このブログシリーズの3番目で最後のパートへようこそ。PostgreSQLのパフォーマンスが何年にもわたってどのように進化したかを探ります。最初の部分では、pgbenchテストで表されるOLTPワークロードについて説明しました。第2部では、従来のTPC-Hベンチマークのサブセット(基本的には電力テストの一部)を使用して、分析/BIクエリについて説明しました。
そして、この最後の部分では、全文検索、つまり、大量のテキストデータのインデックスを作成して検索する機能について説明します。同じインフラストラクチャ(特にインデックス)は、JSONBドキュメントなどの半構造化データのインデックス作成に役立つ場合がありますが、このベンチマークが焦点を当てているのはそれではありません。
ただし、最初に、PostgreSQLでの全文検索の履歴を見てみましょう。これは、従来は構造化データを行と列に格納することを目的とした、RDBMSに追加する奇妙な機能のように見えるかもしれません。
全文検索の歴史
1996年にPostgresがオープンソースになったとき、全文検索と呼べるものは何もありませんでした。しかし、Postgresを使い始めた人々は、テキストドキュメントでインテリジェントな検索を行いたいと考えていたため、LIKEクエリは十分ではありませんでした。彼らは、辞書を使用して用語を字句化したり、ストップワードを無視したり、一致するドキュメントを関連性で並べ替えたり、インデックスを使用してこれらのクエリを実行したりできるようにしたいと考えていました。従来のSQL演算子では合理的に実行できないこと。
幸いなことに、それらの人々の一部は開発者でもあったので、彼らはこれに取り組み始めました–そしてPostgreSQLが世界中でオープンソースとして利用可能であるおかげで、彼らはそうすることができました。全文検索には何年にもわたって多くの貢献者がいますが、最初はこの取り組みは、次の写真に示すように、OlegBartunovとTeodorSigaevによって主導されました。どちらも依然としてPostgreSQLの主要な貢献者であり、全文検索、インデックス作成、JSONサポート、およびその他の多くの機能に取り組んでいます。

TeodorSigaevとOlegBartunov
当初、この機能は、2002年にリリースされた「tsearch」と呼ばれる外部の「contrib」モジュール(現在は拡張機能と言えます)として開発されました。その後、これはtsearch2によって廃止され、多くの点で機能が大幅に改善されました。 8.3(2008年にリリース)これはPostgreSQLコアに完全に統合されました(つまり、拡張機能は下位互換性のために提供されていましたが、拡張機能をまったくインストールする必要はありませんでした)。
それ以来、多くの改善がありました(たとえば、JSONBのようなデータ型のサポート、jsonpathを使用したクエリなどの作業は継続されています)。しかし、これらのプラグインは、現在PostgreSQLにあるフルテキスト機能のほとんどを導入しました。辞書、フルテキストのインデックス作成およびクエリ機能などです。
ベンチマーク
OLTP / TPC-Hベンチマークとは異なり、「業界標準」と見なされる、または複数のデータベースシステム用に設計されたフルテキストベンチマークを私は知りません。私が知っているベンチマークのほとんどは、単一のデータベース/製品で使用することを目的としており、それらを意味のある形で移植するのは難しいため、別のルートを使用して、独自のフルテキストベンチマークを作成する必要がありました。
数年前、私はarchieを作成しました。これはPostgreSQLメーリングリストアーカイブのダウンロードを可能にし、解析されたメッセージをPostgreSQLデータベースにロードしてインデックスを作成して検索できるようにするPythonスクリプトです。すべてのアーカイブの現在のスナップショットには最大100万行があり、データベースにロードした後、テーブルは約9.5GBになります(インデックスは含まれません)。
クエリに関しては、ランダムなクエリを生成できる可能性がありますが、それがどれほど現実的かはわかりません。幸いなことに、数年前、PostgreSQL Webサイトから33kの実際の検索のサンプルを入手しました(つまり、人々がコミュニティアーカイブで実際に検索したもの)。これ以上現実的で代表的なものを手に入れることはできないでしょう。
これらの2つの部分(データセット+クエリ)の組み合わせは、優れたベンチマークのようです。データを読み込むだけで、さまざまな種類のインデックスを使用したさまざまな種類のフルテキストクエリで検索を実行できます。
クエリ
フルテキストクエリにはさまざまな形があります。クエリは、一致するすべての行を選択するだけで、結果をランク付け(関連性で並べ替え)、少数または最も関連性の高い結果を返すなど、さまざまな形でベンチマークを実行しました。クエリの種類ですが、この投稿では、全体的な動作を非常にうまく表現していると思われる2つの単純なクエリの結果を示します。
- SELECT id、件名FROMメッセージWHERE body_tsvector @@ $ 1
- SELECT id、件名FROMメッセージWHERE body_tsvector @@ $ 1
ORDER BY ts_rank(body_tsvector、$ 1)DESC LIMIT 100
最初のクエリは一致するすべての行を返すだけですが、2番目のクエリは最も関連性の高い100個の結果を返します(これはおそらくユーザー検索に使用するものです)。
他のさまざまなタイプのクエリを試しましたが、最終的には、これら2つのクエリタイプのいずれかと同じように動作しました。
インデックス
各メッセージには、検索できる2つの主要な部分(件名と本文)があります。それぞれに個別のtsvector列があり、個別にインデックスが付けられます。メッセージの件名は本文よりもはるかに短いため、インデックスは当然小さくなります。
PostgreSQLには、全文検索に役立つ2種類のインデックス(GINとGiST)があります。主な違いはドキュメントで説明されていますが、簡単に言うと:
- GINインデックスは検索が高速です
- GiSTインデックスは不可逆です。つまり、検索中に再チェックが必要です(したがって、処理が遅くなります)
以前は、GiSTインデックスの更新は(特に多くの同時セッションで)安価であると主張していましたが、インデックスコードの改善により、これはしばらく前にドキュメントから削除されました。
このベンチマークは、更新による動作をテストしません。フルテキストインデックスなしでテーブルをロードし、一度にビルドしてから、データに対して33kクエリを実行します。つまり、これらのインデックスタイプがこのベンチマークに基づいて同時更新を処理する方法については何も言えませんが、ドキュメントの変更は最近のさまざまなGINの改善を反映していると思います。
これは、メーリングリストアーカイブのユースケースとも非常によく一致するはずです。このユースケースでは、たまに新しいメールを追加するだけです(更新はほとんどなく、書き込みの同時実行性はほとんどありません)。ただし、アプリケーションが多数の同時更新を行う場合は、それを自分でベンチマークする必要があります。
ハードウェア
以前と同じ2台のマシンでベンチマークを実行しましたが、結果/結論はほぼ同じであるため、小さい方の数値のみを示します。つまり、
- CPU i5-2500K(4コア/スレッド)
- 8GB RAM
- 6 x 100GB SSD RAID0
- カーネル5.6.15、ext4ファイルシステム
データセットの読み込み時の容量は約10GBであるため、RAMよりも大きくなります。ただし、インデックスはまだRAMよりも小さいため、ベンチマークにとって重要です。
結果
OK、いくつかの数字とチャートの時間です。最初にGINを使用し、次にGiSTインデックスを使用して、データの読み込みとクエリの両方の結果を示します。
GIN/データロード
負荷は特に面白くないと思います。まず、そのほとんど(青い部分)はフルテキストとは関係ありません。これは、2つのインデックスが作成される前に発生するためです。この時間のほとんどは、メッセージの解析、メールスレッドの再構築、返信のリストの維持などに費やされます。このコードの一部はPL/pgSQLトリガーに実装されており、一部はデータベースの外部に実装されています。フルテキストに関連する可能性のある部分の1つは、tsvectorの作成ですが、それに費やされた時間を分離することは不可能です。
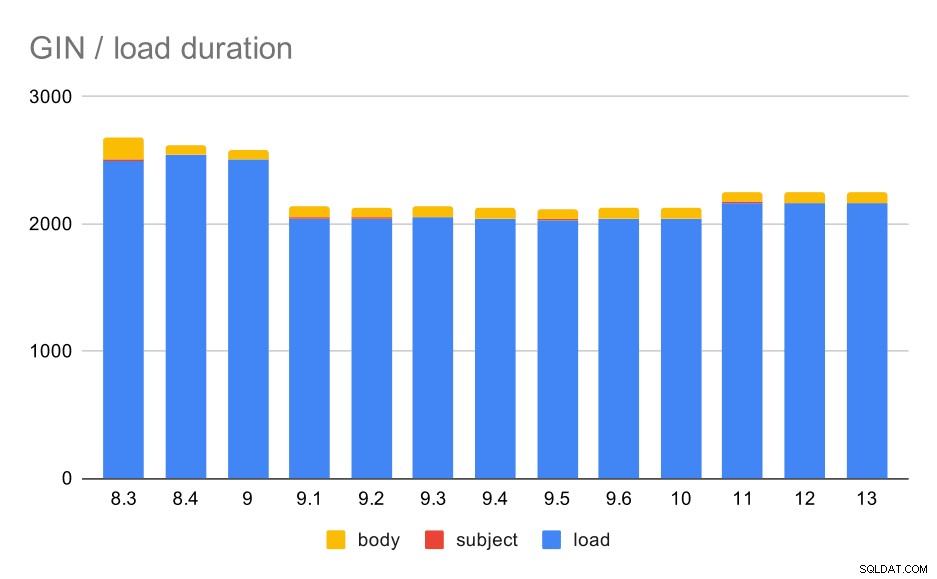
テーブルとGINインデックスを使用したデータロード操作。
次の表は、このグラフのソースデータを示しています。値は秒単位の期間です。 LOADには、(Pythonスクリプトからの)mboxアーカイブの解析、テーブルへの挿入、およびさまざまな追加タスク(電子メールスレッドの再構築など)が含まれます。 SUBJECT / BODY INDEXは、データがロードされた後、subject/body列にフルテキストGINインデックスを作成することを指します。
| LOAD | SUBJECT INDEX | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
明らかに、パフォーマンスはかなり安定しています。9.0と9.1の間でかなり大幅な改善(約20%)がありました。どの変更がこの改善の原因であるかはよくわかりません。9.1リリースノートには明確に関連するものはないようです。 8.4ではGINインデックスの作成も明らかに改善されており、時間が約半分に短縮されています。もちろん、これは素晴らしいことです。興味深いことに、これに明らかに関連するリリースノートの項目もありません。
しかし、GINインデックスのサイズはどうですか?少なくとも9.4までは、さらに多くの変動性があります。その時点で、インデックスのサイズは約1GBからわずか約670MB(約30%)に減少します。
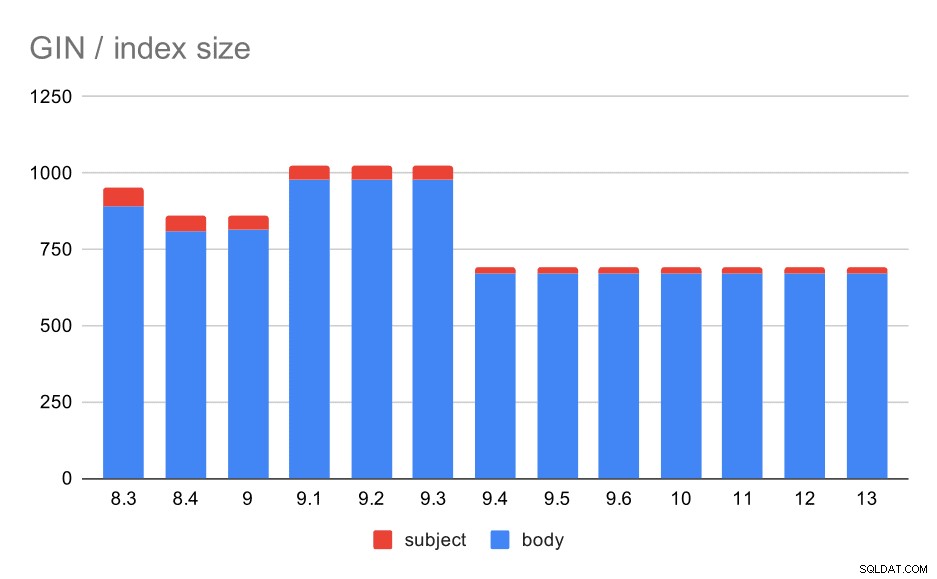
メッセージの件名/本文のGINインデックスのサイズ。値はメガバイトです。
次の表は、メッセージ本文と件名のGINインデックスのサイズを示しています。値はメガバイト単位です。
| BODY | SUBJECT | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
この場合、このスピードアップは9.4リリースノートのこのアイテムに関連していると安全に推測できます:
- GINインデックスサイズを縮小する(Alexander Korotkov、Heikki Linnakangas)
8.3と9.1の間のサイズのばらつきは、レンマ化(単語が「基本」形式に変換される方法)の変更によるものと思われます。サイズの違いは別として、たとえば、これらのバージョンのクエリはわずかに異なる数の結果を返します。
GIN/クエリ
さて、このベンチマークの主要部分–クエリのパフォーマンス。ここに示されている数値はすべて単一のクライアントに関するものです。OLTPのパフォーマンスに関連する部分でクライアントのスケーラビリティについてはすでに説明しましたが、調査結果はこれらのクエリにも当てはまります。 (さらに、この特定のマシンには4つのコアしかないため、スケーラビリティテストに関してはそれほど遠くはありません。)
SELECT id、件名FROMメッセージWHERE tsvector @@ $ 1
まず、一致するすべてのドキュメントを検索するクエリ。 「件名」列の検索では、1秒あたり約800クエリを実行できます(実際には9.1で少し低下します)が、9.4では突然1秒あたり最大3000クエリを実行します。 「本文」の列については、基本的に同じ話です。最初は160クエリ、9.1では最大90クエリに減少し、9.4では300クエリに増加します。
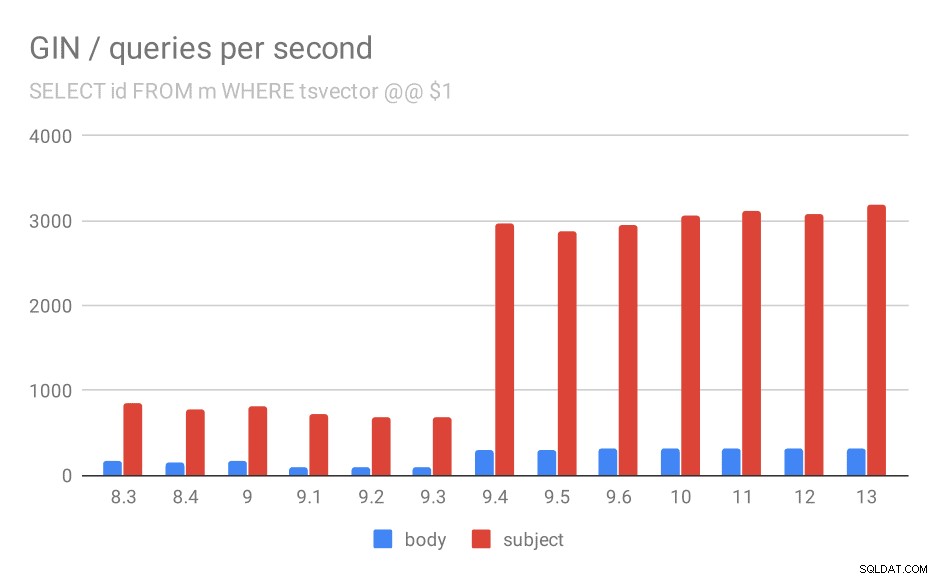
最初のクエリの1秒あたりのクエリ数(一致するすべての行をフェッチします)。
繰り返しになりますが、ソースデータ–数値はスループット(1秒あたりのクエリ数)です。
| BODY | SUBJECT | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
9.4での改善は、リリースノートのこの項目に関連していると安全に推測できます:
- マルチキーGINルックアップの速度を向上させる(Alexander Korotkov、Heikki Linnakangas)
したがって、同じ2人の開発者によるGINの別の9.4の改善–明らかに、AlexanderとHeikkiは、9.4リリースでGINインデックスに対して多くの優れた作業を行いました😉
SELECT id、件名FROMメッセージWHERE tsvector @@ $ 1
ORDER BY ts_rank(tsvector、$ 2)DESC LIMIT 100
ts_rankとLIMITを使用して関連性によって結果をランク付けするクエリの場合、全体的な動作はほぼ同じであり、グラフを詳細に説明する必要はないと思います。
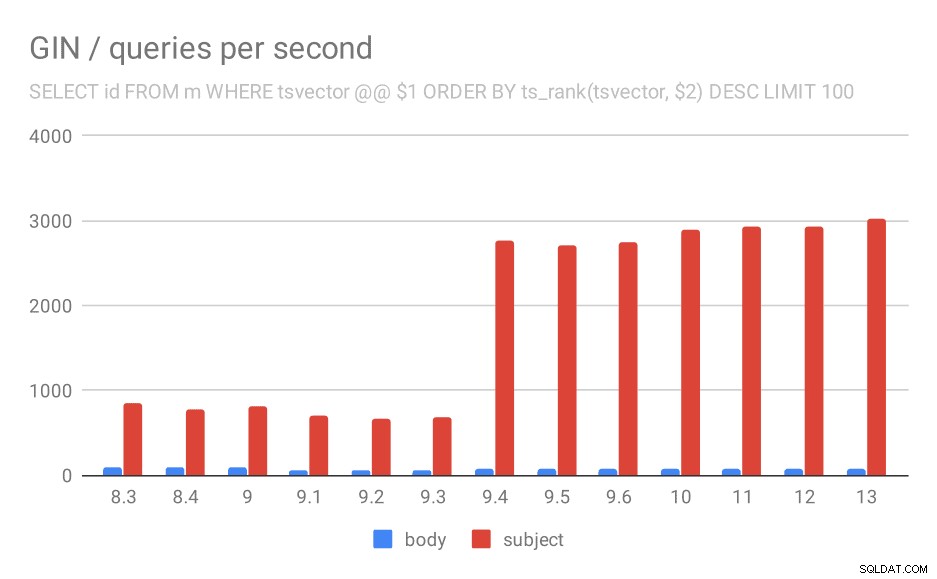
2番目のクエリ(最も関連性の高い行をフェッチする)の1秒あたりのクエリ数。
| BODY | SUBJECT | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
ただし、1つ質問があります。それは、なぜパフォーマンスが9.0と9.1の間で低下したのかということです。スループットはかなり大幅に低下しているようです。本文の検索では約50%、メッセージの件名での検索では20%です。何が起こったのか明確な説明はありませんが、2つの観察結果があります…
まず、インデックスサイズが変更されました。最初のグラフ「GIN /インデックスサイズ」と表を見ると、メッセージ本文のインデックスが813MBから約977MBに増加していることがわかります。これは大幅な増加であり、減速の一部を説明している可能性があります。ただし、問題は、サブジェクトのインデックスがまったく増加しなかったにもかかわらず、クエリも遅くなったということです。
次に、クエリが返した結果の数を確認できます。インデックス付けされたデータセットはまったく同じなので、すべてのPostgreSQLバージョンで同じ数の結果を期待するのは合理的ですよね?実際には、次のようになります。
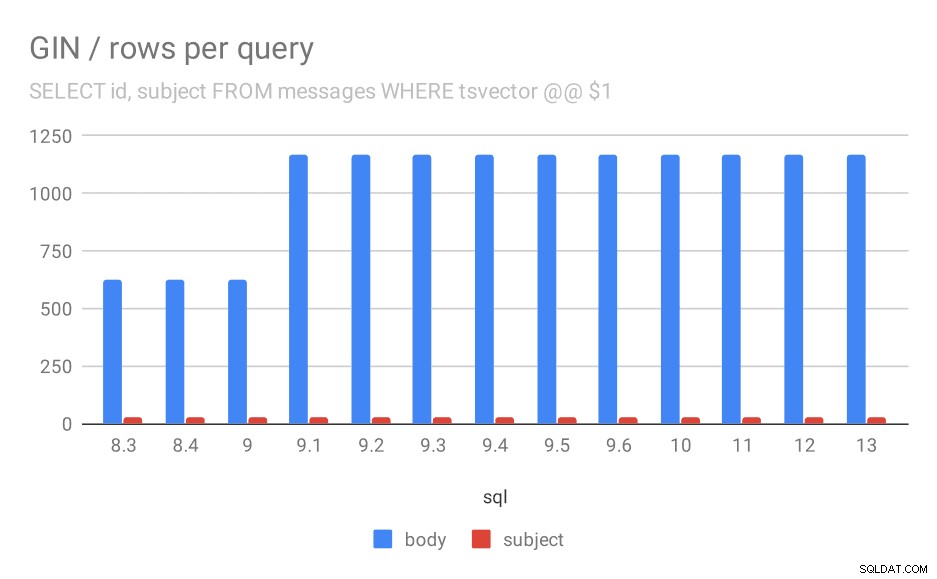
クエリに対して返された平均行数。
| BODY | SUBJECT | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
明らかに、9.1では、メッセージ本文での検索結果の平均数が突然2倍になります。これは、速度低下にほぼ完全に比例します。ただし、主題検索の結果の数は同じままです。より多くのメッセージを照合できるようにインデックスが変更されたが、少し遅くなったことを除いて、これについてはあまり良い説明がありません。もっと良い説明があれば聞きたいです!
GiST/データロード
現在、他のタイプのフルテキストインデックス–GiST。これらのインデックスは損失があります。つまり、テーブルの値を使用して結果を再チェックする必要があります。したがって、GINインデックスと比較してスループットは低くなると予想できますが、それ以外の場合は、ほぼ同じパターンを期待するのが妥当です。
ロード時間は実際にGINとほぼ完全に一致します。インデックスの作成時間は異なりますが、全体的なパターンは同じです。 9.1でスピードアップ、11で少しスローダウン。
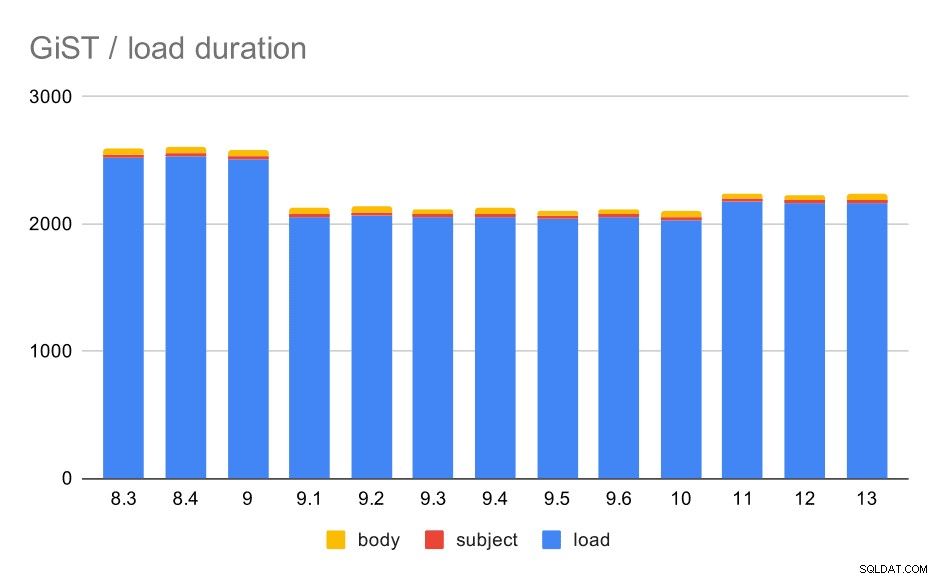
テーブルとGiSTインデックスを使用したデータロード操作。
| LOAD | SUBJECT | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
ただし、インデックスサイズはほぼ一定のままでした。9.4のGINと同様のGiSTの改善はなく、サイズが約30%減少しました。 9.1が増加しました。これは、そのバージョンでフルテキストインデックスが変更され、より多くの単語にインデックスが付けられたことを示すもう1つの兆候です。
これは、GiSTがGINの場合とまったく同じである(9.1の増加を伴う)結果の平均数によってさらにサポートされます。
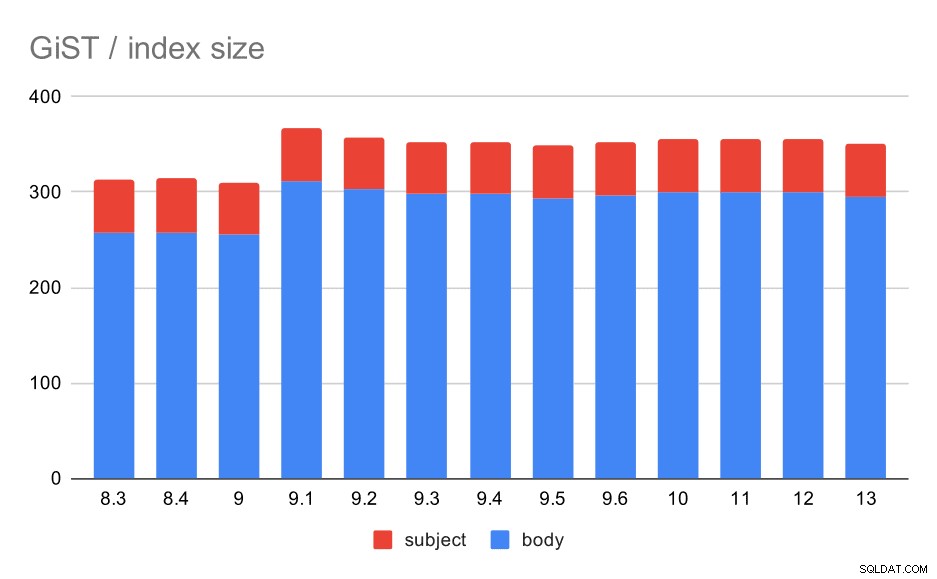
メッセージの件名/本文のGiSTインデックスのサイズ。値はメガバイトです。
| BODY | SUBJECT | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
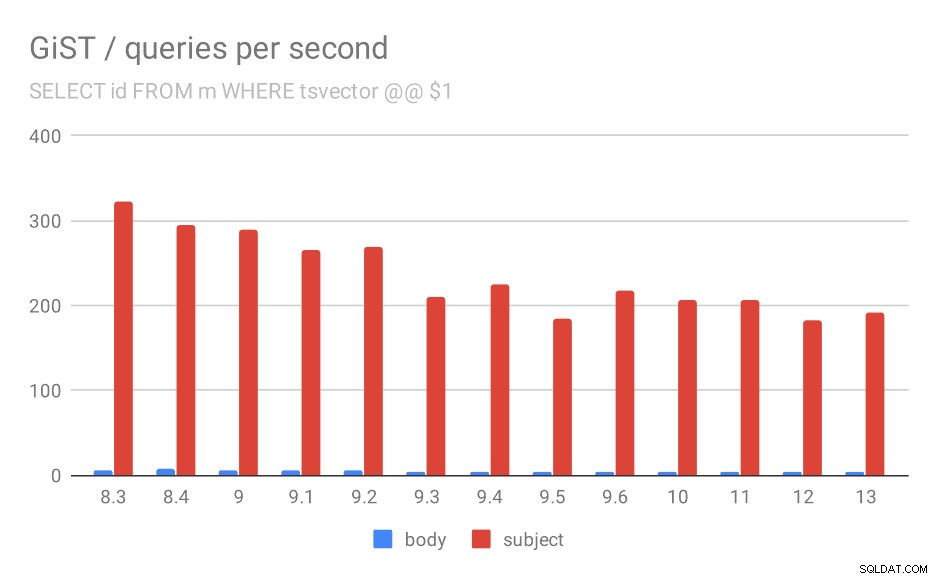
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
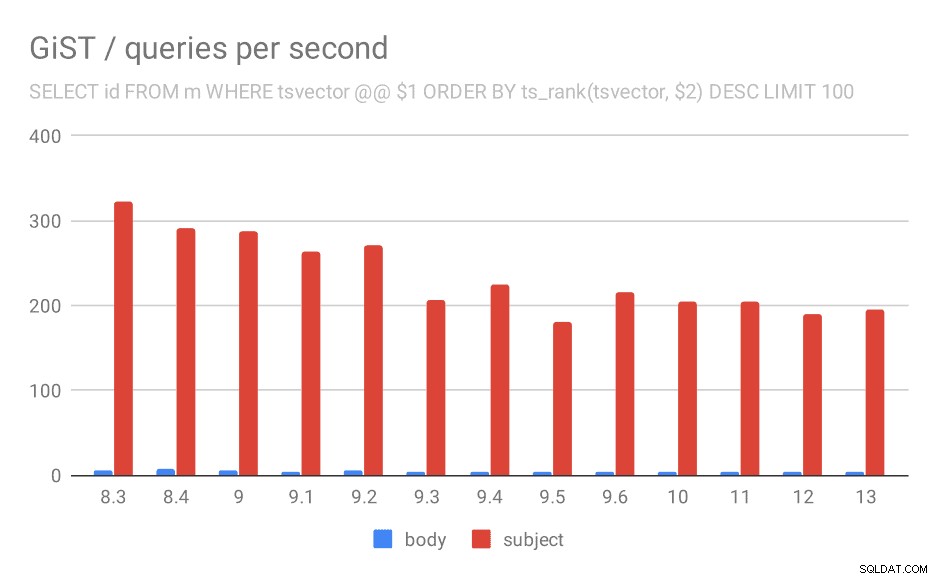
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).