概要
この記事では、SQLテーブルから重複行を削除するために利用できる2つの異なるアプローチについて説明します。これは、時間どおりに行われないと、データが大きくなるにつれて時間の経過とともに困難になることがよくあります。
重複する行の存在は、SQL開発者とテスターが時々直面する一般的な問題ですが、これらの重複する行は、この記事で説明するさまざまなカテゴリに分類されます。
この記事では、データベーステーブルに挿入されたデータが重複レコードの導入につながる特定のシナリオに焦点を当て、次に重複を削除する方法を詳しく見て、最後にこれらの方法を使用して重複を削除します。
サンプルデータの準備
重複を削除するために利用できるさまざまなオプションの調査を開始する前に、この時点でサンプルデータベースを設定することをお勧めします。これは、重複データがシステムに侵入する状況と、それを根絶するために使用するアプローチを理解するのに役立ちます。 。
サンプルデータベース(UniversityV2)のセットアップ
学生のみで構成される非常に単純なデータベースを作成することから始めます。 最初の表。
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
生徒のテーブルを作成する
Studentテーブルに2つのレコードのみを追加しましょう:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
データチェック
現在、2つの異なるレコードを含むテーブルを表示します。
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
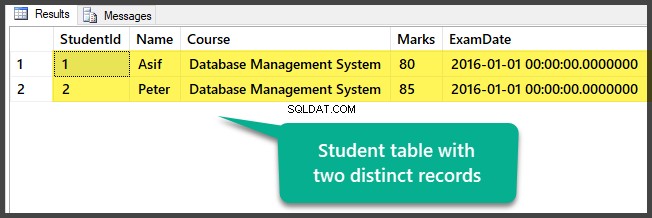
1つのテーブルと2つの異なる(異なる)レコードを含むデータベースを設定することで、サンプルデータを正常に準備できました。
ここでは、単純な状況から少し複雑な状況まで、重複が導入および削除される可能性のあるいくつかのシナリオについて説明します。
ケース01:重複の追加と削除
次に、Studentテーブルに重複する行を導入します。
前提条件
この場合、学生の名前の場合、テーブルには重複したレコードがあると言われます 、コース 、マーク 、および ExamDate 学生のIDであっても、複数のレコードで一致する 違います。
したがって、2人の学生が同じ名前、コース、マーク、および試験日を持つことはできないと想定しています。
StudentAsifの重複データの追加
Student:Asifの重複レコードを意図的に挿入しましょう 学生に 次のような表:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
重複する学生データを表示する
学生を表示する 重複レコードを表示するテーブル:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
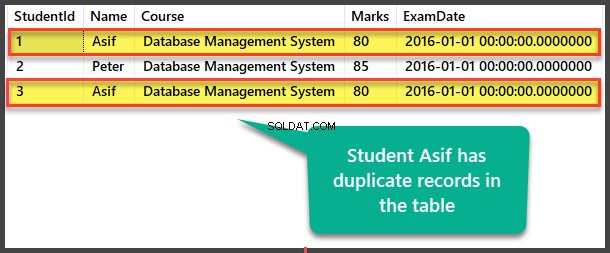
自己参照方法による重複の検索
このテーブルに何千ものレコードがある場合、テーブルを表示してもあまり役に立ちません。
自己参照方式では、同じテーブルへの2つの参照を取得し、他のIDよりも小さくまたは大きくなるIDを除いて、列ごとのマッピングを使用してそれらを結合します。
自己参照メソッドを見て、次のような重複を見つけましょう。
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
上記のスクリプトの出力には、重複するレコードのみが表示されます。

自己参照方法-2による重複の検索
自己参照を使用して重複を見つける別の方法は、次のようにINNERJOINを使用することです。
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

自己参照方式による重複の削除
次の構文に沿ってDELETEを使用することを除いて、重複を見つけるために使用したのと同じ方法を使用して重複を削除できます。
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
重複削除後のデータチェック
重複を削除した後、レコードをすばやく確認しましょう:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
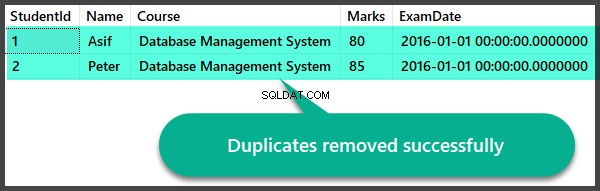
重複ビューの作成と削除重複ストアドプロシージャ
スクリプトがSQLで重複する行を正常に検出して削除できることがわかったので、使いやすさのためにそれらをビューとストアドプロシージャに変換することをお勧めします。
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
複数の重複レコードの追加と表示
ここで、学生にさらに4つのレコードを追加しましょう。 テーブルとすべてのレコードは、同じ名前、コース、マーク、試験日を持つように重複しています:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
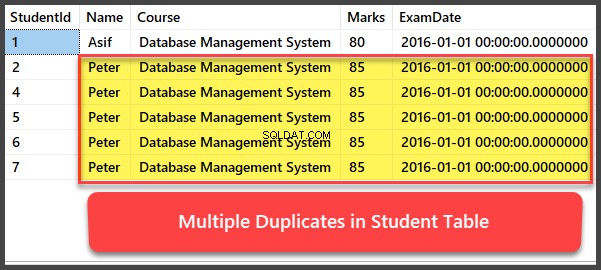
UspRemoveDuplicatesプロシージャを使用した重複の削除
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
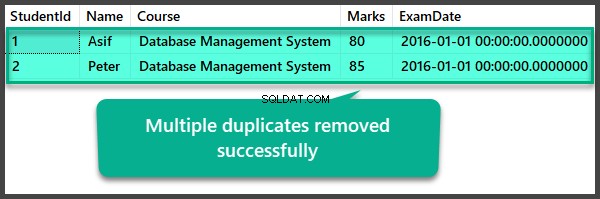
複数の重複を削除した後のデータチェック
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
ケース02:同じIDの重複の追加と削除
これまでに、異なるIDを持つ重複レコードを特定しましたが、IDが同じである場合はどうなりますか。
たとえば、主キーのないテキストファイルまたはExcelファイルからテーブルが最近インポートされたシナリオを考えてみてください。
前提条件
この場合、一部のID列を含むすべての列の値が完全に同じであり、主キーが欠落しているために重複レコードを入力しやすくなっている場合、テーブルには重複レコードがあると言われます。
主キーなしでコーステーブルを作成する
主キーがない場合に重複するレコードがテーブルに分類されるシナリオを再現するために、最初に新しいコースを作成しましょう。 次のように、University2データベースに主キーがないテーブル:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
人口コーステーブル
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
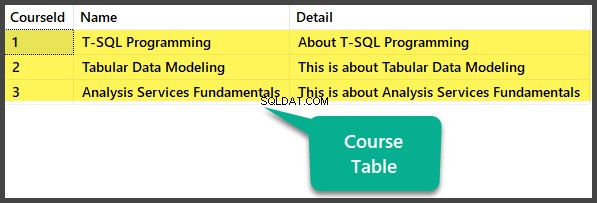
データチェック
コースを表示する テーブル:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
コーステーブルに重複データを追加する
次に、重複をコースに挿入します テーブル:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
重複するコースデータを表示する
表を表示するには、すべての列を選択してください:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

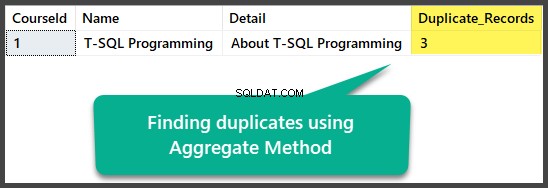
集計方法による重複の検索
集計カウント(*)関数を使用してすべての行をカウントするとともに、すべての列を選択した後、すべての列を合計1つ以上でグループ化することにより、集計メソッドを使用して正確な重複を見つけることができます。
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
これは次のように適用できます:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
集計方法による重複の削除
次のように集計メソッドを使用して重複を削除しましょう:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
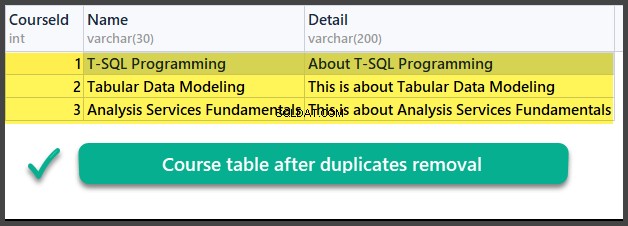
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
データチェック
UniversityV2を使用
そのため、2つの異なるシナリオに基づく2つの異なる方法を使用して、データベーステーブルから重複を削除する方法を正常に学習しました。
やるべきこと
データベーステーブルを簡単に識別して、重複する値から解放できるようになりました。
1. UspRemoveDuplicatesByAggregateを作成してみます 上記の方法に基づいてストアドプロシージャを作成し、ストアドプロシージャを呼び出して重複を削除します
2.上記で作成したストアドプロシージャ(UspRemoveDuplicatesByAggregates)を変更して、この記事に記載されているクリーンアップのヒントを実装してみてください。
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. UspRemoveDuplicatesByAggregate を確認できますか? 重複を削除した後でも、ストアドプロシージャを可能な限り何度でも実行して、プロシージャが最初から一貫していることを示すことができますか?
4.以前の記事「テスト駆動データベース開発(TDDD)の開始にジャンプ–パート1」を参照して、SQLDevBlogデータベーステーブルに重複を挿入してみてください。その後、このヒントに記載されている両方の方法を使用して重複を削除してみてください。
5.別のサンプルデータベースEmployeesSampleを作成してみてください 以前の記事「データベース単体テストで依存関係とデータを分離する方法」を参照し、重複をテーブルに挿入して、このヒントから学んだ両方の方法を使用してそれらを削除してみてください。
便利なツール:
dbForge Data Compare for SQL Server –ビッグデータを処理できる強力なSQL比較ツール。