テーブルスキーマ
ルールを適用するには、 pvanlagen.buildidを宣言するだけです。 UNIQUE >
:
ALTER TABLE pvanlagen ADD CONSTRAINT pvanlagen_buildid_uni UNIQUE (buildid);
building.gid あなたのアップデートが明らかにしたように、PKです。参照整合性も適用するには、 buildings.gidへ 。
これで両方を実装しました。ただし、大きな UPDATEを実行する方が効率的です。 前の下 これらの制約を追加します。
テーブル定義で改善する必要のあるものは他にもたくさんあります。 1つは、 buildings.gid pvanlagen.buildidも同様です タイプはintegerである必要があります (またはおそらく bigint たくさん燃やすと PK値の)。 数値 高価なナンセンスです。
コアの問題に焦点を当てましょう:
最も近い建物を見つけるための基本的なクエリ
ケースは見た目ほど単純ではありません。 「最近傍」> 問題、固有の割り当ての追加の複雑さ。
このクエリは、最も近い1つを見つけます 各PVの構築(PVAnlageの略-pvanlagenの行 )、どちらも割り当てられていませんが、まだ:
SELECT pv_gid, b_gid, dist
FROM (
SELECT gid AS pv_gid, ST_Transform(geom, 31467) AS geom31467
FROM pvanlagen
WHERE buildid IS NULL -- not assigned yet
) p
, LATERAL (
SELECT b.gid AS b_gid
, round(ST_Distance(p.geom31467
, ST_Transform(b.centroid, 31467))::numeric, 2) AS dist -- see below
FROM buildings b
LEFT JOIN pvanlagen p1 ON p1.buildid = b.gid -- also not assigned ...
WHERE p1.buildid IS NULL -- ... yet
-- AND p.gemname = b.gemname -- not needed for performance, see below
ORDER BY p.geom31467 <-> ST_Transform(b.centroid, 31467)
LIMIT 1
) b;
このクエリを高速にするには、必要 建物の空間的で機能的なGiSTインデックス 多くにするために より速く:
CREATE INDEX build_centroid_gix ON buildings USING gist (ST_Transform(centroid, 31467));
理由がわからない あなたはしません
詳細な説明付きの関連回答:
さらに読む:
- https://workshops.boundlessgeo.com/postgis-intro/knn html
- https://www.postgresonline.com/journal/archives/306-KNN-GIST-with-a-Lateral-twist-Coming-soon-to-a-database-near- you.html
インデックスが設定されていれば、一致を同じ gemnameに制限する必要はありません。 パフォーマンスのために。これは、強制する実際のルールである場合にのみ実行してください。常に監視する必要がある場合は、FK制約に列を含めます。
残りの問題
上記のクエリをUPDATEで使用できます 声明。各PVは1回だけ使用されますが、複数のPVが同じ建物を見つける可能性があります。 最も近くに。許可するのは1つのみです 建物ごとのPV。では、それをどのように解決しますか?
つまり、ここでオブジェクトをどのように割り当てますか?
簡単な解決策
簡単な解決策の1つは次のとおりです。
UPDATE pvanlagen p1
SET buildid = sub.b_gid
, dist = sub.dist -- actual distance
FROM (
SELECT DISTINCT ON (b_gid)
pv_gid, b_gid, dist
FROM (
SELECT gid AS pv_gid, ST_Transform(geom, 31467) AS geom31467
FROM pvanlagen
WHERE buildid IS NULL -- not assigned yet
) p
, LATERAL (
SELECT b.gid AS b_gid
, round(ST_Distance(p.geom31467
, ST_Transform(b.centroid, 31467))::numeric, 2) AS dist -- see below
FROM buildings b
LEFT JOIN pvanlagen p1 ON p1.buildid = b.gid -- also not assigned ...
WHERE p1.buildid IS NULL -- ... yet
-- AND p.gemname = b.gemname -- not needed for performance, see below
ORDER BY p.geom31467 <-> ST_Transform(b.centroid, 31467)
LIMIT 1
) b
ORDER BY b_gid, dist, pv_gid -- tie breaker
) sub
WHERE p1.gid = sub.pv_gid;
DISTINCT ON(b_gid)を使用しています 正確に1つに減らす 建物ごとの行、最短距離のPVを選択します。詳細:
複数のPVに最も近い建物には、最も近いPVのみが割り当てられます。 PK列gid (エイリアス pv_gid )2つが等しく近い場合、タイブレーカーとして機能します。このような場合、一部のPVは更新から削除され、未割り当てのままになります。 。 繰り返し すべてのPVが割り当てられるまでクエリを実行します。
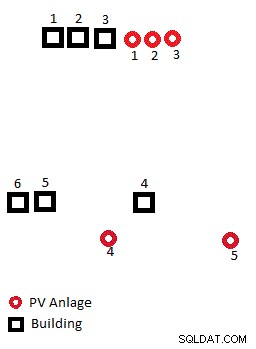
これはまだ単純なアルゴリズムです 、 けれど。上の図を見ると、これにより建物4がPV 4に割り当てられ、建物5がPV 5に割り当てられますが、全体としては4-5と5-4の方がおそらくより良いソリューションになるでしょう...
脇: distのタイプ 列
現在、数値
それのための。元のクエリに定数integerが割り当てられました 、数値では意味がありません 。
私の新しいクエリでは、 ST_Distance()
実際の距離をメートル単位でdoubleとして返します。精度
。単純に割り当てると、数値に15桁程度の小数桁が含まれます。 データ型であり、その数はではありません そもそも正確。ストレージを無駄にしたいのではないかと真剣に疑っています。
元の倍精度を保存したい 計算から。または、さらに良い 、必要に応じて丸めます。メーターが十分に正確である場合は、 integerにキャストして保存するだけです。 (数値は自動的に丸められます)。または、最初に100を掛けて、cmを節約します。
(ST_Distance(...) * 100)::int