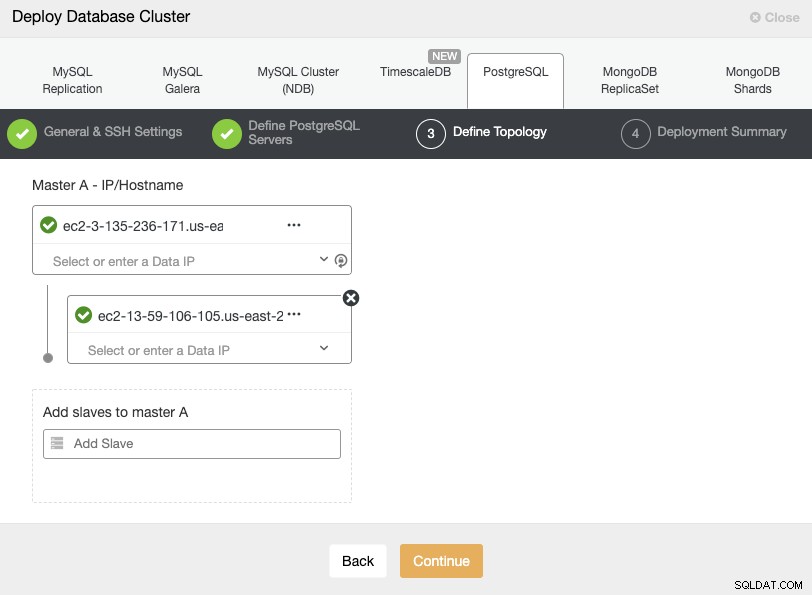
サーバーを追加するときに、IPまたはホスト名を入力できます。このステップでは、ClusterControlに使用するネットワークに関する制限がないため、セカンダリクラウドプロバイダーまたはオンプレミスに配置されたノードを追加することもできますが、より明確にするために、次のステップで追加しますセクション。ここでの唯一の要件は、ノードへのSSHアクセスが必要です。
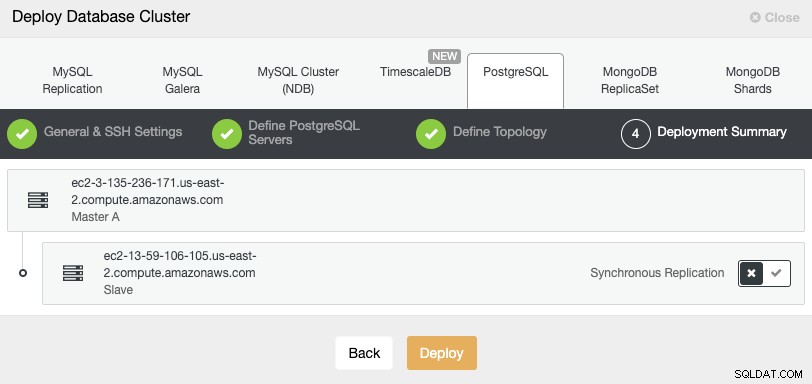
最後のステップで、レプリケーションを同期にするか非同期にするかを選択できます。
ここにリモートノードを追加する場合は、非同期レプリケーションを使用することが重要です。使用しない場合、クラスターは遅延またはネットワークの問題の影響を受ける可能性があります。
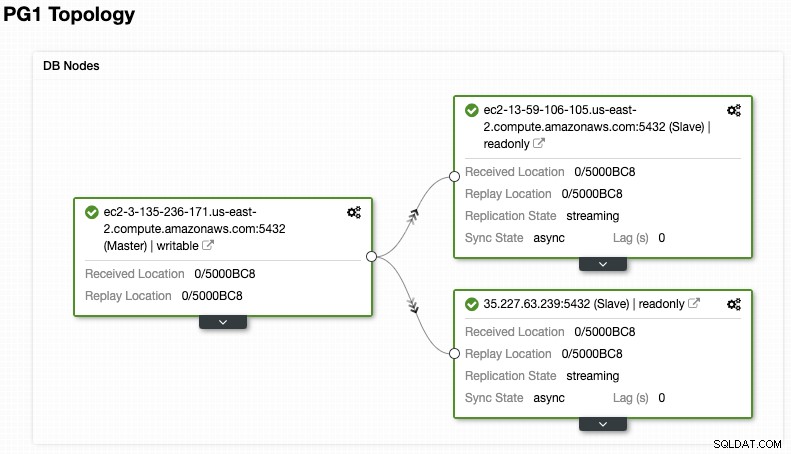
ClusterControlアクティビティモニターで作成ステータスを監視できます。
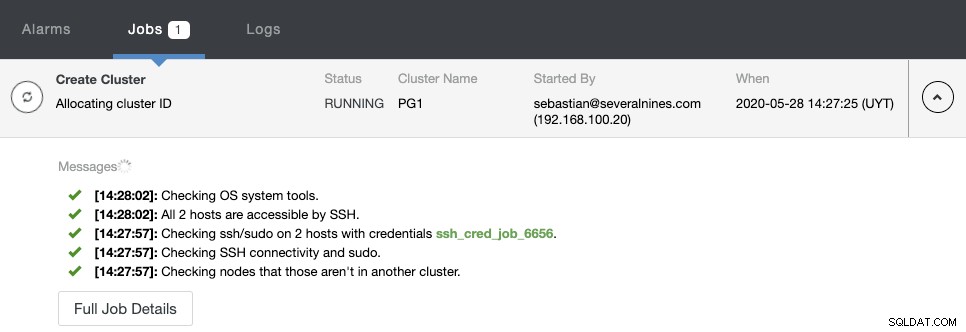
タスクが完了すると、ClusterControlのメイン画面に新しいPostgreSQLクラスターが表示されます。

クラスターを作成したら、ロードバランサーやレプリケーションノードのデプロイ/インポートなど、いくつかのタスクを実行できます。
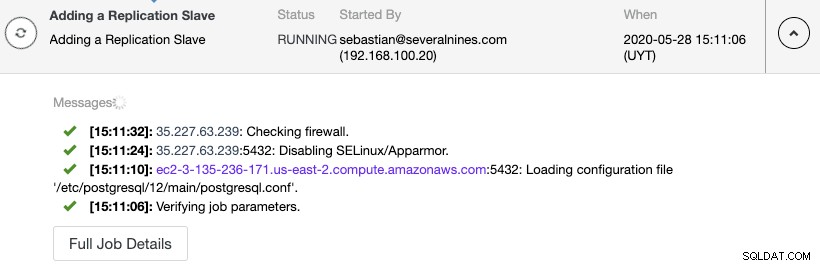
クラスターアクションに移動し、[レプリケーションスレーブの追加]を選択します:
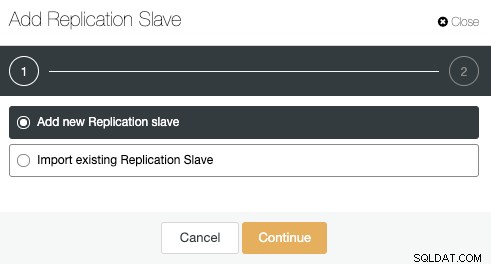
リモートノードが新規インストールであると想定しているため、[新しいレプリケーションスレーブの追加]オプションを使用します。そうでない場合は、代わりに[既存のレプリケーションスレーブのインポート]オプションを使用できます。
> 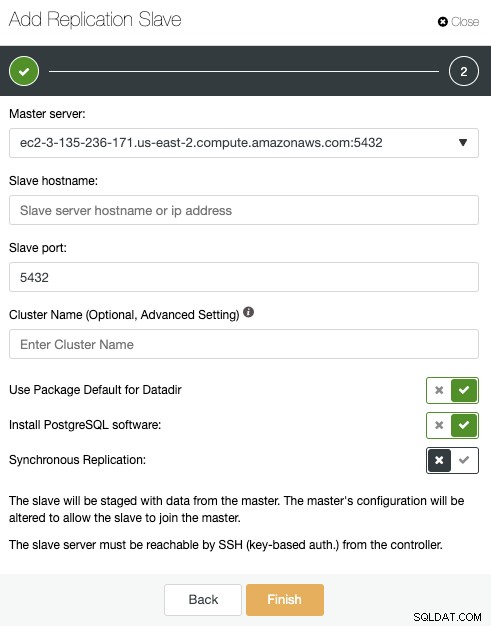
ここでは、プライマリサーバーを選択し、新しいスタンバイサーバーのIPアドレスとデータベースポートを入力するだけです。次に、ClusterControlにソフトウェアをインストールするかどうか、およびレプリケーションを同期にするか非同期にするかを選択できます。繰り返しになりますが、別の場所(別のクラウドプロバイダーまたはオンプレミス)にノードを追加する場合は、ネットワークパフォーマンスに関連する問題を回避するために、非同期レプリケーションを使用する必要があります。
このようにして、必要な数のレプリカを追加し、ClusterControlで実装できるロードバランサーを使用してそれらの間で読み取りトラフィックを分散できます。
ClusterControlアクティビティモニターでレプリケーションノードの作成を監視できます。
これらのClusterControl機能を使用すると、ハイブリッドクラウド環境、異なるクラウドプロバイダー間、またはクラウドプロバイダーとオンプレミス環境間でPostgreSQLデータベース(および異なるテクノロジー)のレプリケーションをすばやくセットアップし、セットアップを管理できます。簡単でフレンドリーな方法。クラウドプロバイダー間、またはプライベートクラウドとパブリッククラウド間の通信については、セキュリティ上の理由から、ネットワークへの不正アクセスのリスクを軽減するために、既知のソースからのトラフィックのみを制限する必要があります。