前回のブログ投稿では、pglogicalアナウンスでパフォーマンス数値を公開する方法について簡単に説明しました。このブログ投稿では、一般的な論理レプリケーションソリューションのパフォーマンス制限と、それらがpglogicalにどのように適用されるかについて説明します。
物理レプリケーション
まず、物理レプリケーション(バージョン9.0以降のPostgreSQLに組み込まれている)がどのように機能するかを見てみましょう。 2つのノードが2つしかない、やや簡略化された図は次のようになります。
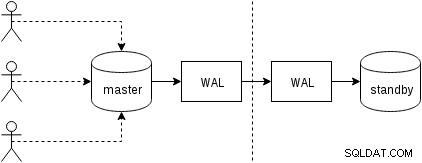
クライアントはマスターノードでクエリを実行し、変更はトランザクションログ(WAL)に書き込まれ、ネットワーク経由でスタンバイノードのWALにコピーされます。次に、スタンバイ上のスタンバイプロセスでのリカバリは、WALから変更を読み取り、リカバリ中と同じようにデータファイルに適用します。スタンバイが「hot_standby」モードの場合、これが発生している間、クライアントはノードで読み取り専用クエリを発行する可能性があります。
追加の処理がほとんどないため、これは非常に効率的です。変更は、不透明なバイナリブロブとしてスタンバイに転送および書き込まれます。もちろん、リカバリは(CPUとI / Oの両方の点で)無料ではありませんが、これよりも効率的にすることは困難です。
物理レプリケーションの明らかな潜在的なボトルネックは、ネットワーク帯域幅(マスターからスタンバイへのWALの転送)とスタンバイでのI / Oです。これは、多くの場合ランダムI / O要求を発行するリカバリプロセスによって飽和する可能性があります(マスターよりも多い場合もありますが、それには入りません。
論理レプリケーション
論理レプリケーションは、不透明なバイナリWALストリームを処理しないため、もう少し複雑ですが、「論理」変更のストリーム(INSERT、UPDATE、またはDELETEステートメントを想像してください。ただし、データ)。論理的な変更を行うことで、競合の解決、選択したテーブルのみの複製、異なるスキーマ間、または異なるバージョン間(または異なるデータベース間)などの興味深い処理を実行できます。
変更を取得するにはさまざまな方法があります。従来のアプローチでは、トリガーを使用して変更をテーブルに記録し、カスタムプロセスがそれらの変更を継続的に読み取り、SQLクエリを実行してスタンバイに適用します。そして、これはすべて、次の図に示すように、外部デーモンプロセス(または場合によっては両方のノードで実行されている複数のプロセス)によって駆動されます

これはslonyまたはlondisteが行うことであり、非常にうまく機能しますが、多くのオーバーヘッドを意味します。たとえば、データの変更をキャプチャし、データを複数回(元のテーブルと「ログ」テーブルに)書き込む必要があります。これらの両方のテーブルのWALにも)。他のオーバーヘッドの原因については後で説明します。 pglogicalは同じ目標を達成する必要がありますが、最近のPostgreSQLバージョンに追加されたいくつかの機能のおかげで(他のツールが実装されたときには利用できませんでした)、異なる方法で達成します。

つまり、変更の個別のログを維持する代わりに、pglogicalはWALに依存します。これはPostgreSQL 9.4で利用可能な論理デコードのおかげで可能であり、WALログから論理変更を抽出できます。このおかげで、pglogicalは高価なトリガーを必要とせず、通常、マスターにデータを2回書き込むことを回避できます(ディスクに流出する可能性のある大規模なトランザクションを除く)。
各トランザクションをデコードした後、それはスタンバイに転送され、適用プロセスはその変更をスタンバイデータベースに適用します。 pglogicalは、通常のSQLクエリを実行することによって変更を適用しませんが、より低いレベルでは、SQLクエリの解析と計画に関連するオーバーヘッドをバイパスします。これにより、すべてがSQLレイヤーを通過する既存のソリューションに比べてpglogicalに大きな利点があります(したがって、解析と計画に費用がかかります)。
潜在的なボトルネック
明らかに、論理レプリケーションは物理レプリケーションと同じボトルネックの影響を受けやすくなっています。つまり、変更を転送するときにネットワークが飽和状態になり、スタンバイに適用するときにスタンバイのI/Oが飽和する可能性があります。物理レプリケーションには存在しない追加の手順のため、かなりのオーバーヘッドもあります。
物理レプリケーションは単にWALをバイトのストリームとして転送するのに対し、論理的な変更を何らかの方法で収集する必要があります。すでに述べたように、既存のソリューションは通常、「ログ」テーブルに変更を書き込むトリガーに依存しています。 pglogicalは、代わりに先行書き込みログ(WAL)と論理デコードに依存して同じことを実現します。これは、トリガーよりも安価であり、ほとんどの場合、データを2回書き込む必要もありません(変更を自動的に適用するという追加のボーナスがあります)。コミット順)。
これは、追加の改善の機会がないということではありません。たとえば、現在、デコードはトランザクションがコミットされた後にのみ行われるため、トランザクションが大きい場合、レプリケーションの遅延が大きくなる可能性があります。物理レプリケーションは、WALの変更を他のノードにストリーミングするだけなので、この制限はありません。大規模なトランザクションもディスクに流出し、重複書き込みが発生する可能性があります。これは、アップストリームがコミットするまでトランザクションを保存する必要があり、ダウンストリームに送信できるためです。
今後の作業では、pglogicalがアップストリームで進行中の大規模なトランザクションのストリーミングを開始できるようにすることで、アップストリームコミットとダウンストリームコミット間のレイテンシを削減し、アップストリーム書き込みの増幅を削減する予定です。
変更がスタンバイに転送された後、適用プロセスは実際に何らかの方法で変更を適用する必要があります。前のセクションで述べたように、既存のソリューションはSQLコマンドを作成して実行することでそれを実現しましたが、pglogicalはSQLレイヤーと関連するオーバーヘッドを完全にバイパスします。
それでも、主キールックアップ、インデックスの更新、トリガーの実行、その他のさまざまなチェックなどを実行する必要があるため、適用が完全に無料になるわけではありません。ただし、SQLベースのアプローチよりも大幅に安価です。ある意味では、COPYと非常によく似ており、トリガーや外部キーなどのない単純なテーブルで特に高速です。
すべての論理レプリケーションソリューションでは、これらの各ステップ(デコードと適用)が単一のプロセスで実行されるため、CPU時間はかなり制限されます。これは、既存のすべてのソリューションの中でおそらく最も差し迫ったボトルネックです。数十または数百のクライアントがクエリを並行して実行している非常に強力なマシンを使用している可能性がありますが、それらすべてを単一のプロセスで実行して、これらの変更をデコードする必要があります(マスター)およびそれらの変更を適用する1つのプロセス(スタンバイ上)。
「単一プロセス」の制限は、各データベースが個別のプロセスによって処理されるため、個別のデータベースを使用することで多少緩和される場合があります。単一のデータベースに関しては、このボトルネックを軽減するために、バックグラウンドワーカーのプールを介して適用を並列化する将来の作業が計画されています。