クエリを実行するとき、SQL Serverオプティマイザーは、もちろん、このプランがサーバーキャッシュにまだ格納されていない場合、既存のインデックスと利用可能な最新の統計に基づいて最適なクエリプランを妥当な時間で見つけようとします。いいえの場合、クエリはこのプランに従って実行され、プランはサーバーキャッシュに保存されます。このクエリのプランがすでに作成されている場合、クエリは既存のプランに従って実行されます。
次の問題に関心があります:
クエリプランのコンパイル中に、可能なインデックスを並べ替えるときに、サーバーが最適なインデックスを見つけられない場合、不足しているインデックスはクエリプランにマークされ、サーバーはそのようなインデックスの統計を保持します:サーバーがこのインデックスを使用する回数このクエリにかかる費用。
この記事では、これらの欠落しているインデックスを分析します–それらを処理する方法。
特定の例でこれを考えてみましょう。ローカルサーバーとテストサーバーのデータベースにいくつかのテーブルを作成します。
[expand title =” Code”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/エキスパンド]
構造は単純で、2つのテーブルで構成されています。最初のテーブルは、識別子、販売日、販売者などのフィールドを持つ注文と呼ばれます。 2つ目は注文の詳細で、一部の商品は価格と数量で指定されます。
簡単なクエリとその計画を見てください:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
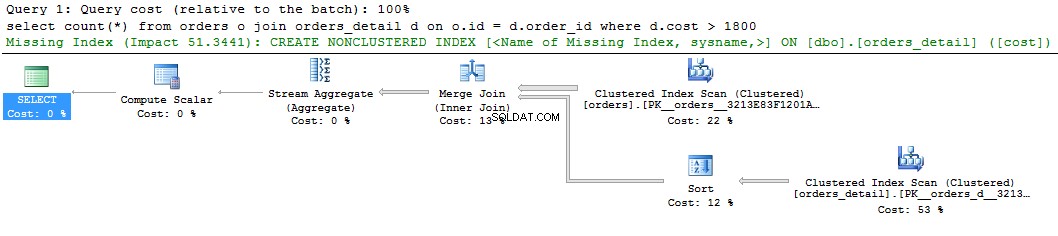
クエリプランのグラフィック表示に、欠落しているインデックスに関する緑色のヒントが表示されます。それを右クリックして「MissingIndexDetails..」を選択すると、提案されたインデックスのテキストが表示されます。唯一行うことは、テキスト内のコメントを削除し、インデックスに名前を付けることです。スクリプトを実行する準備ができました。
SSMSによって提供されたヒントから受け取ったインデックスは作成しません。代わりに、このインデックスが、欠落しているインデックスにリンクされた動的ビューによって推奨されるかどうかを確認します。ビューは次のとおりです。
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
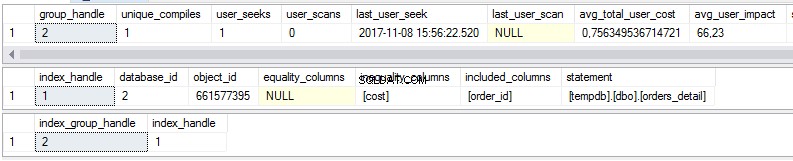
ご覧のとおり、最初のビューには欠落しているインデックスに関する統計がいくつかあります。
- 提案されたインデックスが存在する場合、検索は何回実行されますか?
- 提案されたインデックスが存在する場合、スキャンは何回実行されますか?
- インデックスを使用した最新の日時
- 提案されたインデックスを含まないクエリプランの現在の実際のコスト。
2番目のビューはインデックス本体です:
- データベース
- オブジェクト/テーブル
- 並べ替えられた列
- インデックスカバレッジを増やすために追加された列
3番目のビューは、1番目と2番目のビューの組み合わせです。
したがって、これらの動的ビューから欠落しているインデックスを作成するスクリプトを生成するスクリプトを取得することは難しくありません。スクリプトは次のとおりです。
[expand title =” Code”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/エキスパンド]
インデックスの効率を上げるために、欠落しているインデックスが出力されます。完璧な解決策は、この結果セットが何も返さない場合です。この例では、結果セットは少なくとも1つのインデックスを返します:

時間がなく、クライアントのバグに対処したくない場合は、クエリを実行し、最初の列をコピーしてサーバー上で実行しました。この後、すべてがうまくいきました。
これらのインデックスの情報を意識的に扱うことをお勧めします。たとえば、システムが次のインデックスを推奨している場合:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
そして、これらのインデックスは検索に使用されます。これらのインデックスを、提案された3つすべてをカバーするインデックスに置き換える方が論理的であることは明らかです。
create index ix_1 on tbl1 (a,b) include (c,d)
したがって、本番サーバーにデプロイする前に、欠落しているインデックスを確認します。それでも…。繰り返しになりますが、たとえば、失われたインデックスをTFSサーバーにデプロイして、全体的なパフォーマンスを向上させました。この最適化を実行するのに最小限の時間がかかりました。しかし、TFS2015からTFS2017に変更すると、これらの新しいインデックスが原因で更新が行われないという問題に直面しました。それにもかかわらず、それらはマスクによって簡単に見つけることができます
select * from sys.indexes where name like 'ix[_]2017%'
便利なツール:
dbForge Index Manager – SQLインデックスのステータスを分析し、インデックスの断片化に関する問題を修正するための便利なSSMSアドイン。