実体関連データモデル 、 ERとも呼ばれます は、データについて推論するために使用できるさまざまなデータモデルの1つです。
特に、これは概念データモデル 、特定の実装にリンクされていないため。それは論理データモデルに任された仕事です。
ERデータモデル 非常に一般的で高レベルであるため、さまざまなまったく異なる種類のデータベースで実装できます。
実装の詳細については考えず、代わりにデータとその編成方法についてのみ考えるので素晴らしいです。 。その間、以前は考えていなかった方法で問題を分析する必要があります。
ERダイアグラムは、データが関係するシナリオの分析に役立つと思います。
ERモデルは、グラフィカルな表記法を使用して、モデル化する必要のあるすべてのデータ、さまざまな種類のデータ間の関係、およびそれに関連する情報を表すためのツールを提供します。
ERモデルを構成する2つのアイテムがあります:
- エンティティ
- 関係
エンティティは、アイテムや人物など、共通のプロパティを持つデータの種類です。
関係はエンティティ間の関係です。
例を挙げましょう。本とその著者について話しましょう。 2つのエンティティがあります :
- 本
- 作成者
特定の本は、本の実体のインスタンスです。
2つのエンティティがあるため、2つの関係があります それらの間の。 1つは、1冊の本と著者の実体との関係です。 1つは、1人の著者と本の実体との関係です。考えてみると、次のようなものがあります。
- 本には著者がいます
- 著者はさまざまな本を書くことができます
この簡単な例を考えると、シナリオのERデータモデルの作成に役立つ視覚的な表記法の導入を開始できます。
注:ER図を描くにはさまざまな方法があります。 私の意見では 、より視覚的で意味があります。
エンティティは長方形で表され、エンティティを識別するためのテキストが含まれています。

エンティティ間の関係は、最も基本的な形式で、2つの関係を結ぶ線と、関係のタイプを識別するためのテキストを含むひし形を使用して表されます。

「本には著者がいる」と「著者が本を書いた」という2つの関係を作成しなかったことに注意してください。私は本と著者の間に「著者」という単一の関係を築きました。
関係ができたら、関係する番号を指定する必要があります。現在、多くの質問があります:
- 本には何人の著者がいますか?
- 著者は複数の本を書くことができますか?
- 著者は、著者と呼ばれるために少なくとも1冊の本を書く必要がありますか?
- 複数の著者が本を書くことはできますか?
- 少なくとも著者がいなくても本は存在できますか?
これらはすべて質問するのに良い質問です。この場合、答えはかなり明白だと思います。そして、答えが明らかでない場合は、問題について考え、独自の制約を追加することができます。
ダイアグラム上でカーディナリティを視覚的に示すには、さまざまな方法があります。エンティティにリンクするときに線の形状を変更することを好む人もいます。
私は物事をより明確にする数字を好みます:

上記の数字はこれを意味します:本は1人以上の著者によって執筆されることができます。 n 任意の数の要素を意味します。
また、著者は0冊の本(おそらく今は1冊を書いています)から無数の本までを執筆することができます。
1つ目はゼロ対多の関係と呼ばれます 。 2つ目は、1対多の関係です。 。
次のものもあります:
- 1対1の関係
- 多対多の関係
- ゼロ対1の関係
各エンティティは1つ以上の属性を持つことができます。
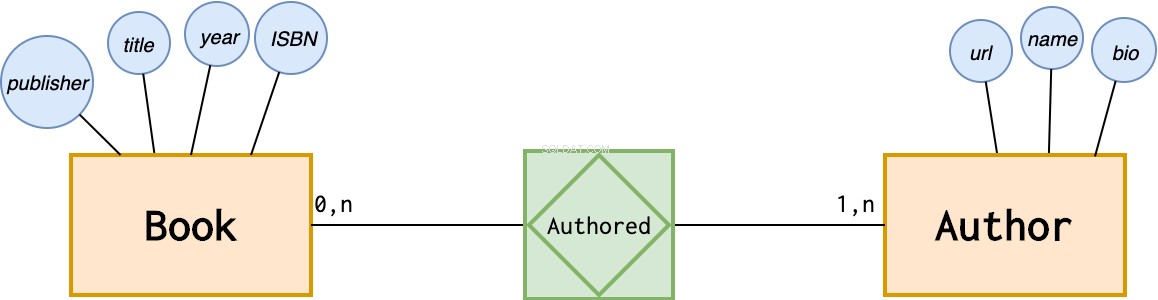
書店で上記の関係を使用するとします。各著者には、名前、経歴、ウェブサイトのURLがあります。
各本には、タイトル、出版社、出版年、ISBNがあります。必要に応じて、発行者もエンティティにすることができます。しかし、それを本の属性として定義することもできます。
上記の情報を表す方法は次のとおりです。
エンティティは一意のキーで識別される必要があります。ブックエンティティは、ISBN属性によって一意に識別できます。すべての本には単一のISBNがあります(本の単一のコピーではなく、本の「タイトル」を表すことを考慮して)。
主キー属性は、その基礎となるものによって識別されます。
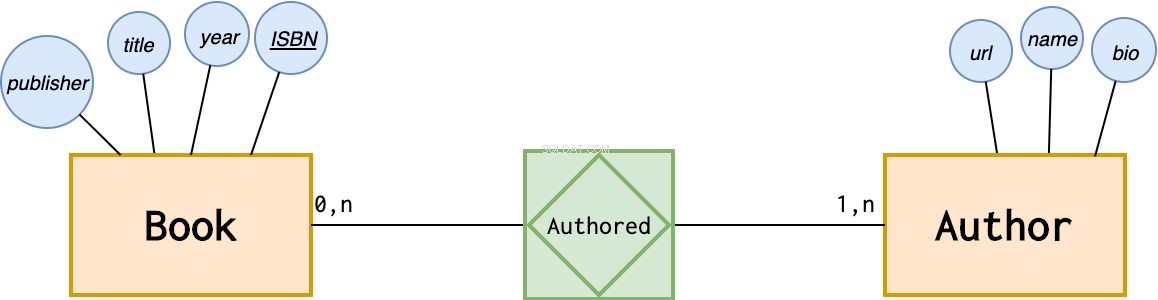
一方、作成者は現時点では一意の識別子を持っていません。 2人の著者が同じ名前を持つことができます。
したがって、一意のキー属性を追加する必要があります。たとえば、id 属性:
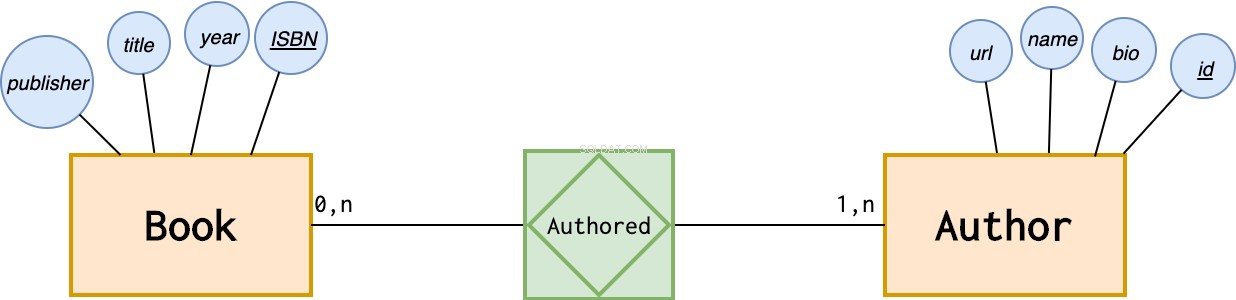
識別子の属性は複数の属性にまたがることができます。
たとえば、パスポートIDと作成者の国は個人を一意に識別し、idを置き換えることができます。 追加した属性:

どれを選ぶ?それはあなたのアプリケーションで何がより理にかなっているのかという問題です。書店をモデル化している場合、すべての本の著者の国とパスポートIDを取得することは期待できません。したがって、ランダムなidを使用します 各著者を選択して関連付けます。
属性はエンティティに固有ではありません。リレーションにも属性を含めることができます。
ライブラリをモデル化する必要があると考えてください。本と著者のエンティティに加えて、読者エンティティを紹介します。 、それを読むために本を借りる人。彼らがそれを借りるとき、私たちはその名前とIDカード番号を取ります:
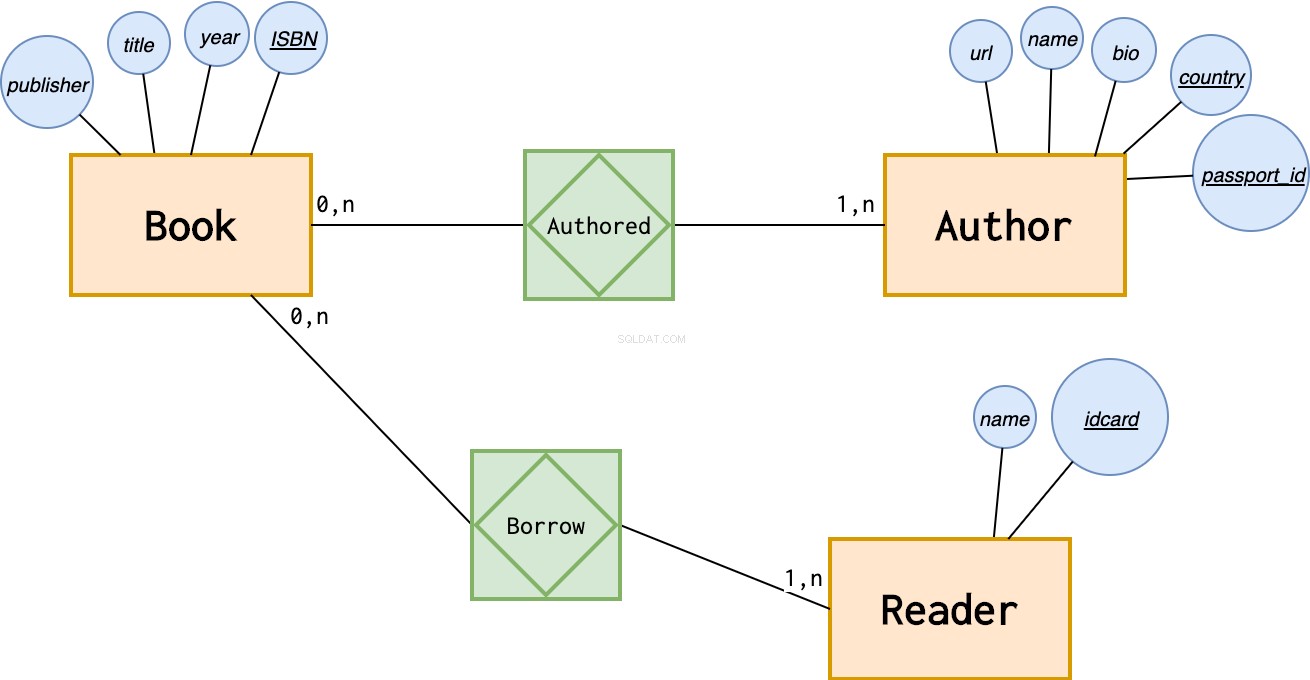
しかし、私たちはまだ情報を逃しています。特定の本のすべての履歴に関する情報を図書館に保存できるように、その人がいつ本を借りたのか、いつ返却したのかを知る必要があります。この情報は、本または読者のエンティティのいずれにも属していません。それは関係に属します:
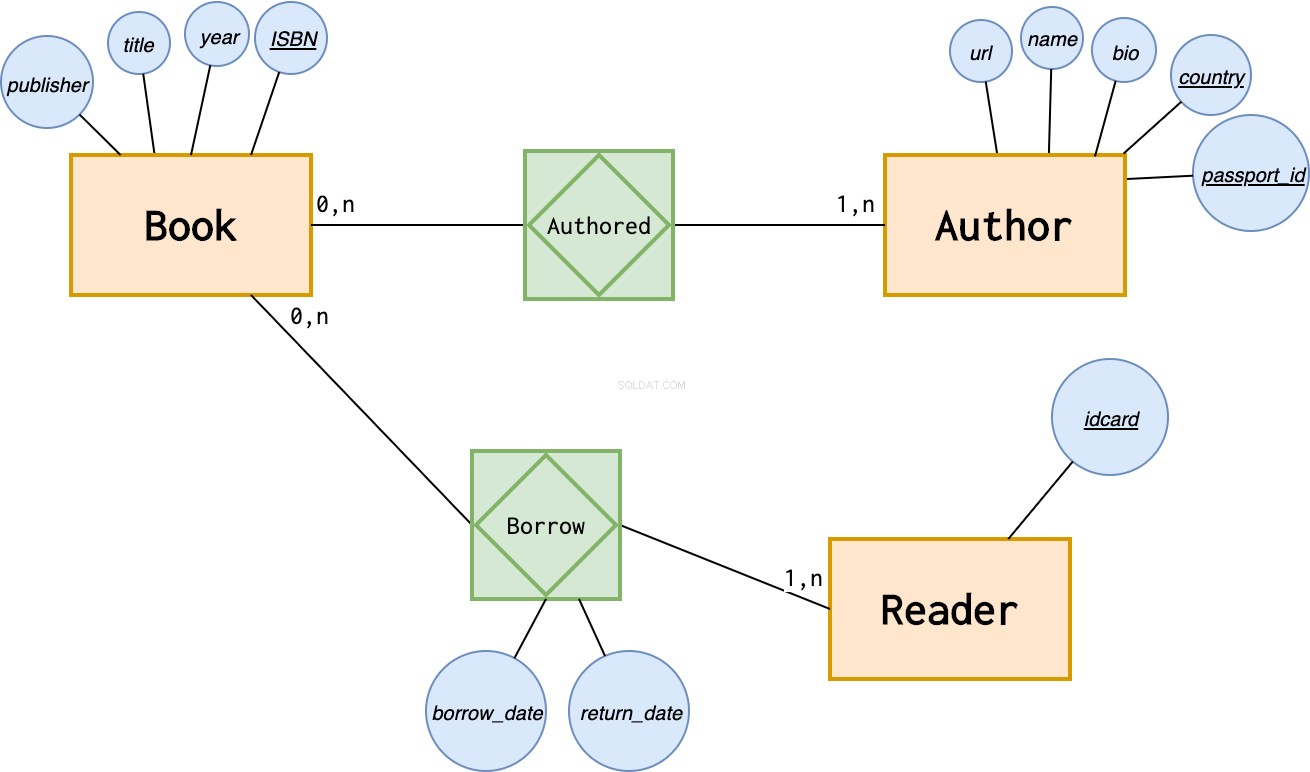
上記の主キーと、ヘルプがエンティティを一意に識別する方法について説明しました。
一部のエンティティは、その存在を他のエンティティに依存しており、弱いエンティティと呼ばれます。 。
オンラインショップの注文をモデル化する必要があるとします。
注文ごとに、1から始まり、時間の経過とともに増加する注文ID、発注日時、顧客に関する情報が保存されるため、請求先と発送先がわかります。
次に、彼らが何を注文したかを知る必要もあります。チェックアウト時にカート内の各アイテムを表す、弱いエンティティ「注文アイテム」を作成します。
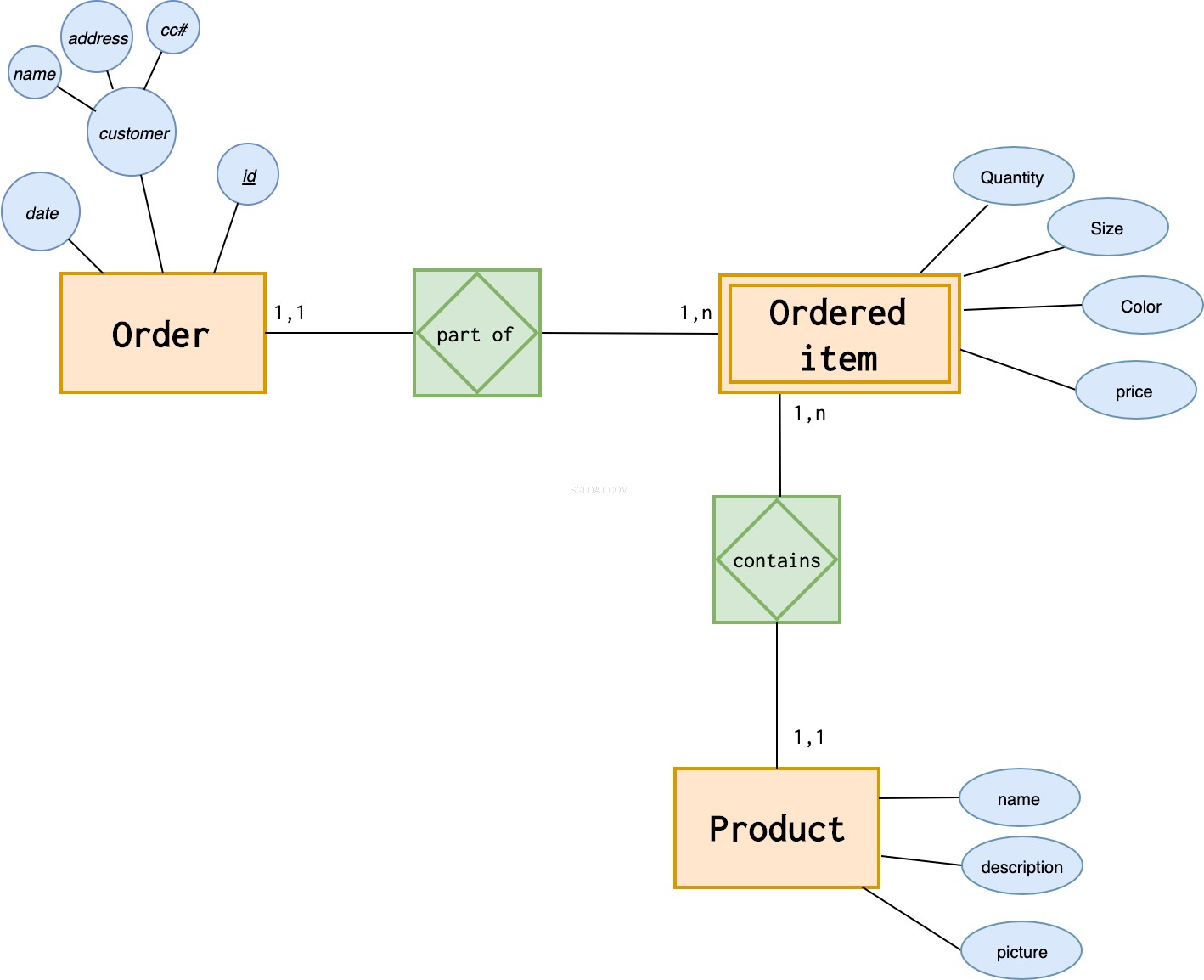
このエンティティは、チェックアウト時のアイテムの価格(したがって、販売中の製品の価格を変更しても、すでに行われた注文には影響しません)、注文されたアイテムの数量、および選択されたオプションを保存します。 Tシャツを販売しているため、注文したTシャツの色とサイズを保存する必要があるとします。
注文されたアイテムエンティティは注文エンティティなしでは存在できないため、これは弱いエンティティです。
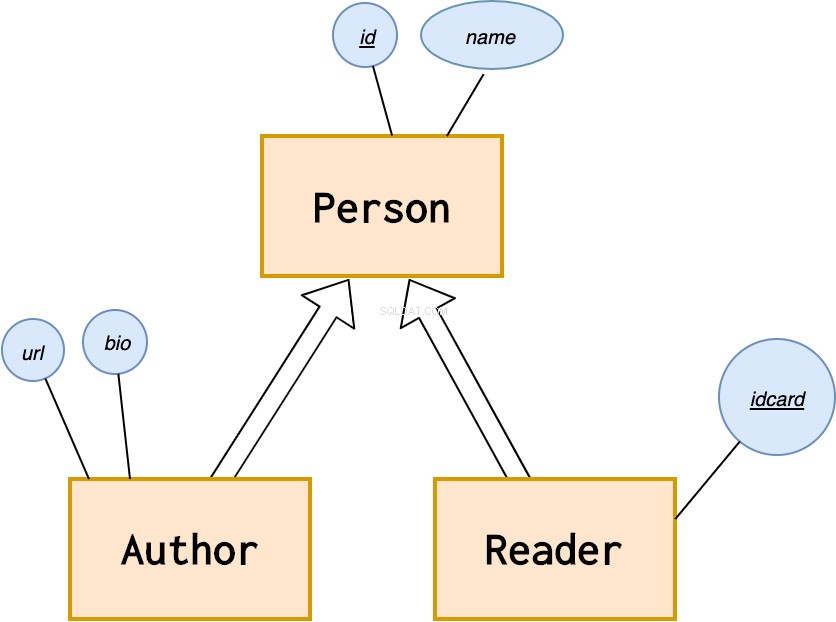
エンティティは、それ自体と再帰的な関係を持つことができます。個人エンティティがあるとします。このようにして親子関係をモデル化できます:
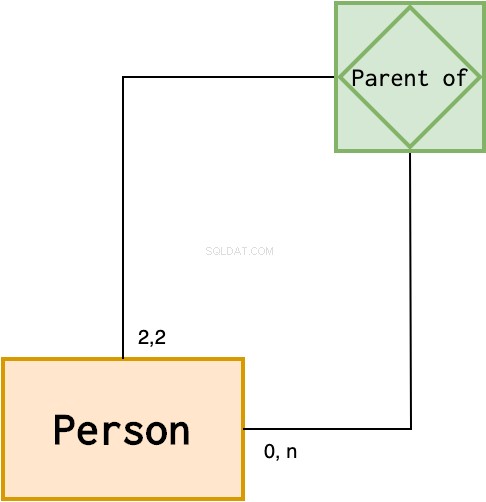
人は0からn人の子供を持つことができ、子供には2人の親がいます(最も単純なシナリオを考慮して)。
ISA関係
ISAはIS-Aの略で、ERモデルで一般化をモデル化する方法です。
これを使用して、類似したエンティティを共通の傘の下にグループ化します。たとえば、本や図書館の例の場合、著者と読者は、個人エンティティを使用して一般化できます。
どちらにも名前があるので、personエンティティまで名前を抽出し、対応するエンティティの作成者または読者であるという特性を管理します。
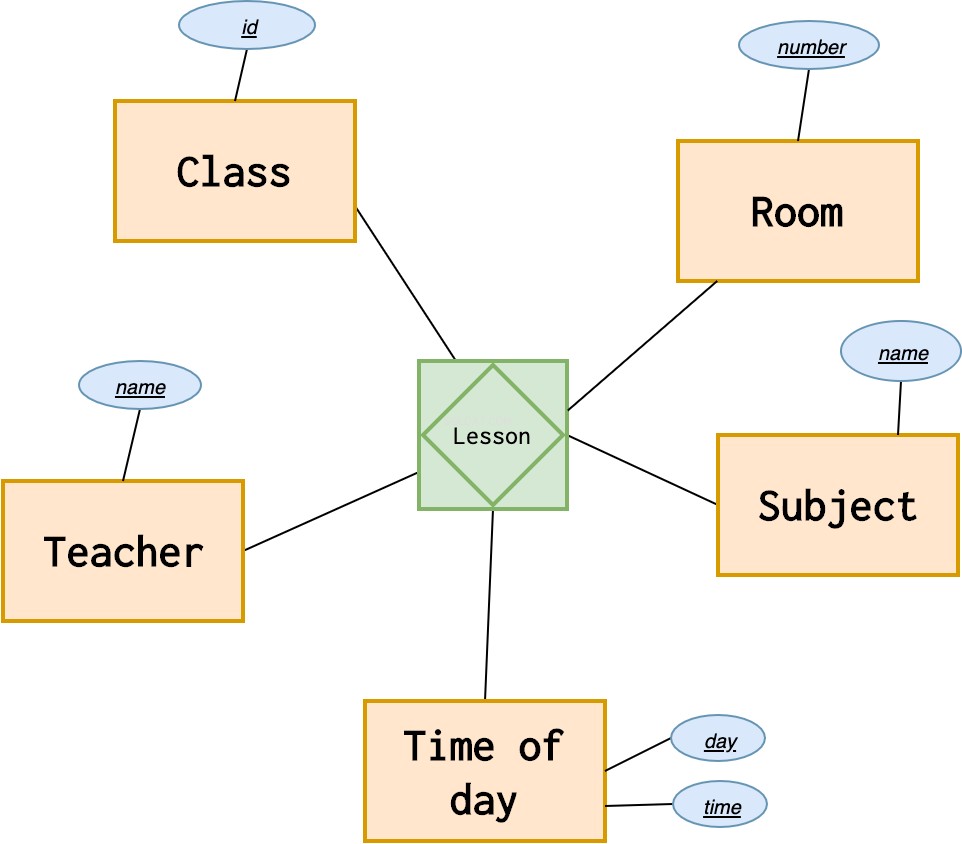
すべての関係が厳密にバイナリであるわけではありません。レッスンのシナリオを見てみましょう。
授業は本日10:00に学校の部屋で行われ、先生が物理についてクラスで話します。
そのため、レッスンは1日の特定の時間に行われ、科目、教師、クラス、部屋が含まれます。
このようにモデル化できます: