以前のブログでお気づきかもしれませんが、ここ数か月は、PostgreSQLの最新の9.5リリースでPostgres-XLを最新の状態にするのに忙しかったです。適度に安定したバージョンのPostgres-XL9.5を入手したら、この新しいバージョンのPostgres-XLのパフォーマンスを測定することに注意を向けました。ベンチマークの選択は、助成金契約318633に基づいて欧州連合が資金提供したAXLEプロジェクトの進行中の作業に大きく影響されます。このプロジェクトで行われた他のすべての作業のパフォーマンスを測定するために、TPCBENCHMARK™Hを使用しているため、 Postgres-XLの評価にも同じベンチマークを使用します。 TPC-HはOLAPワークロードを測定しようとするため、Postgres-XLにも適しています。Postgres-XLでうまくいくはずです。
1。 Postgres-XLクラスターのセットアップ
ベンチマークが決定されると、もう1つの大きな課題は、テストに適したリソースを見つけることでした。物理マシンの大規模なクラスターにアクセスできませんでした。だから私たちはほとんどがすることをしました。 Postgres-XLクラスターのセットアップにはAmazonAWSを使用することにしました。 AWSは幅広いインスタンスを提供しており、インスタンスタイプごとに異なるコンピューティングまたはIOパワーを提供しています。
AWSのこのページには、利用可能なさまざまなインスタンスタイプ、利用可能なリソース、およびさまざまなリージョンの料金が表示されます。価格と在庫状況は地域によって異なる場合があるため、すべての地域を確認することが重要です。 Postgres-XLはコンポーネント間で低レイテンシと高スループットを必要とするため、同じリージョン内のすべてのインスタンスをインスタンス化することも重要です。 3TB TPC-Hでは、i2.xlargeAWSインスタンスの16データノードクラスターを使用することにしました。これらのインスタンスには、それぞれ4つのvCPU、30 GBのRAM、800 GBのSSDがあり、すべての分散テーブル、レプリケートされたテーブル(クラスターのサイズが大きくなるにつれてより多くのスペースを必要とします)、それらのインデックスを保持し、十分な空きスペースを残すのに十分なストレージがあります。 CREATEINDEXおよびその他のクエリ用の一時テーブルスペースにあります。
2。ベンチマークの設定
2.1TPCBenchmark™H
ベンチマークには、大量のデータを調べ、高度に複雑なクエリを実行し、重要なビジネス上の質問に回答することを目的とした22のクエリが含まれています。完全なTPCBenchmark™H仕様は、負荷、電力、スループットなどのさまざまなテストを扱っていることに注意してください テスト。テストでは、個々のクエリのみを実行し、完全なテストスイートは実行していません。 TPCBenchmark™Hは、複雑なビジネス分析アプリケーションを代表する方法でシステム機能を実行するように設計された一連のビジネスクエリで構成されています。これらのクエリには現実的なコンテキストが与えられており、読者がベンチマークのコンポーネントに直感的に関連付けられるように、卸売業者の活動を描写しています。
2.2データベースのエンティティ、関係、および特性
TPC-Hデータベースのコンポーネントは、8つの個別のテーブル(ベーステーブル)で構成されるように定義されています。これらのテーブルの列間の関係を次の図に示します。 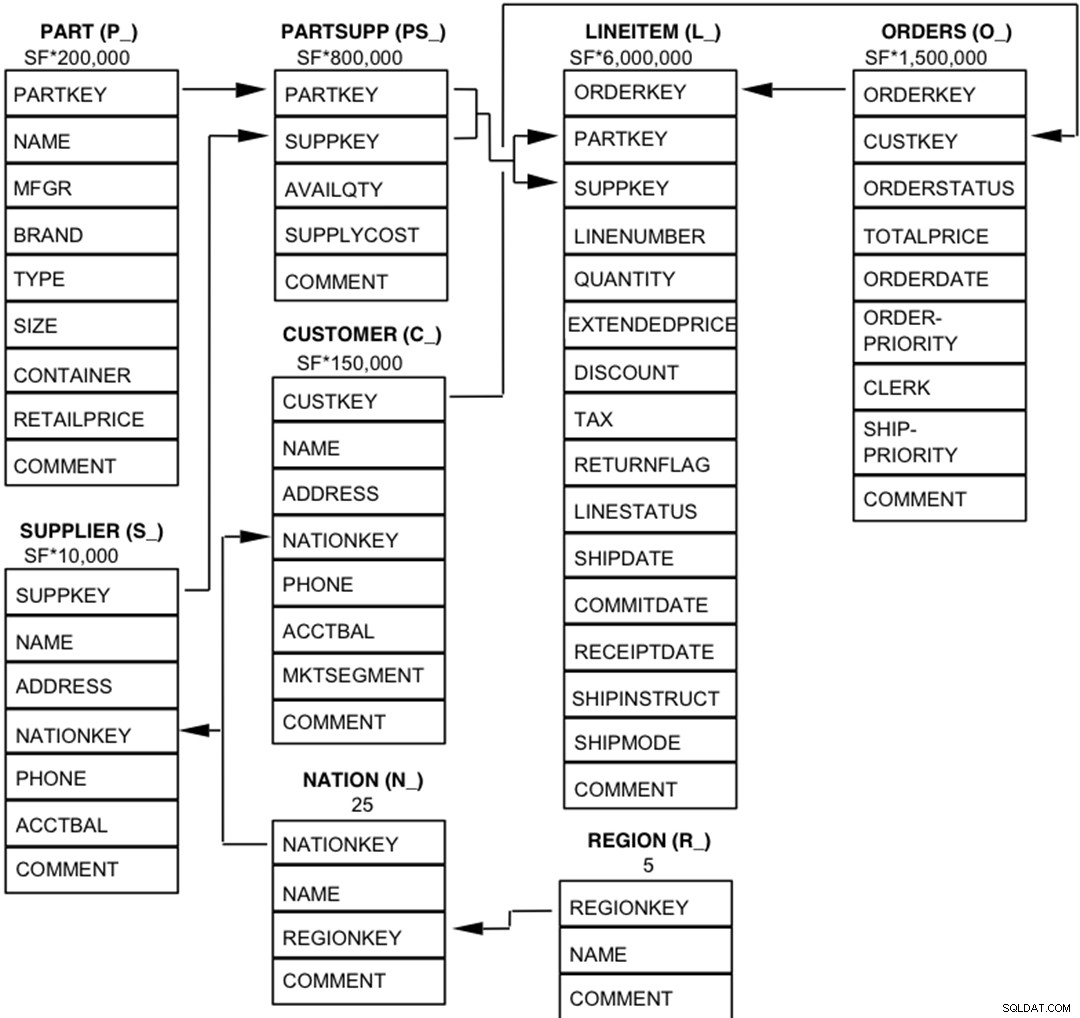 凡例 :
凡例 :
-
- 各テーブル名に続く括弧には、そのテーブルの列名のプレフィックスが含まれています;
-
- 矢印は、テーブル間の1対多の関係の方向を指しています
- 各テーブル名の下の数値/式は、テーブルのカーディナリティ(行数)を表します。選択したデータベースサイズを取得するために、スケールファクターであるSFによってファクタリングされるものもあります。 LINEITEMテーブルのカーディナリティは概算です
2.3Postgres-XLのデータ配布
ベンチマークの22のクエリすべてを分析し、ベンチマークのさまざまなテーブルに対して次のデータ分散戦略を考え出しました。
| テーブル名 | 配布戦略 |
| LINEITEM | HASH(l_orderkey) |
| 注文 | HASH(o_orderkey) |
| PART | HASH(p_partkey) |
| PARTSUPP | HASH(ps_partkey) |
| 顧客 | 複製 |
| サプライヤー | 複製 |
| NATION | 複製 |
| 地域 | 複製 |
ベンチマークで最大のテーブルであるLINEITEMとORDERSは、多くの場合、ORDERKEYで結合されることに注意してください。したがって、これらのテーブルをORDERKEYに配置することは非常に理にかなっています。同様に、PARTとPARTSUPPはPARTKEYで頻繁に結合されるため、PARTKEY列に配置されます。残りのテーブルは、必要に応じてローカルで結合できるように複製されます。
3。ベンチマーク結果
3.1負荷テスト
PostgreSQL9.6で3TBTPC-H負荷テストを実行して得られた結果を、16ノードのPostgres-XLクラスターと比較しました。次のグラフは、Postgres-XLのパフォーマンス特性を示しています。
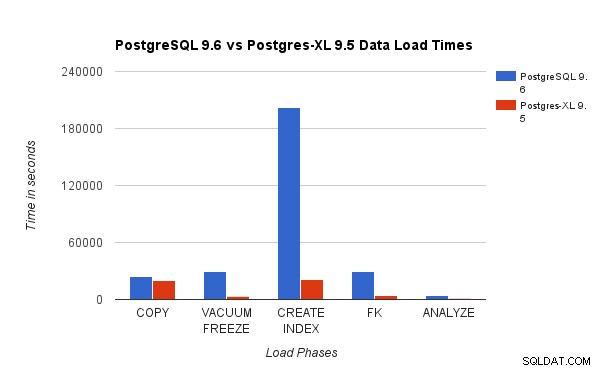 上のグラフは、PostgreSQLとPostgres-XLを使用した負荷テストのさまざまなフェーズを完了するのにかかる時間を示しています。ご覧のとおり、Postgres-XLはCOPYの方がわずかに優れており、他のすべての場合にははるかに優れています。 注 :特に複数のCOPYストリームが同時に実行されている場合、コーディネーターはCOPYフェーズ中に多くの計算能力を必要とすることがわかりました。これに対処するために、コーディネーターは16vCPUを備えたコンピューティング最適化AWSインスタンスで実行されました。または、複数のコーディネーターを実行して、それらの間で計算負荷を分散することもできます。
上のグラフは、PostgreSQLとPostgres-XLを使用した負荷テストのさまざまなフェーズを完了するのにかかる時間を示しています。ご覧のとおり、Postgres-XLはCOPYの方がわずかに優れており、他のすべての場合にははるかに優れています。 注 :特に複数のCOPYストリームが同時に実行されている場合、コーディネーターはCOPYフェーズ中に多くの計算能力を必要とすることがわかりました。これに対処するために、コーディネーターは16vCPUを備えたコンピューティング最適化AWSインスタンスで実行されました。または、複数のコーディネーターを実行して、それらの間で計算負荷を分散することもできます。
3.2電力テスト
また、PostgreSQL9.6とPostgres-XL9.5での3TBベンチマークのクエリ実行時間を比較しました。次のグラフは、2つの設定でのクエリ実行のパフォーマンス特性を示しています。
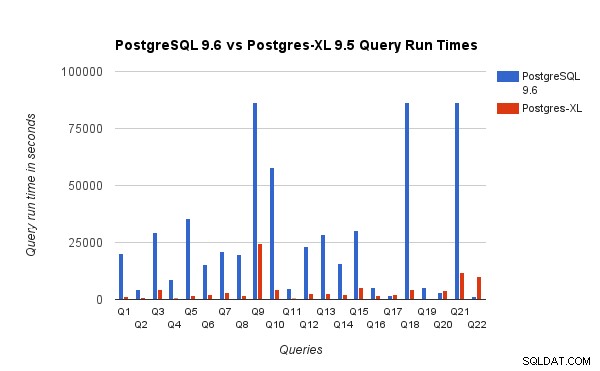 平均して、Postgres-XLではクエリの実行速度が約6.4倍、クエリの少なくとも25%であることがわかりました。パフォーマンスはほぼ直線的に向上しました。つまり、この16ノードのPostgres-XLクラスターでは16倍近くパフォーマンスが向上しました。さらに、クエリの少なくとも50%で、パフォーマンスが10倍向上しました。さらにクエリのパフォーマンスを分析し、利用可能なすべてのデータノード間で適切に分割されているクエリは、ノード間のデータ交換が最小限であり、リモート実行呼び出しを繰り返さなくても、Postgres-XLで非常に適切にスケーリングできると結論付けました。このようなクエリは通常、上部にリモートサブクエリスキャンノードがあり、ノードの下のサブツリーは1つ以上のノードで並行して実行されます。また、リモートサブクエリスキャンノードの上に制限ノードや集約ノードなどの他のノードがあることも一般的です。そのようなクエリでさえ、Postgres-XLで非常にうまく機能します。クエリQ1は、Postgres-XLで非常に適切に拡張できるクエリの例です。一方、datanode-datanodeおよび/またはcoordinator-datanode間でタプルの多くの交換を必要とするクエリは、Postgres-XLではうまく機能しない可能性があります。同様に、多くのノード間接続を必要とするクエリでも、パフォーマンスが低下する可能性があります。たとえば、単一ノードのPostgreSQLサーバーと比較してQ22のパフォーマンスが悪いことに気付くでしょう。 Q22のクエリプランを分析したところ、クエリプランには3つのレベルのネストされたリモートサブクエリスキャンノードがあり、各ノードがデータノードへの接続を同数開いていることがわかりました。さらに、Nest Loop Anti Joinは、トップレベルのリモートサブクエリスキャンノードと内部関係を持っているため、外部関係のすべてのタプルに対して、リモートサブクエリを実行する必要があります。これにより、クエリ実行のパフォーマンスが低下します。
平均して、Postgres-XLではクエリの実行速度が約6.4倍、クエリの少なくとも25%であることがわかりました。パフォーマンスはほぼ直線的に向上しました。つまり、この16ノードのPostgres-XLクラスターでは16倍近くパフォーマンスが向上しました。さらに、クエリの少なくとも50%で、パフォーマンスが10倍向上しました。さらにクエリのパフォーマンスを分析し、利用可能なすべてのデータノード間で適切に分割されているクエリは、ノード間のデータ交換が最小限であり、リモート実行呼び出しを繰り返さなくても、Postgres-XLで非常に適切にスケーリングできると結論付けました。このようなクエリは通常、上部にリモートサブクエリスキャンノードがあり、ノードの下のサブツリーは1つ以上のノードで並行して実行されます。また、リモートサブクエリスキャンノードの上に制限ノードや集約ノードなどの他のノードがあることも一般的です。そのようなクエリでさえ、Postgres-XLで非常にうまく機能します。クエリQ1は、Postgres-XLで非常に適切に拡張できるクエリの例です。一方、datanode-datanodeおよび/またはcoordinator-datanode間でタプルの多くの交換を必要とするクエリは、Postgres-XLではうまく機能しない可能性があります。同様に、多くのノード間接続を必要とするクエリでも、パフォーマンスが低下する可能性があります。たとえば、単一ノードのPostgreSQLサーバーと比較してQ22のパフォーマンスが悪いことに気付くでしょう。 Q22のクエリプランを分析したところ、クエリプランには3つのレベルのネストされたリモートサブクエリスキャンノードがあり、各ノードがデータノードへの接続を同数開いていることがわかりました。さらに、Nest Loop Anti Joinは、トップレベルのリモートサブクエリスキャンノードと内部関係を持っているため、外部関係のすべてのタプルに対して、リモートサブクエリを実行する必要があります。これにより、クエリ実行のパフォーマンスが低下します。
4。いくつかのAWSレッスン
Postgres-XLのベンチマークを行っている間、AWSの使用に関するいくつかのレッスンを学びました。 AWSでPostgres-XLを使用/テストしようとしている人には役立つと思いました。
- AWSは、いくつかの異なるタイプのインスタンスを提供しています。特定のインスタンスタイプを選択する前に、作業負荷と必要なストレージの量を慎重に評価する必要があります。
- ストレージが最適化されたインスタンスのほとんどには、エフェメラルディスクが接続されています。これらのディスクに追加料金を支払う必要はありません。これらのディスクはインスタンスに接続されており、多くの場合、EBSよりもパフォーマンスが優れています。ただし、それらを使用できるようにするには、それらを明示的にマウントする必要があります。ただし、これらのディスクに保存されているデータは永続的ではなく、インスタンスが停止すると消去されることに注意してください。したがって、その状況に対処する準備ができていることを確認してください。 AWSは主にベンチマークに使用していたため、これらのエフェメラルディスクを使用することにしました。
- EBSを使用している場合は、適切なプロビジョンドIOPSを選択してください。値が小さすぎるとIOが非常に遅くなりますが、値が大きすぎると、特に多数のノードを処理する場合にAWSの請求額が大幅に増える可能性があります。
- インスタンスを同じゾーンで開始して、レイテンシを減らし、インスタンス間の接続のスループットを向上させるようにしてください。
- プライベートネットワークを使用して相互に通信するようにインスタンスを構成してください。
- スポットインスタンスを見てください。彼らは比較的安いです。 AWSはスポットインスタンスを自由に終了する場合があるため、たとえば、スポット価格が最大入札価格を超えた場合は、それに備えてください。 Postgres-XLは、終了するノードに応じて、部分的または完全に使用できなくなる可能性があります。 AWSは、launch_groupの概念をサポートしています。 複数のインスタンスが同じlaunch_groupにグループ化されている場合、 AWSが1つのインスタンスを終了することを決定した場合、すべてのインスタンスが終了します。
5。結論
さまざまなベンチマークを通じて、Postgres-XLが実世界の複雑なクエリの大規模なセットに対して非常に適切に拡張できることを示すことができます。これらのベンチマークは、OLAPワークロードの効果的なソリューションとしてのPostgres-XLの機能を実証するのに役立ちます。私たちの実験では、特に非常に大規模なクラスターの場合や、プランナーがプランの選択を誤った場合に、Postgres-XLにいくつかのパフォーマンスの問題があることも示されています。また、データノードへの同時接続が非常に多い場合、パフォーマンスが低下することも確認しました。今後もこれらのパフォーマンス問題に取り組んでいきます。また、適切なワークロードを使用して、OLTPソリューションとしてのPostgres-XLの機能をテストしたいと思います。