「しかし、開発サーバーでは問題なく動作しました!」
SQLクエリのパフォーマンスの問題があちこちで発生したときに何回聞きましたか?私はその日に自分でそれを言いました。 1秒未満で実行されるクエリは、運用サーバーでは正常に実行されると思いました。しかし、私は間違っていました。
この経験に関係がありますか?なんらかの理由で今日もこのボートに乗っているなら、この投稿はあなたのためです。これにより、SQLクエリのパフォーマンスを微調整するためのより優れたメトリックが得られます。 STATISTICSIOで最も重要な3つの数字について説明します。
例として、AdventureWorksサンプルデータベースを使用します。
以下のクエリの実行を開始する前に、STATISTICSIOをオンにしてください。クエリウィンドウでこれを行う方法は次のとおりです。
USE AdventureWorks
GO
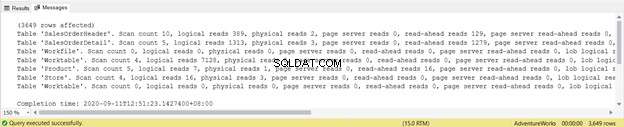
SET STATISTICS IO ONSTATISTICS IO ONでクエリを実行すると、さまざまなメッセージが表示されます。これらは、SQL Server Management Studioのクエリウィンドウの[メッセージ]タブで確認できます(図1を参照)。
短いイントロが終わったので、さらに深く掘り下げましょう。
1。高い論理読み取り
私たちのリストの最初のポイントは、最も一般的な原因である高い論理読み取りです。
論理読み取りは、データキャッシュから読み取られたページ数です。 1ページのサイズは8KBです。一方、データキャッシュは、SQLServerで使用されるRAMを指します。
論理読み取りは、パフォーマンスの調整に不可欠です。この係数は、SQLServerが必要な結果セットを生成するために必要な量を定義します。したがって、覚えておくべき唯一のことは、論理読み取りが高いほど、SQLServerが動作する必要がある時間が長くなることです。これは、クエリが遅くなることを意味します。論理読み取りの数を減らすと、クエリのパフォーマンスが向上します。
しかし、なぜ経過時間の代わりに論理読み取りを使用するのですか?
- 経過時間は、クエリだけでなく、サーバーによって実行される他の処理によって異なります。
- 経過時間は、開発サーバーから本番サーバーに変わる可能性があります。これは、両方のサーバーの容量とハードウェアおよびソフトウェアの構成が異なる場合に発生します。
経過時間に依存すると、「しかし、開発サーバーでは正常に動作しました!」と言うことになります。遅かれ早かれ。
物理読み取りの代わりに論理読み取りを使用するのはなぜですか?
- 物理読み取りは、ディスクからデータキャッシュ(メモリ内)に読み取られたページ数です。クエリに必要なページがデータキャッシュに入ると、ディスクからそれらを再読み込みする必要はありません。
- 同じクエリが再実行されると、物理的な読み取りはゼロになります。
論理読み取りは、SQLクエリのパフォーマンスを微調整するための論理的な選択です。
これが実際に動作することを確認するために、例に進みましょう。
論理読み取りの例
2011年7月11日に出荷された注文の顧客のリストを取得する必要があるとします。以下の非常に単純なクエリを考え出します。
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'簡単です。このクエリの出力は次のとおりです。

次に、このクエリのSTATISTICSIOの結果を確認します。

出力には、クエリで使用された4つのテーブルのそれぞれの論理読み取りが表示されます。合計で、論理読み取りの合計は729です。合計21の物理読み取りも表示されます。ただし、クエリを再実行すると、ゼロになります。
SalesOrderHeaderの論理読み取りを詳しく見てみましょう。 。なぜ689の論理読み取りがあるのか疑問に思いますか?おそらく、以下のクエリの実行プランを調べることを考えました:
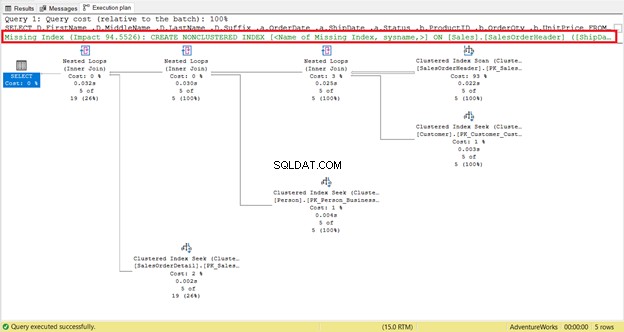
1つには、 SalesOrderHeaderで発生したインデックススキャンがあります。 93%のコストで。何が起こっているのでしょうか?そのプロパティを確認したと仮定します:
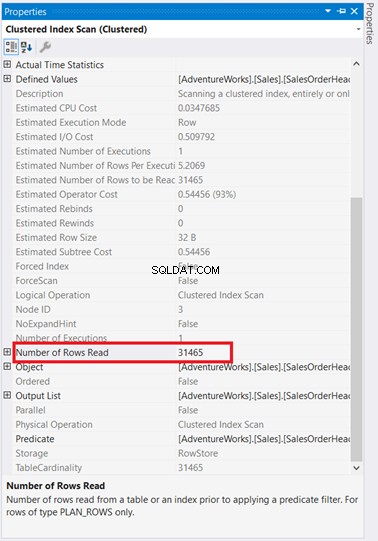
うわあ!返された5行のみに対して31,465行が読み取られましたか?ばかげている!
論理読み取りの数を減らす
読み取られた31,465行を減らすのはそれほど難しくありません。 SQLServerはすでに手がかりを与えてくれました。次の手順に進みます。
ステップ1:SQL Serverの推奨事項に従い、欠落しているインデックスを追加する
実行プラン(図4)にインデックスの推奨事項がないことに気づきましたか?それで問題は解決しますか?
調べる方法は1つあります:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])クエリを再実行して、STATISTICSIO論理読み取りの変更を確認します。

STATISTICS IO(図6)でわかるように、論理読み取りが689から17に大幅に減少しています。新しい全体的な論理読み取りは57であり、729の論理読み取りから大幅に改善されています。ただし、確かに、実行計画をもう一度調べてみましょう。
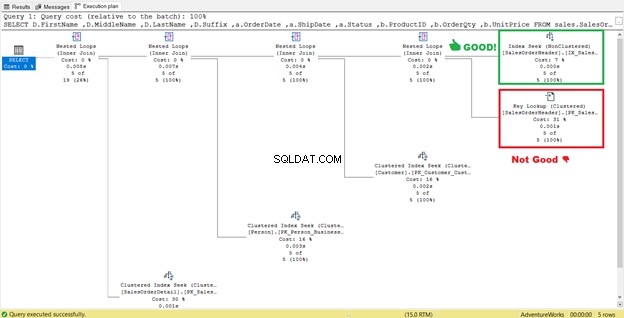
計画が改善され、論理読み取りが減少したようです。インデックススキャンがインデックスシークになりました。 SQL Serverは、 Shipdate =’07 / 11/2011’ のレコードを取得するために、行ごとに検査する必要がなくなります。 。しかし、その計画にはまだ何かが潜んでおり、それは正しくありません。
ステップ2が必要です。
ステップ2:インデックスを変更し、含まれる列に追加する:OrderDate、Status、CustomerID
実行プラン(図7)にそのキールックアップ演算子が表示されていますか?これは、作成された非クラスター化インデックスでは不十分であることを意味します。クエリプロセッサはクラスター化インデックスを再度使用する必要があります。
プロパティを確認しましょう。
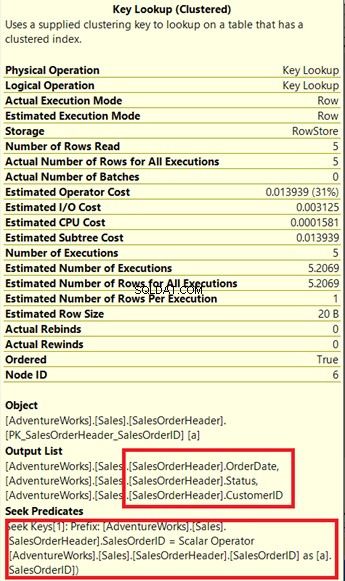
出力リストの下にある同封のボックスに注意してください 。 OrderDateが必要になることがあります 、ステータス 、および CustomerID 結果セットで。これらの値を取得するために、クエリプロセッサはクラスター化インデックスを使用しました(述語の検索を参照)。 )テーブルにたどり着きます。
そのキールックアップを削除する必要があります。解決策は、 OrderDateを含めることです。 、ステータス 、および CustomerID 以前に作成したインデックスへの列。
- IX_SalesOrderHeader_ShipDateを右クリックします SSMSで。
- プロパティを選択します 。
- 含まれる列をクリックします タブ。
- OrderDateを追加します 、ステータス 、および CustomerID 。
- [ OK]をクリックします 。
インデックスを再作成した後、クエリを再実行します。これにより、キールックアップが削除されますか? 論理的な読み取りを減らしますか?

機能した! 17の論理読み取りから2まで(図9)。
そしてキールックアップ ?
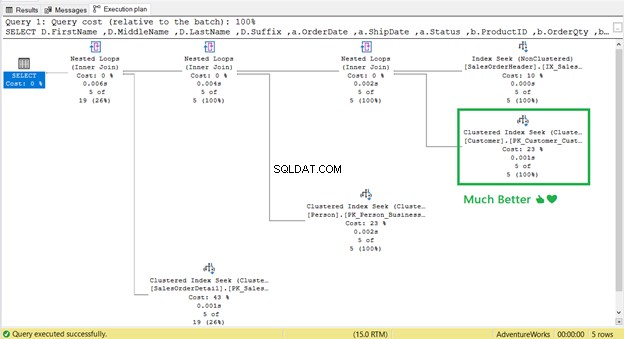
なくなった! クラスター化されたインデックスシーク キールックアップに取って代わりました。
お持ち帰り
それで、私たちは何を学びましたか?
論理読み取りを減らし、SQLクエリのパフォーマンスを向上させる主な方法の1つは、適切なインデックスを作成することです。しかし、落とし穴があります。この例では、論理読み取りが減少しました。時々、反対が正しいでしょう。他の関連クエリのパフォーマンスにも影響を与える可能性があります。
したがって、インデックスを作成した後は、必ずSTATISTICSIOと実行プランを確認してください。
2。ハイロブ論理読み取り
ポイント1とほとんど同じですが、データ型テキストを処理します。 、 ntext 、画像 、 varchar (最大 )、 nvarchar (最大 )、 varbinary (最大 )、または列ストア インデックスページ。
例を参照してみましょう:lob論理読み取りの生成。
ロブ論理読み取りの例
価格、色、サムネイル画像、およびより大きな画像を含む製品をWebページに表示するとします。したがって、次のような初期クエリが考えられます。
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.Color次に、それを実行すると、次のような出力が表示されます。

あなたはそのような高性能志向の男(またはギャル)なので、すぐにSTATISTICSIOをチェックします。ここにあります:

目の汚れのように感じます。 665 lob論理読み取り?これを受け入れることはできません。言うまでもなく、 ProductPhotoからそれぞれ194個の論理読み取りが行われます。 およびProductProductPhoto テーブル。確かに、このクエリにはいくつかの変更が必要だと思います。
ロブ論理読み取りの削減
前のクエリでは97行が返されました。 97台すべてのバイク。これはWebページに表示するのに適していると思いますか?
インデックスが役立つかもしれませんが、最初にクエリを単純化してみませんか?このようにして、SQLServerが返すものを選択できます。 lob論理読み取りを減らすことができます。
- 製品サブカテゴリのフィルターを追加し、顧客に選択させます。次に、これをWHERE句に含めます。
- ProductSubcategoryを削除します 製品サブカテゴリのフィルタを追加するため、列。
- LargePhotoを削除します 桁。ユーザーが特定の製品を選択したときにこれを照会します。
- ページングを使用します。お客様は97台すべての自転車を一度に表示することはできません。
上記のこれらの操作に基づいて、クエリを次のように変更します。
- ProductSubcategoryを削除します およびLargePhoto 結果セットの列。
- OFFSETとFETCHを使用して、クエリのページングに対応します。一度に10個の製品のみをクエリします。
- ProductSubcategoryIDを追加します 顧客の選択に基づいてWHERE句で。
- ProductSubcategoryを削除します ORDERBY句の列。
クエリは次のようになります:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.変更が行われると、lob論理読み取りは改善されますか? STATISTICS IOは次のように報告します:

ProductPhoto テーブルに0lob論理読み取りが含まれるようになりました–665lob論理読み取りからnoneまで。それはいくつかの改善です。
持ち帰り
lob論理読み取りを減らす方法の1つは、クエリを書き直して単純化することです。
不要な列を削除し、返される行を必要最小限に減らします。必要に応じて、ページングにOFFSETとFETCHを使用します。
クエリの変更によってLOB論理読み取りとSQLクエリのパフォーマンスが向上したことを確認するには、常にSTATISTICSIOを確認してください。
3。高いワークテーブル/ワークファイルの論理読み取り
最後に、 Worktableの論理的な読み取りです およびワークファイル 。しかし、これらのテーブルは何ですか?クエリで使用しないのになぜ表示されるのですか?
作業台を持っている およびワークファイル STATISTICS IOに表示されるということは、SQLServerが目的の結果を得るにはさらに多くの作業が必要であることを意味します。 tempdbで一時テーブルを使用することになります 、つまりワークテーブル およびワークファイル 。論理読み取りがゼロであり、サーバーに問題を引き起こさない限り、STATISTICSIO出力にそれらを含めることは必ずしも有害ではありません。
これらのテーブルは、ORDER BY、GROUP BY、CROSS JOIN、DISTINCTなどがある場合に表示されることがあります。
ワークテーブル/ワークファイルの論理読み取りの例
特定の商品を販売せずにすべての店舗に問い合わせる必要があると想定します。
最初に思いついたのは次のとおりです。
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDこのクエリは3649行を返しました:
STATISTICSIOが何を伝えているかを確認しましょう:

作業台は注目に値します 論理読み取りは7128です。全体的な論理読み取りは8853です。実行プランを確認すると、多くの並列処理、ハッシュ一致、スプール、およびインデックススキャンが表示されます。
ワークテーブル/ワークファイルの論理読み取りの削減
満足のいく結果が得られる単一のSELECTステートメントを作成できませんでした。したがって、唯一の選択肢は、SELECTステートメントを複数のクエリに分割することです。以下を参照してください:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProducts数行長く、一時テーブルを使用します。それでは、STATISTICSIOが明らかにすることを見てみましょう。
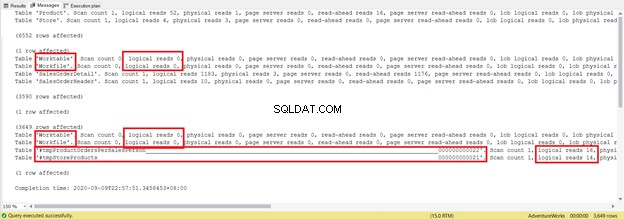
この統計レポートの長さに焦点を当てないようにしてください-それはイライラするだけです。代わりに、各テーブルから論理読み取りを追加してください。
合計1279で、単一のSELECTステートメントからの8853の論理読み取りであったため、大幅に減少しました。
一時テーブルにインデックスを追加していません。 SalesOrderHeader にさらに多くのレコードが追加される場合は、1つ必要になることがあります。 およびSalesOrderDetail 。しかし、あなたは要点を理解します。
持ち帰り
1つのSELECTステートメントが適切に見える場合があります。ただし、舞台裏では、その逆が当てはまります。 ワークテーブル およびワークファイル 論理読み取りが多いと、SQLクエリのパフォーマンスが低下します。
クエリを再構築する別の方法が考えられず、インデックスが役に立たない場合は、「分割統治」アプローチを試してください。 ワークテーブル およびワークファイル SSMSの[メッセージ]タブに引き続き表示される場合がありますが、論理読み取りはゼロになります。したがって、全体的な結果は論理的な読み取りが少なくなります。
SQLクエリのパフォーマンスと統計IOの要点
これらの3つの厄介なI/O統計の大きな問題は何ですか?
これらの数値に注意を払い、数値を下げると、SQLクエリのパフォーマンスの違いは昼と夜のようになります。次のような論理読み取りを減らすためのいくつかの方法のみを示しました。
- 適切なインデックスを作成する;
- クエリの簡素化–不要な列を削除し、結果セットを最小化します。
- クエリを複数のクエリに分割します。
統計の更新、インデックスの最適化、適切なFILLFACTORの設定などがあります。コメントセクションでこれにさらに追加できますか?
この投稿が気に入ったら、お気に入りのソーシャルメディアと共有してください。