この記事では、テーブルをプライマリファイルグループからセカンダリファイルグループに移動する方法について説明します。まず、データファイル、ファイルグループ、ファイルグループの種類を理解しましょう。
データベースファイルとファイルグループ
SQL Serverを任意のサーバーにインストールすると、データを格納するためのプライマリデータファイルとログファイルが作成されます。プライマリデータファイルには、テーブル、インデックス、ストアドプロシージャなどのデータとデータベースオブジェクトが格納されます。ログファイルには、トランザクションの回復に必要な情報が格納されます。データファイルはファイルグループにまとめることができます。
SQLServerには3種類のファイルがあります
- プライマリファイル :SQL Serverのインストール時に作成され、データベースのメタデータと情報が含まれます。ユーザーデータ、オブジェクトはプライマリデータファイルに保存できます。プライマリファイルの拡張子は.mdfです。
- セカンダリファイル :セカンダリファイルはユーザー定義です。ユーザーデータ、ユーザーが作成したオブジェクトを保存します。拡張子は.ndfです。
- トランザクションログファイル ■:T-Logsファイルは、データベースを回復するために実行されたすべてのトランザクションをログに記録します。 .ldfのログファイル拡張子。
上で述べたように、データファイルはファイルグループにグループ化できます。 SQL Serverのインストール中に、プライマリデータファイルを持つプライマリファイルグループが作成されます。セカンダリファイルグループはユーザー定義です。それらには二次データファイルがあります。新しいデータベースを作成するときに、セカンダリデータファイルとファイルグループを作成できます。セカンダリデータファイルを追加すると、パフォーマンスが向上します。異なるディスクドライブまたは個別のディスクパーティションに作成できるため、IO待機と読み取り/書き込みの待ち時間が短縮されます。
テーブルとインデックスを別々のファイルグループに保持することをお勧めします。また、大きなテーブルを別々のファイルに保持すると、パフォーマンスが向上します。
ファイルグループには次の3つのタイプがあります。
- 行ファイルグループ :行ファイルグループは、プライマリファイルグループとも呼ばれ、プライマリデータファイルが含まれています。 SQLオブジェクト、データ、システムテーブルはプライマリファイルグループに割り当てられます。
- メモリ最適化ファイルグループ :メモリ最適化ファイルグループには、メモリ最適化テーブルとデータが含まれています。インメモリOLTPを有効にするには、メモリ最適化ファイルグループを作成する必要があります。
- FileStream :ファイルストリームファイルグループには、画像、ドキュメント、実行可能ファイルなどのファイルストリームデータが含まれます。プライマリファイルグループにはファイルストリームデータを含めることはできません。FileStreamファイルグループを作成する必要があります。 FileStreamデータが含まれています。
デモのセットアップ
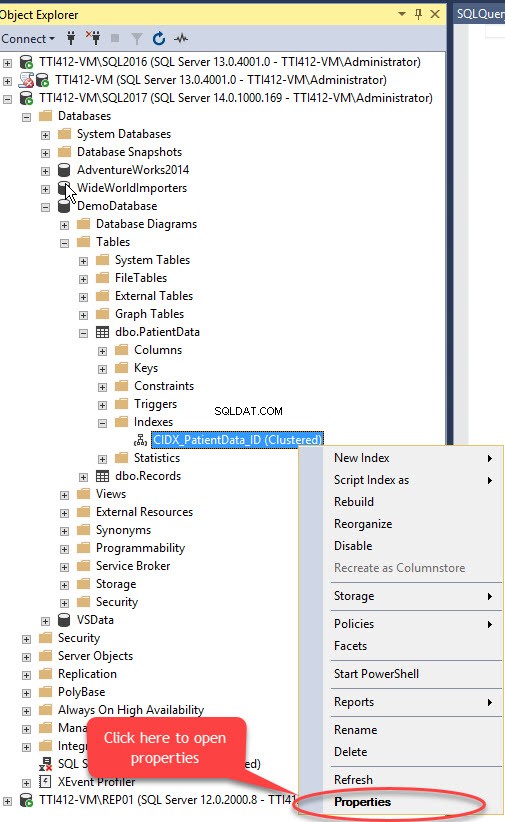
このデモでは、SQLServer2017インスタンスに「DemoDatabase」を作成しました。 「Records」タブと「PatientData」タブがデータベースに作成されました。 「PK_CIDX_Records_ID」主キーは「Records」テーブルに作成され、「CIDX_PatientData_ID」クラスター化インデックスは「PatientData」テーブルに作成されました。このデモでは、「Records」テーブルと「PatientData」テーブルをプライマリファイルグループからセカンダリファイルグループに移動します。
このためには、次のことを行う必要があります。
- セカンダリファイルグループを作成します。
- データファイルをセカンダリファイルグループに追加します。
- 主キー制約を使用してクラスター化インデックスを移動することにより、テーブルをセカンダリファイルグループに移動します。
- 主キーなしでクラスター化インデックスを移動して、テーブルをセカンダリファイルグループに移動します。
セカンダリファイルグループの作成
セカンダリファイルグループは、T-SQLを使用するか、SQL ServerManagementStudioのファイルの追加ウィザードを使用して作成できます。 SSMSを使用してファイルグループを追加するには、SSMSを開き、ファイルグループを作成する必要があるデータベースを選択します。データベースを右クリックして、「プロパティ」を選択します 」>>「ファイルグループ」を選択します 」をクリックし、「ファイルグループの追加」をクリックします 次の画像に示すように」:
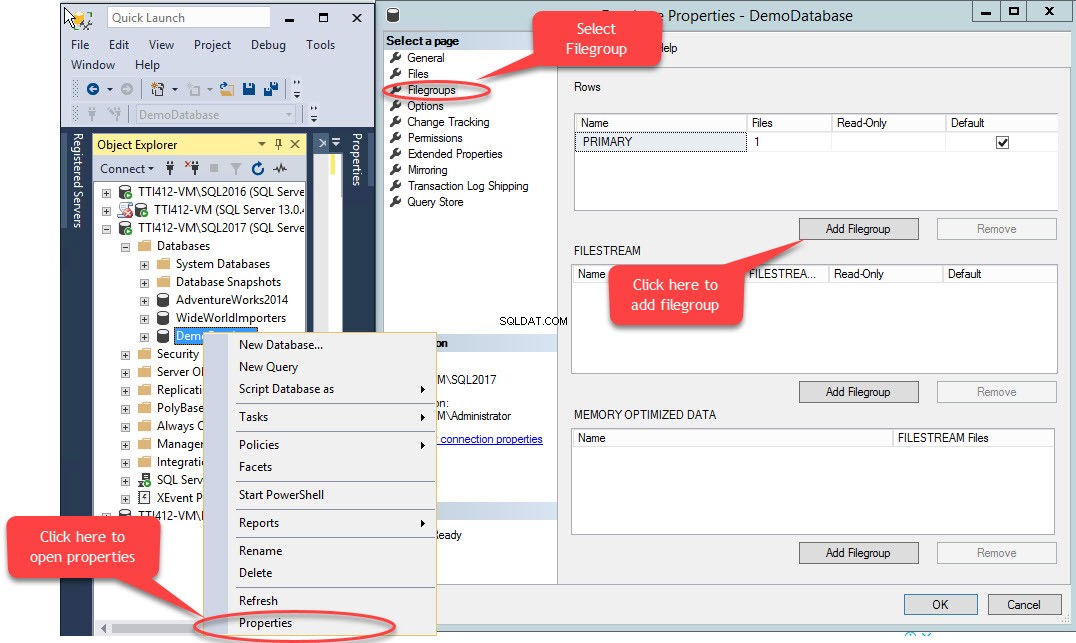
「ファイルグループの追加」をクリックすると 」ボタンをクリックすると、「行」に行が追加されます 」グリッド。 「行 」グリッドで、「名前」に適切なファイルグループ名を入力します " 桁。ファイルグループは読み取り専用でもデフォルトでもありません。したがって、読み取り専用を維持してください およびデフォルト 新しいファイルグループのチェックボックスがオフになっています。次の画像を参照してください:
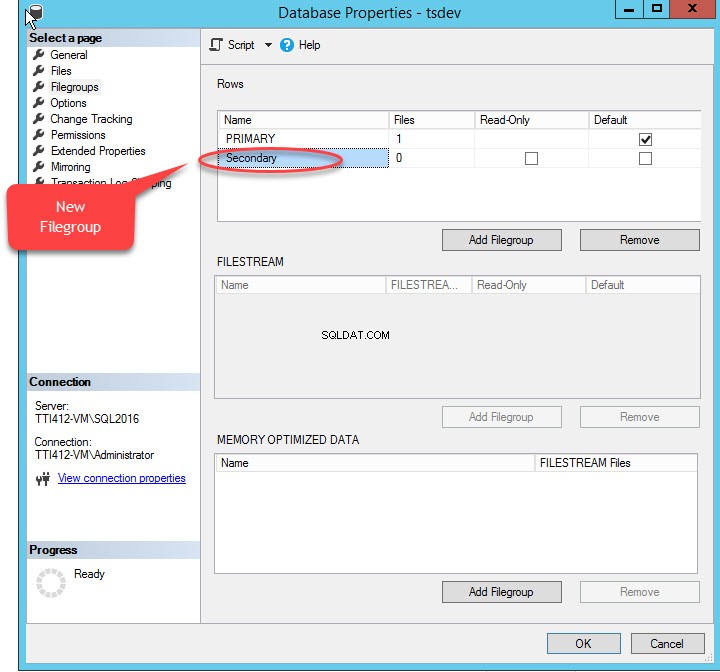
[OK]をクリックしてダイアログボックスを閉じます。
T-SQLスクリプトを使用してファイルグループを作成するには、次のスクリプトを実行します。
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
ファイルグループへのファイルの追加
ファイルグループにファイルを追加するには、データベースのプロパティを開き、[ファイル]を選択して、[追加]をクリックします。次の画像に示すように:
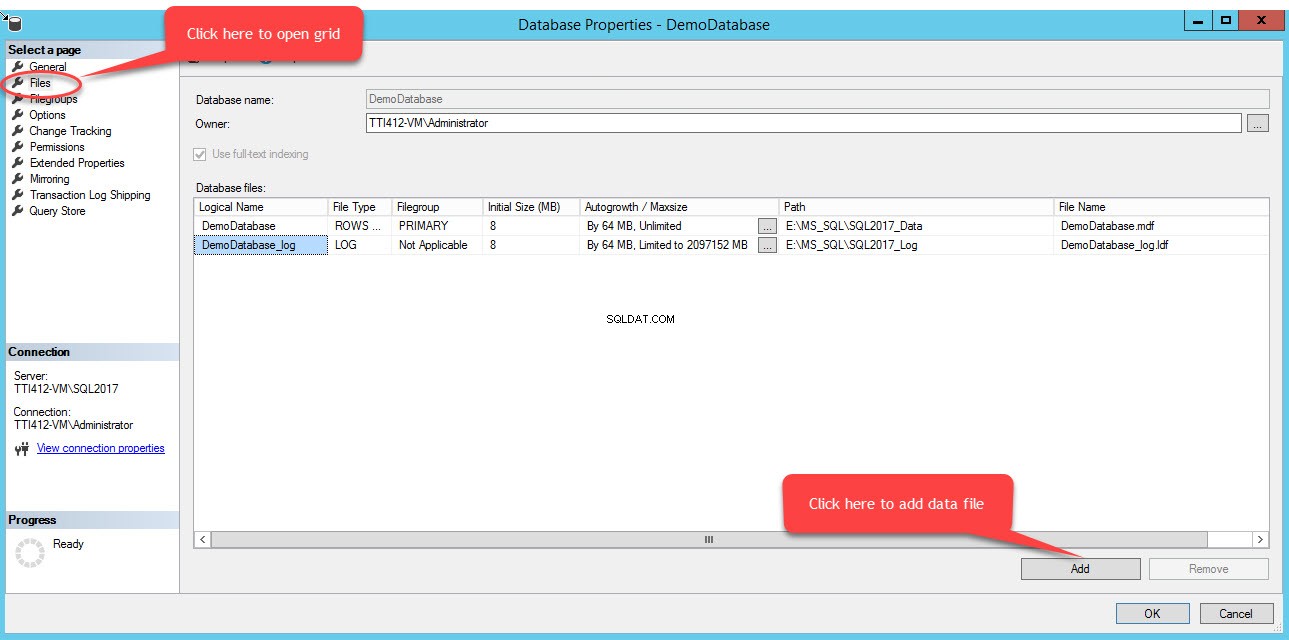
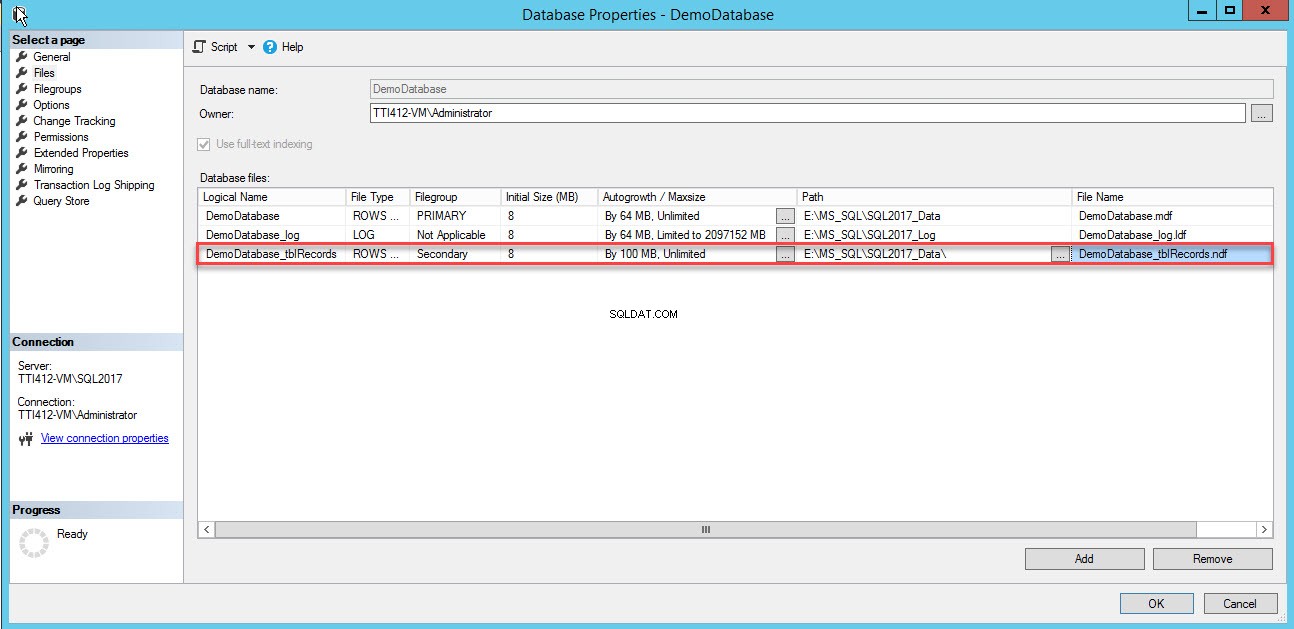
データベースファイルに空の行が追加されます グリッドビュー。グリッドビューで、論理名に適切な論理名を入力します 列で、行データを選択します ファイルタイプから ドロップダウンボックスで、セカンダリを選択します ファイルグループから ドロップダウンボックスで、ファイルの初期サイズを初期サイズに設定します 列、自動成長/最大サイズで自動成長と最大サイズのパラメータを設定します 列に、パス内のセカンダリデータファイルの物理的な場所を指定します 列に入力し、ファイル名に適切なファイル名を入力します 桁。次の画像を参照してください:
次のT-SQLスクリプトを使用して、セカンダリデータファイルを作成します。
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
二次データファイルが作成されました。次の画像を参照してください:
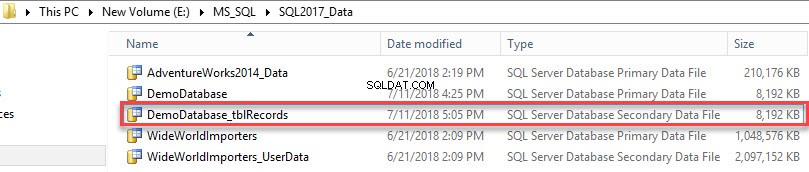
データベース上に作成されたファイルグループのリストを表示するには、次のクエリを実行します。
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupidの内部結合sys.sysfilesb
以下はクエリの出力です。

既存のテーブルをプライマリファイルグループからセカンダリファイルグループに転送する
クラスタ化されたインデックスを別のファイルグループに移動することで、既存のテーブルを別のファイルグループに移動できます。ご存知のように、クラスター化されたインデックスのリーフノードには実際のデータがあります。したがって、クラスター化インデックスを移動すると、テーブル全体を別のファイルグループに移動できます。インデックスの移動には制限があります。インデックスが主キーまたは一意性制約である場合、SQL ServerManagementStudioを使用してインデックスを移動することはできません。これらのインデックスを移動するには、インデックスの作成を使用する必要があります ステートメントとDROP_Existing=ON オプション。
主キー制約を使用したクラスター化インデックスの移動。
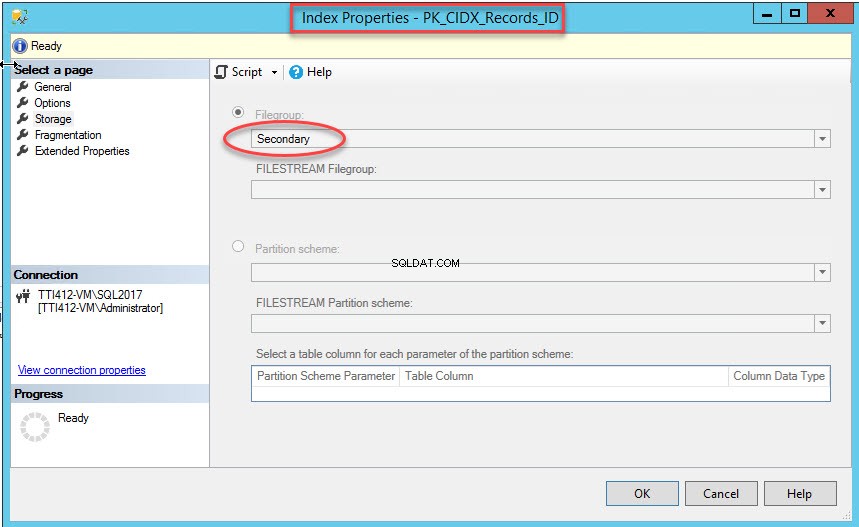
主キーは一意の値を適用するため、一意のクラスター化インデックスを作成します。キー列はPRNです。セカンダリファイルグループに作成するには、 DROP_EXISTING =ONを設定します オプションとファイルグループはセカンダリである必要があります。次のスクリプトを実行します。
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
コマンドが正常に実行されたら、セカンダリファイルグループにインデックスが作成されていることを確認します。これを行うには、ストレージを右クリックします インデックスプロパティのオプション ダイアログボックス。インデックスプロパティを開くには、 DemoDatabaseを展開します データベース>>テーブルを展開>>インデックスを展開します 。 PK_CIDX_Records_IDを右クリックします 、次の画像に示すように:
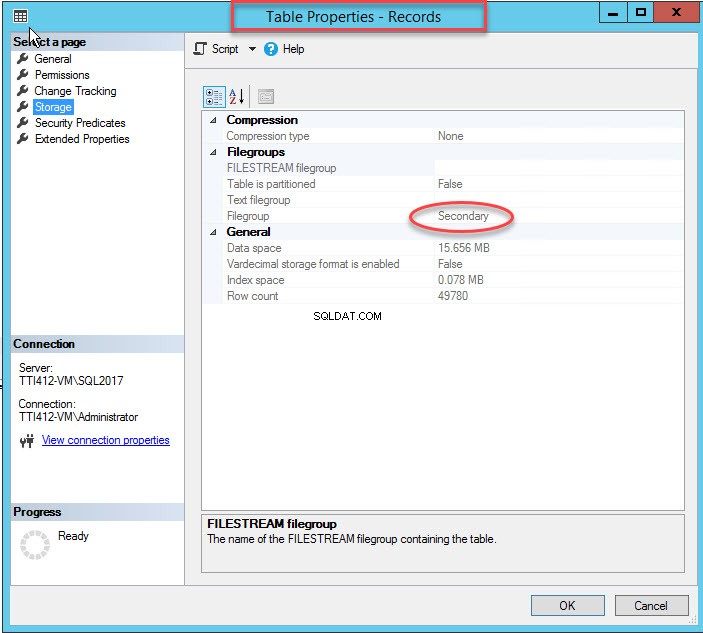
前述したように、クラスター化されたインデックスがセカンダリファイルグループに移動すると、テーブルはセカンダリファイルグループに移動されます。確認するには、ストレージを右クリックします テーブルプロパティのオプション ダイアログボックス。インデックスプロパティを開くには、 DemoDatabaseを展開します データベース>>テーブルを展開 ■>>レコードを右クリックします ストレージを選択します 次の画像に示すように:
主キーなしでクラスター化インデックスを移動する
SQL Server Management Studioを使用して、主キーなしでクラスター化インデックスを移動できます。これを行うには、 DemoDatabaseを展開します データベース>>テーブルを展開>> Indexeを展開します ■>>CIDX_PatientData_IDを右クリックします インデックスを作成し、プロパティを選択します 次の画像に示すように:
インデックスプロパティ ダイアログボックスが開きます。ダイアログボックスで、[ストレージ]、[]を選択します [ストレージ]ウィンドウで、[ファイルグループ]をクリックします ドロップダウンボックスで、セカンダリを選択します ファイルグループをクリックし、[ OK ]をクリックします 次の画像に示すように:
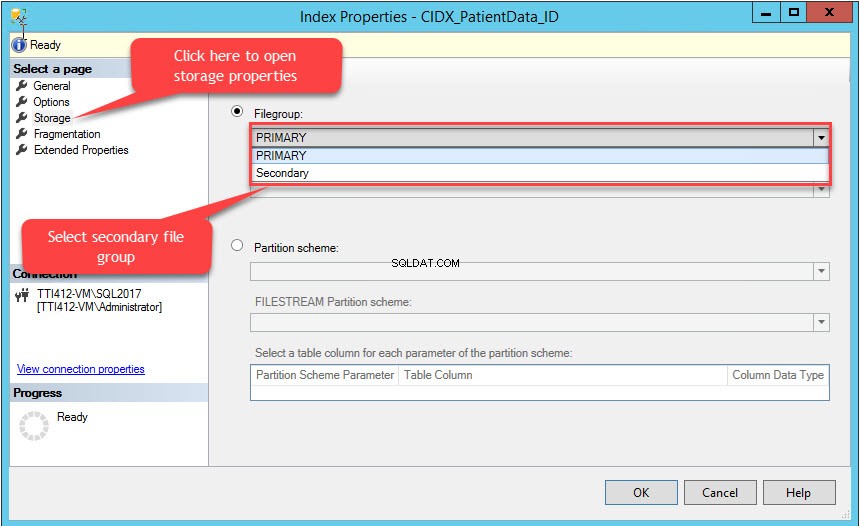
インデックスファイルグループを変更すると、インデックス全体が再作成されます。インデックスが再作成されたら、テーブルのプロパティを開きます ストレージを選択します。
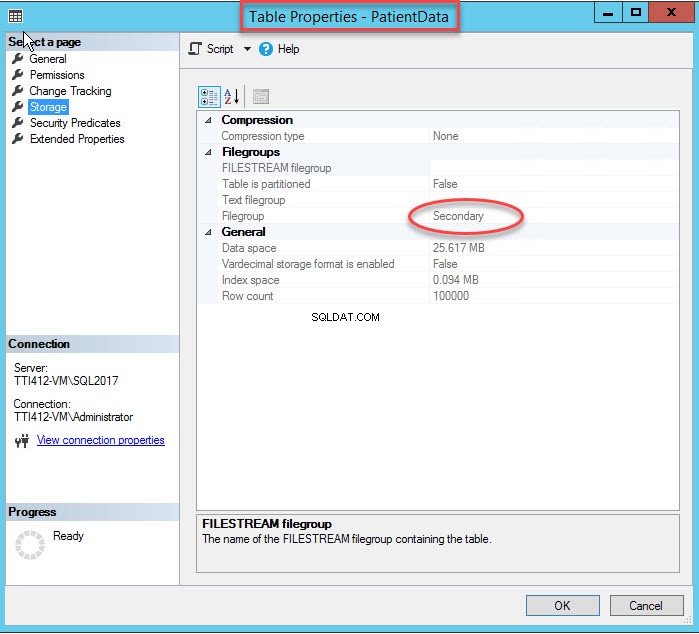
上の画像でわかるように、 CIDX_PatientData_IDを移動します セカンダリファイルグループPatientDataへのクラスター化されたインデックス テーブルもセカンダリに移動されます ファイルグループ。
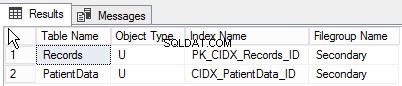
次のクエリを実行すると、別のファイルグループに作成されたオブジェクトのリストを見つけることができます。
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go クエリの出力は次のとおりです。
概要
この記事では、説明しました
-
- データファイルとファイルグループの基本。
- セカンダリファイルグループを作成し、それにセカンダリデータファイルを追加する方法。
- 次を移動して、テーブルをセカンダリファイルグループに移動します。
- 主キー。
- クラスター化されたインデックス。