時系列データベースは、その名前が示すように、時間とともに変化するデータを格納するように設計されています。これは、時間の経過とともに収集されたあらゆる種類のデータである可能性があります。一部のシステムから収集された指標である可能性があり、実際には、すべてのトレンドシステムが時系列データの例です。
さまざまなタイプの時系列データベースがありますが、どれを使用する必要がありますか?
このブログでは、TimescaleDBとInfluxDBの2つの主要なオプションの主な違いを説明します。
InfluxDB
InfluxDBはInfluxDataによって作成されました。これは、Goで記述されたカスタムのオープンソースのNoSQL時系列データベースです。データストアは、InfluxQLと呼ばれるデータをクエリするためのSQLに似た言語を提供します。これにより、開発者はアプリケーションに簡単に統合できます。また、Fluxと呼ばれる新しいカスタムクエリ言語があります。この言語を使用すると、一部のタスクが簡単になる場合がありますが、カスタムクエリ言語を採用する場合は常に学習曲線があります。
これはFluxクエリの例です:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()このデータベースでは、各測定値にタイムスタンプと、関連するタグのセットおよびフィールドのセットがあります。フィールドは実際の測定値を表し、タグは測定値を説明するメタデータを表します。フィールドのデータ型は、float、int、strings、およびbooleansに制限されており、データを書き換えずに変更することはできません。タグ値にはインデックスが付けられます。これらは文字列として表され、更新できません。
InfluxDBは、スキーマやインデックスの作成について心配する必要がないため、非常に簡単に開始できます。ただし、これは非常に厳格で制限があり、追加のインデックスの作成、連続フィールドのインデックス、事後のメタデータの更新、データ検証の実施などはできません。
スキーマレスではありません。入力データから自動作成される基礎となるスキーマがあります。
InfluxDBは、レプリケーション、高可用性、バックアップ/復元などのフォールトトレランスのためのいくつかのツールを最初から実装する必要があり、ディスク上の信頼性に責任があります。これらのツールの使用に制限されており、HAなどのこれらの機能の多くは、エンタープライズバージョンでのみ使用できます。
InfluxDBバックアップツールは、完全バックアップまたは増分バックアップを実行でき、ポイントインタイムリカバリに使用できます。
InfluxDBは、PostgreSQLやTimescaleDBよりも大幅に優れたオンディスク圧縮も提供します。
TimescaleDB
TimescaleDBは、完全なSQLをサポートする、高速な取り込みと複雑なクエリ用に最適化されたオープンソースの時系列データベースです。 PostgreSQLに基づいており、時系列データに最高のNoSQLとリレーショナルの世界を提供します。
これはTimescaleDBクエリの例です:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';PostgreSQL拡張機能としてのTimescaleDBは、リレーショナルデータベースです。これにより、新規ユーザーの学習曲線が短くなり、バックアップ用のpg_dumpやpg_backupなどのツールや、他の時系列データベースの前にある高可用性ツールを継承できます。また、高可用性セットアップで使用できるレプリケーションの主要な方法としてストリーミングレプリケーションもサポートしています。フェイルオーバーとバックアップに関しては、ClusterControlなどの外部システムを使用してこのプロセスを自動化できます。
TimescaleDBでは、各時系列測定値が独自の行に記録され、時間フィールドの後に、浮動小数点数、整数、文字列、ブール値、配列、JSONブロブ、地理空間ディメンション、日付/時刻など、他の任意の数のフィールドが続きます。タイムスタンプ、通貨、バイナリデータなど。
任意のフィールド(標準インデックス)または複数のフィールド(複合インデックス)、あるいは関数などの式にインデックスを作成したり、インデックスを行のサブセット(部分インデックス)に制限したりすることもできます。これらのフィールドはいずれも、追加のメタデータを格納できるセカンダリテーブルへの外部キーとして使用できます。
このように、スキーマを選択し、システムに必要なインデックスを決定する必要があります。
パフォーマンス
パフォーマンスについて話す場合は、すばらしいTimescaleDB比較ブログを確認できます。ここに、チャートとメトリックを使用した両方のデータベース間のパフォーマンスの詳細な比較があります。このブログからの最も重要な情報のいくつかを見てみましょう。
挿入
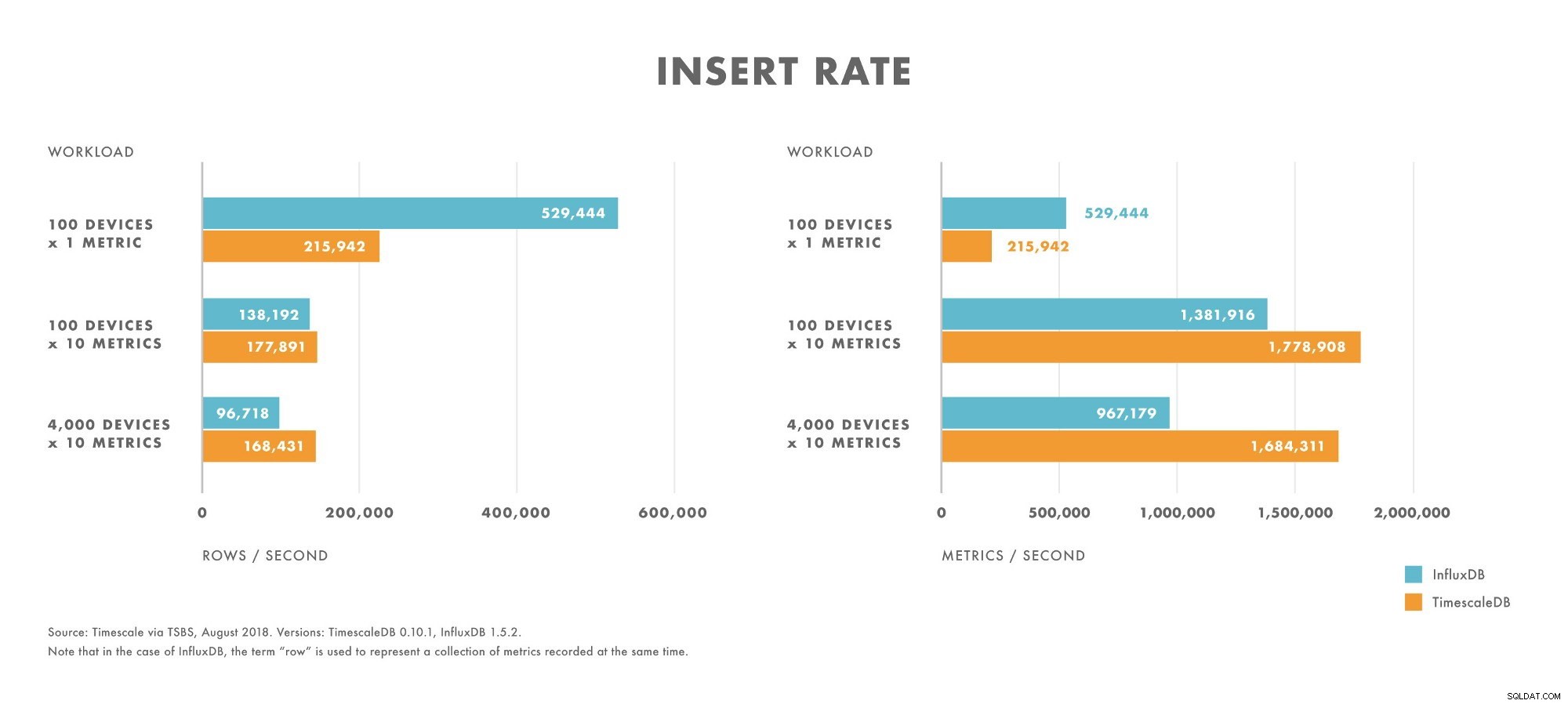
- カーディナリティが非常に低いワークロード(100台のデバイスなど)の場合、InfluxDBはTimescaleDBよりも優れています。
- カーディナリティが増加すると、InfluxDBの挿入パフォーマンスはTimescaleDBよりも速く低下します。
- カーディナリティが中程度から高いワークロード(たとえば、100台のデバイスが10個のメトリックを送信する)の場合、TimescaleDBはInfluxDBよりも優れています。

読み取りレイテンシ
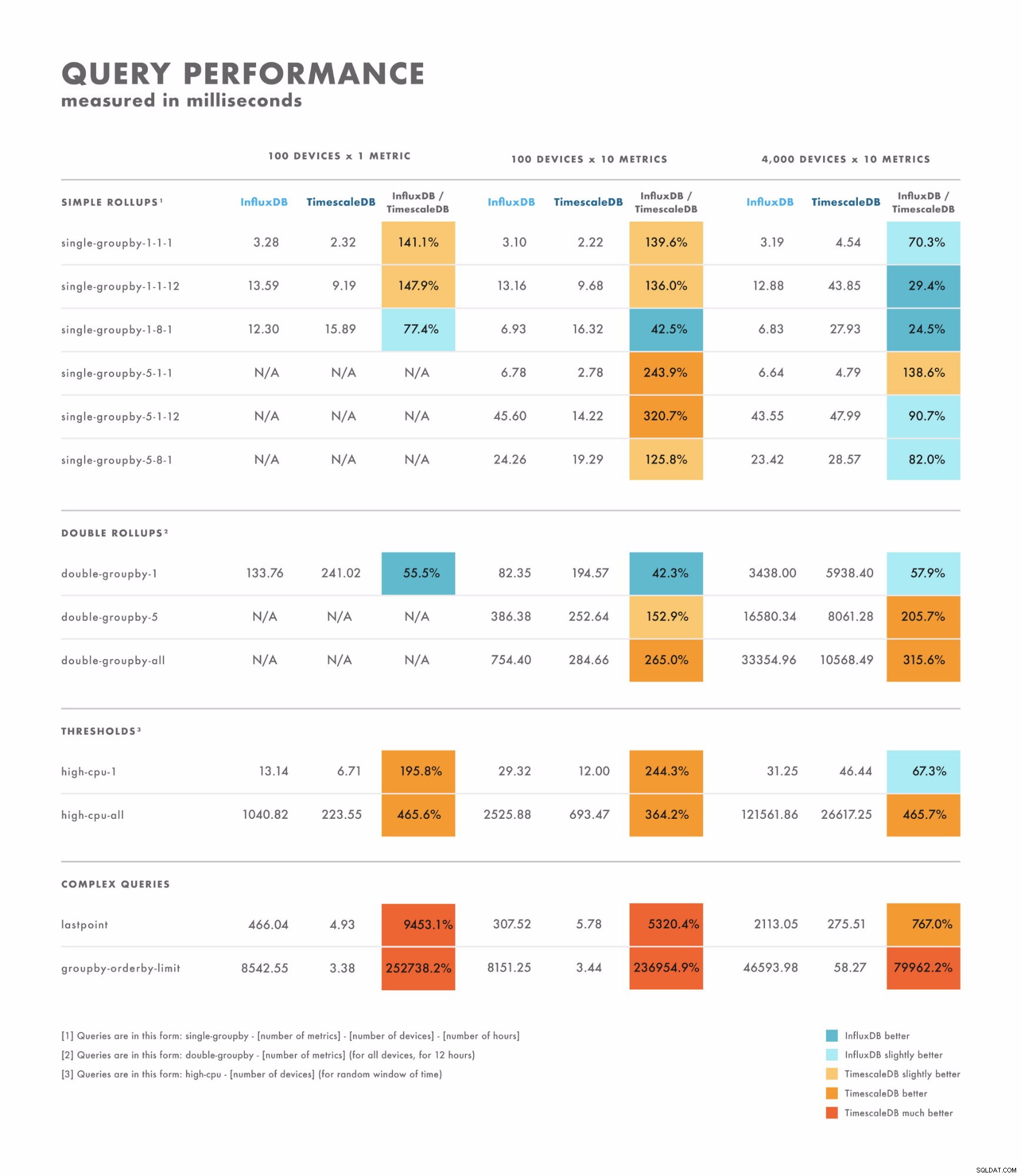
- 単純なクエリの場合、結果はかなり異なります。一方のデータベースが他方よりも明らかに優れている場合もあれば、データセットのカーディナリティに依存する場合もあります。ここでの違いは、多くの場合、1桁から2桁のミリ秒の範囲です。
- 複雑なクエリの場合、TimescaleDBはInfluxDBを大幅に上回り、幅広いクエリタイプをサポートします。ここでの違いは、多くの場合、数秒から数十秒の範囲です。
- そのことを念頭に置いて、適切にテストするための最良の方法は、実行する予定のクエリを使用してベンチマークを行うことです。
安定性の問題
- InfluxDBには、高い(100K以上)カーディナリティでの安定性とパフォーマンスの問題があります。
結論
データがInfluxDBデータモデルに適合し、将来変更される予定がない場合は、InfluxDBの使用を検討する必要があります。これは、このモデルの使用を開始するのが簡単であり、列指向のアプローチを使用するほとんどのデータベースと同様に、 PostgreSQLやTimescaleDBよりも優れたオンディスク圧縮を提供します。
ただし、リレーショナルモデルはより用途が広く、InfluxDBモデルよりも多くの機能、柔軟性、および制御を提供します。これは、アプリケーションが進化するにつれて特に重要になります。また、システムを計画するときは、現在と将来の両方のニーズを考慮する必要があります。
このブログでは、TimescaleDBとInfluxDBの簡単な比較を見ることができます。また、TimescaleDBはPostgreSQLの拡張機能であり、PostgreSQLから多くを継承しているため、かなり成熟していて機能が豊富に見えます。ただし、このブログで前述した長所と短所に基づいて独自の決定を下し、自分のワークロードのベンチマークを確認することができます。この新しい時系列データベースの世界で頑張ってください!