データ管理のリレーショナルモデルは、1969年にエドガーF.コッド博士によって最初に開発されました。最新のリレーショナルデータベース管理システム(RDBMS)は、このパラダイムに沿っています。 RDBMSで識別される主要な構造は、「テーブル」と呼ばれる論理構造です。テーブルは主に行と列で構成されます(レコードと属性、またはタプルとフィールドとも呼ばれます)。厳密な数学的意味では、テーブルという用語 実際にはリレーションと呼ばれ、「リレーショナルモデル」という用語を説明します。数学では、関係は集合の表現です。
expression属性は、列の目的を適切に説明します。これは、列に関連付けられた行のセットを特徴づけます。各列は特定のデータ型である必要があり、各行には「キー」と呼ばれる固有の識別特性が必要です。データの変更は通常、リレーショナルモデルを使用して行うとより効率的になりますが、モデルNoSQLシステムで再定義された古い階層モデルを使用するとデータの取得が高速になる場合があります。
データの正規化は、ビジネスデータをフォームにモデル化する数学的プロセスであり、各エンティティが単一の関係(テーブル)で表されるようにします。リレーショナルモデルの初期の支持者は、正規形の概念を提案しました。 Edgar Coddは、第1、第2、および第3の正規形を定義しました。その後、レイモンドF.ボイスが加わりました。一緒に彼らはBoyce-Codd正規形を定義しました。これまでに、6つの正規形が理論的に定義されていますが、ほとんどの実際のアプリケーションでは、通常、正規化を3番目の正規形まで拡張します。各正規形は、データ変更中の異常を回避し、テーブル内のデータの冗長性と依存性を減らすように努めています。正規化の各レベルは、より多くのテーブルを導入し、冗長性を減らし、各テーブルの単純さを増すだけでなく、リレーショナルデータベース管理システム全体の複雑さを増す傾向があります。そのため、構造的にRDBMシステムは階層システムよりも複雑になる傾向があります。
データベースの正規化を行う理由:4つの異常
正規化なしのデータストレージは、データ消費に関して多くの問題を引き起こします。正規化の支持者は、そのような問題を異常と呼びました。これらの異常を説明するために、図1に示されているデータを見てみましょう。

図。 1人のスタッフテーブル
1.1。テーブルの作成
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2。行を挿入
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3。テーブルのクエリ
select * from staffers;
この表は、本質的に、誤って結合された2つのデータセット(スタッフ名と部門)を表しています。すべてのスタッフが同じ部門(エンジニアリング)の出身であることに注意してください。これは、単純化のため、および正規化を示すために行われました。この構造の操作に関連する主な問題は3つあります。
挿入異常
新しいレコードを挿入するには、部門名とマネージャー名を繰り返し続ける必要があります。
削除の異常
スタッフの記録を削除するには、関連するマネージャーと部門も削除する必要があります。すべてのスタッフの記録を削除する必要がある場合は、すべての部門とすべてのマネージャーも削除する必要があります。
更新の異常
部門のマネージャーを変更する必要がある場合は、スタッフごとに値が重複しているため、このテーブルのすべての行を変更する必要があります。
この記事の次のセクションでは、実際のRDBMシステムで観察される可能性がはるかに高い第1、第2、および第3の正規形について説明します。 4番目、5番目、Boyce-Coddの正規形など、理論には他にも拡張機能がありますが、この記事では、3つの正規形に限定します。
最初の正規形
第一正規形は、次の4つのルールで定義されています。
これは基本的に、列の内容を分割できなくなるまで分割する必要があることを意味します。 役割に注意してください スタッフの列 テーブルは、StaffID=3の行のルール2に違反しています。
正規化されたテーブルの一意性は、通常、主キーを使用して実現されます。主キーは、テーブルの各行を一意に定義します。ほとんどの場合、主キーは1つの列のみで定義されます。複数の列で構成される主キーは、複合キーと呼ばれます。
スタッフのデータを揃えるには 第一正規形の教義を持つ表は、図2、3、および4に示すように表を分割する必要があります。
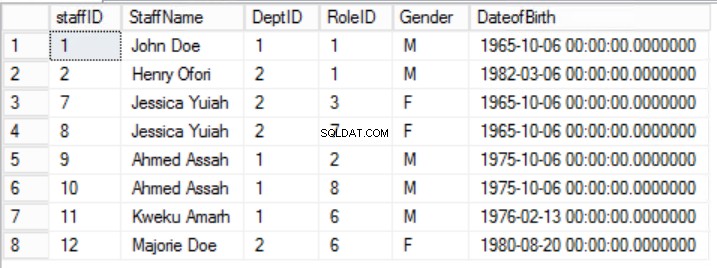
図。 2人のスタッフテーブル
スタッフのデータを絞り込みました テーブルを作成し、一意性を保証するために複合主キーを実装しました。また、2つの追加のテーブルロールを作成しました および部門 コアスタッフと関係があります 外部キーを使用して実装されたテーブル。リスト2のDDLを確認してください。
リスト2.新しいスタッフのDDL 第一正規形の表。
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
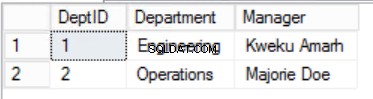
図。 3部門の表
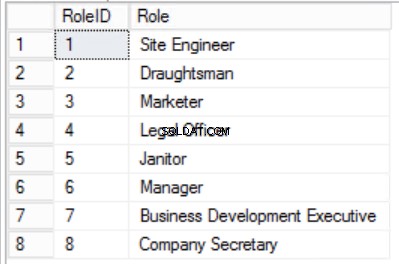
図。 4つの役割の表
第2正規形
-
-
すべての非キー列は、主キーに部分的に依存していてはなりません。
2番目のルールの目的は、テーブルのすべての列が、主キーを一緒に構成するすべての列に依存している必要があるということです。図2、3、および4の表を振り返ると、第一正規形のすべての要件を満たしていることがわかります。また、2つのテーブルの第2正規形の要件を達成しましたロール および部門 。ただし、スタッフの場合 テーブル、まだ問題があります。主キーは、StaffID列とRoleID列で構成されています。
ここでは、スタッフの性別と生年月日がRoleIDに依存しないため、第2正規形の規則2が破られています。部分的な依存関係があります。
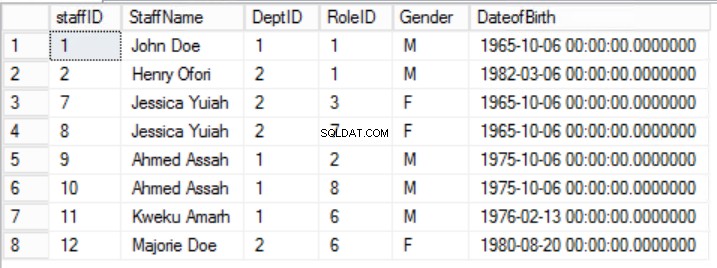
図。第一正規形の5人のスタッフ
この例では、主キーからRoleIDを削除することでこれを修正できますが、これを行うと、別のルール、つまり第一正規形に記載されている一意性の役割に違反することになります。別のアプローチを取る必要があります。 スタッフを変更します スタッフが複数の役割を果たすことができることを理解したテーブル。図6を参照してください。
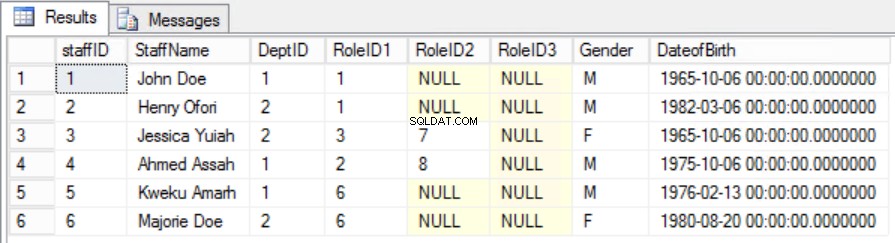
図。 2番目の正規形の6人のスタッフテーブル
一意性を維持し、部分的な依存関係を削除することに成功しました。
リスト3.2番目の正規形の新しいスタッフテーブルのDDL。
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
第3正規形
-
2番目の正規形はすでに配置されている必要があります。
-
すべての非キー列は、主キーへの推移的な依存関係を持ってはなりません。
第3正規形の目的は、非キー列がすでに主キーに依存している場合でも、非キー列に依存する列があってはならないということです。
例として、スタッフに列を追加することにしたと仮定します。 スタッフのマネージャーをはっきりと見るために、図7に示すような表。そうすることで、マネージャー名はDeptIDに依存し、DeptIDはStaffIDに依存するため、2番目の第3正規形ルールに違反することになります。これは推移的な依存関係です。
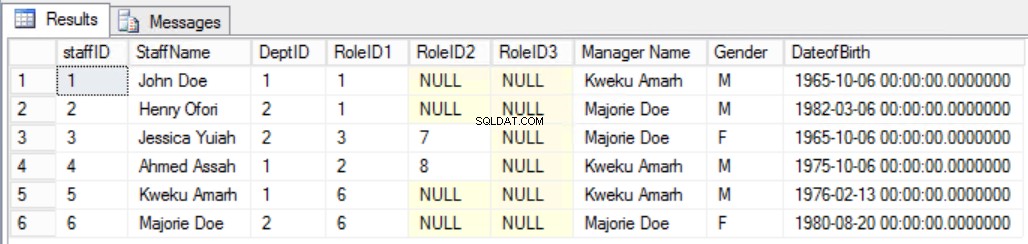
図。第3正規形(破られた規則)の7人のスタッフテーブル
古いフォームを保持し、StaffersテーブルとDepartmentテーブルの間の結合を使用して必要な情報を表示することをお勧めします。
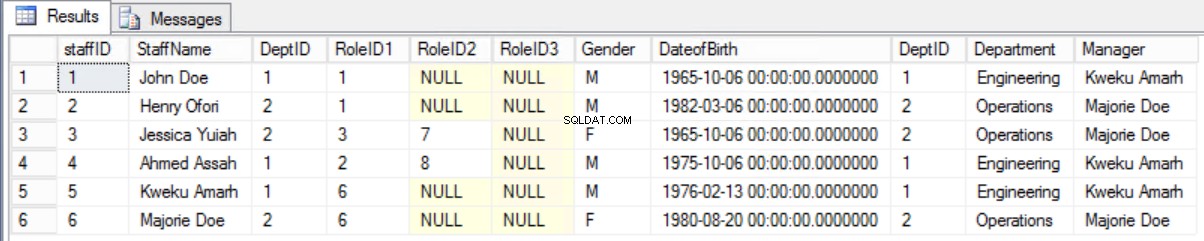
図。 8スタッフと部門の間で参加する
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
実用的なアプリケーション
ほとんどの成熟したアプリケーションは、妥当な範囲で正規化のルールを実装しています。データの正規化の実装により、主キー制約と外部キー制約が使用されることがわかります。さらに、主題を深く掘り下げると、外部キーのインデックス付けなどの問題も発生します。先に、挿入、削除、および更新の異常で説明されているように、正規化の欠如がデータのスムーズな操作にどのように影響するかについて説明しました。適切な正規化が行われていないと、クエリのパフォーマンスに間接的に影響を与える可能性もあります。
最近、表1に示す形式のテーブルに出くわしました。これをCustomer_Accountsと呼びます。
| S/いいえ | | Account_No | Phone_No |
| 1 | ケネス・イギリ | 9922344592 | 2348039988456、2348039988456、2348039988456 |
| 2 | Ernest Doe | 6677554897 | 2348022887546、2348039988456 |
表1Customer_Accounts
このテーブルの主な問題は、第一正規形の2番目のルールに違反していることです。この場合の結果は、電話番号に基づいて顧客を検索するには、WHERE句でLIKEを使用し、先頭に%を使用する必要があるということでした。
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
上記の構成の影響は、オプティマイザーがインデックスを使用したことがないということでした。これは、パフォーマンスの大きな問題でした。
データの正規化はデータベース設計の領域にあり、開発者とDBAの両方がこの記事で概説されているルールに注意を払う必要があります。データベースが本番環境に移行する前に、正規化を実行することをお勧めします。適切に設計されたリレーショナルデータベース管理システムの利点は、努力するだけの価値があります。