この記事では、2UDAで機械学習機能を利用するためのステップバイステップガイドを提供します。この記事では、動物の例を使用して、動物が哺乳類、鳥、魚、昆虫のいずれであるかを予測します。
ソフトウェアバージョン
2UDAバージョン11.6-1を使用して、機械学習モデルを実装します。 2UDAバージョン11.6-1の組み合わせ:
- PostgreSQL 11.6
- オレンジ3.23.0
2UDAの最新バージョンはここにあります。
ステップ1:トレーニングデータセットをPostgreSQLにロードする
モデルのトレーニングに使用されるサンプルデータセットは、こちらの公式OrangeGitHubリポジトリで入手できます。
トレーニングデータをPostgreSQLテーブルにロードするには、次の手順に従います。
- psql、OmniDB、または使い慣れたその他のツールを介してPostgreSQLに接続します。
- トレーニングデータを保存するテーブルを作成します 。ここでは、training_dataという名前が付けられています。
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- COPYクエリを介してトレーニングデータをテーブルに挿入します。 COPYクエリを実行する前に、PostgreSQLにデータファイルの読み取り権限が必要であることを確認してください。そうでない場合、COPY操作は失敗します。
注: 必ずタブを入力してください 区切り文字の後の一重引用符の間のスペース キーワード。
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
以下のトレーニングデータセットのスクリーンショットをご覧ください
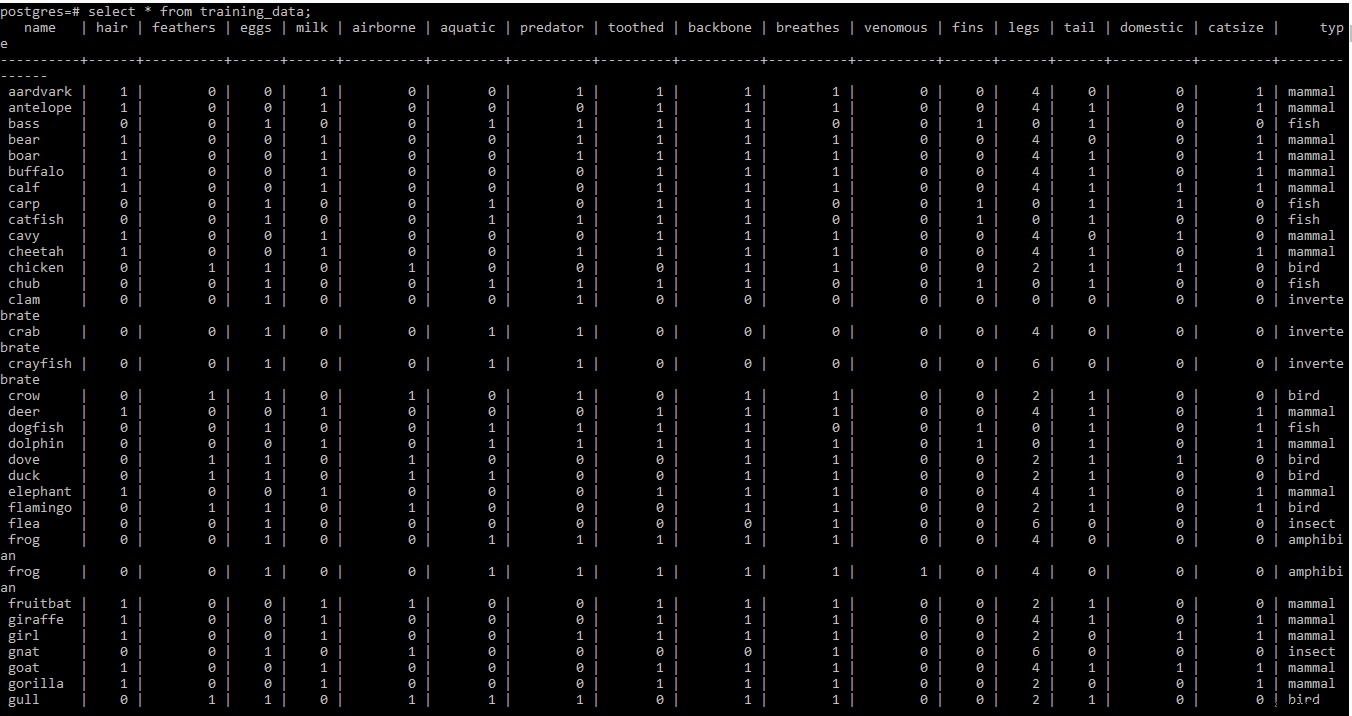
注: .tabのトレーニングデータセットの2行目と3行目 ファイルにはいくつかのメタ情報が含まれています。この時点では不要なため、ファイルから削除されました。
ステップ2:Orangeでワークフローを作成する
- デスクトップに移動し、オレンジ色のアイコンをダブルクリックします。
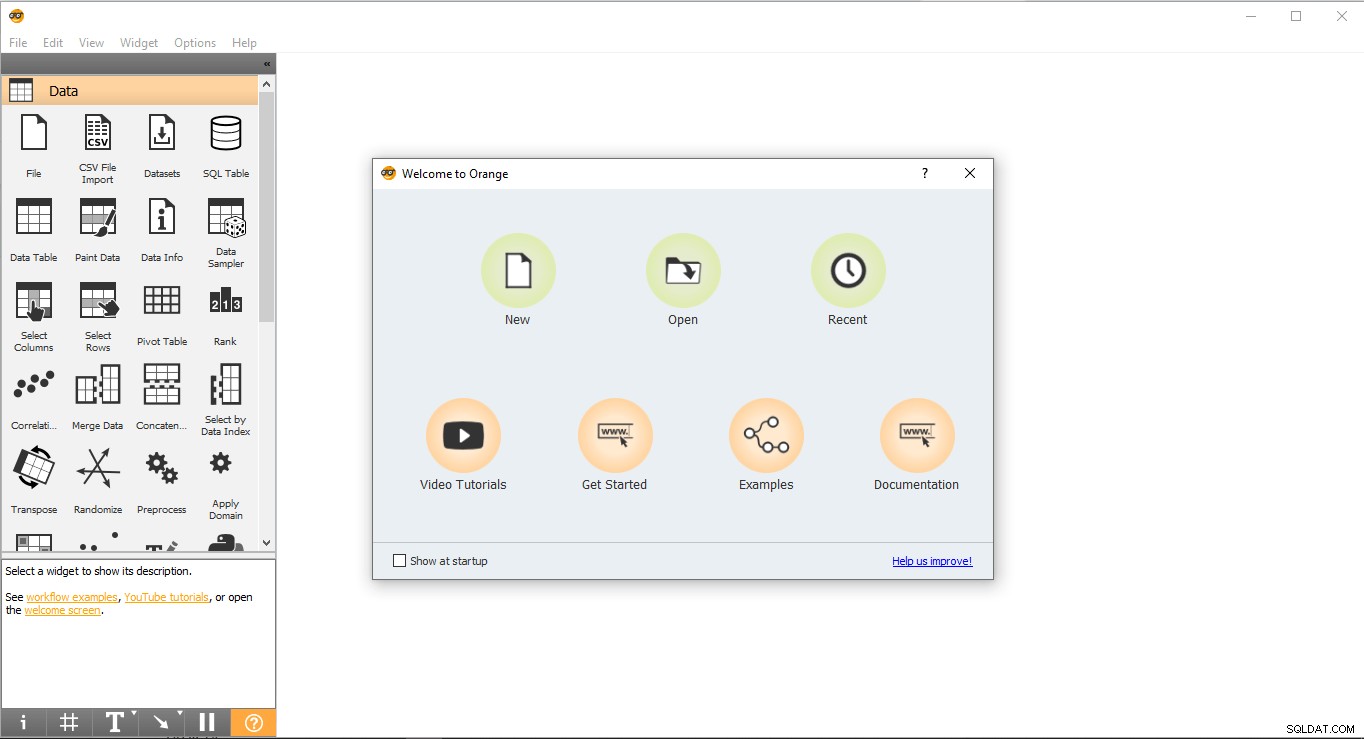
- これは、起動ページがどのように見えるかです。 新規を選択します オプションを選択すると、空白のプロジェクトが作成されます。

これで、データセットに機械学習モデルを適用する準備が整いました。
ステップ3:データをトレーニングするための機械学習モデルを選択します
この記事では、k最近傍 隣人 (KNN)機械学習モデルは、データのトレーニングに使用されます。データトレーニングプロセスが完了すると、次のステップでテストデータが予測に渡されます。 予測の正確さをチェックするウィジェット。
ステップ4:PostgreSQLからOrangeにトレーニングデータをインポートする
このトレーニングデータセットは、機械学習モデルのトレーニングに使用されます。
- SQLテーブルをドラッグアンドドロップします データのウィジェット メニュー。
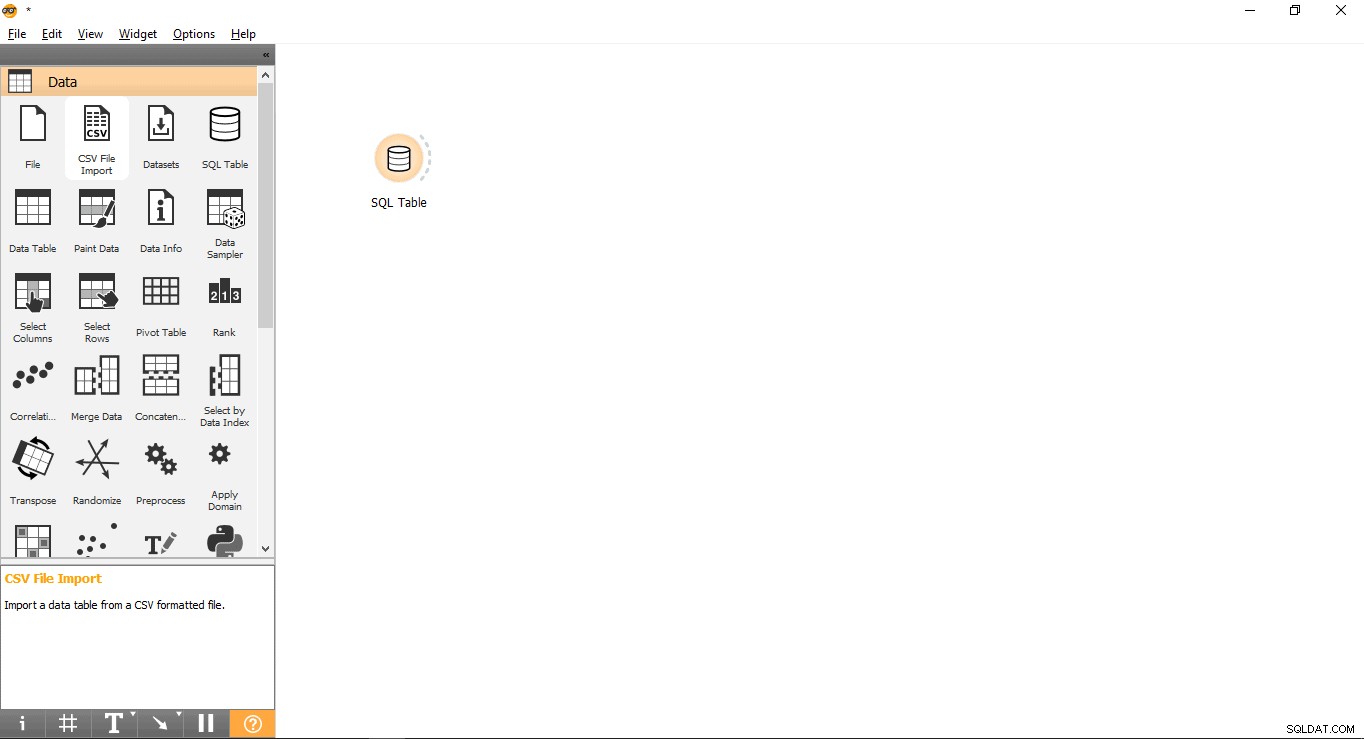
- ウィジェットの名前を変更する(オプション)
- SQLテーブルを右クリックします ウィジェット。
- 名前の変更を選択します 。
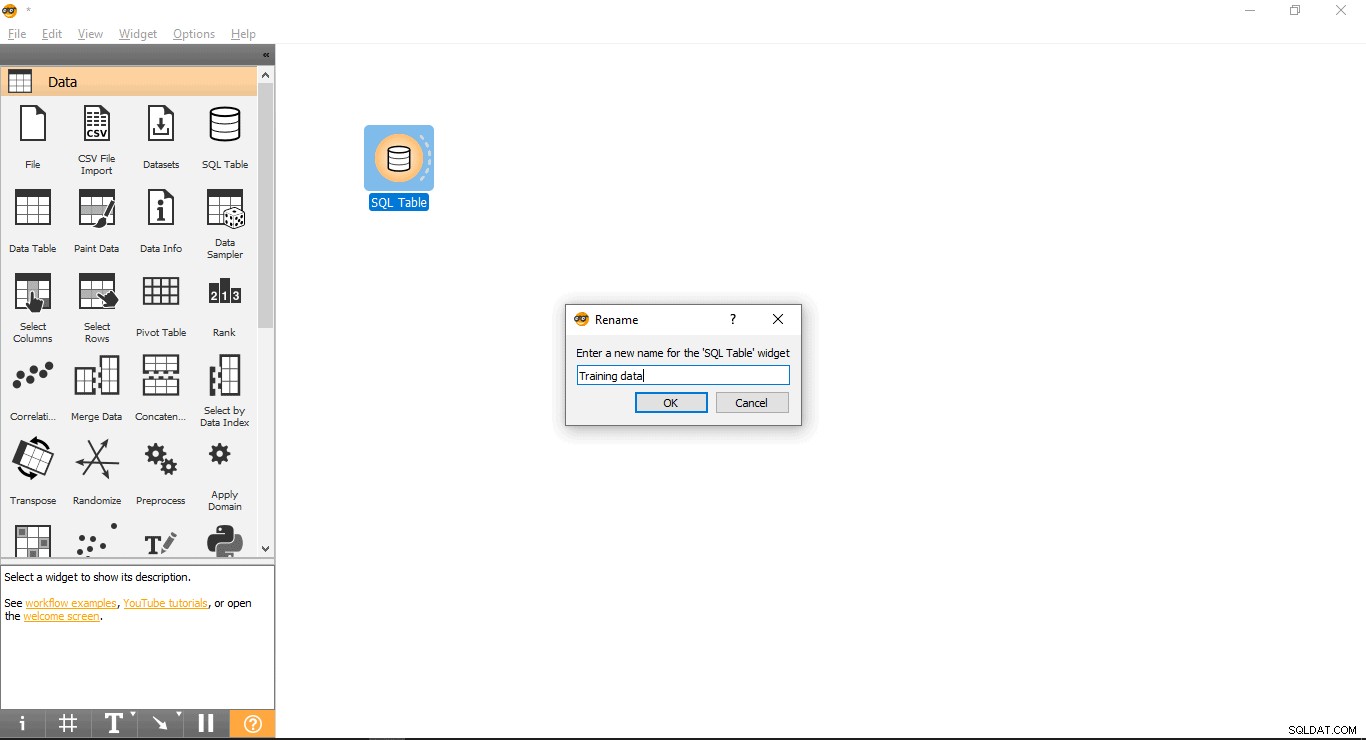
- PostgreSQLに接続して、トレーニングデータセットを読み込みます。
- トレーニングデータをダブルクリックします ウィジェット。
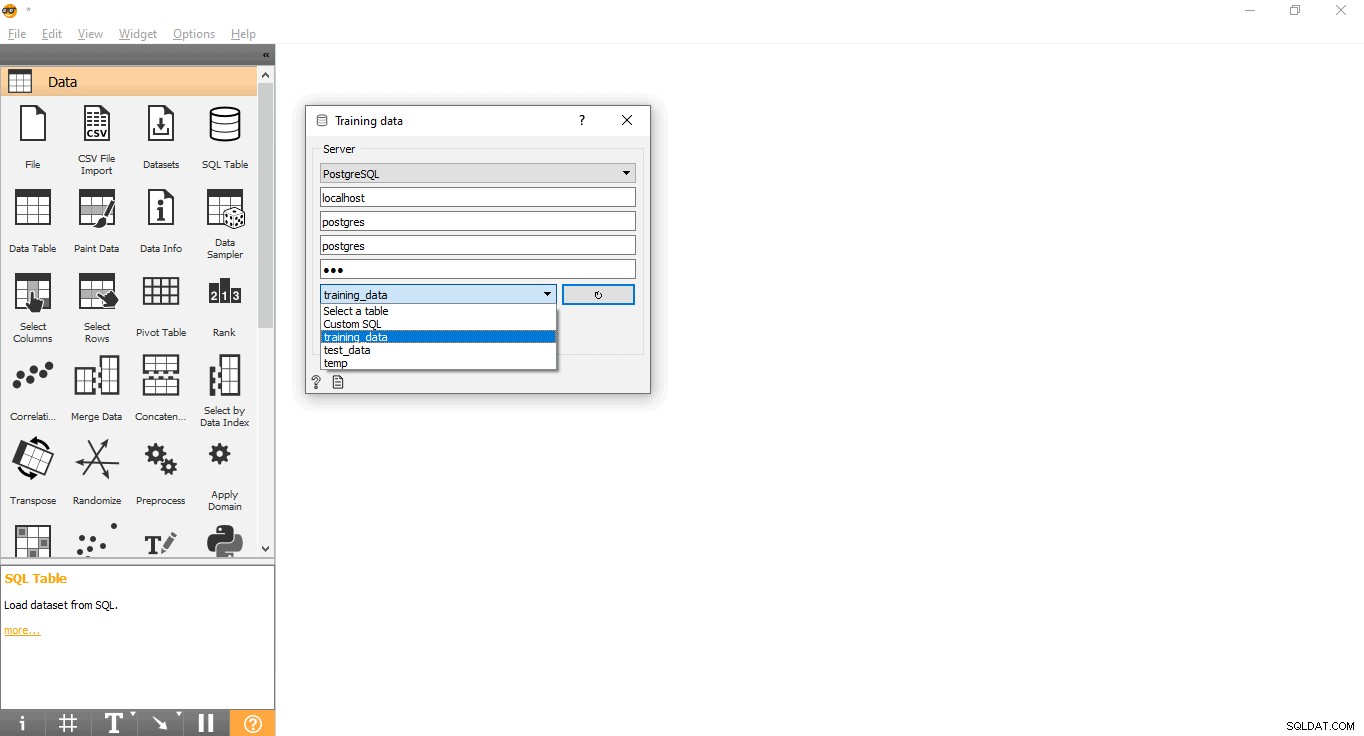
- PostgreSQLデータベースに接続するためのクレデンシャルを入力します。
- リロードボタンを押して、指定されたデータベースから使用可能なすべてのテーブルをロードします。
- ドロップダウンメニューからtraining_dataテーブルを選択し、ポップアップを閉じます。
ステップ5:ターゲット列を追加する
機械学習モデルはこのターゲット変数/列のデータを予測しようとするため、この手順は重要です。
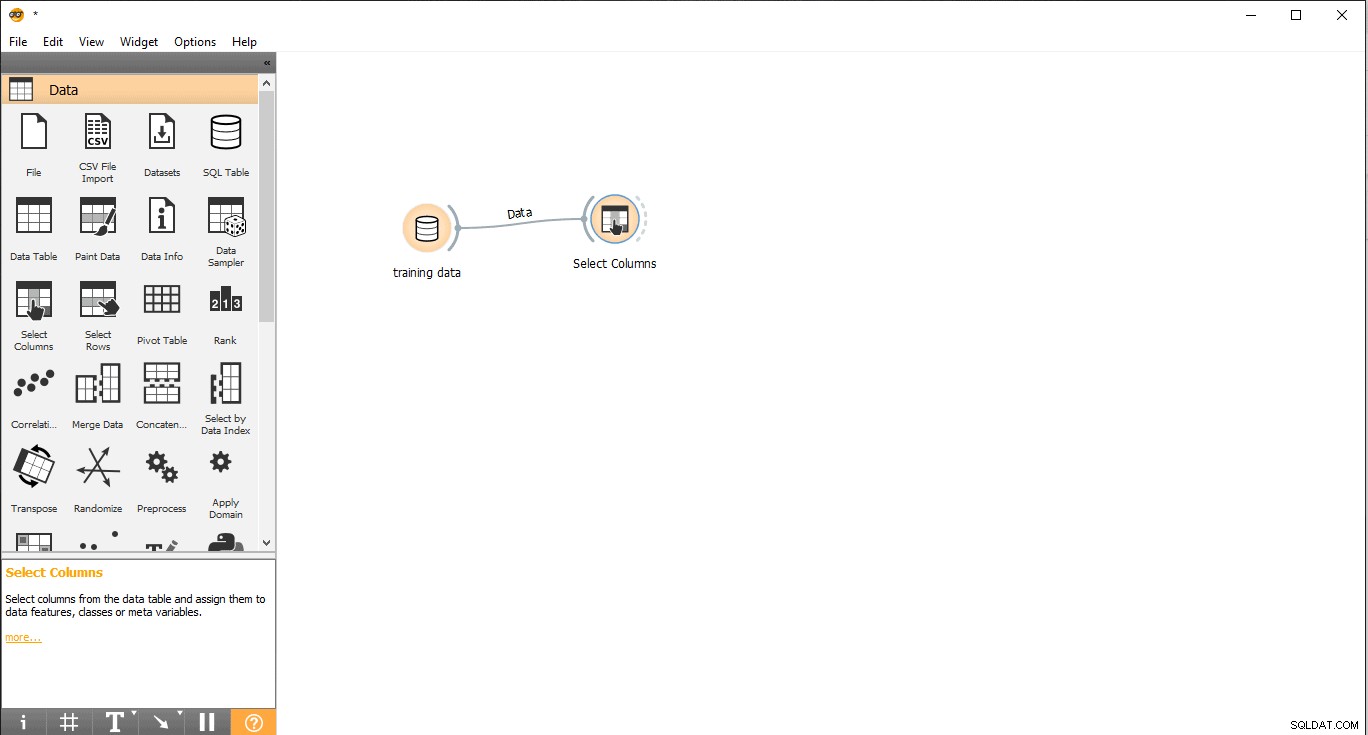
- ドラッグアンドドロップ列の選択 データからのウィジェット メニュー。
- 列の選択をダブルクリックします ウィジェット。
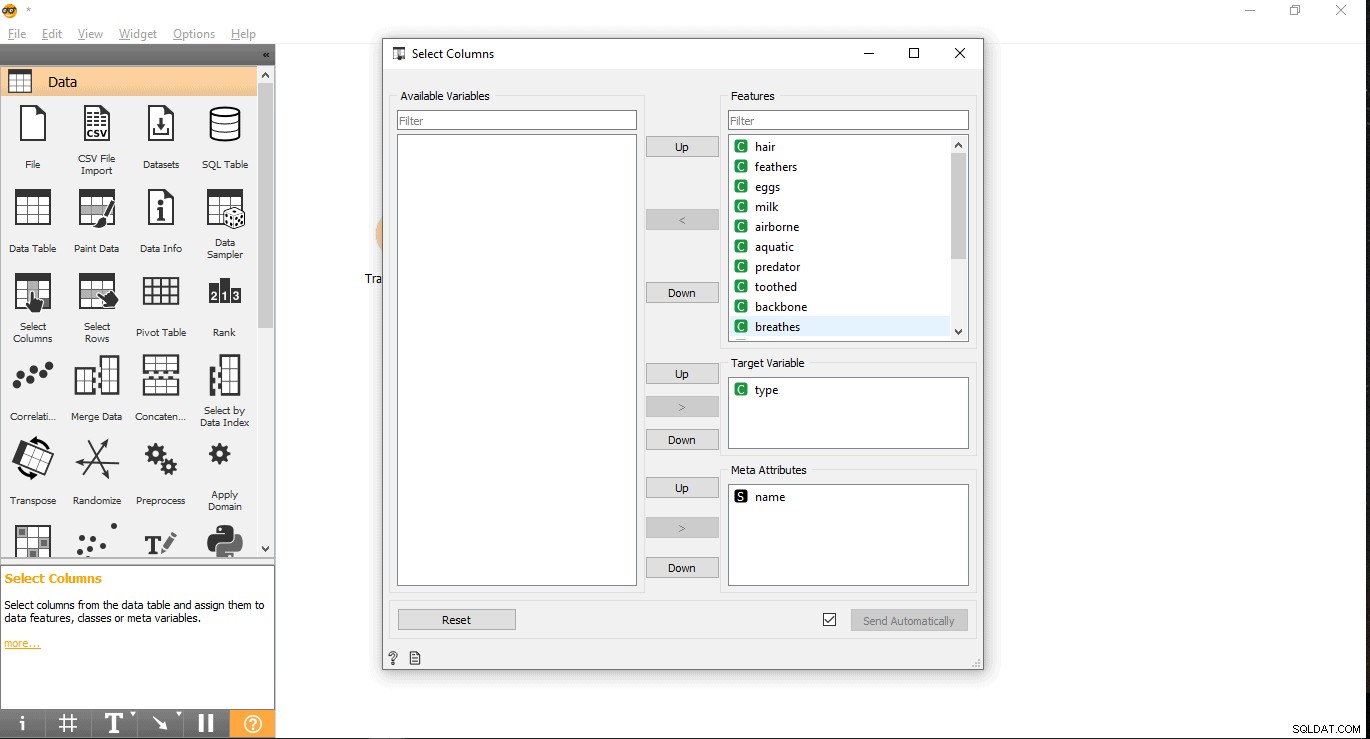
- 機能ラベルの下のターゲット列を検索します。ここでは、タイプが使用されます 特定の動物がどのタイプであるかを確認する必要があるため、ターゲット変数として使用します。
- ターゲット変数の下にドラッグアンドドロップします ボックスを開き、ポップアップを閉じます。
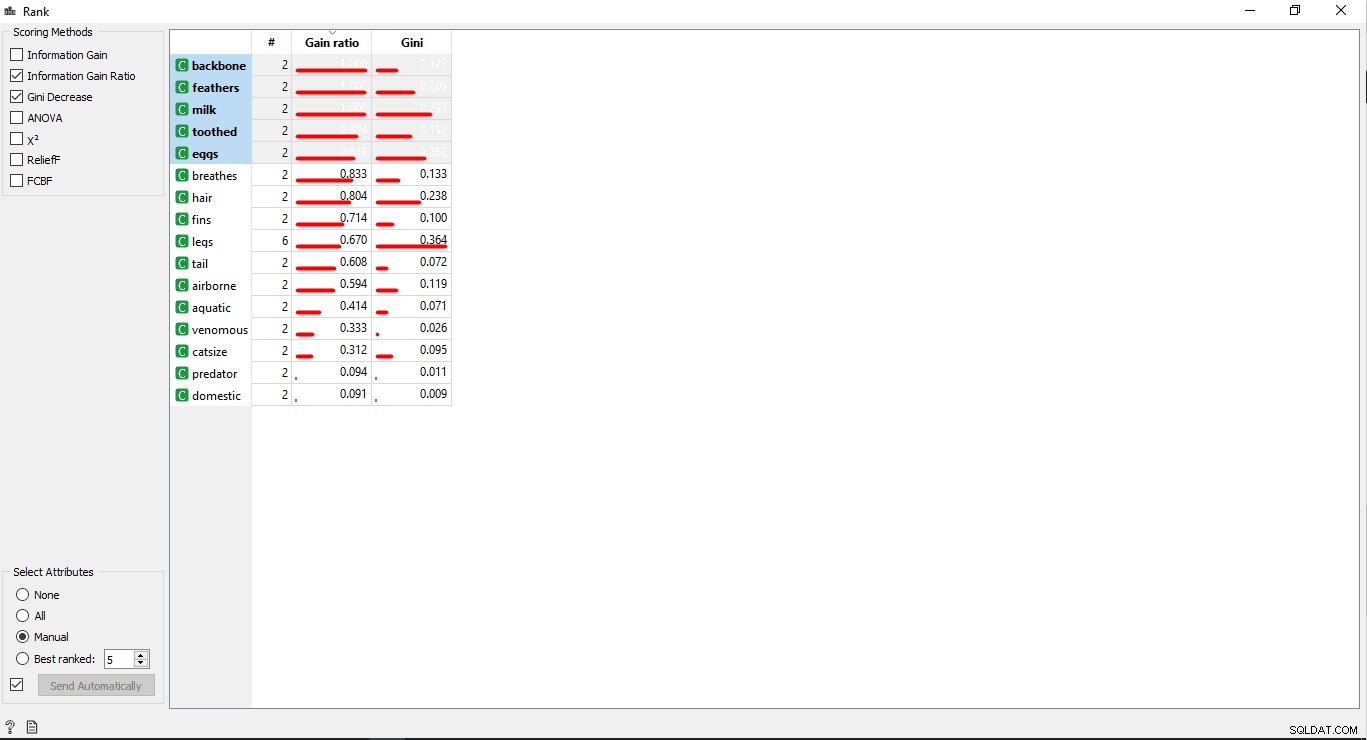
ステップ6:列のランキング
ターゲット列との相関関係に従って、トレーニング変数/列をランク付けまたはスコアリングできます。
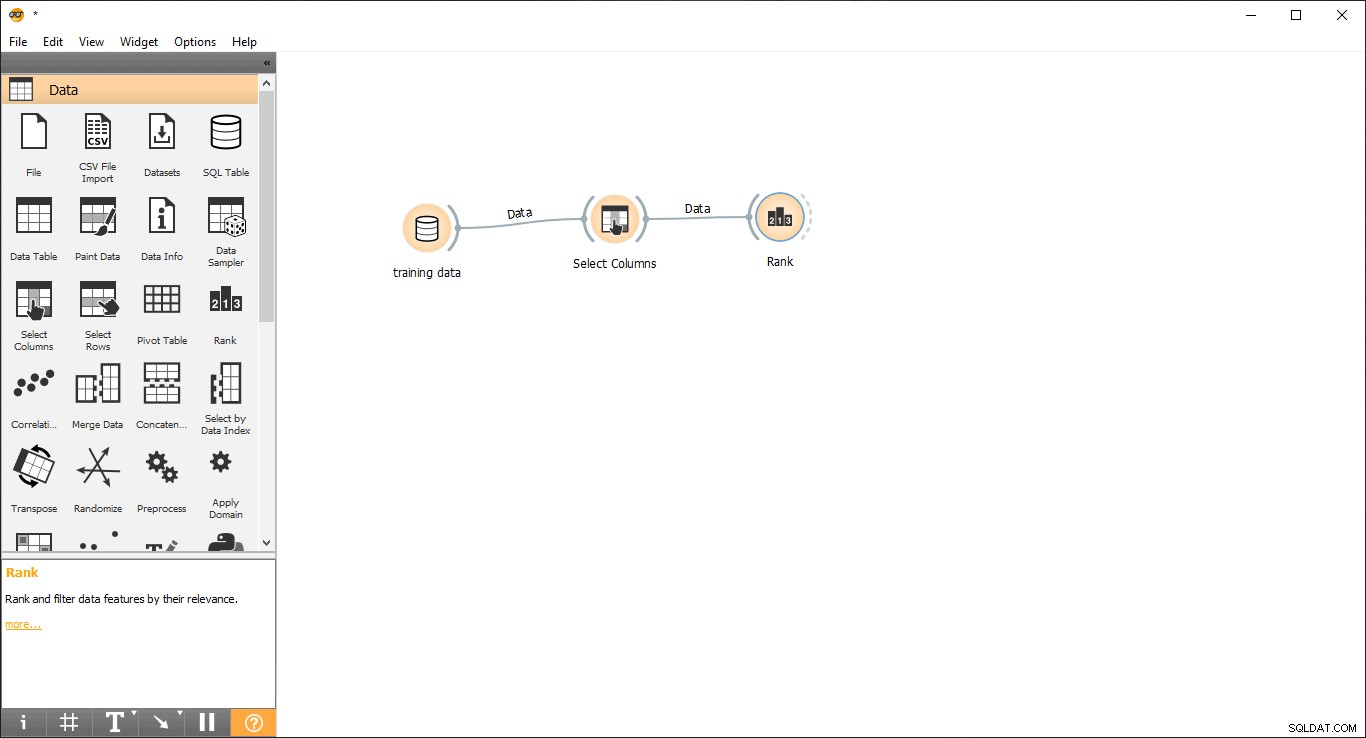
- ランクをドラッグアンドドロップします データからのウィジェット メニュー。
- 列の選択からリンク線を描画します ランクへのウィジェット ウィジェット。
- ランクをダブルクリックします トレーニングデータテーブルで最も関連性の高い列を表示するウィジェット。デフォルトで上位5列が選択されます。
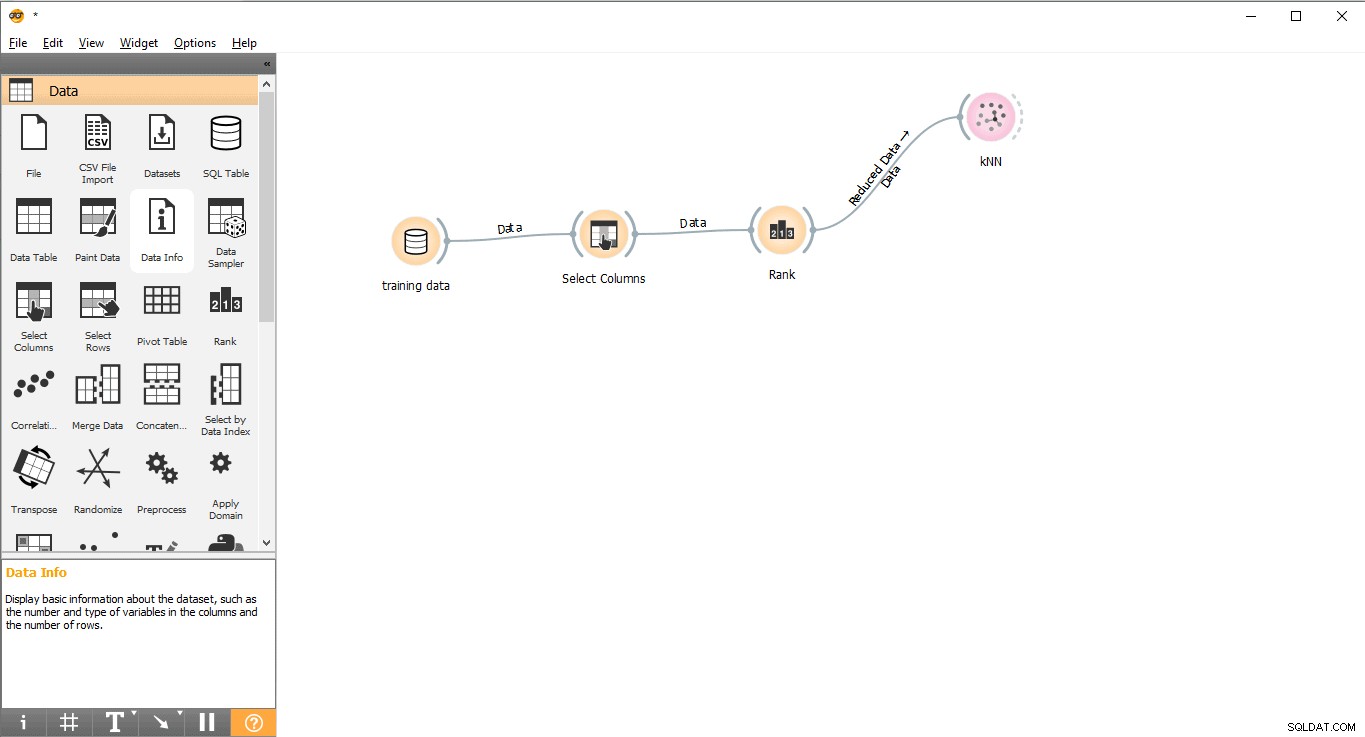
ステップ7:データトレーニング
このステップでは、機械学習モデル(KNN)がトレーニングデータセットを使用してトレーニングされます。次の手順に従ってください:
- KNNをドラッグアンドドロップします モデルのウィジェット メニュー。
- ランクからリンク線を引く KNNへのウィジェット ウィジェット。
ステップ8:テストデータセットをPostgreSQLにロードする
予測を実行するために、別のテストデータセットが作成されます。手順に従って、テストデータセットをPostgreSQLテーブルにロードしてください。
- テストデータを保存するためのテーブルを作成します 。ここでは、test_dataという名前が付けられています。
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- COPYを使用してテストデータをテストテーブルに挿入します クエリ。 コピーを実行する前に クエリでは、PostgreSQLにデータファイルの読み取り権限が必要であることを確認してください。そうでない場合、COPY操作は失敗します。
注: 必ずタブを入力してください 区切り文字の後の一重引用符の間のスペース キーワード。疑問符は意図的にタイプに配置されています 機械学習モデルを使用して特定の動物の種類を把握する必要があるため、テストデータセットの列。
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
以下のテストデータセットのスクリーンショットを見つけてください

ステップ9:PostgreSQLからOrangeにテストデータをインポートする
予測を適用するには、次の手順に従ってください。
- SQLテーブルをドラッグアンドドロップします データからのウィジェット メニュー。
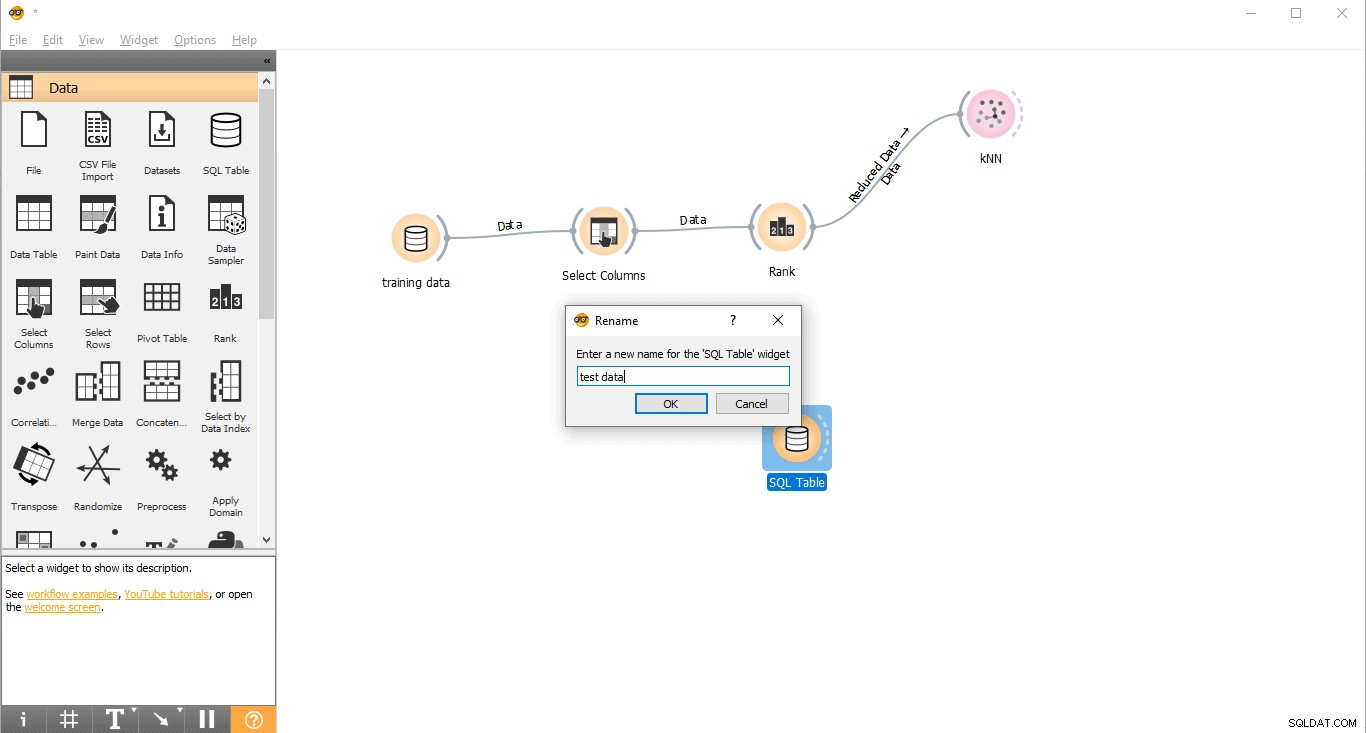
- ウィジェットの名前を変更する(オプション)
- SQLテーブルを右クリックします ウィジェット。
- 名前の変更を選択します 。
- PostgreSQLに接続してテストデータをロードします。
- テストデータをダブルクリックします ウィジェット。
- テストデータと接続します PostgreSQLのテーブル。
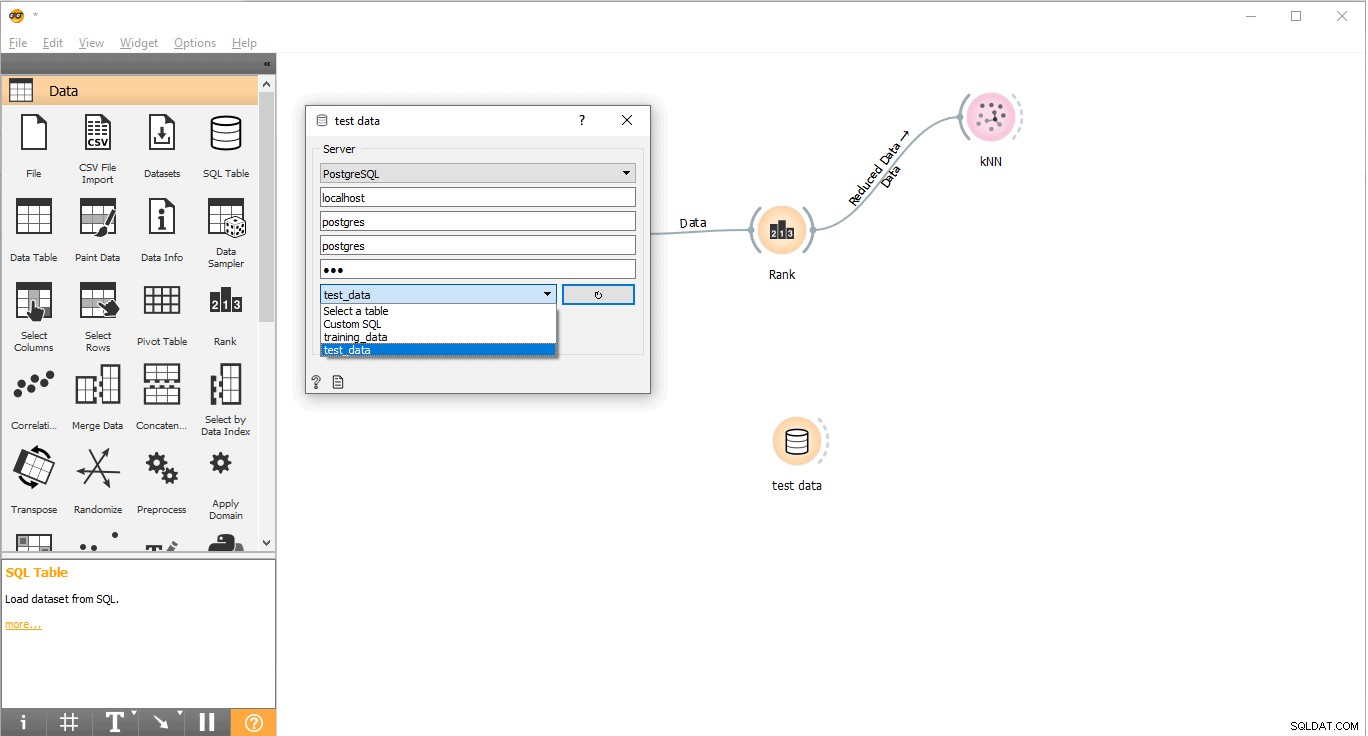
これで、予測を実行する準備が整いました。
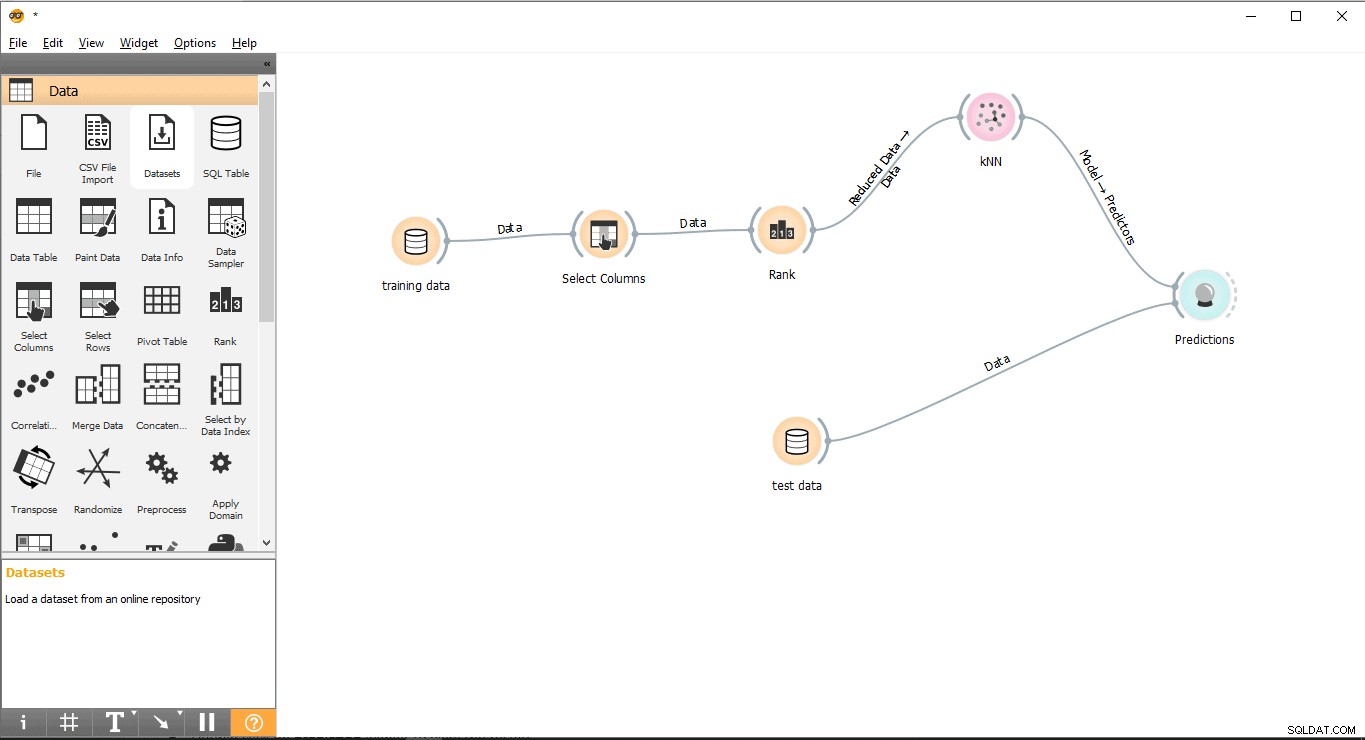
ステップ10:予測
予測 ウィジェットは、 KNNからのトレーニングデータに基づいてテストデータを予測しようとします 。
- ドラッグアンドドロップ予測 評価のウィジェット メニュー。
- リンクラインフォームを描画するテストデータ 予測へのウィジェット ウィジェット。
- KNNからリンク線を引く 予測へのウィジェット ウィジェット。
ステップ11:結果
予測をダブルクリックします 結果を表示するウィジェット。
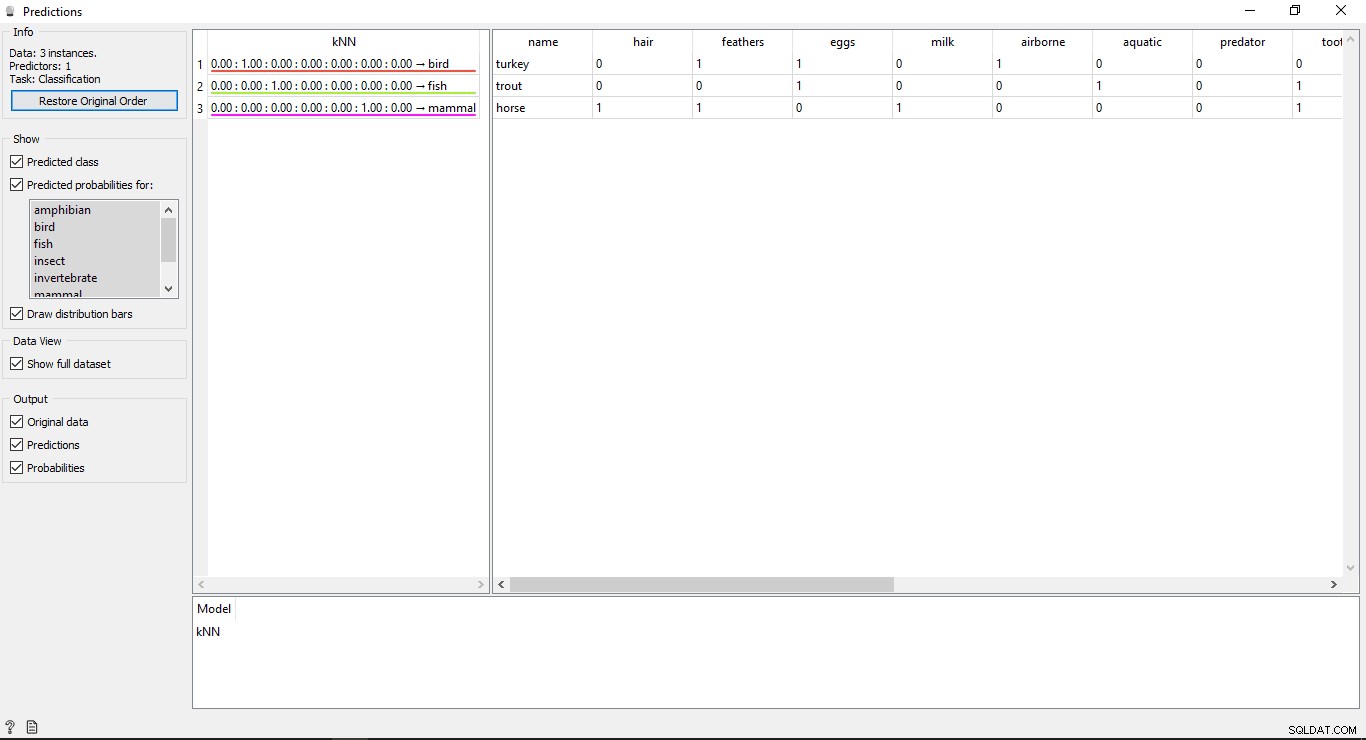
結果を理解する
予測ウィンドウに2つのメインテーブルが表示されます。左側の表は予測結果を示し、右側の表は予測のために提供された元のテストデータを示しています。
KNN以降 モデルはデータのトレーニングに使用されたため、 KNNという名前の1つの列が表示されます 結果が一覧表示されます。
ご存知のとおり:
- 馬 哺乳類です
- トラウト 魚です
- トルコ 鳥です
したがって、KNNはすべてのタイプを正しく判別できます。
予測精度
予測ウィジェットの出力の左側にある表を見ると、予測されたタイプの前にいくつかの数値、つまり1.00があります。 0.00これらの数値は、予測されたタイプの精度を示しています。
トレーニングデータセットでは7種類の動物を使用したため、合計7列が表示され、各列は1種類の動物を表す精度値を示します。画面左側の予測確率の下にあるリストを見ると、どの列がどの種類の動物を表しているかを確認できます。 ラベル。 トルコと書かれている最初の行を見ると 鳥です 。その精度は1.00であることがわかります (2列目から100%)。他の例でも同じですトラウト 魚です 精度は1.00 (3列目から100%)
この記事では、k最近傍法(KNN)を使用して機械学習モデルを実装しました。次のブログでは、サポートベクターマシンを使用します (SVM)モデル。
ご質問やご意見がございましたら、こちらのお問い合わせフォームからご連絡ください。