最小限のロギングの達成 INSERT ... SELECTを使用する 空に クラスタ化されたインデックスターゲットは、データパフォーマンス読み込みガイドで説明されているほど単純ではありません。 。
この投稿は新しい詳細を提供します 最小限のロギングの要件について 挿入ターゲットが空の従来のクラスター化インデックスである場合。 (そこにある「従来の」という言葉は、列ストアを除外します およびメモリ最適化 (「ヘカトン」)クラスター化されたテーブル)。ターゲットテーブルがヒープの場合に適用される条件については、このシリーズの前の記事を参照してください。
データ読み込みパフォーマンスガイド 最小限のロギングに必要な条件の概要が含まれています クラスタ化されたテーブルに:
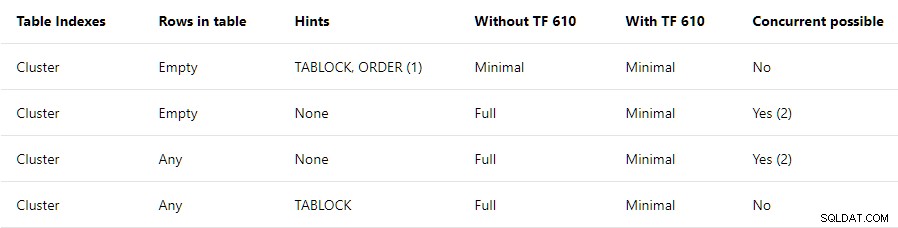
この投稿は一番上の行のみに関係しています 。 TABLOCK およびORDER ヒントが必要であり、次のようなメモが必要です。
BULK INSERTを使用する場合は、注文ヒントを使用する必要があります。
要約の一番上の行は、すべて 空のクラスター化されたインデックスへの挿入は、最小限に記録されます
他の一括読み込み方法とは異なり、不可能 必要な
SQLServerが
(これにより、ヒープの最小ロギングの条件が思い出される場合があります。 、ただし、必要な推定 ここでのデータサイズは8ページではなく2ページです。)
推定データサイズ ここでの計算は、8バイトの RID を除いて、ヒープについて前の記事で説明したのと同じ癖の影響を受けます。 存在しません。
SQL Server 2012以前の場合、これは5バイトの追加を意味します 行ごとがデータサイズの計算に含まれます:内部ビットの場合は1バイト フラグ、および uniquifierの4バイト (一意性関数を格納しない一意のインデックスの場合でも計算に使用されます 。
SQL Server 2014以降の場合、 uniquifier 一意の場合は正しく省略されます インデックスがありますが、1バイト余分に 内部ビットの場合 フラグは保持されます。
次のスクリプトは、新しいテストデータベースの開発SQLServerインスタンスで実行する必要があります。
デモでは、
(SQL Server 2012以前でスクリプトを実行する場合は、
出力は、挿入されたすべての行が完全にログに記録されたことを示しています 空にもかかわらず ターゲットのクラスター化されたテーブルと
Clustered Index Insertの実行プランのプロパティ 演算子は、
計算の詳細(SQL Server 2014以降)は次のとおりです。
計算された行サイズ(61バイト)は、挿入ストリームに存在する内部メタデータの余分な1バイトによって、実際の行ストレージサイズ(60バイト)とは異なります。また、この計算では、ページヘッダーによって各ページで使用される96バイトや、行のバージョン管理のオーバーヘッドなどは考慮されていません。 SQL Server 2012での同じ計算 uniquifierの行ごとにさらに4バイトを追加します (前述のように、一意のインデックスには存在しません)。余分なバイトは、各ページに収まると予想される行が少ないことを意味します:
2番目の条件も満たされているので、
その他の興味深い点:
低カーディナリティ推定値に注意してください Clustered Index Insertで オペレーター。
たとえば、
キャッシュによる予期しない動作を回避する1つの方法は、
空の一括読み込み
推定 データサイズの計算を挿入しますしません 実行プランを乗算した結果と一致する推定行数 および推定行サイズ 挿入への入力のプロパティ オペレーター。内部計算には(誤って)挿入ストリームに1つ以上の内部列が含まれていますが、これらは最終インデックスに保持されていません。内部計算では、ページヘッダーや行のバージョン管理などの他のオーバーヘッドも考慮されていません。
最小限のロギングをテストまたはデバッグする場合 問題が発生し、カーディナリティの見積もりが低くなることに注意してください。また、
このシリーズの最後のパートでは、最小限のロギングを達成するために必要な条件について詳しく説明します。 TABLOCKである限り およびORDER ヒントが指定されます。 TABLOCK RowSetBulkを有効にするにはヒントが必要です ヒープテーブルのバルクロードに使用される機能。 ORDER 行がClusteredIndex Insert に確実に到達するには、ヒントが必要です。 ターゲットインデックスのプラン演算子キーオーダー 。この保証がないと、SQL Serverは正しくソートされていないインデックス行を追加する可能性があり、これは適切ではありません。ORDERを指定します INSERT ... SELECTに関するヒント 声明。このヒントは同じではありません ORDER BYを使用する場合 INSERT ... SELECTの句 声明。 ORDER BY INSERTの句 アイデンティティの方法を保証するだけです 行の挿入順序ではなく、値が割り当てられます。 INSERT ... SELECTの場合 、SQLServerは独自の決定を行います 行がClusteredIndex Insertに表示されるようにするかどうか キー順の演算子かどうか。この評価の結果は、 DMLRequestSortを通じて実行計画に表示されます。 挿入のプロパティ オペレーター。 DMLRequestSort プロパティ必須 trueに設定する INSERT ... SELECTの場合 最小限に記録されるインデックスに 。 falseに設定されている場合 、最小限のロギング 発生しません。 DMLRequestSortがある trueに設定 唯一の許容可能な保証です SQLServerの挿入入力順序の説明。実行計画を調べて予測するかもしれません その行はクラスター化インデックスの順序で到着する必要があり、到着する必要がありますが、特定の内部保証はありません。 DMLRequestSortによって提供されます 、その評価は無意味です。 DMLRequestSortの場合 true 、SQL Server may 明示的な並べ替えを導入する 実行プランの演算子。他の方法で注文を内部的に保証できる場合は、並べ替え 省略できます。並べ替えと並べ替えなしの両方の選択肢が利用できる場合、オプティマイザーはコストベースを作成します 選択。コスト分析では、最小限のロギングは考慮されていません。 直接;これは、シーケンシャルI/Oの期待される利点とページ分割の回避によって推進されます。DMLRequestSort条件
DMLRequestSortの設定を選択するには、次の両方のテストに合格する必要があります。 true テーブルロックが指定された空のクラスター化インデックスに挿入する場合:
SIMPLEを使用するように設定 またはBULK_LOGGED リカバリーモデル。 INSERT ... SELECT を使用して、268行を新しいクラスター化テーブルにロードします。 TABLOCKを使用 、および生成されたトランザクションログレコードに関するレポート。IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; TOPを変更してください。 後で説明する理由により、スクリプトの268から252までの句。)TABLOCK ヒント: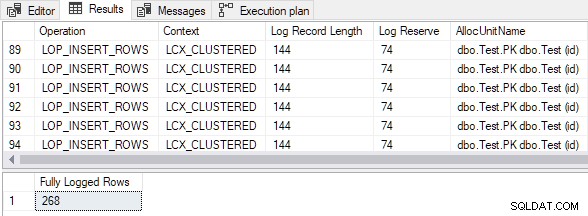
DMLRequestSort falseに設定されています 。これは、挿入する行の推定数が250を超えているにもかかわらず(最初の要件を満たしている)、計算された データサイズはありません 2つの8KBページを超えています。
ビット =1バイト(内部)。 integer =4バイト( id 列)。 integer =4バイト( c1 列)。 char(45) =45バイト(パディング 列)。
TOPの変更 268行から269行(または2012年の場合は252行から253行)の句により、予想されるデータサイズの計算がちょうど 2ページの最小しきい値を超えるチップ:
DMLRequestSort trueに設定されています 、および最小限のロギング 以下の出力に示すように、達成されます: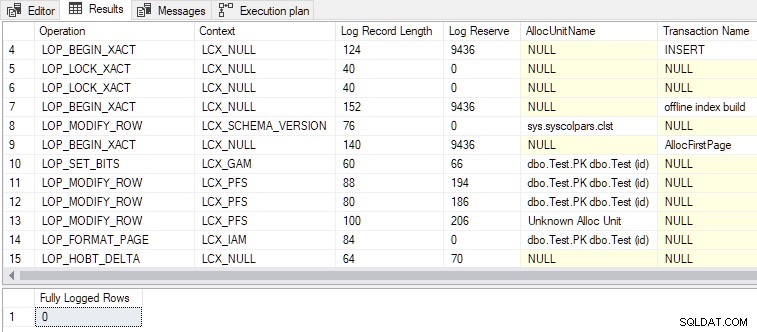
LOP_BEGIN_XACT 最小限のログのレコード レコードは比較的大量のログスペース(それぞれ9436バイト)を予約します。 Tab-X )、最小限のログ 挿入はスキーマの変更を行います( Sch-M )「実際の」オフラインインデックスビルドと同じように。 INSERT ... SELECTを使用して空のクラスター化テーブルを一括読み込みする TABLOCKを使用 およびDMRequestSort trueに設定 RowsetBulkを使用します 最小限のログと同じようにメカニズム ヒープロードは前の記事で行いました。 DMLRequestSortを設定するために必要なしきい値のいずれか true カーディナリティの推定が不正確なために到達しなかった場合、挿入は完全にログに記録されます 、実行時に発生した実際の行数と合計データサイズに関係なく。 TOPを変更します デモスクリプトの句で変数を使用すると、カーディナリティが固定されます guess 100行のうち、最小251行を下回っています:-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; DMLRequestSort プロパティは、キャッシュされたプランの一部として保存されます。キャッシュされたプランが再利用された場合 、 DMLRequestSortの値 再計算されません 再コンパイルが発生しない限り、実行時に。 TRIVIALでは再コンパイルは発生しないことに注意してください 統計またはテーブルカーディナリティの変更に基づく計画。 OPTION(RECOMPILE)を使用することです。 ヒント。これにより、 DMLRequestSortの適切な設定が保証されます 実行ごとにコンパイルが発生しますが、再計算されます。 DMLRequestSortを強制することが可能です trueに設定する 文書化されていない、サポートされていないを設定する データを変更するT-SQLクエリの最適化で書いたように、フラグ2332をトレースします。残念ながら、これはありません 最小限のロギングに影響を与える 空のクラスター化されたテーブルの適格性—挿入は250行と2ページを超えて見積もる必要があります。このトレースフラグは、他の最小ログに影響します。 このシリーズの最後の部分で説明するシナリオ。 INSERT ... SELECTを使用したクラスター化されたインデックス RowsetBulkを再利用します ヒープテーブルを一括ロードするために使用されるメカニズム。これにはテーブルロックが必要です(通常は TABLOCKで実現されます ヒント)と ORDER ヒント。 ORDERを追加する方法はありません INSERT ... SELECTへのヒント 声明。結果として、最小限のロギングを達成します 空のクラスター化されたテーブルにするには、 DMLRequestSortが必要です。 Clustered Index Insertのプロパティ 演算子はtrueに設定されています 。この保証 Insertに表示される行をSQLServerに送信します オペレーターは、ターゲットインデックスキーの順序で到着します。効果は、 ORDERを使用した場合と同じです。 BULK INSERTなどの他の一括挿入メソッドで使用できるヒント およびbcp 。 DMLRequestSortの場合 trueに設定する 、必要があります:
DMLRequestSortの設定に注意してください。 実行計画の一部としてキャッシュされます。 RowsetBulkを使用せずに 機構。これらは、トレースフラグ610でSQL Server 2008に追加され、SQLServer2016以降でデフォルトでオンに変更された新しい機能に直接対応しています。