以前のHybridCloudブログでは、Hybrid Cloudトポロジ設定を利用する主なオプションの1つは、これを障害復旧ターゲットとして使用することであるとよく述べています。組織構造では、クラウドまたはオンプレミスのいずれかでデータベースセットアップをアーキテクチャに実装する前に、ディザスタリカバリプラン(DRP)に常に対処するのが一般的です。正しく対処および理解されていない場合、すべてが予期せず失敗し、ビジネスに悲劇的な影響を与える可能性があると考えるかもしれません。これらの課題を克服するには、効果的なDRP(ディザスタリカバリプラン)が必要です。このプランでは、アプリケーション、インフラストラクチャ、およびビジネス要件に応じてシステムが適切に構成されています。このような状況で成功するための鍵は、問題をどれだけ迅速に修正または回復できるかです。
DRPは災害状況に対応しますが、Business Continuityは、必要に応じてDRPが常にテストされ、動作していることを確認します。データベースのディザスタリカバリオプションは、継続的な運用と期待の限界への制限を保証する必要があります。目的のRTOおよびRPOと一致している必要があります。災害時でもアプリケーションで本番データベースを利用できるようにすることが不可欠です。そうしないと、高額な取引になる可能性があります。アーキテクトであるDBAは、データベース環境が災害に耐えることができ、災害復旧SLAに準拠していることを確認する必要があります。災害がデータベースの可用性とビジネスの継続性に影響を与えないように、データベースの展開を正しく構成する必要があります。
PostgreSQLクラスターは、ベストプラクティスに準拠し、業界標準に受け入れられる体系的なアプローチで構成する必要があります。体系的なアプローチに加えて、次のプロセスまたはメカニズムは、ハイブリッドクラウドにデプロイされたPostgreSQLにこれらのプレゼンスがあることを確認するのに役立ちます。
-
フェイルオーバー/スイッチオーバー
-
自動バックアップ
-
高可用性
-
負荷分散
-
高度に分散された環境
フェイルオーバーは、マスターが失敗した場合の自動化されたプロセスです。ホットスタンバイまたはウォームスタンバイサーバーのいずれかがプライマリ/マスターの役割に昇格します。高可用性環境で、フェールオーバーノードの候補として機能するセカンダリノードを少なくとも1つ持つことがベストプラクティスです。プライマリサーバーに障害が発生すると、スタンバイサーバーはフェイルオーバー手順を開始する必要があります。その後、セカンダリサーバーまたはスタンバイサーバーがマスターの役割を果たします。フェイルオーバーシステムは、一般的に、プライマリとスタンバイとして機能する少なくとも2台のサーバーを利用します。その接続性チェックは、ノンストップチェックを実行し、両方が良好な状態にあり、通信が有効であるかどうかを確認するハートビートメカニズムによって支援されます。ただし、場合によっては、接続によって誤ったアラームが発生することがあります。したがって、一部のセットアップおよび環境では、監視ノードなどの3番目のシステムの存在は別のネットワークまたはデータセンターにあります。これは、不適切または不要なフェイルオーバーを防ぐための絶対確実なオプションです。絶対確実な検証ノードは、追加の機能とチェックを所有できるため、複雑さが増します。このセットアップでは、実装に変更があったときにフェイルオーバーが正しく行われることを確認するために、完全かつ厳密なテストが必要です。また、これはPostgreSQLの劣化を防ぐために重要です。
ハイブリッドクラウド内のPostgreSQLクラスターでフェイルオーバーメカニズムを利用して準備するときは、ツールが、達成するはずの仕事を遂行するのに完全に適合していることを確認する必要があります。高度なフェイルオーバーに関して、PostgreSQLにバンドルされていないサードパーティのツールがあります。たとえば、ClusterControl、CitusData(c / o Microsoft)によるpg_auto_failover、Pgpool-II、Bucardoなどがあります。これらの高度なユーティリティツールは、ノードフェンシングまたはSTONITH(頭の中で他のノードを撃つ)として有名なものを提供します。これにより、障害が発生したプライマリノードまたはマスターノードは、通常のトランザクションを処理するために、書き込みを受け入れたり、以前の状態としてオンラインに戻ったりすることを回避できます。この問題は、一般にスプリットブレインシナリオとして知られています。障害(ハードウェアまたはリソースレベル)が原因でデータの同期が失われますが、プライマリサーバー(おそらく1つのプライマリサーバーのみ)は、データ書き込み要求の通常の受信者を実行しているように動作し、クラスター全体のデータ破損を引き起こします。
バックアップは、常に高い保証とデータ損失に対する保護を提供します。バックアップは、災害発生時のデータ損失を最小限に抑えるのに役立つため、RPOを最大化します。自動バックアップを検討して準備する必要があるのは、バックアップアプライアンス/ハードウェア、バックアップデータの冗長性、セキュリティ、パフォーマンス、速度、およびデータストレージです。
ハイブリッドクラウドで可用性の高いPostgreSQLクラスターは、データベース通信が稼働時間を保証することを常に保証します。高可用性の理想的なケースは、可用性の測定によって異なります。この場合、ハイブリッドクラウドにデプロイされたPostgreSQLの一般的なセットアップは、パブリッククラウドでホストされているデータベースであり、プライマリクラスターに障害が発生したり、ネットワーク障害が発生した場合にデータ回復クラスターとして機能するセカンダリクラスターである可能性があります。多くのダウンタイム。一部のセットアップでは、パブリッククラウドにあるセカンダリクラスターがプライマリクラウドほど洗練されていない可能性があります。たとえば、これがオンプレミスクラウドまたはプライベートクラウドであるとします。アプリケーションは、データベースに接続できる訪問者またはトラフィックを制限するためにいろいろと試すことができます。このタイプのシナリオでは、セットアップコストを削減できますが、もちろん、これは要件によってのみ異なります。アプリケーションタイプが大規模で、通常から混雑するトラフィック状況をノンストップで受信する必要がある場合は、高可用性を確保するために、セカンダリクラスタリソースがプライマリと同じくらい強力である必要があります。つまり、99.9999999%です。
ハイブリッドクラウド環境で高可用性PostgreSQLクラスターを実現するには、フェイルオーバーメカニズムが必要です。障害が発生してプライマリクラスターまたはプライマリサーバーがダウンした場合、セカンダリサーバーまたはスタンバイサーバーは、その場所がどこであってもマスターの役割を果たすことができます。最も重要なことは機能性であり、特にアプリケーションまたはクライアントの観点からのパフォーマンスは、まったく影響を受けないか、少なくともごくわずかです。
PostgreSQLクラスターの負荷分散メカニズムは、ハイブリッドクラウドのセットアップを支援します。これにより、特にトラフィックの負荷が高い場合に、管理が容易になり、リスクが軽減されます。多くの場合、サーバーに深刻な高負荷がかかっているため、サーバーがパニックに陥ります。これにより、バックグラウンドで実行されている多くのスレッドによってビジーなリソースが消費されるため、サーバーが使用できなくなる状態になります。この状況は、不正なクエリとデータベースの設計アーキテクチャを修正することで改善できます。これには、書き込み負荷に対して読み取りを分散する方法と、マスターマスターセットアップや1つのマスターだけで、より高いコンピューティングリソースとメモリリソースを提供するために垂直方向にスケーリングするなどのアプリケーション要件の深い理解が含まれている必要があります。ハイブリッドクラウド環境でのPostgreSQLの展開を支援するために、pgbouncerやPgpoolIIなどのサードパーティツールも豊富に用意されています。
スケーラビリティに関しては、複数の場所または異なるクラウドプロバイダー(オンプレミスまたはプライベートクラウドとパブリッククラウド)に高度に分散されているため、ハイブリッドクラウド環境での柔軟性と忍容性が向上し、ディザスタリカバリに最適です。自然災害や大災害に有利な特定のクラウドの場所でフェイルオーバーする必要がある場合、特にプライマリクラスターが存在する指定された地域が現在荒廃しているか、自然の原因によって影響を受けている場合は、柔軟性があります。これは避けられない原因であり、現在の状況を理解し、信頼する必要があります。アプリケーションとクライアントは、ノンストップで継続的に提供される必要があります。これは、プライベート環境またはオンプレミス環境でもサービスを提供しながら、クラウドでパブリックに利用できるという目的を果たします。この設定により、複雑さが増し、データベース側とセキュリティおよびネットワーキングに関する高度な知識が必要になります。ここで成功するには、最適化と調整が不可欠です。インターネット上を移動するときにデータをカプセル化するための厳格なセキュリティを提供する一方で、パフォーマンスが安定し、実装されたセットアップの影響を受けないことが証明されている必要があるためです。
セットアップが複雑なため、ツールを使用することは、展開を管理し、データベースの全体的なステータスを促進し、クラスターの1つの側面を監視しますが、オンプレミスのプライベートクラウドから全体的なレベルで監視するのに理想的です。パブリッククラウドの側面について。アラームやアラートが発生した場合に問題を簡単かつタイムリーに修正して対処できるように、すべての設定を管理しやすくわかりやすいレベルに保つ必要があります。
ClusterControlを使用すると、組織または企業はデータベースを柔軟に管理し、セットアップの全体的な複雑さを軽減できます。 ClusterControlは、フェイルオーバー、自動バックアップを提供し、高可用性セットアップ、負荷分散を提供し、分散環境の展開をサポートして、パブリッククラウド、プライベート、またはオンプレミスのいずれかにノードを簡単に追加できるようにします。
ClusterControl自動回復
ClusterControlの自動回復は、特にノードがダウンした場合やクラスターが劣化状態になった場合に、多くのフェイルオーバーメカニズムと回復特性を表します。これは、以下のスクリーンショットに示すように簡単に実行できます。
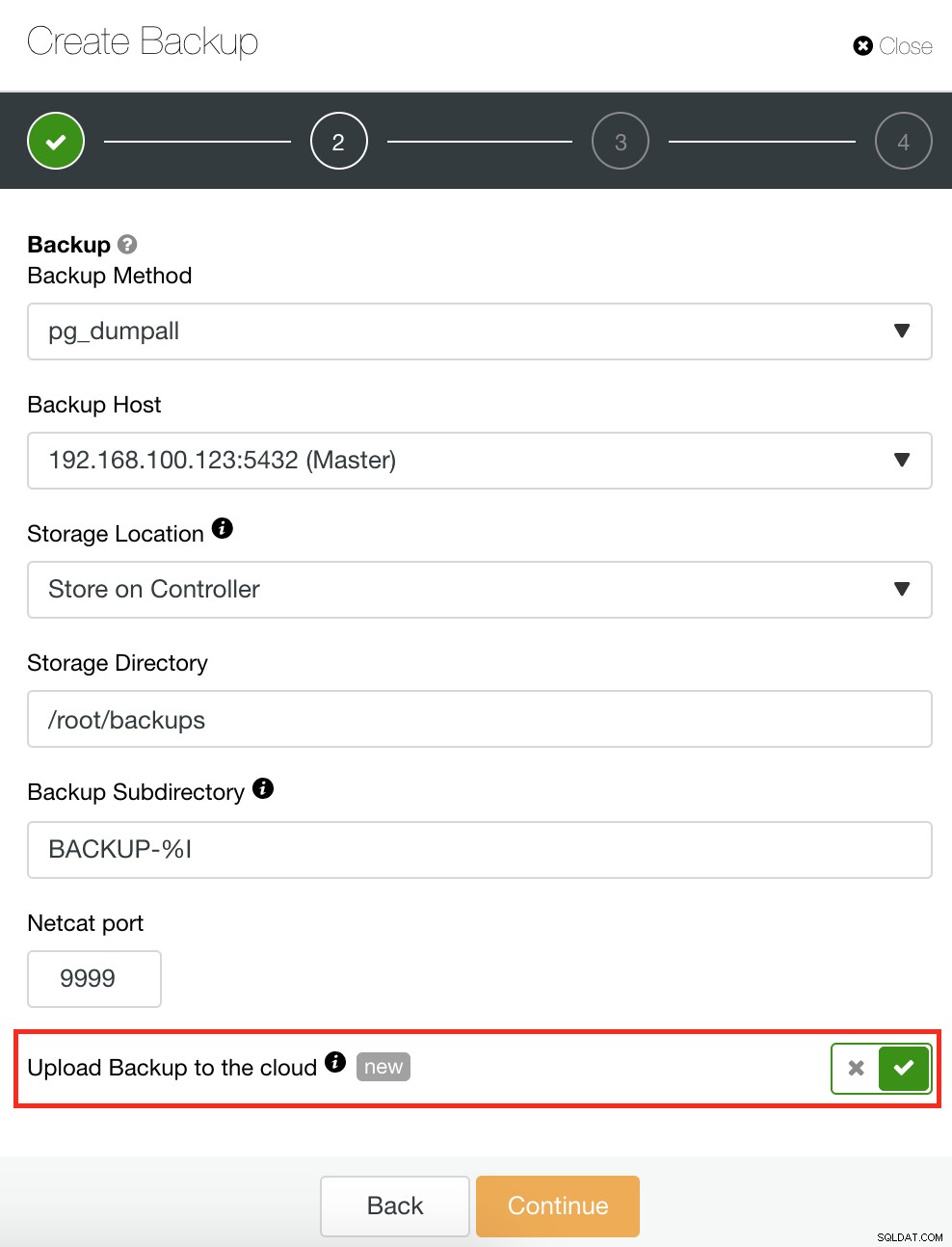
ClusterControlには、バックアップの管理、バックアップの作成、バックアップのスケジュール設定、およびバックアップの復元を可能にするバックアップと復元機能もあります。バックアップの管理は非常に簡単で、バックアップの作成またはスケジュール設定は簡単ですが、高度なオプションも提供します。また、バックアップデータの冗長性を確保し、ディザスタリカバリオプションを強化できるクラウドバックアップオプションも提供します。以下を参照してください:
以下に示すように、バックアップを管理すると、復元するバックアップを選択するためのシンプルなUIが提供されます。そうしないと、削除する必要がある場合があります。 ClusterControlバックアップでは保持期間を選択できるため、リストが長い場合は、保持期間に達したときにこれらの一部を削除できます。 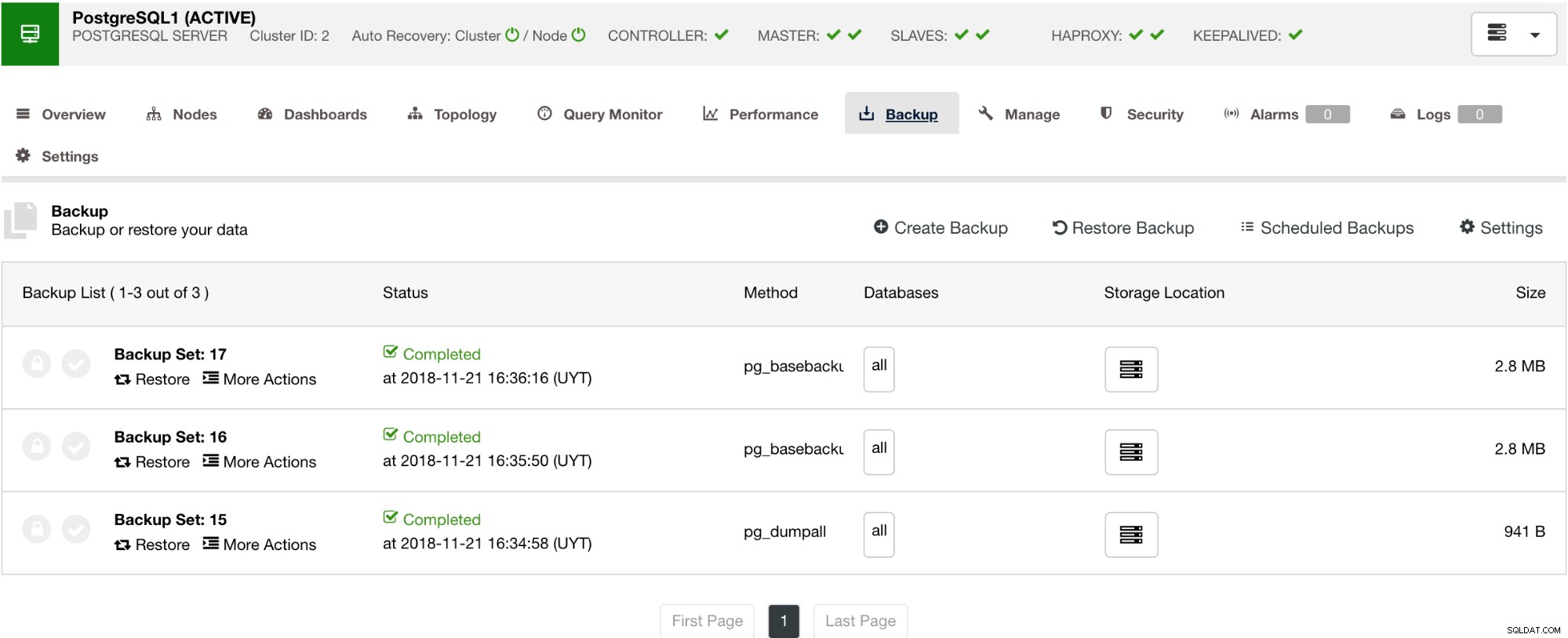
高可用性(HA)および負荷分散(LB)メカニズムをサポート
PostgreSQLクラスターに高可用性を追加するために、手動でセットアップしたり、いくつかの方法を調べたりする必要はありません。 ClusterControlで仕事を成し遂げるための簡単で便利な方法があります。スクリーンショットの例を見ると、HAProxyとKeepalivedが設定されています。以下のスクリーンショットを参照してください:
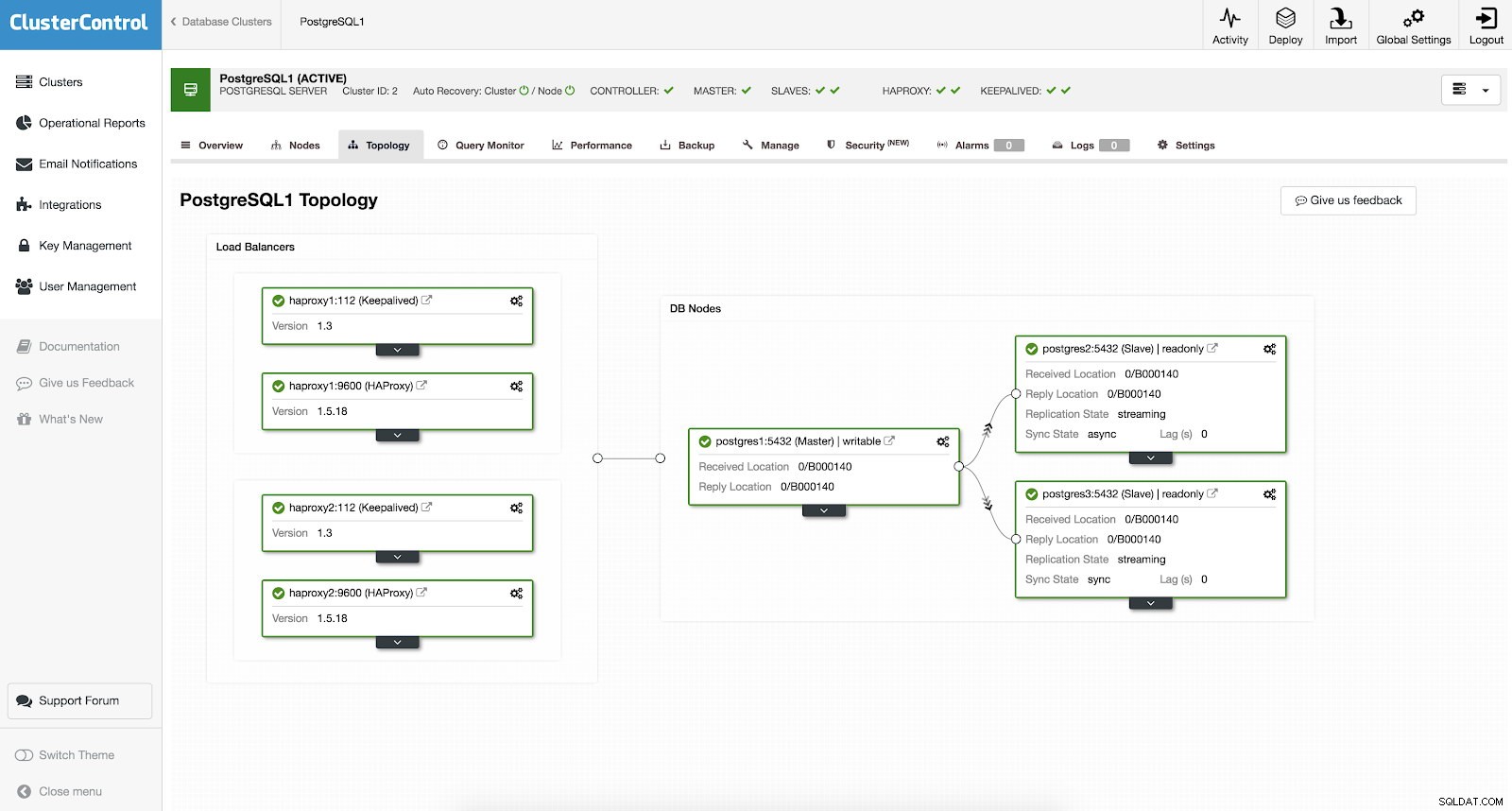
ClusterControlで高可用性を設定するには、<クラスターの選択>→管理→ロードバランサーを使用します。
オンプレミスまたはプライベートクラウドからパブリッククラウドに均等に分散したい場合、ClusterControlはクラウド展開もサポートします。ただし、PostgreSQLクラスターの場合、セカンダリスレーブを別のクラウドに配置することを計画している場合は、以下に示すようにスレーブクラスターを作成できます。

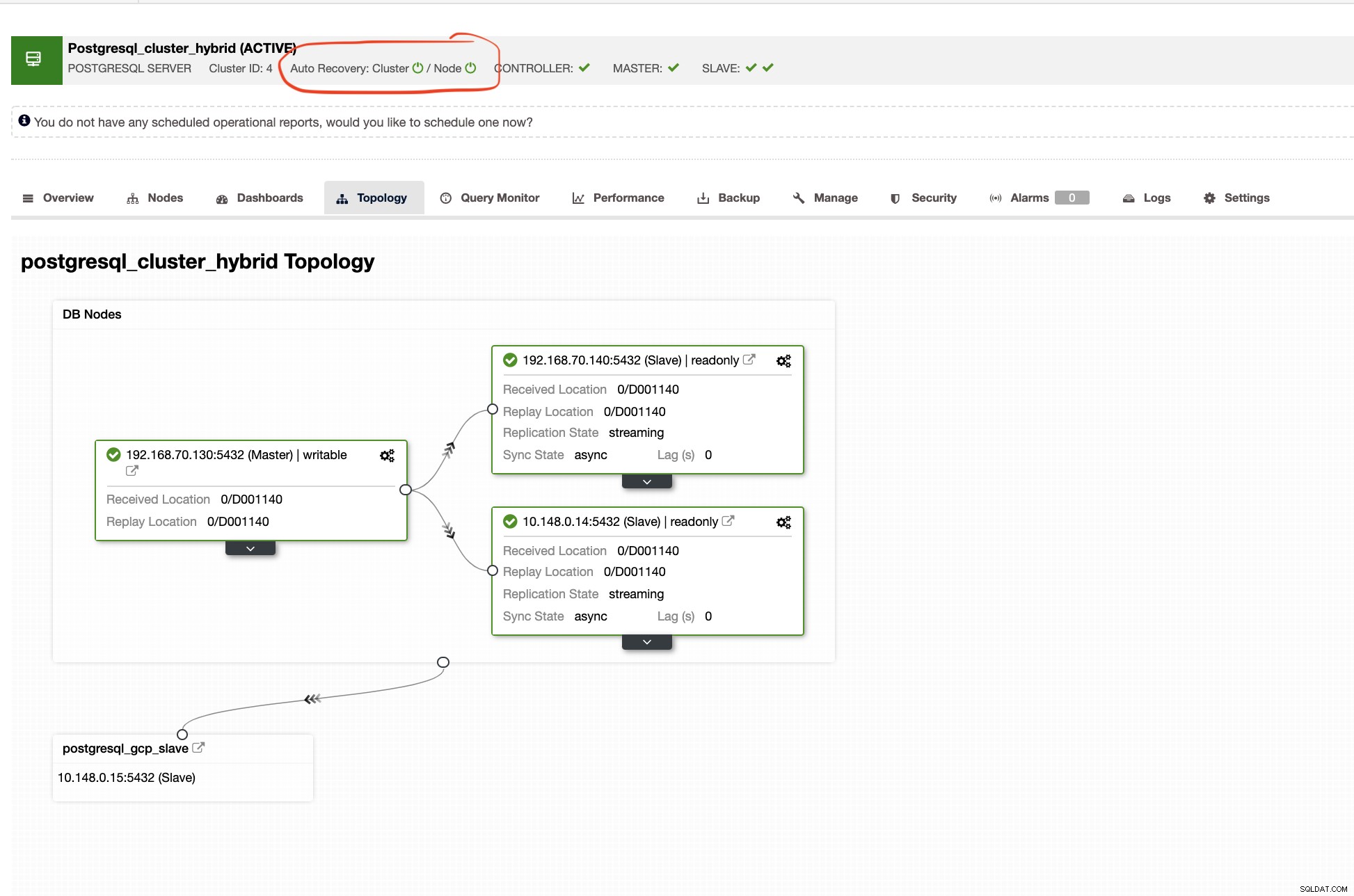
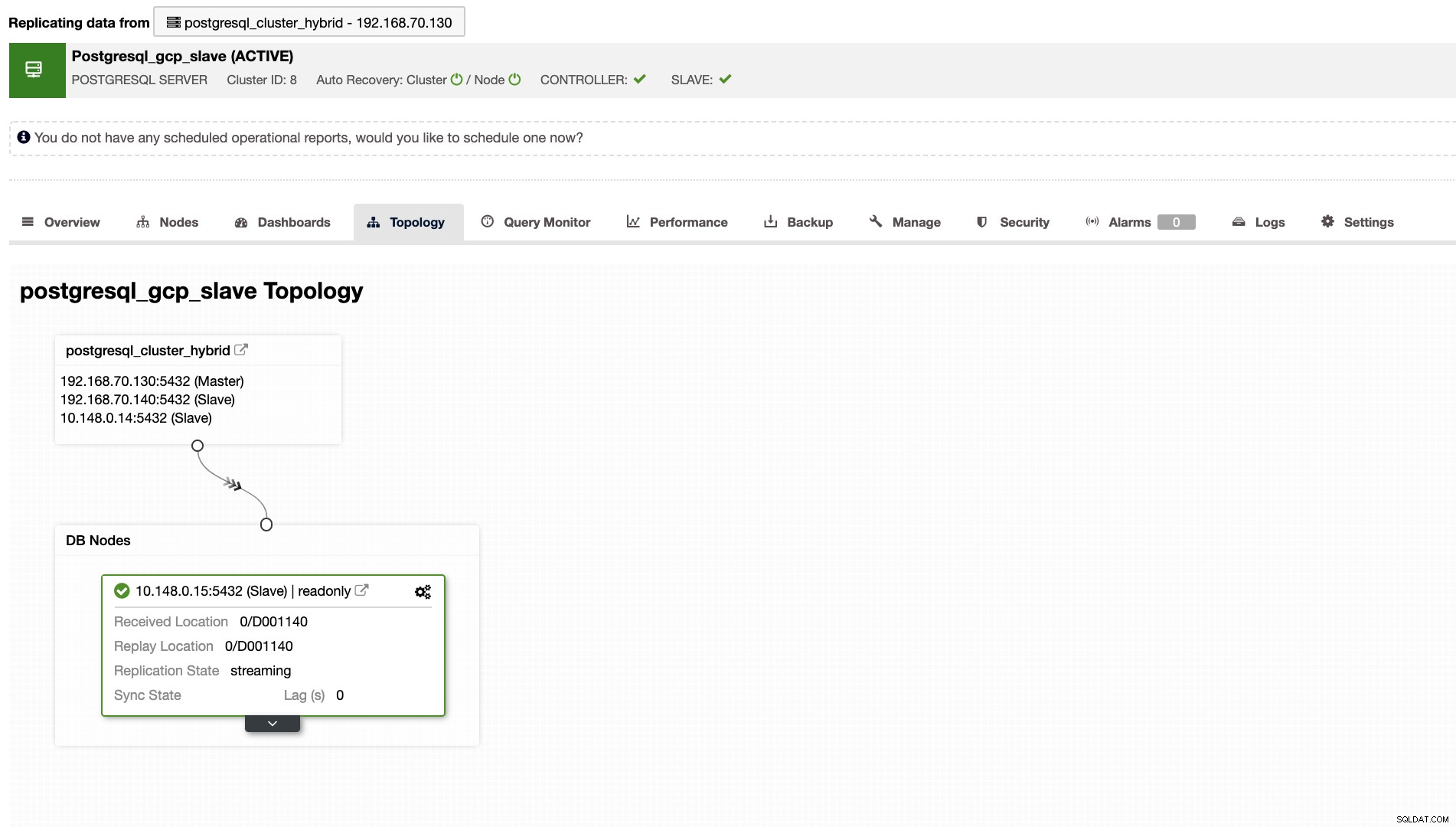
ClusterControlは、ハイブリッドクラウド環境をセットアップするたびに、クラスターの適切なトポロジも表示します。以下を参照してください
一方、スレーブクラスターでは、トポロジに元のツリーが表示され、マスターが表示されます。ここでのスレーブは、主にGoogle Cloudにある別のネットワークにあるのに対し、マスターはオンプレミスにあることを示しています。
特にPostgreSQLクラスターを使用したハイブリッドクラウドのセットアップは、複雑さを増すことを認めることができます。災害復旧計画をサポートするには、オプションを備えた適切なツールが必要です。これらは、経済的損害や顧客の信頼を失うという潜在的な大惨事からあなたのビジネスを救い、回避するために非常に重要です。テクノロジーの適切なツールとスキルに投資すれば、ビジネスを悪影響から救うことができます。