次のストアドプロシージャ呼び出しのパフォーマンスが遅いと報告している開発者と協力しています:
EXEC [dbo].[charge_by_date] '2/28/2013';
開発者にどのような問題が発生しているかを尋ねますが、返される唯一の追加情報は、「実行速度が遅い」ということです。したがって、SQL Serverインスタンスにジャンプして、実際のを確認します。 実行計画。これを行うのは、実行プランがどのように見えるかだけでなく、プランの推定行数と実際の行数の違いにも関心があるためです。
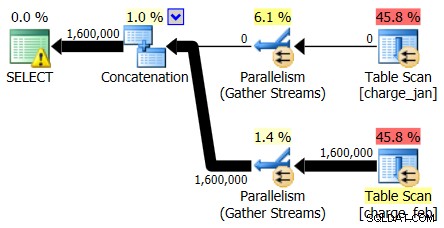
最初にプランのオペレーターだけを見ると、いくつかの注目すべき詳細を見ることができます:
- ルート演算子に警告があります
- リーフレベル(charge_janとcharge_feb)で参照される両方のテーブルのテーブルスキャンがあり、なぜこれらがまだヒープであり、クラスター化インデックスがないのか疑問に思います
- Charge_febテーブルを流れる行のみがあり、charge_janテーブルは流れていないことがわかります
- 計画に並列ゾーンが表示されます
ルートイテレータの警告については、その上にカーソルを合わせると、次のインデックスの推奨事項を含むインデックス警告が欠落していることがわかります。
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
元のデータベース開発者にクラスター化インデックスがない理由を尋ねると、「わからない」と答えます。
変更を加える前に調査を続けると、SQL Sentry PlanExplorerの[PlanTree]タブを見ると、いずれかのテーブルの推定行と実際の行の間に大きな偏りがあることがわかります。

2つの問題があるようです:
- charge_janテーブルスキャンの行の過小評価
- charge_febテーブルスキャンの行の過大評価
したがって、カーディナリティの推定値は 歪んでいて、これがパラメータスニッフィングに関連しているかどうか疑問に思います。パラメータのコンパイル済み値を確認し、それをパラメータの実行時の値と比較することにしました。これは、[パラメータ]タブに表示されます:

実際、実行時の値とコンパイルされた値には違いがあります。データベースを製品のようなテスト環境にコピーしてから、最初に2013年2月28日のランタイム値を使用してストアドプロシージャの実行をテストし、その後2013年1月31日をテストします。
2013年2月28日と2013年1月31日のプランの形状は同じですが、実際のデータフローは異なります。 2013年2月28日の計画とカーディナリティの見積もりは次のとおりです。
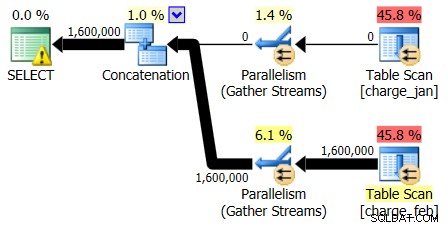

また、2013年2月28日の計画ではカーディナリティの推定の問題は示されていませんが、2013年1月31日の計画では次のようになっています。
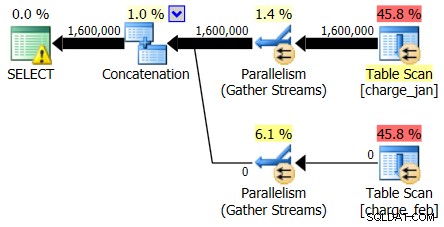

したがって、2番目の計画は、見た元の計画とは逆に、同じ過大評価と過小評価を示しています。
Charge_janテーブルとcharge_febテーブルの両方について、提案されたインデックスをprodのようなテスト環境に追加し、それがまったく役立つかどうかを確認することにしました。 1月/2月の順序でストアドプロシージャを実行すると、次の新しいプランの形状と関連するカーディナリティの見積もりが表示されます。
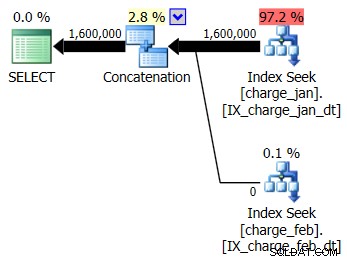

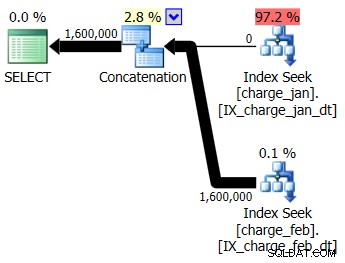

新しいプランでは、各テーブルからのインデックスシーク操作が使用されますが、一方のテーブルからはゼロ行が流れ、もう一方のテーブルからは流れません。また、実行時の値がコンパイルとは異なる月にある場合、パラメータースニッフィングに基づくカーディナリティ推定の偏りが見られます。時間値。
チームには、十分なメリットと関連する回帰テストの証明なしにインデックスを追加しないというポリシーがあります。とりあえず、作成した非クラスター化インデックスを削除することにしました。不足しているクラスター化にすぐに対処することはありませんが インデックス、後で処理することにします。
この時点で、次のようなストアドプロシージャの定義をさらに調べる必要があることに気付きます。
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
次に、charge_viewオブジェクトの定義を確認します。
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
ビューは、日付ごとに異なるテーブルに分割された料金データを参照します。次に、ストアドプロシージャの定義を変更することで、2番目のクエリ実行プランのスキューを防ぐことができるかどうか疑問に思います。
おそらく、オプティマイザが実行時に値を知っていれば、カーディナリティの見積もりの問題はなくなり、全体的なパフォーマンスが向上しますか?
先に進み、次のようにストアドプロシージャの呼び出しを再定義し、RECOMPILEヒントを追加します(これによりCPU使用率が増加する可能性があることも聞いていますが、これはテスト環境であるため、試してみても安全です):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
次に、2013年1月31日の値を使用してから、2013年2月28日の値を使用して、ストアドプロシージャを再実行します。
計画の形状は同じままですが、カーディナリティの見積もりの問題は削除されました。
2013年1月31日のカーディナリティ推定データは、次のことを示しています。

また、2013年2月28日のカーディナリティ推定データは次のことを示しています。

それは少しの間あなたを幸せにします、しかしそれからあなたは全体的なクエリ実行の期間が以前と比較的同じように見えることに気づきます。あなたは、開発者があなたの結果に満足するだろうという疑いを持ち始めます。カーディナリティの見積もりの偏りを解決しましたが、期待されるパフォーマンスの向上がなければ、意味のある方法で支援したかどうかはわかりません。
この時点で、クエリ実行プランは必要な情報のサブセットにすぎないことに気付いたので、[テーブルI / O]タブを確認して、調査をさらに拡大します。 2013年1月31日の実行について、次の出力が表示されます。

また、2013年2月28日の実行では、同様のデータが表示されます。

その時点で、両方のデータアクセス操作かどうか疑問に思います。 各プランにはテーブルが必要です。オプティマイザーが1月の行のみが必要であることがわかっている場合、なぜ2月にアクセスするのか、またはその逆の場合はどうでしょうか。また、クエリオプティマイザには、存在しないという保証はありません。 テーブル自体の制約によって明示的に保証されていない限り、「間違った」テーブルの他の月の実際の行。
各テーブルのsp_helpを介してテーブル定義を確認しましたが、どちらのテーブルにも制約が定義されていません。
したがって、テストとして、次の2つの制約を追加します。
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
ストアドプロシージャを再実行すると、次のプランの形状とカーディナリティの見積もりが表示されます。
2013年1月31日実行:
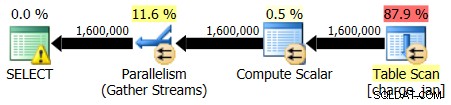

2013年2月28日実行:


表I/Oをもう一度見ると、2013年1月31日の実行について次の出力が表示されます。

また、2013年2月28日の実行についても同様のデータが表示されますが、charge_febテーブルについては次のようになります。

RECOMPILEがまだストアード・プロシージャー定義にあることを思い出して、それを削除して、同じ効果が見られるかどうかを確認してみてください。これを実行すると、2つのテーブルのアクセスが返されますが、行がないテーブルの実際の論理読み取りはありません(制約のない元のプランと比較して)。たとえば、2013年1月31日の実行では、次のテーブルI/O出力が表示されました。

新しいCHECK制約とRECOMPILEソリューションの負荷テストを進め、プラン(および関連するプランオペレーター)からテーブルアクセスを完全に削除することにしました。また、クラスター化されたインデックスキーと、現在関連付けられているテーブルにアクセスする幅広いワークロードのセットに対応する適切なサポートされている非クラスター化されたインデックスについての議論の準備をします。