SQL Serverのデータ型とそのサイズの選択は重要ですか?
答えはあなたが得た結果にあります。データベースは短時間で膨れ上がりましたか?クエリは遅いですか?間違った結果になりましたか?挿入および更新中のランタイムエラーはどうですか?
自分が何をしているのかを知っていれば、それほど大変な作業ではありません。今日は、これらのデータ型で行うことができる5つの最悪の選択について学習します。それらがあなたの習慣になっている場合、これは私たちがあなた自身とあなたのユーザーのために修正すべきものです。
SQLの多くのデータ型、多くの混乱
SQL Serverのデータ型について最初に知ったとき、選択肢は圧倒的でした。図1のこの単語の雲のように、すべてのタイプが私の頭の中で混同されています。

ただし、カテゴリに分類することはできます:
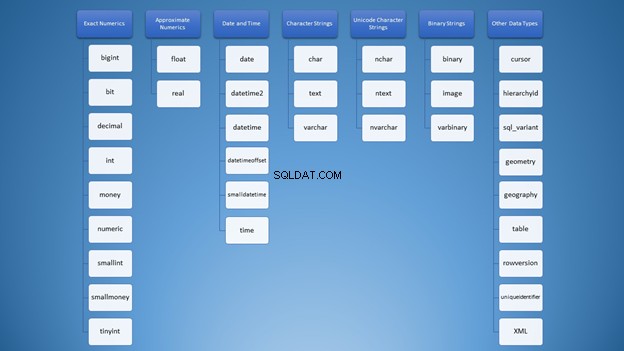
それでも、文字列を使用するために、間違った使用法につながる可能性のある多くのオプションがあります。最初は、 varchar およびnvarchar まったく同じでした。また、どちらも文字列タイプです。数字の使用も同じです。開発者として、さまざまな状況でどのタイプを使用するかを知る必要があります。
しかし、私が間違った選択をした場合に起こりうる最悪の事態は何でしょうか。教えてあげましょう!
1。間違ったSQLデータ型の選択
このアイテムは、ポイントを証明するために文字列と整数を使用します。
間違った文字列SQLデータ型の使用
まず、文字列に戻りましょう。 Unicodeおよび非Unicode文字列と呼ばれるものがあります。どちらもストレージサイズが異なります。これは、列と変数宣言で定義することがよくあります。
構文はvarcharのいずれかです。 (n)/ char (n)または nvarchar (n)/ nchar (n)ここで n サイズです。
nに注意してください 文字数ではなく、バイト数です。これはよくある誤解です。varchar 、文字数はバイト単位のサイズと同じです。ただし、 nvarcharにはありません 。
この事実を証明するために、2つのテーブルを作成し、それらにいくつかのデータを入れましょう。
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
それでは、DATALENGTHを使用して行サイズを確認しましょう。
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
図3は、違いが2つあることを示しています。以下で確認してください。
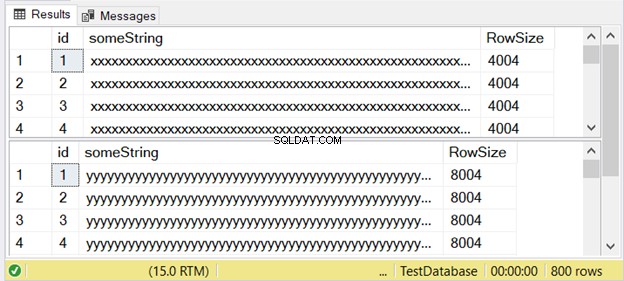
行サイズが8004の2番目の結果セットに注目してください。これはnvarcharを使用します データ・タイプ。また、最初の結果セットの行サイズのほぼ2倍です。そして、これは varcharを使用します データ型。
ストレージとI/Oへの影響がわかります。図4は、2つのクエリの論理読み取りを示しています。
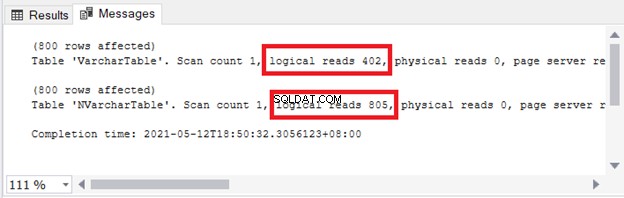
見る? nvarchar を使用する場合、論理読み取りも2つあります。 varcharと比較して 。
したがって、それぞれを同じ意味で使用することはできません。 多言語を保存する必要がある場合 文字、 nvarcharを使用 。それ以外の場合は、 varcharを使用します 。
これは、 nvarcharを使用する場合を意味します シングルバイト文字のみ(英語など)の場合、ストレージサイズが大きくなります 。クエリのパフォーマンスは、論理読み取りが多いほど遅くなります。
SQL Server 2019(およびそれ以降)では、 varchar を使用して、Unicode文字データの全範囲を保存できます。 またはchar UTF-8照合オプションのいずれかを使用します。
間違った数値データ型SQLの使用
同じ概念がbigintにも当てはまります vs. int –それらのサイズは、昼と夜を意味する場合があります。 nvarcharのように およびvarchar 、 bigint intの2倍のサイズです ( bigintの場合は8バイト intの場合は4バイト 。
それでも、別の問題が発生する可能性があります。 サイズを気にしないと、エラーが発生する可能性があります。 intを使用する場合 列を作成し、2,147,483,647を超える数値を格納すると、算術オーバーフローが発生します:
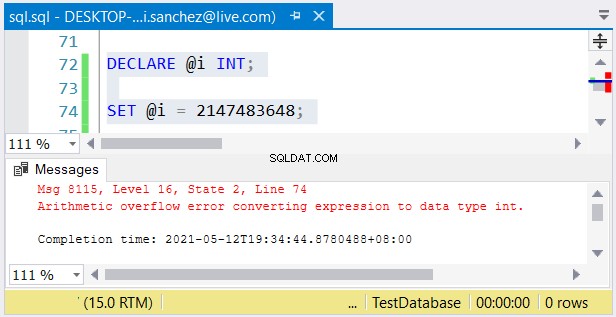
整数タイプを選択するときは、最大値のデータが適合することを確認してください 。たとえば、履歴データを使用してテーブルを設計しているとします。主キー値として整数を使用することを計画しています。 2,147,483,647行に達しないと思いますか?次に、 intを使用します bigintの代わりに 主キーの列タイプとして。
起こりうる最悪の事態
間違ったデータ型を選択すると、クエリのパフォーマンスに影響したり、ランタイムエラーが発生したりする可能性があります。したがって、データに適したデータ型を選択してください。
2。 SQLのビッグデータ型を使用して大きなテーブル行を作成する
次の項目は最初の項目に関連していますが、例を使用してさらにポイントを拡大します。また、それはページと大きなサイズの varchar と関係があります またはnvarchar 列。
ページと行サイズとは何ですか?
SQL Serverのページの概念は、スパイラルノートブックのページと比較できます。ノートブックの各ページの物理的なサイズは同じです。あなたは言葉を書き、それに絵を描きます。一連の段落や写真を表示するのに十分なページがない場合は、次のページに進みます。場合によっては、ページを破って最初からやり直すこともあります。
同様に、SQL Serverのテーブルデータ、インデックスエントリ、および画像はページに保存されます。
ページのサイズは8KBと同じです。データの行が非常に大きい場合、8KBページに収まりません。 1つ以上の列は、ROW_OVERFLOW_DATAアロケーションユニットの下の別のページに書き込まれます。 IN_ROW_DATAアロケーションユニットの下のページの元の行へのポインタが含まれています。
これに基づいて、データベース設計中にテーブルに多くの列を収めることはできません。 I/Oに影響があります。また、これらの行オーバーフローデータに対して多くのクエリを実行すると、実行時間が遅くなります 。これは悪夢になる可能性があります。
さまざまなサイズの列をすべて最大化すると、問題が発生します。次に、データはROW_OVERFLOW_DATAの下の次のページに流出します。小さいサイズのデータで列を更新します。そのページで削除する必要があります。新しい小さいデータ行は、他の列と一緒にIN_ROW_DATAの下のページに書き込まれます。ここに関係するI/Oを想像してみてください。
大きな行の例
まず、データを準備しましょう。大きなサイズの文字列データ型を使用します。
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
行サイズの取得
生成されたデータから、DATALENGTHに基づいて行サイズを調べてみましょう。
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
各行のバイト数は8060バイトまたは8KB未満であるため、最初の300レコードはIN_ROW_DATAページに収まります。しかし、最後の100行は大きすぎます。図6の結果セットを確認してください。
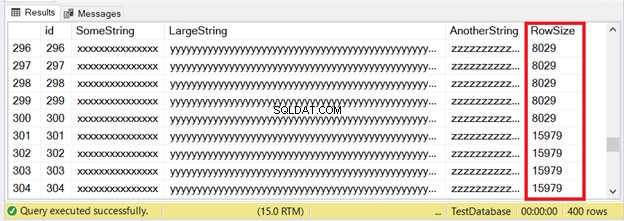
最初の300行の一部が表示されます。次の100は、ページサイズの制限を超えています。最後の100行がROW_OVERFLOW_DATAアロケーションユニットにあることをどのようにして知ることができますか?
ROW_OVERFLOW_DATAの検査
sys.dm_db_index_physical_statsを使用します 。テーブルとインデックスのエントリに関するページ情報を返します。
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
結果セットを図7に示します。

そこにそれがある。図7は、ROW_OVERFLOW_DATAの下の100行を示しています。これは、行301から400で始まる大きな行が存在する場合の図6と一致しています。
次の質問は、これらの100行をクエリしたときに取得する論理読み取りの数です。やってみましょう。
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

LargeTableの102個の論理読み取りと100個のlob論理読み取りが表示されます。 。これらの数値は今のところそのままにしておきます。後で比較します。
それでは、100行をより小さなデータで更新するとどうなるか見てみましょう。
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
この更新ステートメントは、図8と同じ論理読み取りとlob論理読み取りを使用しました。これから、100ページのlob論理読み取りのために何か大きなことが起こったことがわかります。
ただし、確かに、 sys.dm_db_index_physical_statsで確認しましょう。 以前と同じように。図9に結果を示します:

なくなった!小さいデータで100行を更新した後、ROW_OVERFLOW_DATAのページと行がゼロになりました。これで、ROW_OVERFLOW_DATAからIN_ROW_DATAへのデータ移動は、大きな行が縮小されたときに発生することがわかりました。これが数千または数百万のレコードで頻繁に発生する場合を想像してみてください。クレイジーですね。
図8では、100個のlob論理読み取りが見られました。ここで、クエリを再実行した後の図10を参照してください。

ゼロになりました!
起こりうる最悪の事態
クエリのパフォーマンスが遅いのは、行オーバーフローデータの副産物です。大きなサイズの列を別のテーブルに移動して、それを回避することを検討してください。または、該当する場合は、 varcharのサイズを小さくします。 またはnvarchar 列。
3。暗黙の変換を盲目的に使用する
SQLでは、タイプを指定せずにデータを使用することはできません。しかし、私たちが間違った選択をした場合、それは寛容です。値を期待するタイプに変換しようとしますが、ペナルティがあります。これは、WHERE句またはJOINで発生する可能性があります。
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
カード番号 列は数値タイプではありません。 nvarchar 。したがって、最初のSELECTは暗黙的な変換を引き起こします。ただし、どちらも正常に実行され、同じ結果セットが生成されます。
図11の実行プランを確認しましょう。
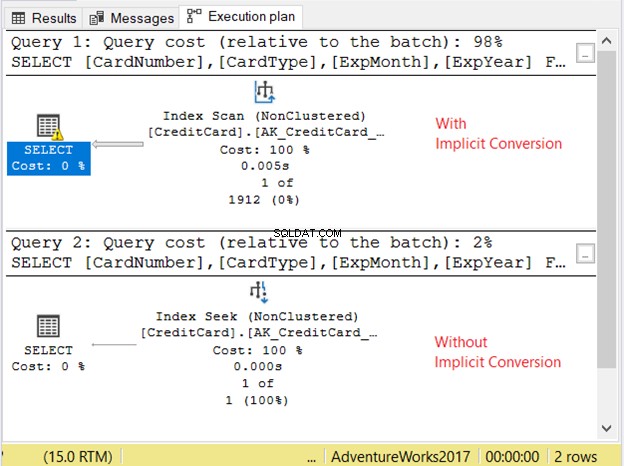
2つのクエリは非常に高速に実行されました。図11では、ゼロ秒です。しかし、2つの計画を見てください。暗黙の変換を使用したものには、インデックススキャンがありました。警告アイコンとSELECT演算子を指す太い矢印もあります。悪いことを教えてくれます。
しかし、それだけではありません。 SELECT演算子の上にマウスを置くと、他の何かが表示されます:

SELECT演算子の警告アイコンは、暗黙の変換に関するものです。しかし、その影響はどのくらいですか?論理読み取りを確認しましょう。
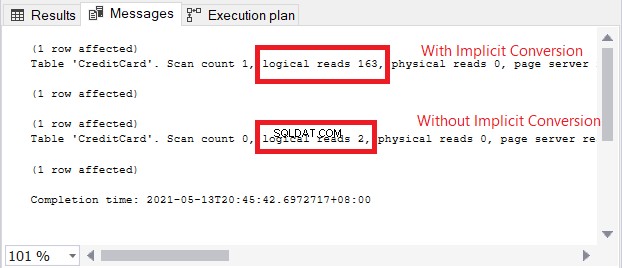
図13の論理読み取りの比較は、天国と地球のようなものです。クレジットカード情報のクエリでは、暗黙の変換により100倍を超える論理読み取りが発生しました。非常に悪いです!
起こりうる最悪の事態
暗黙的な変換によって高い論理読み取りと不適切な計画が発生した場合は、大きな結果セットでクエリのパフォーマンスが低下することが予想されます。これを回避するには、WHERE句で正確なデータ型を使用し、比較する列を照合する際にJOINを使用します。
4。近似数値の使用と丸め
図2をもう一度確認してください。近似数値に属するSQLサーバーのデータ型はfloat および本物 。それらで構成された列と変数は、数値の近似値を格納します。これらの数値を切り上げるまたは切り下げることを計画している場合は、大きな驚きを得る可能性があります。これについて詳しく説明した記事がここにあります。 1 + 1が3になる方法と、四捨五入の数値を処理する方法をご覧ください。
起こりうる最悪の事態
フロートの丸め または本物 クレイジーな結果をもたらす可能性があります。四捨五入後に正確な値が必要な場合は、10進数を使用してください または数値 代わりに。
5。固定サイズの文字列データ型をNULLに設定する
charのような固定サイズのデータ型に注目しましょう。 およびnchar 。埋め込まれたスペースを除いて、それらをNULLに設定すると、 charのサイズと同じストレージサイズが維持されます。 桁。したがって、 charを設定します (500)NULLへの列のサイズは500であり、ゼロまたは1ではありません。
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
上記のコードでは、 charのサイズに基づいてデータが最大化されています。 およびvarchar 列。 DATALENGTHを使用して行サイズを確認すると、各列のサイズの合計も表示されます。次に、列をNULLに設定しましょう。
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
次に、DATALENGTHを使用して行をクエリします:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
各列のデータサイズはどうなると思いますか?図14を確認してください。
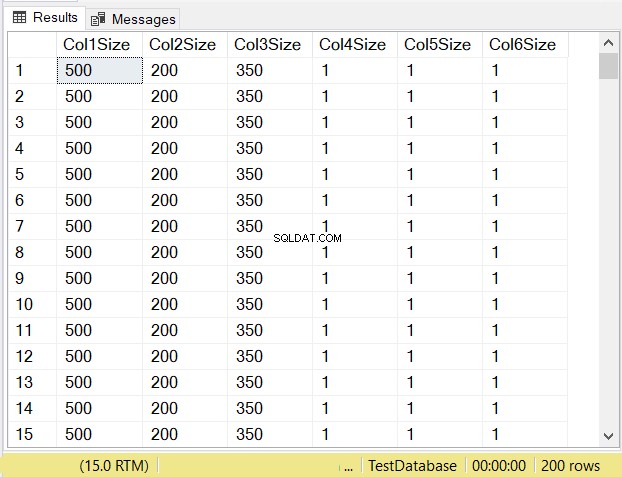
最初の3列の列サイズを確認します。次に、テーブルが作成されたときの上記のコードとそれらを比較します。 NULL列のデータサイズは、列のサイズと同じです。一方、 varchar NULLの列のデータサイズは1です。
起こりうる最悪の事態
テーブルの設計中に、null許容の char NULLに設定されている場合でも、列のストレージサイズは同じです。また、同じページとRAMを消費します。列全体を文字で埋めない場合は、 varcharの使用を検討してください。 代わりに。
次は何ですか?
では、SQLサーバーのデータ型とそのサイズの選択は重要ですか?ここに提示されたポイントは、ポイントを作るのに十分なはずです。それで、あなたは今何ができますか?
- サポートしているデータベースを確認する時間を取ってください。プレートに複数ある場合は、最も簡単なものから始めます。そして、はい、時間を作ってください、時間を見つけないでください。私たちの仕事では、時間を見つけることはほとんど不可能です。
- テーブル、ストアドプロシージャ、およびデータ型を扱うすべてのものを確認します。問題を特定するときは、プラスの影響に注意してください。上司がなぜこれに取り組む必要があるのかと尋ねたときに、それが必要になります。
- 各問題領域を攻撃するように計画します。あなたの会社が問題に対処する際に持っている方法論や方針に従ってください。
- 問題がなくなったら、祝いましょう。
簡単そうに聞こえますが、そうではないことは誰もが知っています。また、旅の終わりには明るい面があることもわかっています。そのため、問題と呼ばれています –解決策があるからです。だから、元気を出してください。
このトピックについて他に何か追加するものはありますか?コメントセクションでお知らせください。そして、この投稿があなたに素晴らしいアイデアを与えたなら、あなたのお気に入りのソーシャルメディアプラットフォームでそれを共有してください。