インナージョイン、アウタージョイン、クロスジョイン?何が得られますか?
有効な質問です。 T-SQLコードが埋め込まれたVisualBasicコードを見たことがあります。 VBコードは、複数のSELECTステートメント(テーブルごとに1つのSELECT *)を持つテーブルレコードを取得します。次に、複数の結果セットを1つのレコードセットに結合します。ばかげている?
それをした若い開発者にとって、そうではありませんでした。しかし、なぜシステムが遅いのかを評価するように頼まれたとき、その問題が最初に私の注意を引きました。それは正しい。彼らはSQL結合について聞いたことがありません。彼らに公平を期すために、彼らは正直で、提案を受け入れました。
SQL結合をどのように説明しますか?おそらく、あなたは1つの歌を覚えています– Imagine ジョン・レノン著:
私は夢想家だと言うかもしれませんが、私だけではありません。
いつかあなたが私たちに加わってくれることを願っています。そうすれば世界は一つになります。
曲の文脈では、参加は団結です。 SQLデータベースでは、2つ以上のテーブルのレコードを1つの結果セットに結合すると結合が形成されます 。
この記事は、SQL結合について説明する3部構成のシリーズの始まりです。
- 内部参加
- OUTER JOIN(LEFT、RIGHT、およびFULLを含む)
- クロスジョイン
ただし、INNER JOINについて説明する前に、結合全般について説明しましょう。

SQLJOINの詳細
結合はFROM句の直後に表示されます。最も単純な形式では、SQL-92標準を使用しているように見えます。
FROM <table source> [<alias1>]
<join type> JOIN <table source> [<alias2>] [ON <join condition>]
[<join type> JOIN <table source> [<alias3>] [ON <join condition>]
<join type> JOIN <table source> [<aliasN>] [ON <join condition>]]
[WHERE <condition>]JOINを取り巻く日常的なことを説明しましょう。
テーブルソース
Microsoftによれば、最大256のテーブルソースを追加できます。もちろん、それはあなたのサーバーリソースに依存します。 256は言うまでもなく、人生で10を超えるテーブルに参加したことはありません。とにかく、テーブルソースは次のいずれかになります。
- 表
- 表示
- テーブルまたはビューの同義語
- テーブル変数
- テーブル値関数
- 派生テーブル
テーブルエイリアス
エイリアスはオプションですが、コードが短縮され、入力が最小限に抑えられます。また、SELECT、UPDATE、INSERT、またはDELETEで使用される2つ以上のテーブルに列名が存在する場合のエラーを回避するのにも役立ちます。また、コードが明確になります。オプションですが、エイリアスを使用することをお勧めします。 (テーブルソースを名前で入力するのが好きでない限り。)
参加条件
ONキーワードは、結合された2つのテーブルの単一の結合または2つのキー列である結合条件の前にあります。または、3つ以上のキー列を使用する複合結合にすることもできます。テーブルがどのように関連しているかを定義します。
ただし、結合条件は、内部結合と外部結合にのみ使用されます。 CROSS JOINで使用すると、エラーが発生します。
結合条件は関係を定義するため、演算子が必要です。
結合条件演算子の最も一般的なものは、等式(=)演算子です。>や<のような他の演算子も機能しますが、まれです。
SQLJOINとサブクエリ
ほとんどの結合はサブクエリとして書き換えることができ、その逆も可能です。参加と比較したサブクエリの詳細については、この記事を確認してください。
結合および派生テーブル
結合で派生テーブルを使用すると、次のようになります。
FROM table1 a
INNER JOIN (SELECT y.column3 from table2 x
INNER JOIN table3 y on x.column1 = y.column1) b ON a.col1 = b.col2別のSELECTステートメントの結果から結合しており、完全に有効です。
さらに多くの例がありますが、SQLJOINSについて最後にもう1つ扱いましょう。これは、SQLServerのクエリオプティマイザプロセスが参加する方法です。
SQLServerが結合を処理する方法
プロセスがどのように機能するかを理解するには、関連する2つのタイプの操作について知る必要があります。
- 論理演算 クエリで使用される結合タイプ(INNER、OUTER、またはCROSS)に対応します。開発者は、クエリを作成するときに処理のこの部分を定義します。
- 物理的な操作 –クエリオプティマイザは、結合に適用できる最適な物理操作を選択します。最良とは、結果を出すのに最も速いことを意味します。クエリの実行プランには、選択した物理結合演算子が表示されます。これらの操作は次のとおりです。
- ネストされたループ結合。 2つのテーブルの一方が小さく、もう一方が大きくてインデックスが付けられている場合、この操作は高速です。必要なI/Oは最小限で、比較は最小限ですが、大規模な結果セットには適していません。
- マージ参加。 これは、結合で使用される列ごとに大きくソートされた結果セットの最速の操作です。
- ハッシュ結合。 クエリオプティマイザは、結果セットがネストされたループに対して大きすぎ、入力がマージ結合に対してソートされていない場合に使用します。ハッシュは、最初にソートしてマージ結合を適用するよりも効率的です。
- アダプティブジョイン。 SQL Server 2017以降では、ネストされたループまたはハッシュの選択が可能になります。 。結合メソッドは、最初の入力がスキャンされるまで延期されます。この操作は、再コンパイルせずに、より適切な物理結合に動的に切り替わります。

なぜこれを気にする必要があるのですか?
一言:パフォーマンス。
1つは、正しい結果を生成するために結合を使用してクエリを作成する方法を知ることです。もう1つは、できるだけ速く実行することです。ユーザーからの評判を高めたい場合は、これについて特に心配する必要があります。
では、これらの論理操作の実行計画で何に注意する必要がありますか?
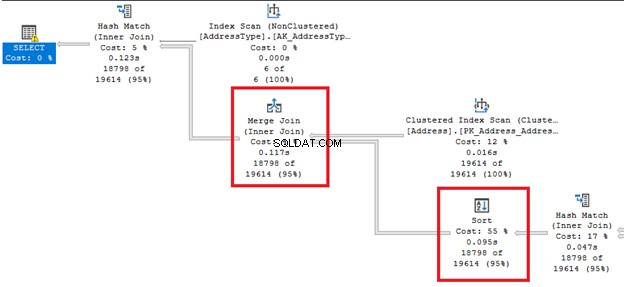
- 並べ替え演算子がマージ結合の前にあるとします 。このソート操作は、大きなテーブルではコストがかかります(図2)。これを修正するには、結合で入力テーブルを事前に並べ替えます。
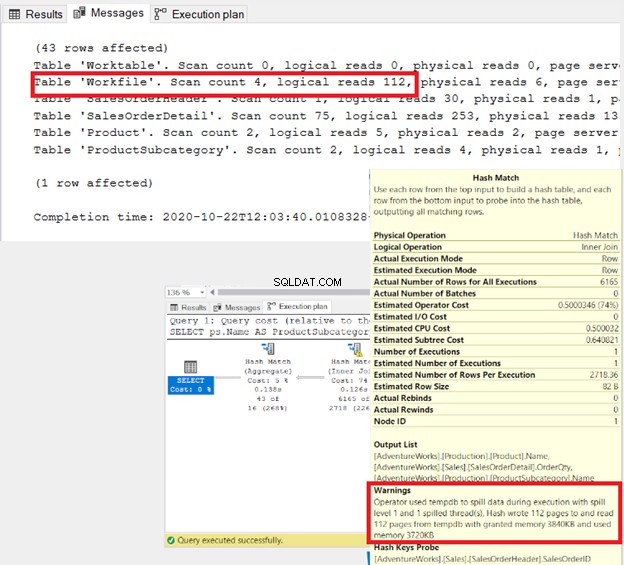
- マージ結合の入力テーブルに重複があるとします 。 SQL Serverは、2番目のテーブルの複製をtempdbのWorkTableに書き込みます。次に、そこで比較を行います。 STATISTICS IOは、関連するすべてのWorkTableを明らかにします。
- ハッシュジョブで大量のデータがtempdbに流出した場合 で、STATISTICS IOは、WorkFilesまたはWorkTablesの大規模な論理読み取りを明らかにします。警告は実行プランにも表示されます(図3)。 2つのことを適用できます。可能であれば、入力テーブルを事前に並べ替えるか、結合を減らします。その結果、クエリオプティマイザは別の物理結合を選択する可能性があります。
ヒントに参加
結合ヒントはSQLServer2019の新機能です。結合で使用すると、クエリオプティマイザーにクエリに最適なものの決定を停止するように指示します。使用する物理的な結合に関しては、あなたが上司です。
やめて、すぐそこに。真実は、クエリオプティマイザは通常、クエリに最適な物理結合を選択するということです。何をしているのかわからない場合は、結合ヒントを使用しないでください。
指定できるヒントは、LOOP、MERGE、HASH、またはREMOTEです。
結合ヒントは使用していませんが、構文は次のとおりです。
<join type> <join hint> JOIN <table source> [<alias>] ON <join condition>内部結合のすべて
INNER JOINは、条件に基づいて、両方のテーブルでレコードが一致する行を返します。キーワードINNERを指定しない場合も、デフォルトの結合になります:
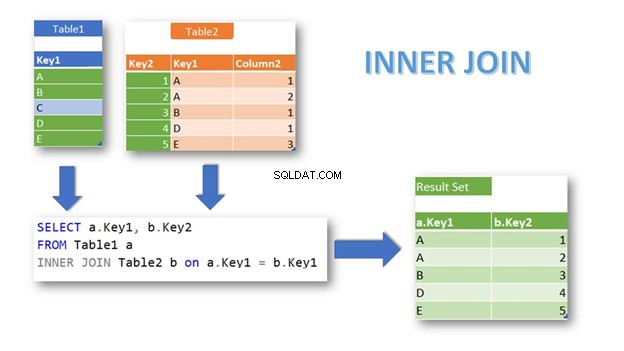
ご覧のとおり、 Table1の一致する行 およびTable2 Key1を使用して返されます 結合条件として。 表1 Key1を持つレコード = Table2 に一致するレコードがないため、「C」は除外されます 。
クエリを作成するときは常に、最初に選択するのはINNERJOINです。 OUTER JOINは、要件によってのみ指示された場合に発生します。
INNERJOIN構文
T-SQLでサポートされているINNERJOIN構文には、SQL-92とSQL-89の2つがあります。
SQL-92内部結合
FROM <table source1> [<alias1>]
INNER JOIN <table source2> [<alias2>] ON <join condition1>
[INNER JOIN <table source3> [<alias3>] ON <join condition2>
INNER JOIN <table sourceN> [<aliasN>] ON <join conditionN>]
[WHERE <condition>]SQL-89内部結合
FROM <table source1> [alias1], <table source2> [alias2] [, <table source3> [alias3], <table sourceN> [aliasN]]
WHERE (<join condition1>)
[AND (<join condition2>)
AND (<join condition3>)
AND (<join conditionN>)]どのINNERJOIN構文が優れていますか?
私が最初に学んだ結合構文はSQL-89でした。 SQL-92がついに登場したとき、長すぎると思いました。また、出力は同じだと思ったのですが、なぜわざわざキーワードを追加するのでしょうか。グラフィカルクエリデザイナは生成されたコードSQL-92を持っていたので、それをSQL-89に戻しました。しかし、今日は、もっと入力する必要がある場合でも、SQL-92を好みます。その理由は次のとおりです。
- 結合のタイプの意図は明確です。私のコードを管理する次の男またはギャルは、クエリで何が意図されているかを知っています。
- SQL-92構文で結合条件を忘れると、エラーが発生します。一方、SQL-89で結合条件を忘れると、CROSSJOINとして扱われます。 INNERまたはOUTERの参加を意味する場合、ユーザーが文句を言うまでは、目立たない論理的なバグになります。
- 新しいツールはSQL-92に傾倒しています。グラフィカルクエリデザイナを再度使用する場合は、SQL-89に変更する必要はありません。頑固ではなくなったので、心拍数は正常に戻りました。乾杯。
上記の理由は私のものです。 SQL-92を好む理由、またはSQL-92を嫌う理由があるかもしれません。それらの理由は何だろうか。下記のコメントセクションでお知らせください。
しかし、例と説明なしにこの記事を終わらせることはできません。
10の内部結合の例
1。 2つのテーブルを結合する
これは、SQL-92構文でINNERJOINを使用して結合された2つのテーブルの例です。
-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON P.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE P.ProductSubcategoryID IN (25, 31, 33); -- for vest, helmet, and light
-- product subcategories必要な列のみを指定します。上記の例では、4つの列が指定されています。 SELECT *よりも長すぎることは承知していますが、これを覚えておいてください。ベストプラクティスです。
テーブルエイリアスの使用にも注意してください。両方の製品 およびProductSubcategory テーブルには[Nameという名前の列があります ]。エイリアスを指定しないと、エラーが発生します。
一方、同等のSQL-89構文は次のとおりです。
-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p, Production.ProductSubcategory ps
WHERE P.ProductSubcategoryID = ps.ProductSubcategoryID
AND P.ProductSubcategoryID IN (25, 31, 33);WHERE句でANDキーワードと混合された結合条件を除いて、これらは同じです。しかし、内部では、それらは本当に同じですか?結果セット、STATISTICS IO、および実行プランを調べてみましょう。
9レコードの結果セットを参照してください:
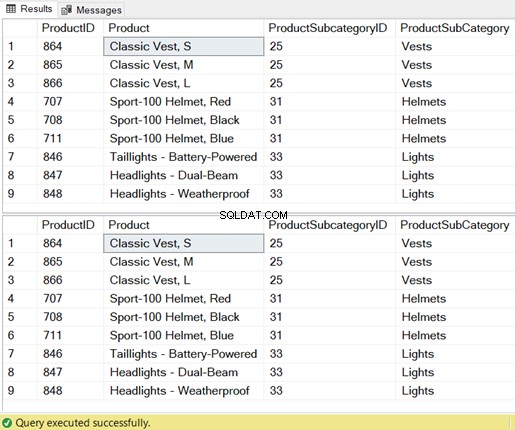
結果だけでなく、SQLServerに必要なリソースも同じです。
論理読み取りを参照してください:
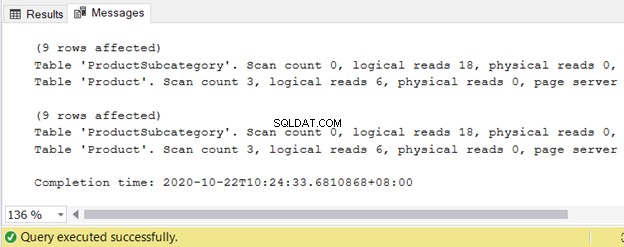
最後に、実行プランは、 QueryPlanHashes の場合、両方のクエリに対して同じクエリプランを明らかにします。 は同じ。図で強調表示されている操作にも注意してください。
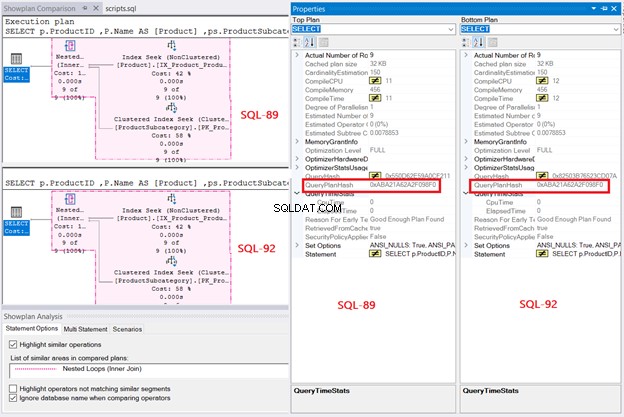
調査結果に基づくと、SQL Serverのクエリ処理は、SQL-92でもSQL-89でも同じです。しかし、私が言ったように、SQL-92の明快さは私にとってはるかに優れています。
図7は、プランで使用されるネストされたループ結合も示しています。なんで?結果セットは小さいです。
2。複数のテーブルを結合する
3つの結合されたテーブルを使用して以下のクエリを確認してください。
-- Get the total number of orders per Product Category
USE AdventureWorks
GO
SELECT
ps.Name AS ProductSubcategory
,SUM(sod.OrderQty) AS TotalOrders
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail sod ON P.ProductID = sod.ProductID
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '1/1/2014' AND '12/31/2014'
AND p.ProductSubcategoryID IN (1,2)
GROUP BY ps.Name
HAVING ps.Name IN ('Mountain Bikes', 'Road Bikes')3。複合結合
2つのキーを使用して2つのテーブルを結合し、それらを関連付けることもできます。以下のサンプルをご覧ください。 AND演算子を使用した2つの結合条件を使用します。
SELECT
a.column1
,b.column1
,b.column2
FROM Table1 a
INNER JOIN Table2 b ON a.column1 = b.column1 AND a.column2 = b.column24。ネストされたループの物理結合を使用した内部結合
以下の例では、製品 テーブルには9つのレコードがあります–小さなセットです。結合されたテーブルはSalesOrderDetail –大規模なセット。図8に示すように、クエリオプティマイザはネストされたループ結合を使用します。
USE AdventureWorks
GO
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);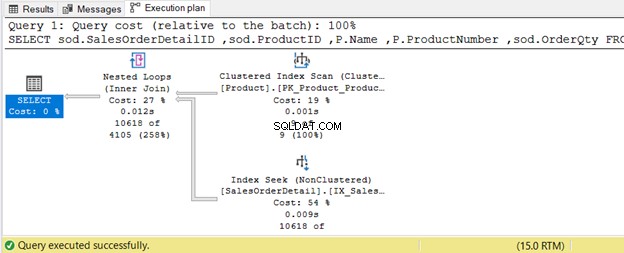
5。マージ物理結合を使用した内部結合
以下の例では、両方の入力テーブルがSalesOrderIDでソートされているため、マージ結合を使用しています。
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID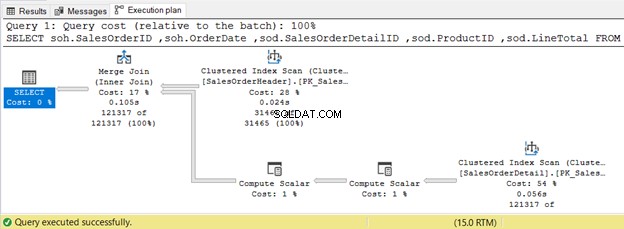
6。ハッシュ物理結合を使用した内部結合
次の例では、ハッシュ結合を使用します:
SELECT
s.Name AS Store
,SUM(soh.TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.Store s ON soh.SalesPersonID = s.SalesPersonID
GROUP BY s.Name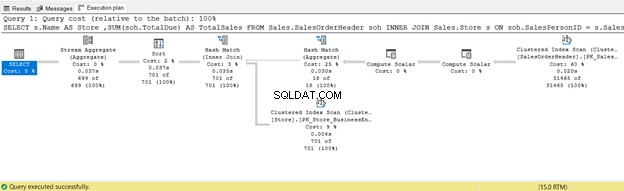
7。アダプティブフィジカルジョインを使用した内部ジョイン
以下の例では、 SalesPerson テーブルには、 TerritoryIDに非クラスター化ColumnStoreインデックスがあります 桁。図11に示すように、クエリオプティマイザはネストされたループ結合を決定しました。
SELECT
sp.BusinessEntityID
,sp.SalesQuota
,st.Name AS Territory
FROM Sales.SalesPerson sp
INNER JOIN Sales.SalesTerritory st ON sp.TerritoryID = st.TerritoryID
WHERE sp.TerritoryID BETWEEN 1 AND 5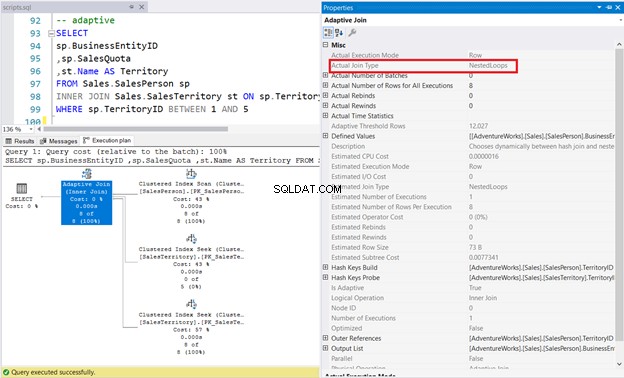
8。サブクエリを内部結合に書き換える2つの方法
ネストされたサブクエリを使用した次のステートメントについて考えてみます。
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT [CustomerID] FROM Sales.Customer
WHERE PersonID IN (SELECT BusinessEntityID FROM Person.Person
WHERE lastname LIKE N'I%' AND PersonType='SC'))以下のように、INNER JOINに変更しても、同じ結果が得られます。
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.lastname LIKE N'I%'それを書き直す別の方法は、派生テーブルをINNERJOINのテーブルソースとして使用することです。
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN (SELECT c.CustomerID, P.PersonType, P.LastName
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = P.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.LastName LIKE N'I%') AS q ON o.CustomerID = q.CustomerID3つのクエリすべてが同じ48レコードを出力します。
9。参加のヒントを使用する
次のクエリはネストされたループを使用しています:
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);強制的にハッシュ結合する場合は、次のようになります。
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER HASH JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);ただし、STATISTICS IOは、強制的にハッシュ結合にするとパフォーマンスが低下することを示していることに注意してください。
一方、以下のクエリはマージ結合を使用しています:
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderIDネストされたループに強制すると、次のようになります。
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER LOOP JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID両方のSTATISTICSIOを確認すると、それをネストされたループに強制すると、クエリを処理するためにより多くのリソースが必要になります。
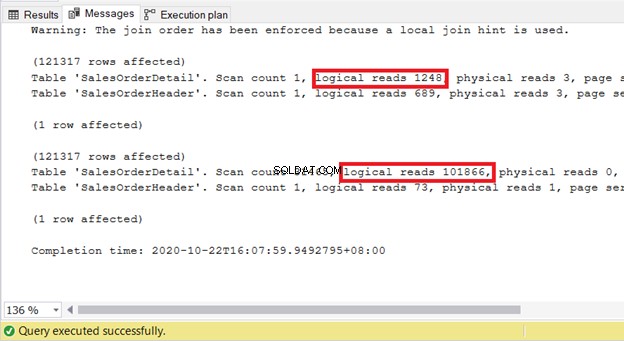
したがって、パフォーマンスを調整するときは、結合ヒントを使用することが最後の手段になるはずです。 SQLServerに処理させてください。
10。 UPDATEでのINNERJOINの使用
UPDATEステートメントでINNERJOINを使用することもできます。次に例を示します:
UPDATE Sales.SalesOrderHeader
SET ShipDate = getdate()
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'UPDATEで結合を使用できるので、DELETEとINSERTを使用して試してみませんか?
SQL結合と内部結合のポイント
では、SQL結合の重要な点は何ですか?
- SQL JOINは、2つ以上のテーブルのレコードを組み合わせて1つの結果セットを形成します。
- SQLには、INNER、OUTER、およびCROSSのタイプの結合があります。
- 開発者または管理者は、要件に使用する論理演算または結合タイプを決定します。
- 一方、クエリオプティマイザは、使用するのに最適な物理結合演算子を決定します。ネストされたループ、マージ、ハッシュ、またはアダプティブにすることができます。
- 結合ヒントを使用して、どの物理結合を使用するかを強制できますが、これが最後の手段になるはずです。ほとんどの場合、SQLServerに処理させることをお勧めします。
- 物理的な結合演算子を知っていると、クエリのパフォーマンスを調整するのにも役立ちます。
- また、サブクエリは結合を使用して書き換えることができます。
一方、この投稿では、内部結合の10の例を示しました。サンプルコードだけではありません。それらのいくつかには、コードがどのように機能するかを徹底的に検査することも含まれています。コーディングを支援するだけでなく、パフォーマンスに注意を払うのにも役立ちます。結局のところ、結果は正しいだけでなく、迅速に配信される必要があります。
まだ終わっていません。次の記事では、外部結合について説明します。しばらくお待ちください。
関連項目
SQL結合を使用すると、複数のテーブルからデータをフェッチして結合できます。 SQL結合の詳細については、このビデオをご覧ください。