注:この投稿は元々、eBook、SQLServerの高性能テクニック第2巻でのみ公開されていました。eBookについてはこちらをご覧ください。
概要:この記事では、INSTEAD OFトリガーのいくつかの驚くべき動作を調べ、SQLServer2014の重大なカーディナリティ推定のバグを明らかにします。
トリガーと行のバージョン管理
DML AFTERトリガーのみが行のバージョン管理(SQL Server 2005以降)を使用して挿入を提供します および削除 トリガープロシージャ内の疑似テーブル。この点は、公式文書の多くでは明確にされていません。ほとんどの場所で、ドキュメントには、行のバージョン管理が挿入されたの構築に使用されると単純に記載されています。 および削除 修飾のないトリガーのテーブル(以下の例):
行バージョニングリソースの使用法
行バージョニングベースの分離レベルについて
データの一括インポート時のトリガー実行の制御
おそらく、これらのエントリの元のバージョンは、INSTEAD OFトリガーが製品に追加される前に書き込まれ、更新されることはありません。それか、それは単純な(しかし繰り返される)見落としです。
とにかく、AFTERトリガーで行バージョン管理が機能する方法は非常に直感的です。これらのトリガーは後に起動します 問題の変更が実行されたため、変更された行のバージョンを維持することで、データベースエンジンが挿入されたを提供する方法を簡単に確認できます。 および削除 疑似テーブル。 削除 疑似テーブルは、変更が行われる前の影響を受ける行のバージョンから作成されます。 挿入 疑似テーブルは、トリガー手順が開始された時点での影響を受ける行のバージョンから形成されます。
トリガーの代わりに
このタイプのDMLトリガーは完全に置換されるため、INSTEADOFトリガーは異なります。 トリガーされたアクション。 挿入 および削除 疑似テーブルは、の変更を表すようになりました。 作成され、トリガーステートメントが実際に実行されました。定義上、変更が行われていないため、これらのトリガーに行のバージョン管理を使用することはできません。では、行バージョンを使用していない場合、SQL Serverはどのようにそれを行いますか?
答えは、INSTEAD OFトリガーが存在する場合、SQLServerはトリガーするDMLステートメントの実行プランを変更することです。影響を受けるテーブルを直接変更するのではなく、実行プランは変更に関する情報を非表示の作業テーブルに書き込みます。このワークテーブルには、元の変更を実行するために必要なすべてのデータ、各行で実行する変更のタイプ(削除または挿入)、およびOUTPUT句のトリガーに必要な情報が含まれています。
トリガーなしの実行プラン
これらすべての動作を確認するために、最初にINSTEADOFトリガーが存在しない状態で簡単なテストを実行します。
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; 削除の実行計画は非常に単純です:
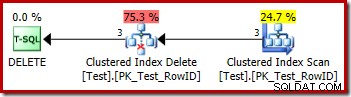
修飾する各行は、クラスター化インデックス削除演算子に直接渡され、クラスター化インデックス削除演算子によって削除されます。簡単。
INSTEADOFトリガーを使用した実行プラン
次に、テストを変更して、INSTEAD OF DELETEトリガー(簡単にするために同じ削除アクションを実行するトリガー)を含めます。
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; DELETEの実行プランは今ではまったく異なります:
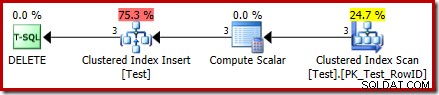
Clustered Index Delete演算子は、Clustered Index Insertに置き換えられました。 。これは非表示のワークテーブルへの挿入であり、(公開実行計画の表現では)削除の影響を受けるベーステーブルの名前に名前が変更されます。名前の変更は、XMLショープランが内部実行プラン表現から生成されるときに発生するため、非表示の作業テーブルを確認するための文書化された方法はありません。
したがって、この変更の結果として、プランは挿入を実行するように見えます。 削除するためにベーステーブルに移動します それからの行。これは紛らわしいですが、少なくともINSTEADOFトリガーの存在を明らかにします。 Insert演算子をDeleteに置き換えると、さらに混乱する可能性があります。おそらく理想は、INSTEAD OFトリガーワークテーブルの新しいグラフィカルアイコンでしょうか?とにかく、それはそれが何であるかです。
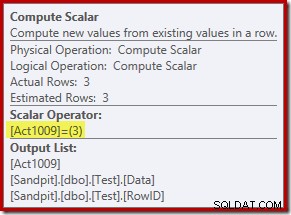
新しいComputeScalar演算子は、各行で実行されるアクションのタイプを定義します。このアクションコードは整数であり、次の意味があります。
- 3=削除
- 4=挿入
- 259=MERGEプランで削除
- 260=MERGEプランに挿入
このクエリの場合、アクションは定数3です。つまり、すべての行が削除されます。 :
更新アクション
余談ですが、INSTEAD OF UPDATE実行プランは、単一のUpdate演算子を2つに置き換えます。 クラスター化されたインデックスは、同じ非表示のワークテーブルに挿入されます–挿入された用の1つ 疑似テーブル行、および削除済み用の行 疑似テーブル行。実行計画の例:

UPDATEを実行するMERGEも、同様の理由で同じベーステーブルへの2つの挿入を含む実行プランを生成します。

トリガー実行プラン
トリガー本体の実行プランにも、いくつかの興味深い機能があります。
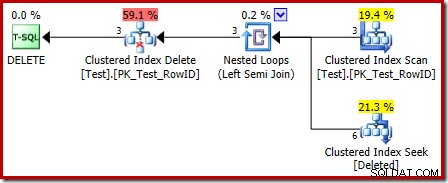
最初に気付くのは、削除されたテーブルに使用されるグラフィカルアイコンが、トリガープランの後に使用されるアイコンと同じではないことです。
INSTEAD OFトリガープランの表現は、クラスター化されたインデックスシークです。基になるオブジェクトは、前に見たものと同じ内部ワークテーブルですが、ここでは deleteedという名前が付けられています。 おそらくAFTERトリガーとのある種の一貫性のために、ベーステーブル名が与えられる代わりに。
削除されたのシーク操作 テーブルが期待したものではない可能性があります(RowIDでのシークを期待していた場合):
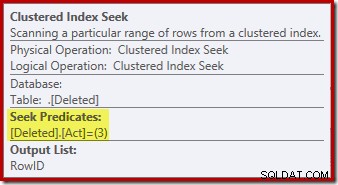
この「seek」は、アクションコードが3(削除)のワークテーブルからすべての行を返します。これは、削除されたスキャンとまったく同じです。 AFTERトリガープランに見られるオペレーター。同じ内部ワークテーブルを使用して、両方の挿入の行を保持します および削除 INSTEADOFトリガーの疑似テーブル。挿入されたスキャンに相当するのは、アクションコード4のシークです(これは削除で可能です) トリガーしますが、結果は常に空になります)。 アクションの一意でないクラスター化インデックスを除いて、内部ワークテーブルにはインデックスはありません。 カラムのみ。さらに、この内部インデックスに関連付けられた統計はありません。
これまでの分析では、RowID列間の結合がどこで実行されるのか疑問に思われるかもしれません。この比較は、ネストされたループの左半結合演算子で残余述語として行われます:
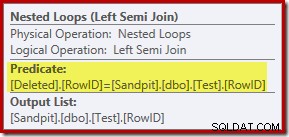
これで、「シーク」は事実上、削除されたのフルスキャンであることがわかりました。 テーブルでは、クエリオプティマイザによって選択された実行プランはかなり非効率的です。実行プランの全体的なフローは、テストテーブルの各行が、削除されたのセット全体と比較される可能性があることです。 行。これはデカルト積のように聞こえます。
節約の恩恵は、結合が半結合であることです。つまり、最初の削除が行われるとすぐに、特定のテスト行の比較プロセスが停止します。 行は残差述語を満たします。それにもかかわらず、戦略は奇妙なもののようです。テストテーブルにさらに多くの行が含まれていると、実行プランの方が優れている可能性がありますか?
1,000行のトリガーテスト
次のスクリプトを使用して、より多くの行でトリガーをテストできます。 1,000から始めます:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; トリガー本体の実行プランは次のとおりです。
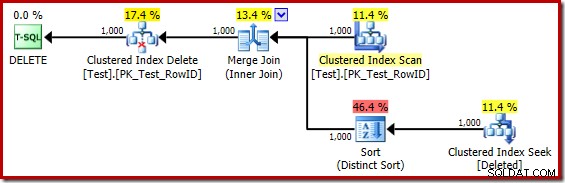
(誤解を招く)クラスター化インデックスシークを削除済みスキャンに精神的に置き換えると、計画は一般的にかなり良好に見えます。オプティマイザは、ネストされたループの半結合ではなく、1対多のマージ結合を選択しました。これは妥当なようです。ただし、Distinct Sortは興味深い追加です:
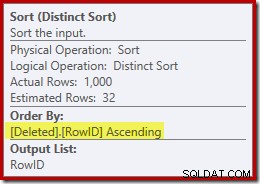
このソートは2つの機能を実行しています。まず、必要な並べ替えられた入力を使用してマージ結合を提供します。これは、必要な順序を提供するための内部作業テーブルにインデックスがないため、十分に公平です。ソートが行う2番目のことは、RowIDで区別することです。 RowIDはベーステーブルの主キーであるため、これは奇妙に思えるかもしれません。
問題は、削除されたの行が テーブルは、元のDELETEクエリが識別した単なる候補行です。 AFTERトリガーとは異なり、これらの行はまだ制約またはキー違反についてチェックされていないため、クエリプロセッサはそれらが実際に一意であるという保証はありません。
一般に、これはINSTEAD OFトリガーで覚えておくべき非常に重要なポイントです。提供された行がベーステーブルの制約(NOT NULLを含む)のいずれかを満たすという保証はありません。これは、トリガーの作成者が覚えておくことが重要なだけではありません。また、クエリオプティマイザが実行できる単純化と変換を制限します。
上記のSortプロパティに示されているが、強調表示されていない2番目の問題は、出力の見積もりが32行しかないことです。内部ワークテーブルには統計が関連付けられていないため、オプティマイザーは推測 Distinct操作の効果で。 RowID値が一意であることは「わかっています」が、難しい情報がない場合、オプティマイザーは推測を不十分にします。この問題は、次のテストで私たちを悩ませることになります。
5,000行のトリガーテスト
次に、テストスクリプトを変更して、5,000行を生成します。
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; トリガー実行プランは次のとおりです。
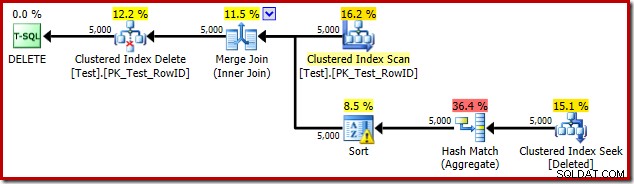
今回、オプティマイザーは、個別の操作と並べ替え操作を分割することを決定しました。 RowIDの識別は、ハッシュ一致(集計)演算子によって実行されます:
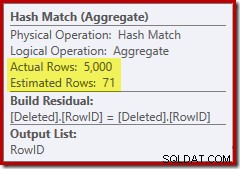
オプティマイザーの出力の見積もりは71行であることに注意してください。実際、RowIDは一意であるため、5,000行すべてが個別に存続します。不正確な見積もりは、クエリメモリ許可の不適切な部分がSortに割り当てられ、最終的に tempdbに流出することを意味します。 :
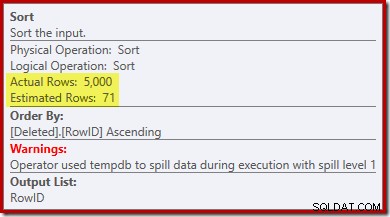
実行プランで並べ替えの警告を表示するには、SQLServer2012以降でこのテストを実行する必要があります。以前のバージョンでは、計画には流出に関する情報が含まれていません。それを明らかにするには、Sort Warningsイベントのプロファイラートレースが必要でした(そして、それを何らかの方法でソースクエリに関連付ける必要があります)。
SQLServer2014で5,000行を使用したトリガーテスト
SQL Server 2014で前のテストを繰り返し、互換性レベル120に設定されたデータベースで、新しいカーディナリティ推定量(CE)が使用される場合、トリガーの実行プランは再び異なります。
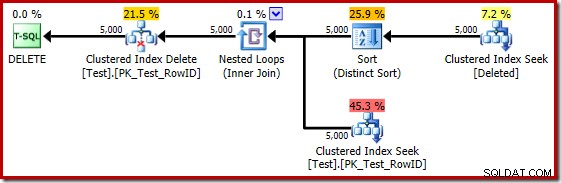
ある意味で、この実行計画は改善のように見えます。 (不要な)個別の並べ替えはまだありますが、全体的な戦略はより自然に見えます。削除された内の個別の候補RowIDごとに テーブルを作成し、ベーステーブルに結合して(候補行が実際に存在することを確認します)、それを削除します。
残念ながら、2014年の計画は、SQLServer2012で見たよりも悪いカーディナリティの見積もりに基づいています。SQLSentryPlanExplorerを切り替えて見積もりを表示する 行数は問題を明確に示しています:
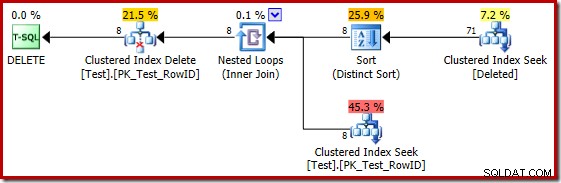
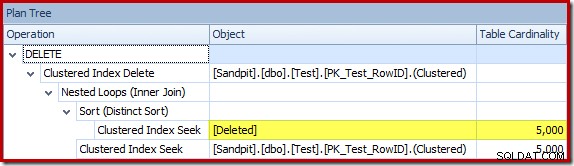
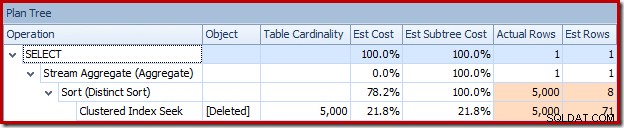
オプティマイザーは、最上位の入力に非常に少数の行が予想されるため、結合にネストされたループ戦略を選択しました。最初の問題は、クラスター化インデックスシークで発生します。オプティマイザーは、この時点で削除されたテーブルに5,000行が含まれていることを認識しています。これは、プランツリービューに切り替えて、オプションの[テーブルカーディナリティ]列(デフォルトで含まれていることを希望します)を追加することでわかります。
SQL Server 2012以前の「古い」カーディナリティ推定器は、内部ワークテーブルの「シーク」が5,000行すべてを返すことを知っているほど賢いです(したがって、マージ結合を選択しました)。新しいCEはそれほどスマートではありません。作業台を「ブラックボックス」と見なし、アクションコード=3に対するシークの効果を推測します:
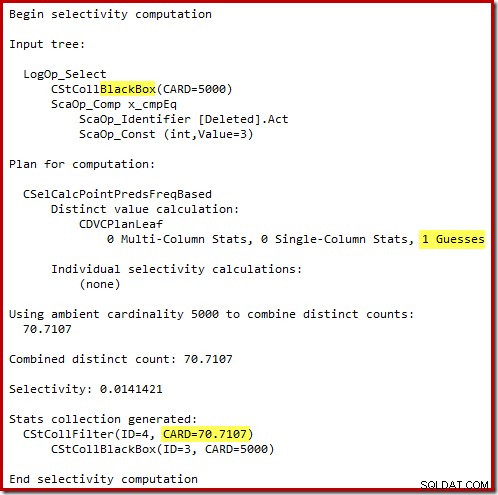
71行の推測(切り上げ)はかなり悲惨な結果ですが、新しいCEがそれらの71行に対する個別の操作の行を推定すると、エラーはさらに複雑になります。
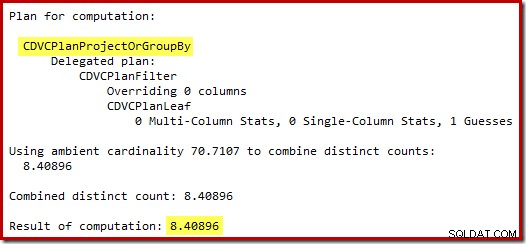
予想される8行に基づいて、オプティマイザーはネストされたループ戦略を選択します。これらの推定誤差を確認する別の方法は、次のステートメントをトリガー本体に追加することです(テスト目的のみ):
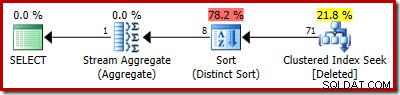
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
見積もり計画は、見積もりエラーを明確に示しています:
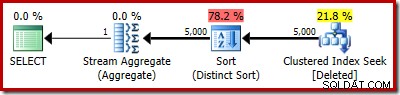
実際の計画では、もちろん5,000行が表示されます:
または、プランツリービューで同時に見積もりと実際を比較することもできます:
100万行…
2014カーディナリティ推定器を使用する場合の推測が不十分なため、テストテーブルに100万行が含まれている場合でも、オプティマイザはネストされたループ戦略を選択します。 2014年の新しいCE推定 そのテストの計画は次のとおりです。
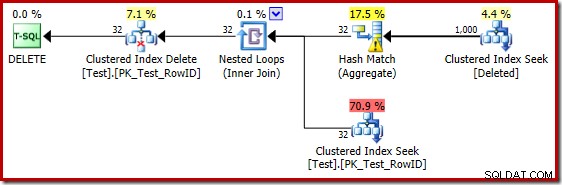
'seek'は、既知のカーディナリティ1,000,000から1,000行を推定し、明確な推定値は32行です。実行後の計画は、ハッシュマッチ用に予約されたメモリへの影響を明らかにします:
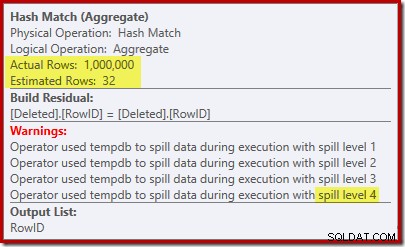
わずか32行を想定しているため、ハッシュマッチは実際の問題に直面し、最終的に完了する前にハッシュテーブルを再帰的にスピルします。
最終的な考え
宣言的な参照整合性で達成できることを実行するためにトリガーを作成してはならないことは事実ですが、適切に作成された 効率的なを使用するトリガー 実行プランのパフォーマンスは、追加の非クラスター化インデックスを維持するコストに匹敵する可能性があります。
上記のステートメントには2つの実際的な問題があります。最初に(そして世界で最高の意志で)人々は常に良いトリガーコードを書くとは限りません。次に、すべての状況でクエリオプティマイザから適切な実行プランを取得するのは難しい場合があります。トリガーの性質は、さまざまな入力カーディナリティとデータ分散で呼び出されることです。
AFTERトリガーの場合でも、削除済みのインデックスと統計が不足しています および挿入 疑似テーブルとは、計画の選択が推測や誤った情報に基づいていることが多いことを意味します。最初に適切なプランが選択された場合でも、再コンパイルがより適切な選択であった場合、後の実行で同じプランが再利用される可能性があります。主に一時テーブルと明示的なインデックス/統計を使用して制限を回避する方法がありますが、それでも細心の注意が必要です(トリガーはストアドプロシージャの形式であるため)。
INSTEAD OFトリガーを使用すると、挿入されたの内容が原因で、リスクがさらに大きくなる可能性があります。 および削除 テーブルは未検証の候補です。クエリオプティマイザは、ベーステーブルの制約を使用して、実行プランを単純化および改良することはできません。 SQL Server 2014の新しいカーディナリティ推定器は、INSTEADOFトリガープランに関しても実際の後退を表しています。エンジンがそれ自体を導入したシーク操作の効果を推測することは、驚くべき、そして歓迎されない見落としです。