XQueryを使用してXMLからデータを解析することは、日常的な方法です。これを最も効果的に行うために、ほとんど労力は必要ありません。
次の構造のディスクファイルからデータを解析する必要があるとします。
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
ファイルからデータを読み取る必要がある場合は、BULK INSERTを使用します:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
サンプルのxmlファイルはこちらです。
ただし、1つの特定の点に注意してください…データを直接読み取らないようにしてください:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) 変数にデータを割り当てます。このようにして、より効率的な実行プランを取得できます:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) 結果を比較します:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
ご覧のとおり、2番目のオプションは大幅に高速です。
XQueryを使用する場合のSQLServerのもう1つの重要な機能は、親要素を読み取るとパフォーマンスが低下する可能性があることです。次の例を考えてみましょう:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) オペレーターから受け取った実際の行数を見てみましょう。値が異常に大きい:
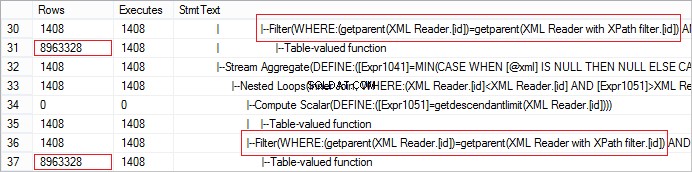
リクエストは、CROSS APPLYを使用して簡単に最適化できます:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) 実行時間を比較してみましょう:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
例からわかるように、CROSSAPPLYを使用したリクエストはすぐに機能します。
ご清聴ありがとうございました。この記事がお役に立てば幸いです。ご不明な点がございましたら、この記事に関するコメントや提案をお寄せください。