Forwarded Recordsのパフォーマンスの問題を確認して解決する前に、SQLServerテーブルの構造を確認する必要があります。
テーブル構造の概要
SQL Serverでは、データストレージの基本単位は8KBページです。 。各ページは、そのページに関するシステム情報を格納する96バイトのヘッダーで始まります。次に、テーブルの行がヘッダーの後にシリアルにデータページに格納されます。ページの最後に、行ごとに1つのエントリを含む行オフセットテーブルが、ページ内の行の順序とは逆に格納されます。この行オフセットエントリは、その行の最初のバイトがページの先頭からどれだけ離れているかを示します。
SQL Serverは、そのテーブルの構造に基づいて、2種類のテーブルを提供します。 クラスター化 テーブルは、事前定義されたクラスター化インデックスキーの1つまたは複数の列の値に基づいて、データページ内のデータを格納および並べ替えます。さらに、クラスター化テーブル内のデータページは、クラスター化インデックスキー値に基づいて、リンクリストで並べ替えられてリンクされます。 Bツリー クラスター化インデックスの構造は、クラスター化インデックスのキー値に基づく高速データアクセス方法を提供します。新しい行が挿入された場合、または既存のキー値がクラスター化テーブルで更新された場合、SQL Serverは、順序付け基準に違反することなく、挿入された行サイズに適合する正しい論理位置に新しい値を格納します。挿入または更新された値がデータページの使用可能なスペースよりも大きい場合、ページは新しい値に合わせて2つのページに分割されます。
2番目のタイプのテーブルはヒープです テーブル。データはデータページ内で任意の順序で並べ替えられておらず、そのテーブルにはクラスター化インデックスが定義されていないため、ページはリンクされていません。これにより、並べ替え基準が適用されます。順序付け基準でソートされていないページ、またはヒープテーブルでリンクされていないページを追跡することは簡単な作業ではありません。ヒープテーブル内のページ割り当ての追跡プロセスを簡素化するために、SQLServerはインデックス割り当てマップを使用します (IAM)、ヒープテーブル内のデータページ間の唯一の論理接続。テーブル内の各データページまたはIAMテーブル内のインデックスのエントリを保持します。ヒープテーブルからデータを取得するために、SQL ServerエンジンはIAMをスキャンしてエクステントを特定します。エクステントは、要求されたデータを格納する8ページを形成します。
転送レコードの問題
新しい行がヒープテーブルに挿入されると、SQLServerエンジンはページの空き領域をスキャンします (PFS)ページは、挿入された行サイズに適合するデータページ内の最初の使用可能な場所を見つけるために、各データページの割り当てステータスとスペース使用量を追跡します。次に、選択したページに行が追加されます。挿入された値がデータページの使用可能なスペースよりも大きい場合、新しい値を挿入できるように、そのテーブルに新しいページが追加されます。
一方、ヒープテーブル内の既存のデータが変更された場合、たとえば、より大きなデータサイズで可変長の文字列を更新し、現在のスペースが新しいデータに適合しない場合、データは別の物理に移動されます場所と転送されたレコード 元のデータの場所のヒープテーブルに挿入され、そのデータの新しい場所を指し示し、追跡データの場所を簡素化します。新しいデータの場所には、新しい場所からデータを移動する場合にデータを最新の状態に保ち、長い転送ポインターチェーンを防止したり、データを削除したりするために、転送ポインターを指すポインターも含まれています。これにより、転送レコードも削除される可能性があります。
Forwarded Recordsリダイレクト方式では、リソースを大量に消費するテーブルと非クラスター化インデックスの再構築操作の必要性が減り、データの場所が変更されるたびにデータアドレスが更新されますが、データの取得に必要な読み取り回数も2倍になります。 SQL Serverは最初に古い場所にアクセスし、新しいデータの場所にリダイレクトする転送済みレコードを見つけます。次に、要求されたデータを読み取り、読み取り操作を2回実行します。さらに、転送されたレコードの問題により、読み取られたシーケンシャルデータがランダムデータ読み取りに変更され、時間の経過とともにデータ取得操作のパフォーマンスに悪影響が及びます。
次のForwardRecordDemoヒープを作成しましょう 以下のCREATETABLET-SQLステートメントを使用したテーブル:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
次に、以下のINSERT INTO T-SQLステートメントを使用して、テスト目的でそのテーブルに3Kレコードを入力します。
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 転送されたレコードの問題の特定
sys.dm_db_index_physical_stats > システム動的管理機能とDETAILEDへの受け渡し 転送レコードの数を返すモード。これを行うには、以下のT-SQLスクリプトを使用します。
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
クエリ結果からわかるように、前のテーブルは、ページ内のデータを並べ替えてページを相互にリンクするためのクラスター化インデックスが作成されていないヒープテーブルです。テーブルに挿入された3K行は、 15に割り当てられます 以下の結果に示すように、転送されたレコードがなく、断片化の割合がゼロのデータページ:

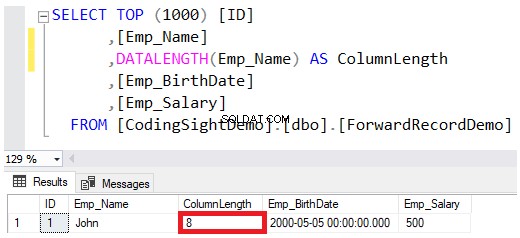
列のデータ型をVARCHARまたはNVARCHARとして定義する場合、データ型定義で指定された値は、データページに値を保存するときにその量を完全に予約せずに、その文字列に許可される最大サイズです。たとえば、ジョン そのテーブルに挿入された従業員名は、 DATALENGTH > 以下の関数結果:
John従業員のフルネームを含めるためにEmp_Name列の値を更新する場合は、以下のUPDATEステートメントを使用してください。
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
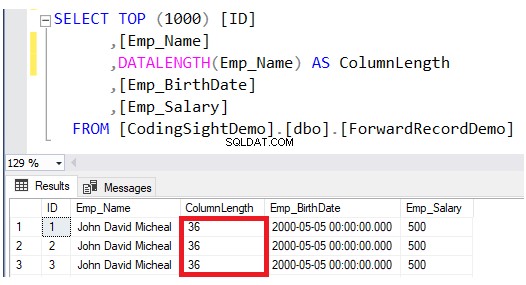
DATALENGTH を使用して、更新された列の長さを確認してください 働き。更新された行のEmp_Name列の長さが28拡張されていることがわかります。 各列あたりのバイト数。これは約3.5 以下の結果に示すように、そのテーブルへの追加のデータページ:
次に、sys.dm_db_index_physical_statsシステム動的管理関数を照会して、更新操作後に転送されたレコードの数を確認します。これを行うには、以下のT-SQLスクリプトを使用します。
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
ご覧のとおり、新しいレコードを追加せずに、より大きな文字列値で1KレコードのEmp_Name列を更新すると、追加の 5が割り当てられます。 以前に予想された3.5ページではなく、そのテーブルへのページ。これは、 484を生成するために発生します 移動されたデータの新しい場所を指すようにレコードを転送しました。これにより、テーブルが 33%になる可能性があります 以下に明確に示すように、断片化されています:

繰り返しになりますが、Emp_Name列の値を更新して、Zaid従業員のフルネームを含めることができた場合は、以下のUPDATEステートメントを使用してください。
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
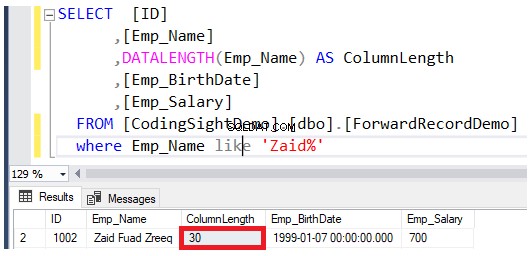
DATALENGTH を使用して、更新された列の長さを確認してください 働き。更新された行のEmp_Name列の長さが22拡張されていることがわかります。 各列あたりのバイト数。これは約2.7 以下の結果に示すように、そのテーブルに追加された追加のデータページ:
更新操作を実行した後、転送されたレコードの数を確認してください。これを行うには、以下の同じT-SQLスクリプトを使用してsys.dm_db_index_physical_statsシステム動的管理関数をクエリします。
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
結果は、新しい行を挿入せずに、他の1KレコードのEmp_Name列をより大きな文字列値で更新すると、別の 4が割り当てられることを示しています。 予想どおり2.7ページではなく、そのテーブルのページ。これは、追加の 417を生成するために発生します 移動されたデータの新しい場所を指し示し、同じ 33%を維持するために、レコードを転送しました 以下に示すように、断片化の割合:

転送されたレコードの問題の修正
転送されたレコードの問題を修正する最も簡単な方法は、列に格納される文字列の最大長を見積もり、固定長を使用して割り当てることです。 可変長データ型を使用するのではなく、その列のデータ型。転送されたレコードの問題を修正するための最適な永続的な方法は、クラスター化されたインデックスを追加することです。 そのテーブルに。このようにして、テーブルは完全にクラスター化されたテーブルに変換され、クラスター化されたインデックスキー値に基づいて並べ替えられます。この記事の冒頭で前述したように、既存のデータ、データページの現在の使用可能なスペースに適合しない新しく挿入および更新されたデータの順序を制御します。
そのテーブルにクラスター化インデックスを追加することがステージングテーブルやETLテーブルなどの特定の要件のオプションではない場合は、転送レコードを監視し、ヒープテーブルを再構築して削除することで、転送レコードの問題を一時的に克服できます。また、そのヒープテーブルのすべての非クラスター化インデックスを更新します。ヒープテーブルを再構築する機能は、ALTERTABLE…REBUILDを使用してSQLServer2008で導入されました。 T-SQLコマンド。
転送されたレコードがデータ取得クエリに与えるパフォーマンスへの影響を確認するには、Emp_Name列の値に基づいて検索を実行するSELECTクエリを実行します。ただし、クエリを実行する前に、TIME統計とIO統計を有効にします。
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
その結果、 925 84ms 以内に要求されたデータを取得するために、論理読み取り操作が実行されます 以下に示すように:

転送されたすべてのレコードを削除するためにヒープテーブルを再構築するには、ALTERTABLE…REBUILDコマンドを使用します。
ALTER TABLE ForwardRecordDemo REBUILD;
同じSELECTステートメントを再度実行します:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
時間とIOの統計では、 21のみが示されます。 925と比較した論理読み取り操作 転送されたレコードを含む論理読み取り操作は、79ミリ秒以内に要求されたデータを取得するために実行されます :

ヒープテーブルを再構築した後に転送されたレコードの数を確認するには、sys.dm_db_index_physical_statsシステム動的管理関数を実行し、以下の同じT-SQLスクリプトを使用します。
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
21のみが表示されます 前の3のページ 転送されたレコードのために消費されたページは、データを格納するためにそのテーブルに割り当てられます。これは、データの挿入および更新操作(15 + 3.5 + 2.7)中に得られた推定結果と同様です。ヒープテーブルを再構築した後、転送されたすべてのレコードが削除されます。その結果、断片化のないテーブルができました:

転送されたレコードの問題は、データベース管理者が計画を立てるときに考慮する必要がある重要なパフォーマンスの問題です。ヒープテーブルのメンテナンス。以前の結果は、3Kレコードのみを含むテストテーブルから取得されます。巨大なテーブルから読み取るときに大量の転送レコードを読み取るために、転送レコードによって浪費されるページ数とI/Oパフォーマンスの低下を想像できます。
参照:
- ページとエクステントのアーキテクチャガイド
- dm_db_index_physical_stats(Transact-SQL)
- ALTER TABLE(Transact-SQL)
- 「転送されたレコード」について知っていると、見つけにくいパフォーマンスの問題を診断するのに役立ちます