この記事では、T-SQL(Transact-SQL)ウィンドウ関数と、日常のデータ分析タスクでの基本的な使用法について説明します。
データ分析に関しては、T-SQLに代わるものがたくさんあります。ただし、時間の経過に伴う改善とウィンドウ関数の導入を考慮すると、T-SQLは基本レベルで、場合によってはそれを超えてデータ分析を実行できます。
SQLウィンドウ関数について
まず、MicrosoftのドキュメントのコンテキストでSQLウィンドウ関数について理解しましょう。
Microsoftの定義
ウィンドウ関数は、ウィンドウ内の各行の値を計算します。
簡単な定義
ウィンドウ関数は、結果セットの特定の部分(ウィンドウ)に焦点を合わせるのに役立ち、結果セット全体ではなく、その特定の部分(ウィンドウ)でのみデータ分析を実行できます。
つまり、SQLウィンドウ関数は、データ分析の目的で結果セットをいくつかの小さなセットに変換します。
結果セットとは
簡単に言うと、結果セットは、SQLクエリの実行によって取得されたすべてのレコードで構成されます。
たとえば、 Productという名前のテーブルを作成できます 次のデータを挿入します:
-- (1) Create the Product table CREATE TABLE [dbo].[Product] ( [ProductId] INT NOT NULL PRIMARY KEY, [Name] VARCHAR(40) NOT NULL, [Region] VARCHAR(40) NOT NULL ) -- (2) Populate the Product table INSERT INTO Product (ProductId,Name,Region) VALUES (1,'Laptop','UK'),(2,'PC','UAE'),(3,'iPad','UK')
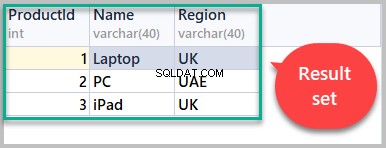
これで、以下のスクリプトを使用して取得された結果セットには、製品のすべての行が含まれます。 テーブル:
-- (3) Result set SELECT [ProductId], [Name],[Region] FROM Product
ウィンドウとは
SQLウィンドウ関数に関連するウィンドウの概念を最初に理解することが重要です。このコンテキストでは、ウィンドウは、結果セットの特定の部分をターゲットにすることによってスコープを絞り込むための単なる方法です(すでに前述したように)。
今疑問に思われるかもしれませんが、「結果セットの特定の部分をターゲットにする」とは実際にはどういう意味ですか?
見た例に戻ると、結果セットを2つのウィンドウに分割することで、製品領域に基づいてSQLウィンドウを作成できます。
Row_Number()について
続行するには、 Row_Number()関数を使用する必要があります これにより、出力行にシーケンス番号が一時的に与えられます。
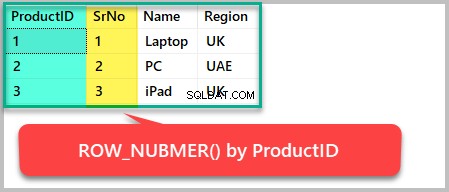
たとえば、ProductIDに基づいて結果セットに行番号を追加する場合 ROW_NUMBER()を使用する必要があります 次のように製品IDで注文するには:
--Using the row_number() function to order the result set by ProductID SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID) AS SrNo,Name,Region FROM Product
ここで、 Row_Number()関数が必要な場合 ProductIDで結果セットを注文するには 降順で、 ProductIDに基づく出力行のシーケンス 次のように変更されます:
--Using the row_number() function to order the result set by ProductID descending SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID DESC) AS SrNo,Name,Region FROM Product

私たちが行ったのは特定の基準でセットを並べ替えることだけなので、SQLウィンドウはまだありません。前に説明したように、ウィンドウ処理とは、結果セットをいくつかの小さなセットに分割して、それぞれを個別に分析することを意味します。
Row_Number()を使用したウィンドウの作成
結果セットにSQLウィンドウを作成するには、そこに含まれる列のいずれかに基づいてSQLウィンドウを分割する必要があります。
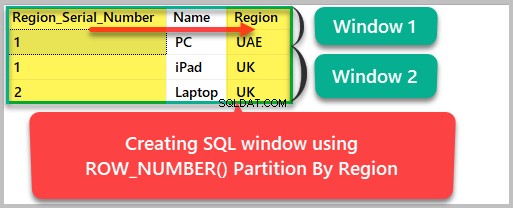
これで、結果セットを次のように地域ごとに分割できます。
--Creating a SQL window based on Region SELECT ROW_NUMBER() OVER (Partition by region ORDER BY Region) as Region_Serial_Number , Name, Region FROM dbo.Product
選択–条項を超える
つまり、選択 オーバーで 句は、結果セットをより小さなウィンドウに分割することにより、SQLウィンドウ関数への道を開きます。
Microsoftのドキュメントによると、選択 以上 句は、任意のウィンドウ関数で使用できるウィンドウを定義します。
それでは、 KitchenProductというテーブルを作成しましょう。 次のように:
CREATE TABLE [dbo].[KitchenProduct]
(
[KitchenProductId] INT NOT NULL PRIMARY KEY IDENTITY(1,1),
[Name] VARCHAR(40) NOT NULL,
[Country] VARCHAR(40) NOT NULL,
[Quantity] INT NOT NULL,
[Price] DECIMAL(10,2) NOT NULL
);
GO
INSERT INTO dbo.KitchenProduct
(Name, Country, Quantity, Price)
VALUES
('Kettle','Germany',10,15.00)
,('Kettle','UK',20,12.00)
,('Toaster', 'France',10,10.00)
,('Toaster','UAE',10,12.00)
,('Kitchen Clock','UK',50,20.00)
,('Kitchen Clock','UAE',35,15.00) それでは、表を見てみましょう:
SELECT [KitchenProductId], [Name], [Country], [Quantity], [Price] FROM dbo.KitchenProduct

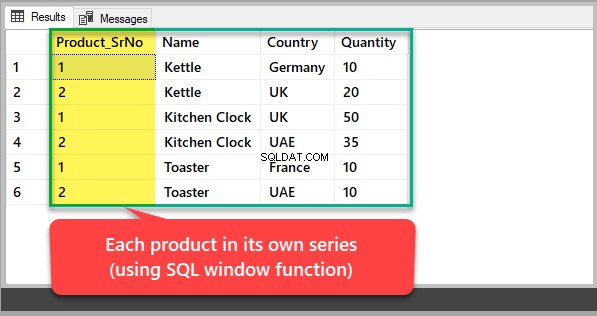
一般化された製品IDに基づく番号ではなく、独自のシリアル番号を持つ各製品を表示する場合は、SQLウィンドウ関数を使用して、次のように製品ごとに結果セットを分割する必要があります。
-- Viewing each product in its own series SELECT ROW_NUMBER() OVER (Partition by Name order by Name) Product_SrNo,Name,Country,Quantity FROM dbo.KitchenProduct
互換性(選択–条項を超える)
Microsoftのドキュメントによると 、Select – Over Clauseは、次のSQLデータベースバージョンと互換性があります。
- SQLServer2008以降
- AzureSQLデータベース
- AzureSQLデータウェアハウス
- 並列データウェアハウス
構文
SELECT – OVER(
構文を簡略化してiを作成したことに注意してください t わかりやすい;参照してください Microsoftのドキュメントを参照してください フル 構文。
前提条件
この記事は基本的に初心者向けに書かれていますが、覚えておく必要のある前提条件がいくつかあります。
T-SQLに精通している
この記事は、読者がT-SQLの基本的な知識を持ち、基本的なSQLスクリプトを記述して実行できることを前提としています。
Salesサンプルテーブルを設定する
この記事では、SQLウィンドウ関数の例を実行できるように、次のサンプルテーブルが必要です。
-- (1) Create the Sales sample table
CREATE TABLE [dbo].[Sales]
(
[SalesId] INT NOT NULL IDENTITY(1,1),
[Product] VARCHAR(40) NOT NULL,
[Date] DATETIME2,
[Revenue] DECIMAL(10,2),
CONSTRAINT [PK_Sales] PRIMARY KEY ([SalesId])
);
GO
-- (2) Populating the Sales sample table
SET IDENTITY_INSERT [dbo].[Sales] ON
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (1, N'Laptop', N'2017-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (2, N'PC', N'2017-01-01 00:00:00', CAST(100.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (3, N'Mobile Phone', N'2018-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (4, N'Accessories', N'2018-01-01 00:00:00', CAST(150.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (5, N'iPad', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (6, N'PC', N'2019-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (7, N'Laptop', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
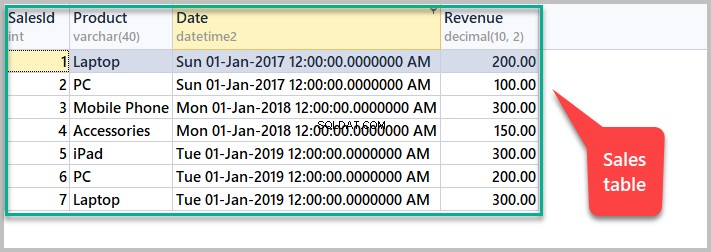
SET IDENTITY_INSERT [dbo].[Sales] OFF 次のスクリプトを実行して、すべての売上を表示します。
-- View sales SELECT [SalesId],[Product],[Date],[Revenue] FROM dbo.Salesを表示
GroupByとSQLウィンドウ関数
不思議に思うかもしれませんが、Group By句とSQLウィンドウ関数の使用の違いは何ですか?
答えは以下の例にあります。
例によるグループ化
製品ごとの総売上高を確認するために、次のようにGroupByを使用できます。
-- Total sales by product using Group By SELECT Product ,SUM(REVENUE) AS Total_Sales FROM dbo.Sales GROUP BY Product ORDER BY Product

したがって、Group By句は、総売上高を確認するのに役立ちます。総売上高は、GroupBy句が使用されていない同じ行のすべての類似製品の収益の合計です。個々の製品の収益(売上)と総売上を確認したい場合はどうなりますか?
ここでSQLウィンドウ関数が機能します。
SQLウィンドウ関数の例
同様のすべての製品の製品、収益、および総収益を確認するには、 OVER()を使用して副産物ごとにデータを分割する必要があります。 次のように:
-- Total sales by product using an SQL window function SELECT Product ,REVENUE ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) AS Total_Sales FROM dbo.Sales
出力は次のようになります。

これで、個々の製品の売上とその製品の総売上を簡単に確認できるようになりました。たとえば、 PCの収益 は100.00ですが、総売上高( PC の収益の合計) 2つの異なるPCモデルが販売されていたため、製品)は300.00です。
集計関数を使用した基本的な分析
集計関数は、一連のデータに対して計算を実行した後、単一の値を返します。
このセクションでは、SQLウィンドウ関数についてさらに詳しく説明します。具体的には、SQLウィンドウ関数を集計関数と一緒に使用して、基本的なデータ分析を実行します。
一般的な集計関数
最も一般的な集計関数は次のとおりです。
- 合計
- カウント
- 最小
- 最大
- 平均(平均)
製品ごとの集合体データ分析
集計関数を使用して副産物ベースで結果セットを分析するには、OVER()ステートメント内で副産物パーティションを持つ集計関数を使用する必要があります。
-- Data analysis by product using aggregate functions SELECT Product,Revenue ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY PRODUCT) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY PRODUCT) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY PRODUCT) as Average_Sales FROM dbo.Sales

PCをよく見ると またはラップトップ 製品、 SQLウィンドウ関数と一緒に集計関数がどのように連携しているかがわかります。
上記の例では、 PCの収益値がわかります。 初回は100.00、次回は200.00ですが、総売上高は300.00になります。残りの集計関数についても同様の情報が表示されます。
日付別の集合体データ分析
それでは、SQLウィンドウ関数を集計関数と組み合わせて使用して、日付ごとに製品のデータ分析を実行してみましょう。
今回は、結果セットを製品ではなく日付で次のように分割します。
-- Data analysis by date using aggregate functions SELECT Product,date,Revenue ,SUM(REVENUE) OVER (PARTITION BY DATE) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY DATE) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY DATE) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY DATE) as Average_Sales FROM dbo.Sales
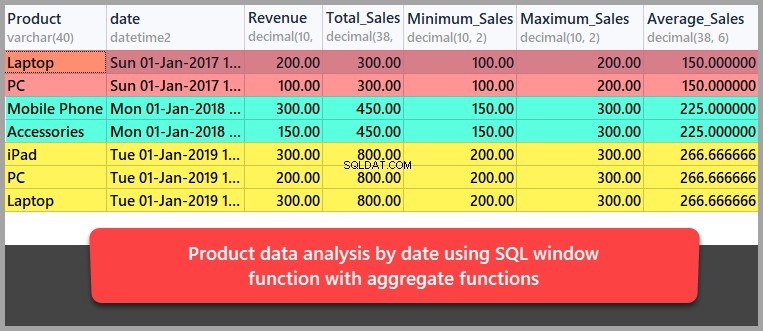
これにより、SQLウィンドウ関数アプローチを使用した基本的なデータ分析手法を学びました。
やるべきこと
SQLウィンドウ関数に慣れてきたので、次のことを試してください。
- 私たちが見た例を念頭に置いて、この記事で言及されているサンプルデータベースでSQLウィンドウ関数を使用して基本的なデータ分析を実行します。
- SalesサンプルテーブルにCustomer列を追加し、別の列(customer)が追加されたときにデータ分析がどれほど豊富になるかを確認します。
- SalesサンプルテーブルにRegion列を追加し、地域ごとの集計関数を使用して基本的なデータ分析を実行します。