もともとは2019年7月2日にサーバーレスに投稿されました

GraphQL APIを介して単純なデータベースを公開するには、多くのカスタムコードとインフラストラクチャが必要です。真か偽か。
「本当」と答えた人のために、GraphQL APIの構築が実際にはかなり簡単であることを示し、その理由と方法を示す具体的な例をいくつか示します。
(サーバーレスを使用してGraphQL APIを構築するのがいかに簡単かをすでに知っている場合は、この記事にもたくさんあります。)
GraphQLは、WebAPIのクエリ言語です。従来のRESTAPIとGraphQLに基づくAPIには重要な違いがあります。GraphQLでは、1つのリクエストを使用して複数のエンティティを一度にフェッチできます。これにより、ページの読み込みが速くなり、フロントエンドアプリの構造がシンプルになり、すべてのユーザーのWebエクスペリエンスが向上します。これまでにGraphQLを使用したことがない場合は、このGraphQLチュートリアルで簡単な紹介を確認することをお勧めします。
サーバーレスフレームワークはGraphQLAPIに最適です。サーバーレスを使用すると、クラウドで独自のAPIサーバーを実行、管理、スケーリングすることを心配する必要がなく、インフラストラクチャ自動化スクリプトを作成する必要もありません。サーバーレスの詳細については、こちらをご覧ください。さらに、サーバーレスは、ベンダーにとらわれない優れた開発者エクスペリエンスと、GraphQLアプリケーションの構築を支援する堅牢なコミュニティを提供します。
私たちの日常生活の多くのアプリケーションにはソーシャルネットワーキング機能が含まれており、そのような機能は、ユーザーやTwitter投稿などのネストされたエンティティを含む構造を公開するのが難しいRESTモデルの代わりにGraphQLを実装することで本当にメリットがあります。 GraphQLを使用すると、単一のAPIリクエストを使用して、必要なすべてのエンティティをクエリ、書き込み、編集できる統合APIエンドポイントを構築できます。
この記事では、サーバーレスフレームワーク、Node.js、およびAmazon RDSで利用可能ないくつかのホストされたデータベースソリューション(MySQL、PostgreSQL、およびAmazon Auroraと同様のMySQL)を使用して単純なGraphQLAPIを構築する方法について説明します。
GitHubのこのリポジトリの例をたどって、飛び込みましょう!
リレーショナルDBバックエンドを使用したGraphQLAPIの構築
このサンプルプロジェクトでは、3つのデータベース(MySQL、PostgreSQL、Aurora)すべてを同じコードベースで使用することにしました。これは本番アプリでもやり過ぎですが、Webスケールの構築方法に驚かされたいと思いました。 😉
しかし、真剣に、お気に入りのデータベースに適用される関連する例を確実に見つけるために、プロジェクトを詰め込みすぎました。他のデータベースの例をご覧になりたい場合は、コメントでお知らせください。
GraphQLスキーマの定義
作成するGraphQLAPIのスキーマを定義することから始めましょう。これは、プロジェクトのルートにあるschema.gqlファイルでGraphQL構文を使用して行います。この構文に慣れていない場合は、このGraphQLドキュメントページの例をご覧ください。
まず、最初の2つのアイテムをスキーマに追加します。UserエンティティとPostエンティティであり、各ユーザーが複数のPostエンティティを関連付けることができるように次のように定義します。
タイプユーザー{
UUID:文字列
名前:文字列
投稿:[投稿]
}
タイプ投稿{
UUID:文字列
テキスト:文字列
}
これで、UserエンティティとPostエンティティがどのように見えるかを確認できます。後で、これらのフィールドをデータベースに直接保存できることを確認します。
次に、APIのユーザーがこれらのエンティティをクエリする方法を定義しましょう。 2つのGraphQLタイプUserとPostをGraphQLクエリで直接使用することもできますが、スキーマを単純に保つために、代わりに入力タイプを作成することをお勧めします。そこで、先に進み、これらの入力タイプのうち2つを追加します。1つは投稿用、もう1つはユーザー用です。
input UserInput {
名前:文字列
投稿:[PostInput]
}
input PostInput {
テキスト:文字列
}
次に、ミューテーション、つまりGraphQLAPIを介してデータベースに格納されているデータを変更する操作を定義しましょう。このために、Mutationタイプを作成します。今のところ使用する唯一のミューテーションはcreateUserです。 3つの異なるデータベースを使用しているため、データベースタイプごとにミューテーションを追加します。各ミューテーションは入力UserInputを受け入れ、Userエンティティを返します。
また、ユーザーにクエリを実行する方法も提供したいので、データベースタイプごとに1つのクエリを使用してクエリタイプを作成します。各クエリは、ユーザーのUUIDである文字列を受け入れ、その名前、UUID、および関連するすべてのPos``tのコレクションを含むUserエンティティを返します。
最後に、スキーマを定義し、クエリタイプとミューテーションタイプをポイントします。
schema { query: Query mutation: Mutation }
これで、新しいGraphQLAPIの完全な説明ができました。ここでファイル全体を見ることができます。
GraphQLAPIのハンドラーの定義
GraphQL APIの説明ができたので、各クエリとミューテーションに必要なコードを記述できます。まず、プロジェクトのルートで、前に作成したschema.gqlファイルのすぐ隣にhandler.jsファイルを作成します。
handler.jsの最初の仕事は、スキーマを読み取ることです。
typeDefs定数は、GraphQLエンティティの定義を保持するようになりました。次に、関数のコードが存在する場所を指定します。わかりやすくするために、クエリとミューテーションごとに個別のファイルを作成します。
リゾルバー定数は、APIのすべての関数の定義を保持するようになりました。次のステップは、GraphQLサーバーを作成することです。上記で必要なgraphql-yogaライブラリを覚えていますか?ここではそのライブラリを使用して、機能するGraphQLサーバーを簡単かつ迅速に作成します。
最後に、GraphQLハンドラーをGraphQL Playgroundハンドラーと一緒にエクスポートします(これにより、WebブラウザーでGraphQL APIを試すことができます)。
さて、これでhandler.jsファイルは完成です。次は、データベースにアクセスするすべての関数のコードを記述します。
クエリとミューテーションのコードを書く
ここで、データベースにアクセスし、GraphQLAPIを強化するためのコードが必要です。プロジェクトのルートで、MySQLリゾルバー関数用に次の構造を作成し、他のデータベースを次のように作成します。
一般的なクエリ
Commonフォルダーで、mysql.jsファイルにcreateUserミューテーションとgetUserクエリに必要なものを入力します。initクエリ。ユーザーと投稿がまだ存在しない場合は、それらのテーブルを作成します。また、ユーザークエリは、ユーザーの作成およびクエリ時にユーザーのデータを返します。これは、ミューテーションとクエリの両方で使用します。
initクエリは、次のようにUsersテーブルとPostsテーブルの両方を作成します。
getUserクエリは、ユーザーとその投稿を返します。
これらの関数は両方ともエクスポートされます。その後、handler.jsファイルでそれらにアクセスできます。
突然変異を書く
新しいユーザーの名前と、それらに属するすべての投稿のリストを受け入れる必要があるcreateUserミューテーションのコードを記述します。これを行うには、ミューテーション用にエクスポートされた単一のfunc関数を使用してresolver / Mutation/mysql_createUser.jsファイルを作成します。
ミューテーション関数は、次のことを順番に実行する必要があります。
-
アプリケーションの環境変数のクレデンシャルを使用してデータベースに接続します。
-
ミューテーションへの入力として提供されたユーザー名を使用して、ユーザーをデータベースに挿入します。
-
また、ミューテーションへの入力として提供された、ユーザーに関連付けられた投稿を挿入します。
-
作成したユーザーデータを返します。
これをコードで実現する方法は次のとおりです。
ここで突然変異を定義する完全なファイルを見ることができます。
クエリの作成
getUserクエリの構造は、先ほど作成したミューテーションと似ていますが、これはさらに単純です。 getUser関数がCommon名前空間にあるので、クエリにカスタムSQLは必要ありません。したがって、次のようにresolver / Query/mysql_getUser.jsファイルを作成します。
このファイルで完全なクエリを確認できます。
serverless.ymlファイルにすべてをまとめる
一歩後退しましょう。現在、次のものがあります:
-
GraphQLAPIスキーマ。
-
handler.jsファイル。
-
一般的なデータベースクエリのファイル。
-
各ミューテーションとクエリのファイル。
最後のステップは、serverless.ymlファイルを介してこれらすべてを接続することです。プロジェクトのルートに空のserverless.ymlを作成し、プロバイダー、リージョン、ランタイムを定義することから始めます。また、LambdaRole IAMロール(後でここで定義します)をプロジェクトに適用します。
次に、データベースクレデンシャルの環境変数を定義します。
すべての変数がカスタムセクションを参照していることに注意してください。カスタムセクションは次に来て、変数の実際の値を保持します。パスワードはデータベースにとってひどいパスワードであり、より安全なものに変更する必要があることに注意してください(おそらくp @ssw0rd😃):
Fn ::GettAttの後のそれらの参照は何ですか、あなたは尋ねますか?それらはデータベースリソースを参照します:
resource / MySqlRDSInstance.ymlファイルは、MySQLインスタンスのすべての属性を定義します。あなたはここでその完全な内容を見つけることができます。
最後に、serverless.ymlファイルで、graphqlとplaygroundの2つの関数を定義します。 graphql関数はすべてのAPIリクエストを処理し、playgroundエンドポイントはGraphQL Playgroundのインスタンスを作成します。これは、WebブラウザーでGraphQLAPIを試すための優れた方法です。
これで、アプリケーションのMySQLサポートが完了しました。
serverless.ymlファイルの全内容はここにあります。
AuroraとPostgreSQLのサポートを追加する
このプロジェクトで他のデータベースをサポートするために必要なすべての構造をすでに作成しました。 AuroraとPostgresのサポートを追加するには、それらのミューテーションとクエリのコードを定義するだけで済みます。これは次のように行います。
-
AuroraとPostgresの共通クエリファイルを追加します。
-
両方のデータベースにcreateUserミューテーションを追加します。
-
両方のデータベースにgetUserクエリを追加します。
-
両方のデータベースに必要なすべての環境変数とリソースの構成をserverless.ymlファイルに追加します。
この時点で、MySQL、Aurora、PostgreSQLを搭載したGraphQLAPIをデプロイするために必要なものはすべて揃っています。
GraphQLAPIのデプロイとテスト
GraphQLAPIのデプロイは簡単です。
-
まず、npm installを実行して、依存関係を設定します。
-
次に、npm run deployを実行します。これにより、すべての環境変数が設定され、デプロイが実行されます。
-
内部的には、このコマンドは適切な環境を使用してサーバーレスデプロイを実行します。
それでおしまい!デプロイステップの出力には、デプロイされたアプリケーションのURLエンドポイントが表示されます。このURLを使用してGraphQLAPIにPOSTリクエストを発行でき、同じURLに対してGETを使用してPlayground(すぐに使用します)を利用できます。
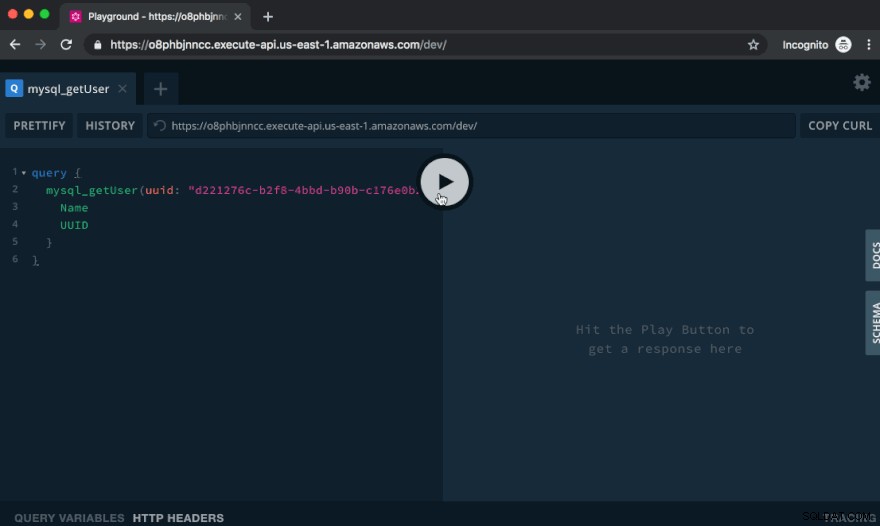
GraphQLプレイグラウンドでAPIを試す
ブラウザでそのURLにアクセスしたときに表示されるGraphQLPlaygroundは、APIを試すのに最適な方法です。
次のミューテーションを実行してユーザーを作成しましょう:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
このミューテーションでは、mysql_createUser APIを呼び出し、新しいユーザーの投稿のテキストを提供し、ユーザーの名前とUUIDを応答として返したいことを示します。
上記のテキストをプレイグラウンドの左側に貼り付けて、[再生]ボタンをクリックします。右側に、クエリの出力が表示されます。
それでは、このユーザーにクエリを実行しましょう:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
これにより、作成したばかりのユーザーの名前とUUIDが返されます。きちんとした!
他のバックエンドであるPostgreSQLとAuroraでも同じことができます。そのためには、ミューテーションの名前をpostgres_createUserまたはaurora_createUserに置き換え、クエリをpostgres_getUserまたはaurora_getUserに置き換える必要があります。自分で試してみてください! (ユーザーはデータベース間で同期されないため、特定の各データベースで作成したユーザーのみを照会できることに注意してください。)
MySQL、PostgreSQL、およびAuroraの実装の比較
まず、AuroraはMySQLと互換性があるため、ミューテーションとクエリはAuroraとMySQLでまったく同じように見えます。そして、これら2つとPostgresの実装の間には最小限のコードの違いしかありません。
実際、単純なユースケースの場合、3つのデータベースの最大の違いは、Auroraはクラスターとしてのみ使用できることです。利用可能な最小のAurora構成には、読み取り専用レプリカと書き込みレプリカが1つずつ含まれているため、この基本的なAuroraデプロイメントでもクラスター化された構成が必要です。
Auroraは、主にAmazonがデータベースエンジンに対して行ったSSD最適化により、MySQLやPostgreSQLよりも高速なパフォーマンスを提供します。プロジェクトが成長するにつれて、Auroraは、デフォルトのMySQLおよびPostgreSQL構成と比較して、データベースのスケーラビリティが向上し、メンテナンスが容易になり、信頼性が向上することに気付くでしょう。ただし、データベースを調整してレプリケーションを追加すれば、MySQLとPostgreSQLでもこれらの改善のいくつかを行うことができます。
テストプロジェクトや遊び場には、MySQLまたはPostgreSQLをお勧めします。これらは、AWS無料利用枠の一部であるdb.t2.microRDSインスタンスで実行できます。 Auroraは現在db.t2.microインスタンスを提供していないため、このテストプロジェクトでAuroraを使用するにはもう少し料金がかかります。
最後の重要な注意事項
サーバーレスデプロイを削除することを忘れないでください GraphQL APIの試用を終えたら、使用しなくなったデータベースリソースにお金をかけ続けないようにします。
この例で作成されたスタックは、プロジェクトのルートでnpmrunremoveを実行することで削除できます。
幸せな実験です!
まとめ
この記事では、3つの異なるデータベースを同時に使用して単純なGraphQLAPIを作成する方法について説明しました。これは実際に行うことではありませんが、Aurora、MySQL、およびPostgreSQLデータベースの単純な実装を比較することができました。 3つのデータベースすべての実装は、構文と展開構成にわずかな違いがない限り、単純なケースではほぼ同じであることがわかりました。
このGitHubリポジトリで、私たちが使用している完全なサンプルプロジェクトを見つけることができます。プロジェクトを試す最も簡単な方法は、リポジトリのクローンを作成し、npmrundeployを使用してマシンからデプロイすることです。
サーバーレスを使用したGraphQLAPIのその他の例については、serverless-graphqlリポジトリを確認してください。
サーバーレスGraphQLAPIの大規模な実行について詳しく知りたい場合は、記事シリーズ「サーバーレスでのスケーラブルで信頼性の高いGraphQLエンドポイントの実行」をお楽しみください。
たぶん、GraphQLはあなたのジャムではなく、REST APIをデプロイしたいですか?いくつかの例については、このブログ投稿をご覧ください。
質問?この投稿にコメントするか、フォーラムでディスカッションを作成してください。
元々はhttps://www.serverless.comで公開されていました。