ぶさいくな。並べ替えられていないデータは次のようになります。データを並べ替えることで、データが見やすくなります。そして、それがSQLORDERBYの目的です。データをソートするための基礎として、1つ以上の列または式を使用します。次に、ASCまたはDESCを追加して、昇順または降順で並べ替えます。
SQL ORDER BY構文:
ORDER BY <order_by_expression> [ASC | DESC]
ORDER BY式は、列または式のリストと同じくらい単純にすることができます。 CASEWHENブロックを使用して条件付きにすることもできます。
非常に柔軟性があります。
OFFSETおよびFETCHを介してページングを使用することもできます。スキップする行数と表示する行数を指定します。
しかし、ここに悪いニュースがあります。
クエリにORDERBYを追加すると、クエリの速度が低下する可能性があります。また、他のいくつかの警告により、ORDERBYが「機能しない」場合があります。ペナルティが発生する可能性があるため、いつでも好きなときに使用することはできません。それで、私たちは何をしますか?
この記事では、ORDERBYを使用する際の推奨事項と禁止事項について説明します。各項目は問題に対処し、解決策が続きます。
準備はいいですか?
SQLORDERBYで行う
1。 SQLORDERBY列にインデックスを付けます
インデックスはすべてクイック検索に関するものです。また、ORDER BY句で使用する列に1つ含めると、クエリを高速化できます。
インデックスのない列でORDERBYの使用を開始しましょう。 AdventureWorksを使用します サンプルデータベース。以下のクエリを実行する前に、 IX_SalesOrderDetail_ProductIDを無効にしてください。 SalesOrderDetailのインデックス テーブル。次に、 Ctrl-Mを押します 実行します。
-- Get order details by product and sort them by ProductID
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT
ProductID
,OrderQty
,UnitPrice
,LineTotal
FROM Sales.SalesOrderDetail
ORDER BY ProductID
SET STATISTICS IO OFF
GO
分析
上記のコードは、SQL ServerManagementStudioの[メッセージ]タブにI/O統計を出力します。別のタブに実行プランが表示されます。
インデックスなし
まず、STATISTICSIOから論理読み取りを取得しましょう。図1を確認してください。
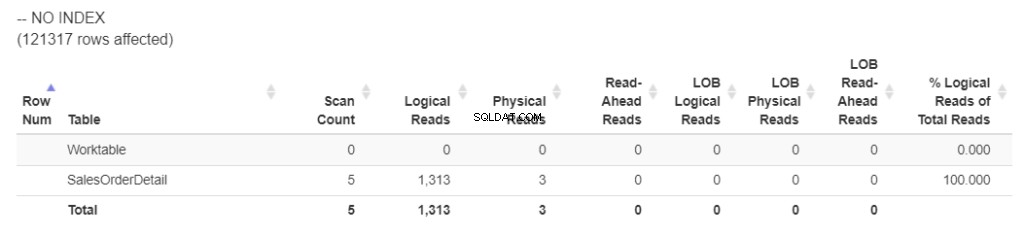
図1 。 インデックス付けされていない列のORDERBYを使用した論理読み取り。 (を使用してフォーマット statisticssparser.com )
インデックスがない場合、クエリは1,313個の論理読み取りを使用しました。そして、その WorkTable ?これは、SQLServerがTempDBを使用したことを意味します 並べ替えを処理します。
しかし、舞台裏で何が起こったのでしょうか?図2の実行プランを調べてみましょう。
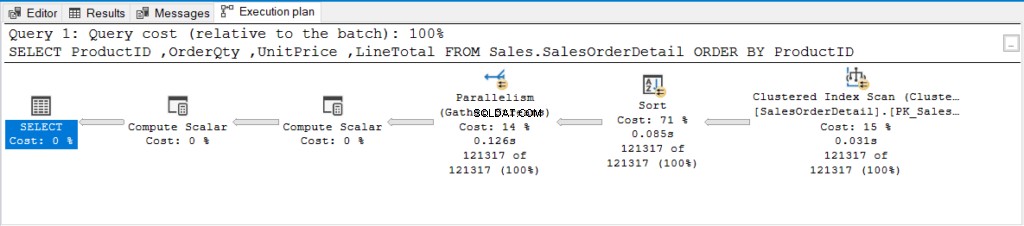
図2 。 インデックス付けされていない列のORDERBYを使用したクエリの実行プラン。
そのParallelism(Gather Streams)演算子を見ましたか?これは、SQLServerがこのクエリを処理するために複数のプロセッサを使用したことを意味します。クエリは、より多くのCPUを必要とするほど重いものでした。
したがって、SQLServerがTempDBを使用した場合はどうなるでしょうか。 およびより多くのプロセッサ?単純なクエリには適していません。
インデックス付き
インデックスが再度有効になった場合、どのように処理されますか?確認してみましょう。インデックスを再構築しますIX_SalesOrderDetail_ProductID 。次に、上記のクエリを再実行します。
図3の新しい論理読み取りを確認してください。
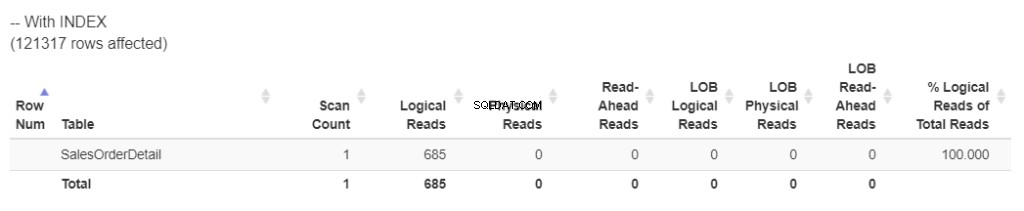
図3 。 インデックスを再構築した後の新しい論理読み取り。
これははるかに優れています。論理読み取りの数をほぼ半分に削減しました。つまり、インデックスによって消費されるリソースが少なくなりました。そしてWorkTable ?なくなった! TempDBを使用する必要はありません 。
そして、実行計画?図4を参照してください。
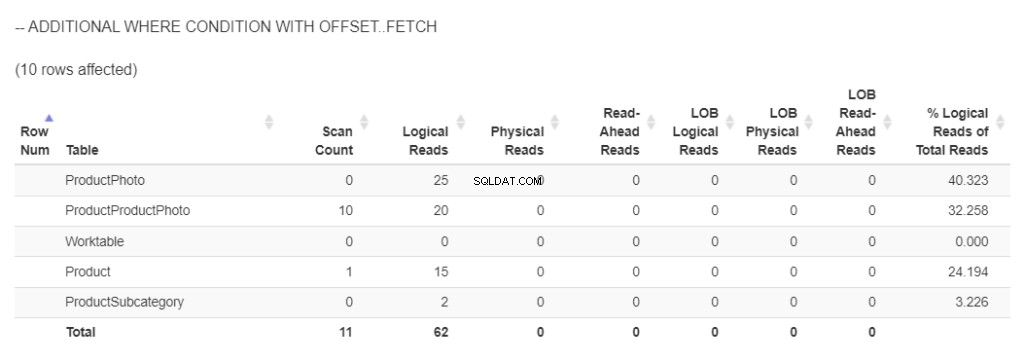
図4 。 インデックスが再構築されたとき、新しい実行プランはより単純になります。
見る?計画はもっと簡単です。同じ121,317行をソートするために追加のCPUは必要ありません。
つまり、要点は次のとおりです。ORDERBYに使用する列にインデックスが付けられていることを確認してください 。
ただし、インデックスを追加すると書き込みパフォーマンスに影響する場合はどうなりますか?
良い質問です。
それが問題である場合は、ソーステーブルの一部を一時テーブルまたはメモリ最適化テーブルにダンプできます。 。次に、そのテーブルにインデックスを付けます。より多くのテーブルが含まれる場合は、同じものを使用します。次に、選択したオプションのクエリパフォーマンスを評価します。より速いオプションが勝者になります。
2。 WHEREおよびOFFSET/FETCHで結果を制限する
別のクエリを使用してみましょう。アプリで商品情報を写真付きで表示する必要があるとします。画像はクエリをさらに重くする可能性があります。したがって、論理読み取りだけでなく、LOB論理読み取りもチェックします。
これがコードです。
SET STATISTICS IO ON
GO
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.Color
SET STATISTICS IO OFF
GO
これにより、97台の自転車が写真付きで出力されます。モバイルデバイスで閲覧するのは非常に困難です。
分析
オフセット/フェッチのない状態で最小限の使用
写真付きの97個の商品を取得するには、論理的な読み取りがどれだけ必要かを次に示します。図5を参照してください。
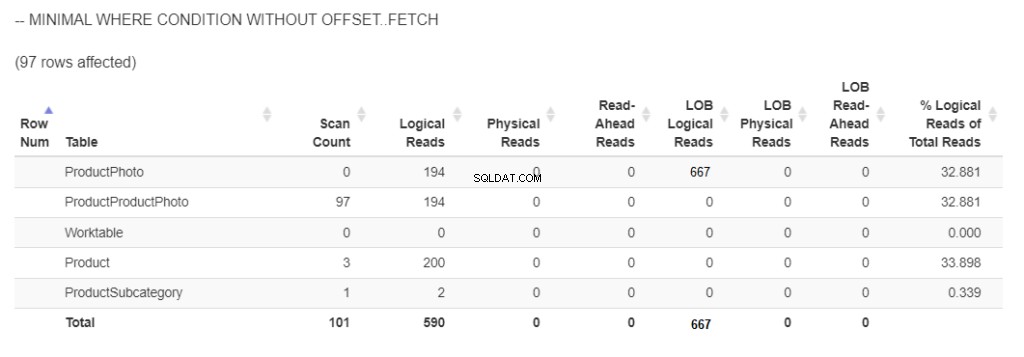
図5 。 OFFSET /FETCHを使用せずにWHERE条件を最小限に抑えてORDERBYを使用する場合の、論理読み取りとLOB論理読み取り 。 (注:statisticsparser.comはlob論理読み取りを表示しませんでした。スクリーンショット SSMSの結果)に基づいて編集されます
2列の画像を取得したため、667個のlob論理読み取りが表示されました。一方、残りの部分には590個の論理読み取りが使用されました。
これが図6の実行計画であり、後でより良い計画と比較できます。
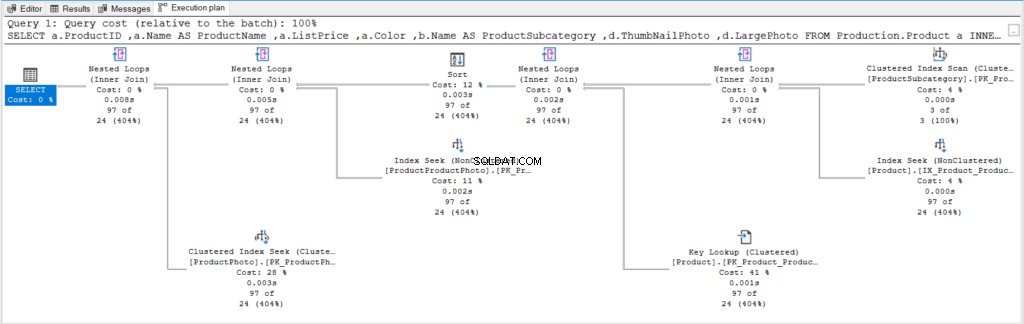
図6 。 OFFSET / FETCHを使用せず、WHERE条件を最小限に抑えたORDERBYを使用した実行プラン。
他の実行計画が表示されるまで、他に言うことはあまりありません。
追加のWHERE条件とオフセット/フェッチを順番に使用
次に、クエリを調整して、最小限のデータが返されるようにします。これから行うことは次のとおりです。
- 製品サブカテゴリに条件を追加します。呼び出し元のアプリでは、ユーザーがサブカテゴリを選択できるようにすることも想像できます。
- 次に、列のSELECTリストと列のORDERBYリストから製品サブカテゴリを削除します。
- 最後に、ORDERBYにOFFSET/FETCHを追加します。 10個の製品のみが返品され、呼び出し元のアプリに表示されます。
これが編集されたコードです。
DECLARE @pageNumber TINYINT = 1
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
このコードをストアドプロシージャにすると、さらに改善されます。また、ページ番号や行数などのパラメータもあります。ページ番号は、ユーザーが現在表示しているページを示します。画面の解像度に応じて行数を柔軟にすることで、これをさらに改善します。しかし、それは別の話です。
それでは、図7の論理読み取りを見てみましょう。
図7 。 クエリを単純化した後の論理読み取りが少なくなります。 OFFSET/FETCHはORDERBYでも使用されます。
次に、図7と図5を比較します。LOB論理読み取りはなくなりました。さらに、結果セットも97から10に減少したため、論理読み取りは著しく減少しました。
しかし、SQL Serverは舞台裏で何をしましたか?図8の実行計画を確認してください。
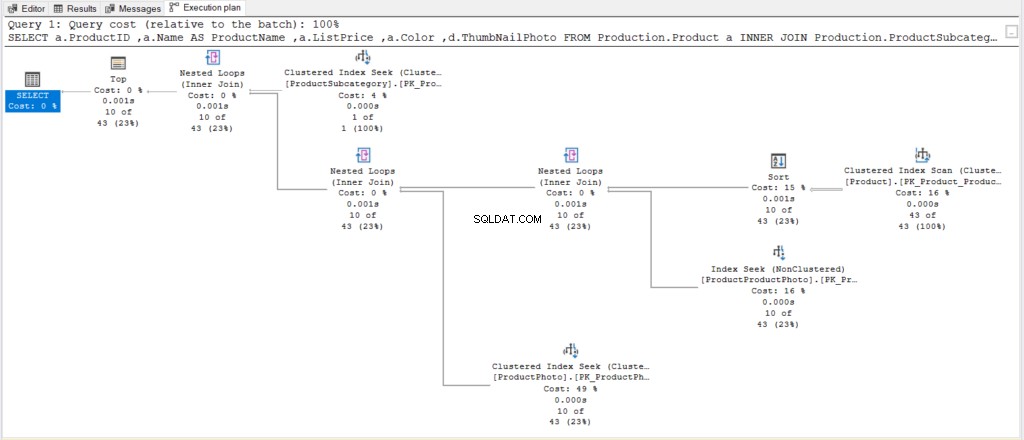
図8 。 クエリを単純化し、ORDERBYにOFFSET/ FETCHを追加した後の、より単純な実行プラン。
次に、図8と図6を比較します。各オペレーターを調べなくても、この新しい計画は前の計画よりも単純であることがわかります。
レッスン? クエリを簡素化します。可能な限りOFFSET/FETCHを使用してください。
SQLORDERBYの禁止事項
ORDERBYを使用するときに必要な作業はこれで完了です。今回は避けるべきことに焦点を当てましょう。
3。クラスタ化インデックスキーで並べ替える場合は、ORDERBYを使用しないでください
役に立たないからです。
例を挙げて見てみましょう。
SET STATISTICS IO ON
GO
-- Using ORDER BY with BusinessEntityID - the primary key
SELECT TOP 100 * FROM Person.Person
ORDER BY BusinessEntityID;
-- Without using ORDER BY at all
SELECT TOP 100 * FROM Person.Person;
SET STATISTICS IO OFF
GO
次に、図9の両方のSELECTステートメントの論理読み取りを確認しましょう。
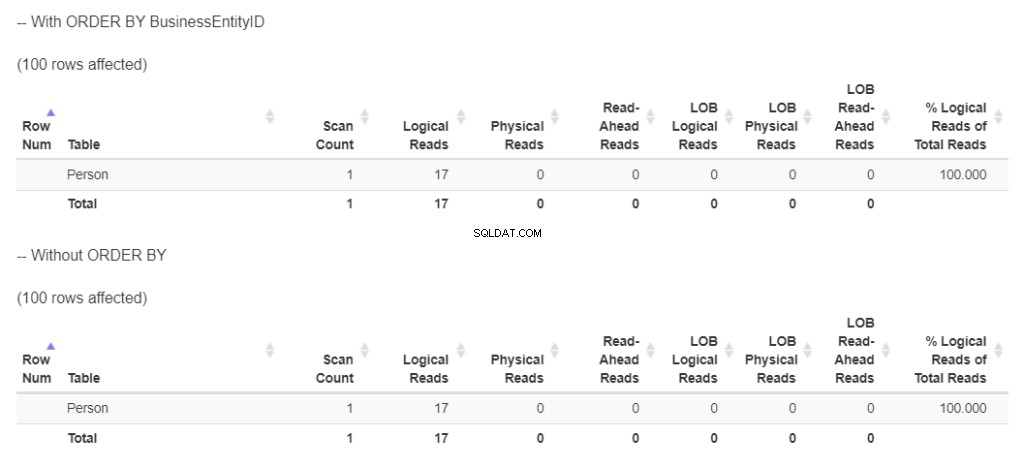
図9 。 Personテーブルに対する2つのクエリは、同じ論理読み取りを示します。 1つはORDERBYあり、もう1つはなしです。
どちらにも17の論理読み取りがあります。同じ100行が返されるため、これは論理的です。しかし、彼らは同じ計画を持っていますか?図10を確認してください。
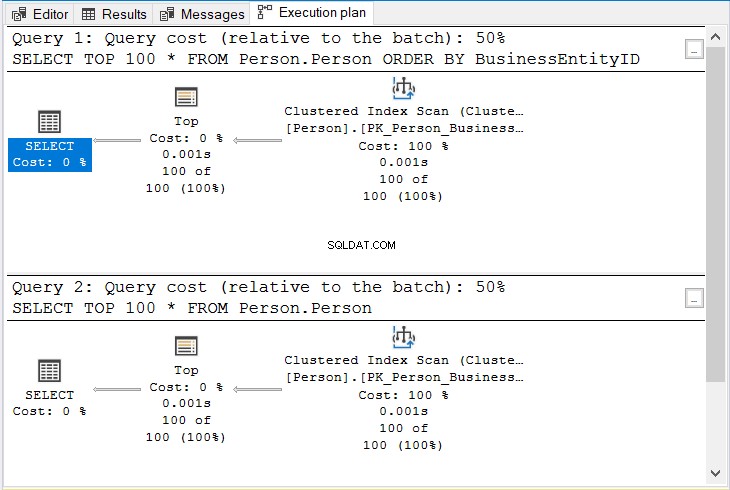
図10 。 クラスター化されたインデックスキーで並べ替えるときにORDERBYを使用するかどうかにかかわらず、同じプラン。
同じ演算子と同じクエリコストを観察します。
しかし、なぜ? 1つ以上の列をクラスター化インデックスにインデックス付けする場合、テーブルは物理的に並べ替えられます クラスタ化されたインデックスキーによって。そのため、そのキーで並べ替えなくても、結果は並べ替えられます。
結論は? ORDER BYを使用する同様のケースでは、クラスター化されたインデックスキーを使用しないことで自分を許してください 。より少ないキーストロークでエネルギーを節約します。
4。文字列列に数字が含まれている場合は、ORDERBY<文字列列>を使用しないでください
数値を含む文字列列で並べ替える場合は、実数タイプのような並べ替え順序を期待しないでください。そうでなければ、あなたは大きな驚きに直面しています。
これが例です。
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY NationalIDNumber;
図11の出力を確認してください。
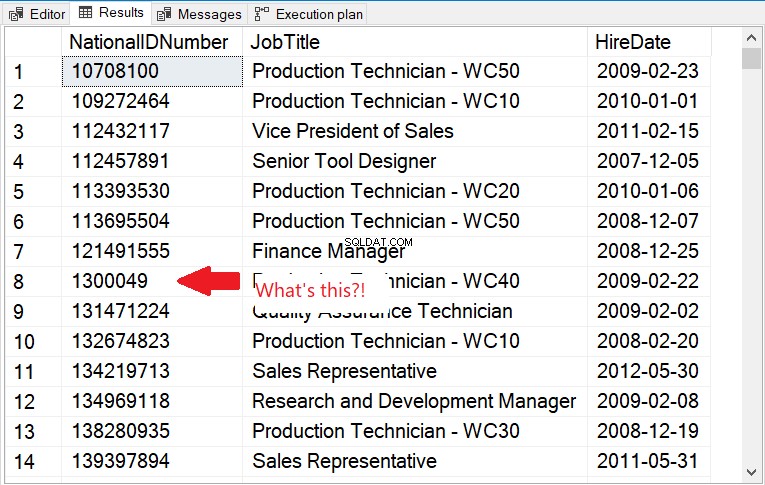
図11 。 数値を含む文字列列の並べ替え順序。数値には従いません。
図11では、辞書式順序に従います。したがって、これを修正するには、CASTを整数に使用します。
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT)
固定出力については、図12を確認してください。
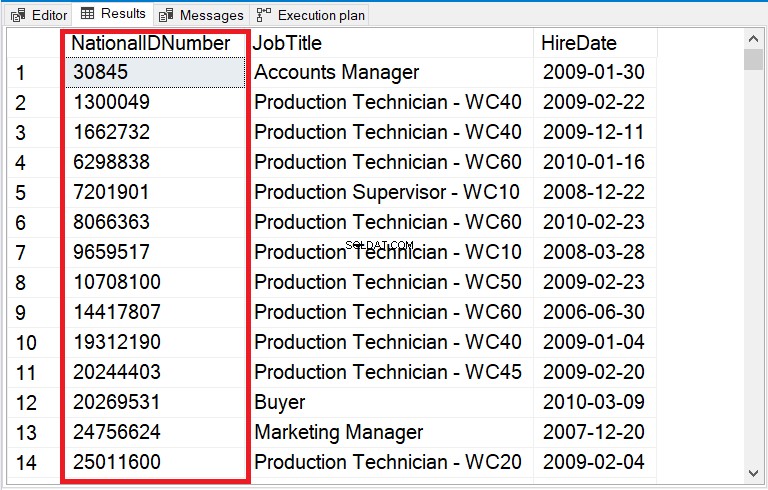
図12 。 CASTからINTに、数値を含む文字列列の並べ替えを修正しました。
したがって、 ORDER BY
5。 SELECTINTO#TempTableをORDERBYで使用しないでください
目的のソート順は、ターゲットの一時テーブルでは保証されません。 公式ドキュメントをご覧ください 。
前の例から変更したコードを作成しましょう。
SELECT
NationalIDNumber
,JobTitle
,HireDate
INTO #temp
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT * FROM #temp;
前の例との唯一の違いは、INTO句です。出力は図11と同じになります。列をINTにキャストしても、正方形1に戻ります。
CREATETABLEを使用して一時テーブルを作成する必要があります。ただし、追加のID列を含めて、それを主キーにします。次に、一時テーブルにINSERTします。
これが修正されたコードです。
CREATE TABLE #temp2
(
id INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
NationalIDNumber NVARCHAR(15) NOT NULL,
JobTitle NVARCHAR(50) NOT NULL,
HireDate DATE NOT NULL
)
GO
INSERT INTO #temp2
(NationalIDNumber, JobTitle, HireDate)
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM #Temp2;
そして、出力は図12と同じになります。それは機能します!
SQLORDERBYの使用に関する注意事項
SQLORDERBYを使用する際の一般的な落とし穴について説明しました。要約は次のとおりです:
すべきこと :
- ORDERBY列にインデックスを付けます
- WHEREとOFFSET/FETCHで結果を制限します
禁止事項 :
- クラスター化されたインデックスキーで並べ替える場合は、ORDERBYを使用しないでください。
- 文字列列に数字が含まれている場合は、ORDERBYを使用しないでください。代わりに、文字列列を最初にINTにキャストします。
- ORDERBYでSELECTINTO#TempTableを使用しないでください。代わりに、最初に追加のID列を使用して一時テーブルを作成します。
ORDER BYを使用する際のヒントとコツは何ですか?下記のコメントセクションでお知らせください。この投稿が気に入ったら、お気に入りのソーシャルメディアプラットフォームで共有してください。